作者简介:
赵永科,笔名卜居,CSDN博主,坚持写技术博客8年。现就职于阿里云计算有限公司,从事异构平台上的人工智能算法优化与系统设计,热爱读书和NES游戏。著有《深度学习:21 天实战 Caffe》一书。
如果说2015年大家还在质疑深度学习、人工智能,认为这是又一轮泡沫的开始,那么2016年可以说是人工智能全面影响人们生活的一年。从AlphaGo到无人驾驶,从美国大选到量子计算机,从小Ai预测“我是歌手”到马斯克的太空计划,每个焦点事件背后都与人工智能有联系。纵览2016年的人工智能技术,笔者的印象是实用化、智能化、芯片化、生态化,让所有人都触手可及。下面我们以时间为坐标,盘点这一年的技术进展。
AlphaGo
3月9-15日,棋坛新秀AlphaGo一战成名,以4:1成绩打败韩国职业棋手围棋九段李世石(围棋规则介绍:对弈双方在19x19棋盘网格的交叉点上交替放置黑色和白色的棋子,落子完毕后,棋子不能移动,对弈过程中围地吃子,以所围“地”的大小决定胜负)。
其实早在2015年10月,AlphaGo v13在与职业棋手、欧洲冠军樊麾二段的五番棋比赛中,以5:0获胜。在与李世石九段比赛中版本为v18,赛后,AlphaGo荣获韩国棋院授予的“第〇〇一号 名誉九段”证书。7月19日,AlphaGo在GoRantings世界围棋排名中超过柯洁,成为世界第一。
看到AlphaGo这一连串不可思议的成绩,我们不禁要问,是什么让AlphaGo在短短时间内就能以如此大的能量在古老的围棋这一竞技项目迅速击败数千年历史积累的人类?

图1 AlphaGo与李世石的对阵
AlphaGo由Google在2014年收购的英国人工智能公司DeepMind开发,背后是一套神经网络系统,由许多个数据中心作为节点相连,每个节点内有多台超级计算机。这个系统基于卷积神经网络(Convolutional Neural Network, CNN)——一种在大型图像处理上有着优秀表现的神经网络,常用于人工智能图像识别,比如Google的图片搜索、百度的识图、阿里巴巴拍立淘等都运用了卷积神经网络。AlphaGo背后的系统还借鉴了一种名为深度强化学习(Deep Q-Learning,DQN)的技巧。强化学习的灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。不仅如此,AlphaGo借鉴了蒙特卡洛树搜索算法(Monte Carlo Tree Search),在判断当前局面的效用函数(value function)和决定下一步的策略函数(policy function)上有着非常好的表现。作为一个基于卷积神经网络、采用了强化学习模型的人工智能,AlphaGo具有广泛适应性,学习能力很强,除了玩游戏、下围棋,最近的DeepMind Health项目将人工智能引入了疾病诊断和预测中,为人们的健康提供更好的保障。
AlphaGo系统和IBM在上个世纪打败国际象棋大师卡斯帕罗夫的深蓝超级计算机有什么不同?
