点击下方
卡片
,关注
「3D视觉工坊」
公众号
选择
星标
,干货第一时间送达
来源:3D视觉工坊
添加小助理:cv3d001,备注:方向+学校/公司+昵称,拉你入群。文末附3D视觉行业细分群。
扫描下方二维码,加入「
3D视觉从入门到精通
」知识星球,星球内凝聚了众多3D视觉实战问题,以及各个模块的学习资料:
近20门秘制视频课程
、
最新顶会论文
、计算机视觉书籍
、
优质3D视觉算法源码
等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

0. 论文信息
标题:SPAQ-DL-SLAM: Towards Optimizing Deep Learning-based SLAM for Resource-Constrained Embedded Platforms
作者:Niraj Pudasaini, Muhammad Abdullah Hanif, Muhammad Shafique
机构:New York University Abu Dhabi
原文链接:https://arxiv.org/abs/2409.14515
1. 摘要
优化基于深度学习的同步定位和地图绘制(DL-SLAM)算法对于在资源受限的嵌入式平台上高效实施、实现自主移动机器人中的实时板上计算至关重要。本文介绍了SPAQ-DL-SLAM,这是一个战略性地将结构化修剪和量化(SPAQ)应用于最先进的DL-SLAM算法之一DROID-SLAM的架构的框架,以提高资源和能量效率。具体来说,我们在DROID-SLAM内的深度学习模块上执行结构化修剪,并基于逐层灵敏度分析进行微调,然后进行8位训练后静态量化(PTQ)。我们的SPAQ-DROIDSLAM模型是DROID-SLAM模型的优化版本,使用我们的SPAQ-DL-SLAM框架,具有20%的结构化修剪和8位PTQ,与DROID-SLAM模型相比,FLOPs减少了18.9%,整体模型大小减少了79.8%。我们在TUM-RGBD基准上的评估表明,SPAQ-DROID-SLAM模型在绝对轨迹误差(ATE)度量上比DROID-SLAM模型平均高出10.5%。此外,我们在ETH3D SLAM训练基准上的结果表明,与DROIDSLAM模型相比,SPAQ-DROID-SLAM模型具有更高的曲线下面积(AUC)分数和在2个额外数据序列中的成功,从而增强了泛化能力。尽管有这些改进,该模型在来自EuRoC数据集的不同Vicon室序列上表现出性能差异,这些序列是在高角速度下捕获的。这种在一些不同场景下的不同性能表明,考虑操作环境和任务来设计DL-SLAM算法可以实现在资源受限的嵌入式平台中部署的最佳性能和资源效率。