国际象棋AI算法一般是枚举所有可能招法,给局面打分。AI能力主要分为两方面:一是局面打分算法是否合理,二是迭代的深度。国际象棋开局的时候可以动8个兵(*2)和两个马(*2)共20种招法,虽然开局到中期招法会多一点,但是总数也就是几十种,游戏判断局面也简单,将军的加分,攻击强子加分,被将军或者有强子被攻击减分,控制范围大的加分,国际象棋里即将升变的兵加分,粗略一算就可以有个相对不错的判断。
围棋棋盘上每一点,都有黑、白、空,三种情况,棋盘上共有19*19=361个点,所以可能产生的局数为3的361次方种(可以想象,从137亿年前宇宙初始下起,60亿人口每天下60亿盘,到目前为止,只下了不到亿亿亿万分之一)。
围棋可选招法非常多,在初期可以全盘落子,打劫的时候则要找“劫材”。围棋判断形势的复杂度也很高,因为所有棋子地位平等,不在于一子定胜负,但每一子对于全局又都是牵一发而动全身,所以需要的是整体协调和全局决策。AlphaGo不仅能很快计算围棋当前局面的效用函数和决定下一步的策略函数,还能结合蒙特卡洛树搜索算法进行纵深的分析,得到整局棋的“最优解”。无论从计算复杂度还是决策的深度上,AlphaGo都有质的飞跃。
小结:
AlphaGo可能是Google公关塑造的一个AI形象,但这是一次十分成功的尝试,引起了世界性的关注。在这些华丽的成绩之外,技术铺垫仍然是一项不容小觑的工作,包括DQN算法模型与硬件平台。我们接下来会详细介绍。
深度增强学习DQN
增强学习是最近几年中机器学习领域的最新进展。
增强学习的目的是通过和环境交互学习到如何在相应的观测中采取最优行为。行为的好坏可以通过环境给的奖励来确定。不同的环境有不同的观测和奖励。
增强学习和传统机器学习的最大区别在于,增强学习是一个闭环学习的系统,算法选取的行为会直接影响到环境,进而影响到该算法之后从环境中得到的观测。
增强学习存在着很多传统机器学习所不具备的挑战。
首先,因为在增强学习中没有确定在每一时刻应该采取哪个行为的信息,算法必须通过探索各种可能才能判断出最优行为。如何有效地在可能行为数量较多的情况下有效探索,是增强学习的重要问题。
其次,在增强学习中一个行为不仅可能会影响当前时刻的奖励,而且还可能会影响之后所有时刻的奖励。
在最坏的情况下,一个好行为不会在当前时刻获得奖励,而会在很多步都执行正确后才能得到。在这种情况下,判断出奖励和很多步之前的行为有关非常难。
虽然增强学习存在很多挑战,它也能够解决很多传统机器学习不能解决的问题。首先,由于不需要标注的过程,增强学习可以更有效地解决环境中所存在着的特殊情况。比如,无人车环境中可能会出现行人和动物乱穿马路的特殊情况。只要模拟器能模拟出这些特殊情况,增强学习就可以学习到怎么在这些特殊情况中做出正确的行为。其次,增强学习可以把整个系统作为一个整体,从而对其中的一些模块更加鲁棒。例如,自动驾驶中的感知模块不可能做到完全可靠。前一段时间,特斯拉无人驾驶的事故就是因为在强光环境中感知模块失效导致的。增强学习可以做到,即使在某些模块失效的情况下也能做出稳妥的行为。最后,增强学习可以比较容易学习到一系列行为。
自动驾驶需要执行一系列正确的行为才能成功驾驶。如果只有标注数据,学习到的模型每个时刻偏移了一点,到最后可能就会偏移非常多,产生毁灭性的后果。而增强学习能够学会自动修正偏移。
DeepMind曾用五款雅达利(Atari)游戏Pong、打砖块、太空侵略者、海底救人、Beam Rider分别测试了自己开发的人工智能,结果发现:游戏后,神经网络的操控能力已经远超世界上任何一位已知的游戏高手。
DeepMind用同样的一套人工智能,测试各种各样的智力竞技项目,取得了优异的战绩,足以证明坐在李世石面前的AlphaGo,拥有多强的学习能力。

图2 Atari游戏画面
小结:
如果说深度学习相当于嗷嗷待哺的婴儿,需要人们准备好大量有营养的数据亲手喂给它,那么增强学习就是拥有基本生活能力的青少年,叛逆而独立,充满激情,喜欢挑战,不断在对抗中学习成长。虽然与成熟的人工智能仍有较大差距,但可以肯定,这只是个时间问题。
Google TPU
Google在今年5月18日Google I/O大会上宣布了加速机器学习的定制ASIC方案:张量处理单元(TPU)。这款芯片由Google工程师设计,用于加速TensorFlow软件,在AlphaGo中TPU也大显神通。TPU已经在用户无感知的情况下在Google云语音、Gmail、Google Photos和Google搜索业务中使用了一年时间。相比目前商品级GPU和FPGA,TPU每瓦性能高出一个数量级。
在大多数企业和研究机构中,设计并构建应用专用处理器是十分奢侈的。开发芯片即使很小的设计也需要投入上百万美元。定制设计的优势相比通用处理器具备更好的性能以及能效。为了平衡收支,需要大规模使用案例和部署量,这样才能将成本摊薄。云服务厂商显然满足这个条件。

图3 Google TPU近照
 图4 配备Google TPU的集群
图4 配备Google TPU的集群
 图5 寒武纪深度神经网络处理器发布现场
图5 寒武纪深度神经网络处理器发布现场
Google认为机器学习的规模是不可预估的,因此有必要构建专用硬件。这个举动当然也给世界上两大芯片厂商——Intel和NVIDIA带来不小触动,两家在新产品的研发上不得不多了一个难缠的对手。
近两年国内的人工智能处理器也如火如荼,最为知名的寒武纪深度神经网络处理器架构采用硬件神经元和硬件突触作为运算器,并为神经网络的高速连接设计了存储结构,另外还专门设计了与通用处理器完全不同的指令集。最新推出的寒武纪-1A(Cambricon-1A)商用智能处理器IP产品,可集成至各类终端SoC芯片,每秒可处理160亿个虚拟神经元,每秒峰值运算能力达2万亿虚拟突触,性能比通用处理器高两个数量级,功耗降低了一个数量级。该处理器荣获第三届世界互联网大会“世界互联网领先科技成果”奖项。
小结:
通用处理器的设计和制造一向由芯片巨头垄断,而在人工智能快速发展的这几年,新架构、新应用使得处理器设计的话语权逐步转移到更大体量的互联网公司,利用规模优势,按照日益增长的需求定制计算架构,在处理器历史上书写新的篇章。
智能驾驶
汽车关系到人们出行,几乎每天必备,而利用人工智能解决出行需求是一个大胆的尝试。从去年的“滴滴”、“快的”烧钱大战开始,到两家合并、今年滴滴完成了对Uber中国并购,国内打车软件实现大一统。技术上,目前主要是利用大数据指导车辆调度,利用更少的成本满足乘客的需求。而各地曝光的打车乱象也成为平台痼疾。如何利用技术克服人性的弱点,是个自然而然的问题。一种思路是使用机器代替人担任司机。
无人驾驶、人工智能等已成为世界性的前沿科技,Google、微软、特斯拉等科技巨头新贵等纷纷布局于此,足见无人车极高的研发价值和广阔的市场。
除了商业价值,无人驾驶所能带来的社会价值更加让人浮想联翩。
首先可以想到,未来无人驾驶技术成熟,可以解放人们的双手。开车出行时,可以有更多的时间做自己的事情。而对于残障人士来说,则意义更大,可以有效提高出行效率,过上更加便捷快速的交通生活。
其次,无人车一定程度上会革新现代交通模式,解决交通道路安全问题。百度高级副总裁、自动驾驶事业部总经理王劲曾表示,人工智能用大量的服务器和数据来拟合成人类的驾驶能力,这个系统会比人类所有驾驶员甚至赛车手的水平都更高,这样才能保障驾驶的安全性。安全性之外,智能化的无人车同时也是大数据集散中心,可以时时将交通状况、行驶情况回传,政府交通指挥中心根据大数据进行交通调度,势必可以更好解决拥堵问题。此外,无人车还能推动汽车工业更环保,同时激活更多新兴产业,带动新的产业升级和行业转型,促进更多就业,高精尖人才的发展。
特斯拉(Tesla)