2. 引言
同时定位与地图构建(SLAM)是一种技术,它使智能体能够在构建未知环境地图的同时,实时追踪自身位置。SLAM被用于实现机器人的自主导航,是实体人工智能(embodied AI)系统中用于导航的内在组成部分。随着实体智能体越来越多地被部署在复杂、动态的真实世界场景中,对精确、鲁棒且计算高效的机载SLAM系统的需求显著增加。
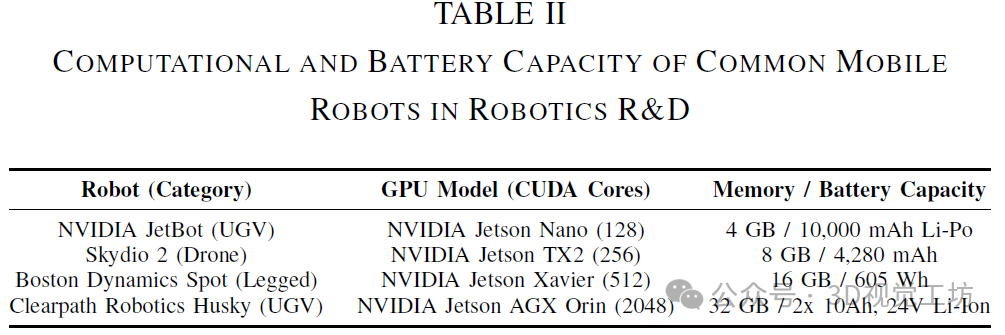
当前的SLAM方法可分为经典方法和基于深度学习的方法。以ORB-SLAM3为例的经典SLAM依赖于手工设计的特征检测和匹配算法。尽管这些方法在计算上是高效的,但在复杂、动态的环境中往往表现不佳。相比之下,DL-SLAM系统(如DROID-SLAM、Rover-SLAM、GO-SLAM和DVI-SLAM)融合了深度神经网络(DNN),以增强对环境的感知和解读能力,从而在准确性、鲁棒性和泛化能力方面取得了显著提升。具体而言,DROID-SLAM在EuRoC数据集上的误差比ORB-SLAM3降低了43%,在TUM-RGBD数据集上,对于ORB-SLAM3成功的序列,其误差降低了83%。然而,DL-SLAM系统的计算需求(见表I)对移动机器人的机载计算构成了重大挑战。这些需求通常超出了移动机器人中常用的嵌入式平台的处理能力(见表II)。
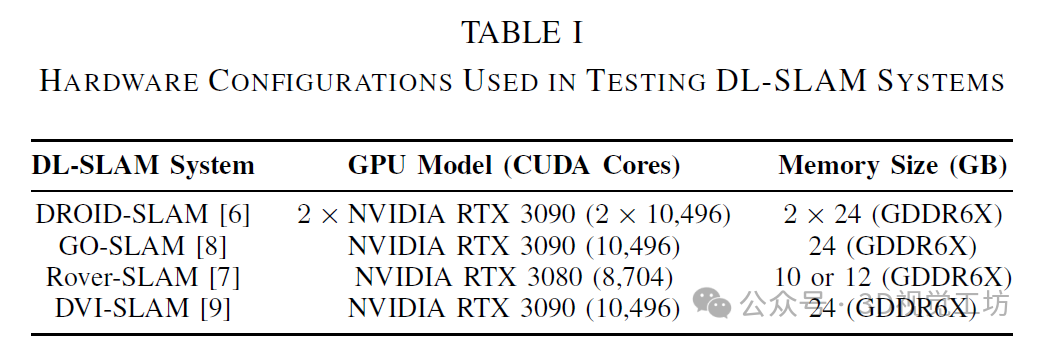
例如,DROID-SLAM的实时实现需要两块NVIDIA RTX 3090 GPU,每块GPU配备10,496个CUDA核心(见表I)。该系统将工作负载分开,在第一块GPU上运行前端跟踪和局部捆集调整,而第二块GPU则处理后端全局捆集调整和回环检测,总共需要约24GB的内存。相比之下,移动机器人中最强大的嵌入式平台之一NVIDIA Jetson AGX Orin仅有2,048个CUDA核心——仅占DROID-SLAM所需数量的9.76%——且内存容量也显著较少(见表II)。这种差异极大地挑战了将最先进的DL-SLAM算法部署在移动机器人的嵌入式平台上的可行性。
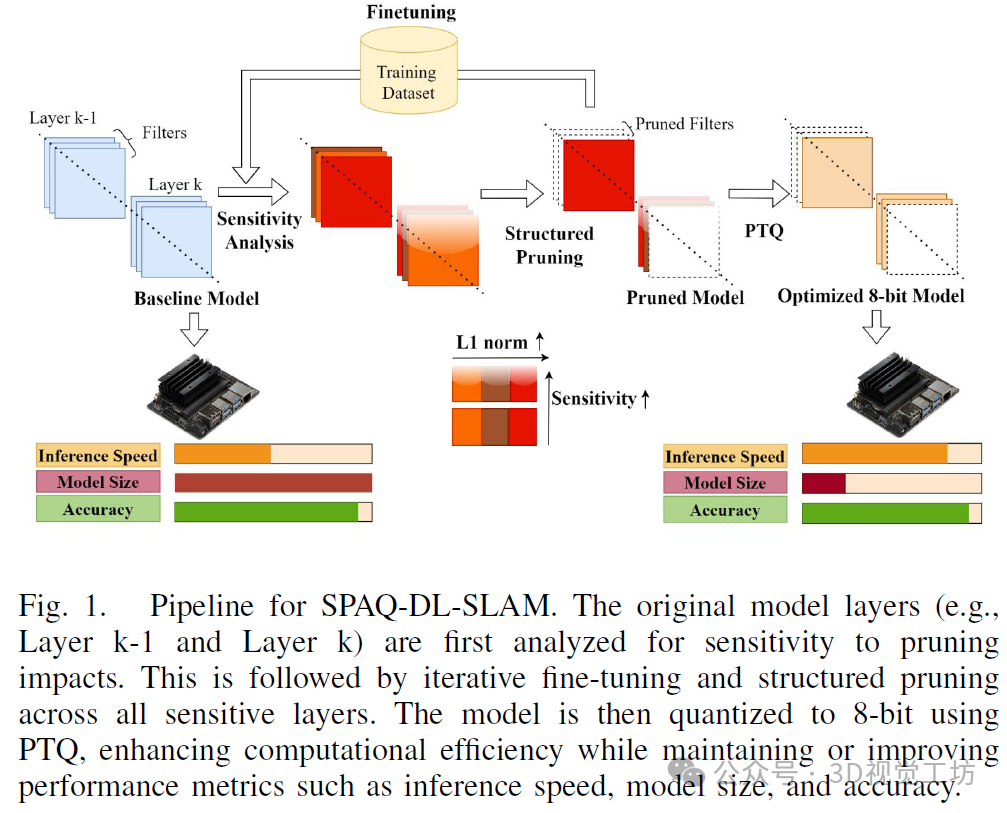
我们的创新贡献:本文提出了一种应用于DROID-SLAM架构的资源与能效优化框架SPAQDL-SLAM(见图1)。据我们所知,这是首次在DL-SLAM算法中实现神经网络优化技术。