今年10月20日,马斯克宣布所有特斯拉新车将装备具有全自动驾驶功能的硬件系统——Autopilot 2.0,这套系统包括了8个摄像机、12个超声波传感器以及一个前向探测雷达。摄像机将提供360度的视角,最大识别距离250米,其中三个将观察前方,提供冗余以确保安全;超声波传感器能够探测软性和硬性的物体;而雷达则可以确保在雨天、雾天、沙尘和雾霾天气中正常工作。

图6 Tesla汽车内景
此外升级的还有车载电脑——新系统的大脑“Tesla Neural Net”(特斯拉神经网)基于nVIDIA的Titan GPU——每秒钟能进行12万亿次计算,比上一代车载电脑快了40倍。马斯克表示,这次的硬件升级将会即时实行,成为未来特斯拉汽车的标配。换句话说,从今天起,每辆新产出的特斯拉都会具有完全自动驾驶的能力。
百度无人车
在11月16日开幕的第三届世界互联网大会上,百度无人车再次亮相。大会期间,18辆百度无人车在桐乡市子夜路智能汽车和智慧交通示范区内首次进行开放城市道路运营。此次百度无人车在乌镇运营体验,是百度首次在开放城市道路情况下,实现全程无人工干预的L4级无人驾驶技术。
在去年12月的乌镇世界互联网大会上,习近平主席视察互联网之光博览会时,百度CEO李彦宏向习近平介绍了百度无人驾驶车。
早在2013年,百度就已经开启了前沿领域的项目布局,无人车由百度研究院主导历时两年研发,2015年12月,更是专门成立自动驾驶事业部,足见百度对无人车项目的重视。凭借LBS、图像识别、大数据等领域深厚的技术积累和人工智能技术的领先,目前百度无人车的研发已经达到世界领先地位。
百度无人驾驶是国内唯一一家通过功能安全ISO26262国际标准的全自动驾驶研究项目。去年12月,百度无人车实现了在北京五环上的上路测试,最高时速100公里,并首次实现城市、环路及高速道路混合路况下全自动驾驶,标志着中国无人驾驶车的发展进入里程碑的新阶段。
对于无人车来说,人工智能、深度学习的技术发展至关重要。无人车在行驶过程中,摄像头、感应器等原件会收集大量数据,而这些数据需要实时处理和分析,通过高性能的计算能力、先进的算法及深度学习系统,来实时适应周围的路面情况自动驾驶汽车。
而据了解,百度在国内拥有首家自主研发的三维高精度地图技术,已达到较高精度,同时具备国内领先的高精度地图采集与自动化处理技术,具备完整的高精度地图采集与自动化处理系统,可支持高精度地图的规模化生产。另外,百度也已经掌握了国内领先的实时高精度定位技术,实现厘米级的定位精度,相比于GPS定位精度提升了两个数量级。在关键技术上“领跑”世界。
小结:
智能驾驶是一项复杂的工程,涵盖了汽车制造、自动控制、传感器、人工智能、地理信息、云计算、交通法规、社会伦理等多个领域,需要极强的技术水准和高尚的职业操守。
Intel人工智能布局
Intel收购Nervana
8月9日,Intel宣布收购创业公司Nervana Systems。Nervana的IP和加速深度学习算法经验可帮助Intel在人工智能领域获得一席之地。
Nervana提供基于云的服务用于深度学习,使用独立开发的、使用汇编级别优化的、支持多GPU的Neon软件,在卷积计算时采用了Winograd算法,数据载入也做了很多优化。该公司宣称,训练模型时,Neon比使用最普遍的Caffe快2倍。不仅如此,Nervana准备推出深度学习定制芯片Nervana Engine,相比GPU在训练方面可以提升10倍性能。与Tesla P100类似,该芯片也利用16-bit半精度浮点计算单元和大容量高带宽内存(HBM,计划为32GB,是竞品P100的两倍),摒弃了大量深度学习不需要的通用计算单元。
在硬件基础上,Nervana于11月份推出了Intel Nervana Graph平台(简称ngraph)。该框架由三部分组成:一个用于创建计算图的API、用于处理常见深度学习工作流的前端API(目前支持TensorFlow和Neon)、用于在 CPU/GPU/Nervana Engine上编译执行计算图的转换器API。
与此同时宣布成立Intel Nervana人工智能委员会,加拿大蒙特利尔大学Yoshua Bengio教授担任创始会员。

图7 Nervana Engine芯片架构
8月17日,在Intel开发者峰会(IDF)上,Intel透露了面向深度学习应用的新Xeon Phi处理器,名为Knights Mill(缩写为 KNM)。它不是Knights Landing和Knights Hill的竞品,而是定位在神经网络云服务中与NVIDIA Tesla GPU一较高下。

图8 ngraph框架
9月6日,Intel收购计算机视觉创业公司Movidius。
Movidius是人工智能芯片厂商,提供低能耗计算机视觉芯片组。Google眼镜内配置了Movidius计算机视觉芯片。Movidius芯片可以应用在可穿戴设备、无人机和机器人中,完成目标识别和深度测量等任务。除了Google之外Movidius与国内联想和大疆等公司签订了协议。Movidius的Myriad 2系列图形处理器已经被联想用来开发下一代虚拟现实产品。
9月8日,Intel FPGA技术大会(IFTD)杭州站宣布了Xeon-FPGA集成芯片项目。这是Intel并购Altera后最大的整合举动,Intel将推出CPU+FPGA架构的硬件平台,该平台预计于2017年量产,届时,一片Skylake架构的Xeon CPU和一片Stratix10的FPGA将“合二为一”,通过QPI Cache一致性互联使FPGA获得高带宽、低延迟的数据通路。在这种形态中,FPGA本身就成为了CPU的一部分,甚至CPU上的软件无需“感知”到FPGA的存在,直接调用mkl库就可以利用 FPGA来加速某些计算密集的任务。
Xeon-FPGA样机已经在世界七大云厂商(Amazon、Google、微软、Facebook、百度、阿里、腾讯)试用,用于加速各自业务热点和基础设施,包括机器学习、搜索算法、数据库、存储、压缩、加密、高速网络互连等。
除了上面CPU+FPGA集成的解决方案,Altera也有基于PCIe加速卡的解决方案。

图9 Xeon-FPGA集成芯片架构
11月8日ISDF大会上宣布,预计明年将销售深度学习预测加速器(DLIA,Deep Learning Inference Accelerator)。该加速器为软硬件集成的解决方案,用于加速卷积神经网络的预测(即前向计算)。软件基于Intel MKL-DNN软件库和Caffe框架,便于二次开发,基于PCIe的FPGA加速卡提供硬件加速。该产品将直接同Google TPU、NVIDIA Tesla P4/M4展开竞争。
小结:
Intel在人工智能领域的动作之大(All in AI),品类之全(面向训练、预测,面向服务器、嵌入式),涉猎之广(Xeon Phi,FPGA,ASIC)令人为之一振。冰冻三尺非一日之寒,AI硬件和上层软件的推广与普及还有很长一段路要走。
NVIDIA人工智能布局
NVIDIA财报显示,深度学习用户目前占据数据中心销售额一半,而HPC占三分之一,剩下的为虚拟化(例如虚拟桌面)。这也驱动NVIDIA在硬件架构和软件库方面不断加强深度学习性能,典型例子是在Maxwell处理器中最大化单精度性能,而在Pascal架构中增加了半精度运算单元。与HPC不同,深度学习软件能够利用较低精度实现较高吞吐。
Pascal架构
在4月5日GTC(GPU Technology Conference)2016大会上,NVIDIA发布了16nm FinFET制程超级核弹帕斯卡(Pascal)显卡,最让人惊叹的还是一款定位于深度学习的超级计算机DGX-1。DGX-1拥有8颗帕斯卡架构GP100核心的Tesla P100 GPU,以及7TB的SSD,两颗16核心的Xeon E5-2698 v3以及512GB的DDR4内存,半精度浮点处理能力170TFLOPS,功耗3.2kW。售价129000美元,现已面市。