3. 效果展示
4. 主要贡献
我们的主要贡献包括:
1)我们提出了SPAQ-DL-SLAM,这是一个针对DL-SLAM系统的优化框架,在DROID-SLAM上实现。该框架基于逐层敏感性分析进行结构化剪枝和微调,然后在DNN模块中进行8位后训练量化(PTQ)。
2)全面的评估显示,使用20%结构化剪枝和8位PTQ的SPAQ-DROID-SLAM减少了18.90%的浮点运算数(FLOPs)和79.8%的模型大小。在TUM-RGBD基准测试中,其绝对轨迹误差(ATE)指标比原始DROID-SLAM基线提高了10.5%,并在ETH3D SLAM基准测试中表现出更好的泛化能力,具有更高的AUC分数,并在另外两个序列中取得成功。
3)我们的评估表明,高角速度数据,特别是来自使用微型飞行器(MAV)的EuRoC的Vicon Room序列的数据,会降低SPAQ-DROID-SLAM的性能,这凸显了为特定环境和任务定制DL-SLAM算法以实现最佳效率的需求。
5. 方法
带有微调的结构化剪枝
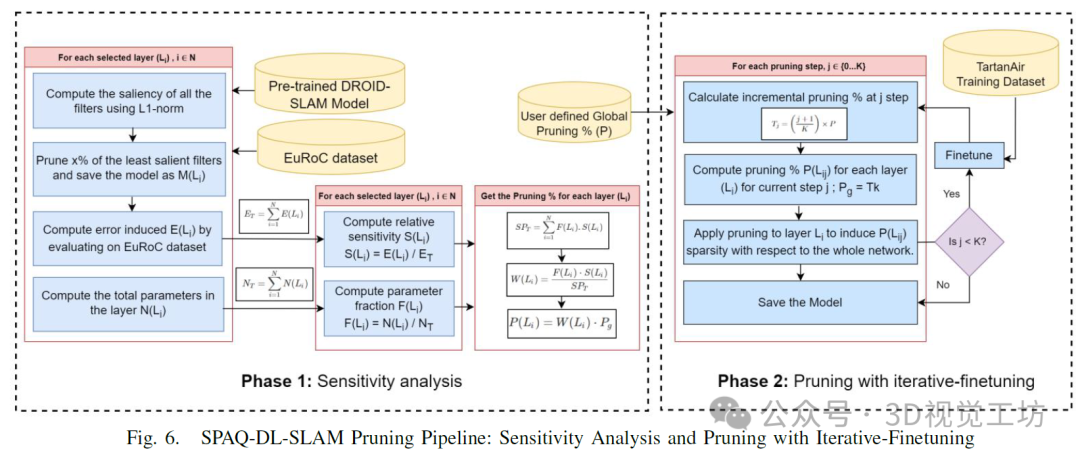
我们对DROIDSLAM架构中深度神经网络(DNN)层的剪枝方法,依赖于逐层敏感性分析的原则,这超越了论文中提出的简单基于显著性的剪枝方法。与论文中应用的方法不同,该方法需要在每个剪枝步骤中进行敏感性分析,而我们仅在所需剪枝百分比的两个中间阶段进行敏感性分析。考虑到DROIDSLAM的密集架构,这一改进显著降低了计算负载和时间。
敏感性分析:对于敏感性分析(见图8,阶段1),迭代所有DNN层:
1)对于选定的层Li,使用L1范数度量来计算滤波器的显著性。
2)基于显著性度量,剪除x%最不重要的滤波器,创建一个剪枝后的模型M(Li)。
3)在EuRoC数据集的所有单目序列上测试剪枝后的模型,并记录由此产生的误差,以评估层剪枝的影响。
4)计算相对敏感性S(Li),即剪除该层所产生的误差E(Li)与所有剪枝模型产生的总误差ET之比。
5)获取每层Li的参数比例F(Li)。
迭代微调剪枝:在敏感性分析之后,根据用户定义的全局剪枝百分比P,执行带有迭代微调的结构化剪枝(见图8,阶段2)。
1)在剪枝过程中,通过用全局剪枝率Pg规范化层的参数F(Li)和相对敏感性S(Li)的乘积,来计算要从Li中移除的滤波器百分比。
2)每次剪枝步骤后,使用训练数据集对模型进行剪枝和微调。
3)在最后一次微调步骤后,保存模型。
训练后量化(PTQ)