9月13日,NVIDIA在GTC中国北京站发布了Tesla P4和P40。这两个处理器也基于最新的Pascal架构,是去年发布的M4和M40的升级版,包括了面向深度学习预测计算的功能单元,丢掉了64位双精度浮点计算单元,取而代之的是8-bit整数算法单元。详细参数如下。

图10 DGX-1外观
Tesla P4为半高半长卡,功耗只有50~75W,便于安装到已有的Web Server提供高效的预测服务。同时,P4包括一个视频解码引擎和两个视频编码引擎,对基于视频的预测服务更为适合。
Tesla P40与P4用途稍有不同,绝对性能高,适合训练+预测,使用GoogLeNet评估时相比上一代M40有8倍性能提升。

图11 Tesla P4/P40参数对比
Tesla P100仍然是最合适训练的GPU,自带NVLink多GPU快速互联接口和HBM2。这些特性是P40和P4不具备的,因为面向预测的GPU不需要这些。
Pascal家族从P100到P4,相对三年前的Kepler架构提速达到40~60倍。
在硬件之外,NVIDIA软件方面也不遗余力。

图12 NVIDIA Pascal架构软硬件加速情况
cuDNN
NVIDIA CUDA深度神经网络库(cuDNN)是一个GPU上的深度神经网络原语加速库。cuDNN提供高度优化的标准功能(例如卷积、下采样、归一化、激活层、LSTM的前向和后向计算)实现。目前cuDNN支持绝大多数广泛使用的深度学习框架如Caffe、TensorFlow、Theano、Torch和CNTK等。对使用频率高的计算,如VGG模型中的3x3卷积做了特别优化。支持Windows/Linux/MacOS系统,支持Pascal/Maxwell/Kepler硬件架构,支持嵌入式平台Tegra K1/X1。在Pascal架构上使用FP16实现,以减少内存占用并提升计算性能。
TensorRT
TensorRT是一个提供更快响应时间的神经网络预测引擎,适合深度学习应用产品上线部署。开发者可以使用TensorRT实现高效预测,利用INT8或FP16优化过的低精度计算,可以显著降低延迟。
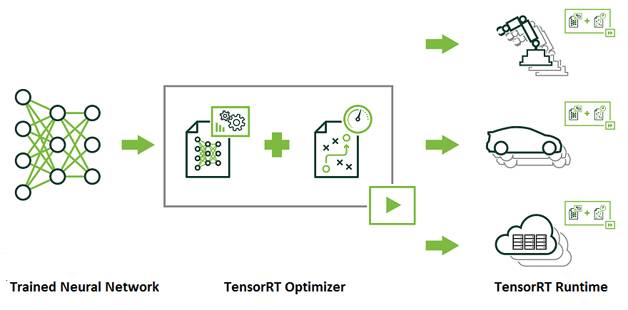
图13 TensorRT的使用方式
DeepStream SDK支持深度学习视频分析,在送入预测引擎之前做解码、预处理。
这两个软件库都是与Pascal GPU一起使用的。
小结:
NVIDIA是最早在AI发力的硬件厂商,但从未停止在软件上的开发和探索,不断向上发展,蚕食、扩充自己在AI的地盘,目前已经涵盖服务器/嵌入式平台,面向多个专用领域(自动驾驶、医疗健康、超算),具备极强的爆发力(从今年NVIDIA股票也能看出这一点)。
FPGA 崛起
FPGA(Field-Programmable Gate Array)是现场可编程门阵列的英文缩写。简单来说,FPGA就像是一块空白的数字电路,开发者可以通过编写硬件代码的方式来设计一个数字电路,代码编写完成后,类似软件代码中的编译过程,FPGA的综合器会对代码进行综合、布局布线,之后会生成一个二进制文件,将这个二进制文件烧写到FPGA后,原本空白的FPGA就变成了开发者设计的电路,这就是“现场”和“可编程”的含义。同时,FPGA可以反复擦写,通过烧写不同的二进制文件来实现不同的功能。因此,FPGA是介于专用集成电路(ASIC)和通用处理器(CPU)之间的一种硬件。
Xilinx和Altera是世界上最大的两家FPGA厂商,共同占据了将近90%的市场份额。在2015年,Intel以167亿美元完成了对Altera的并购,并购后的Altera成为Intel可编程技术事业部。此次并购足以见得Intel非常看重FPGA在其生态体系中的作用,可以从中看到Intel携手FPGA进军数据中心的决心。图14为Altera的FPGA芯片。










