大量与政治相关的信息隐藏在数字文本语料库中,计算文本分析减少了昂贵的人工劳动来实现对这些语料的分析,通过算法支持工具帮助研究人员从文本中提取有意义的信息,过去十年中在政治科学领域越来越受欢迎(Benoit, 2020; Grimmer & Stewart, 2013; Lucaset al. 2015; Van Atteveldt, Trilling & Calderon, 2022; Wilkerson & Casas, 2017)。
有监督学习即属于这种算法支持工具
(Osnabrügge, Ash & Morelli, 2021)。
研究人员手动创建一组特定任务的示例(训练数据),然后训练一个模型,以便在未见过的文本上重现任务。然而,这需要大量文本才能获得良好性能,在社会科学领域,
数据稀缺性
的问题尤其突出。
本文认为深度迁移学习可以缓解这种问题。迁移学习的主要假设是,
机器学习模型可以在预训练阶段学习“语言知识”和“任务知识”,并将这些“知识”存储在其参数中
(Pan & Yang, 2010; Ruder, 2019)。在随后的微调(fine-tuning)阶段,它们可以利用这些“先验知识”,以较少的数据学习新任务。即:模型的参数可以代表词概率的统计模式(“语言知识”),将词相关性与特定类别联系起来(“任务知识”),然后在新任务中重复使用这些参数表示(“知识迁移”)。
在政治学文献中,通过预训练的词嵌入使用浅层“语言知识”的做法越来越流行(Rodman, 2020; Rodriguez & Spirling, 2022),而对深层“语言知识”和
BERT
(Bidirectional Encoder Representations from Transformers,
基于Transformer的双向编码表征法
)等模型的研究,直到最近才开始在选定的任务中使用(Bestvater & Monroe, 2022;Licht, 2023;Widmann & Wich, 2022)。尚未发现有关“任务知识”的政治学文献。
本文在此基础上分析了迁移学习在与政治科学家相关的各种任务和数据集中的优势;“任务知识”作为迁移学习第二个组成部分的重要性;迁移学习对不平衡数据的影响;以及不同算法需要多少训练数据和人工注释。
为了检验迁移学习的理论优势,本文系统地比较了两种经典的有监督算法(支持向量机[SVM]和逻辑回归)和两种迁移学习模型(BERT-base和BERT-NLI)在八个任务上的表现,这些任务来自于五个被广泛使用的政治科学数据集。分析发现,在数据极少时,BERT-NLI的表现更好,相反BERT-base在数据更多时表现更好。二者均比经典模型性能更佳。此外,迁移学习对不平衡数据尤其有益。
最后,本文讨论了深度迁移学习的局限性,并概述了政治科学研究的新机遇。我们通过开源代码和通用BERT-NLI模型,本文为数据和模型的重用作出了重要的贡献。
二、迁移学习思维
政治科学中的有监督学习
有监督
机器学习项目通常以一个实质性研究问题开始,该问题要求在大型文本语料库上重复特定的分类任务,根据研究需要对成千上万条文本
进行主题、情感或其他概念类别的
分类
。其大致步骤包括:
通过反复讨论形成代码集,从而制定出量身定制的分类任务;通过人工标注较小的文本集(训练和测试数据)来执行分类任务;在这些人工标注的数据上训练和测试有监督机器学习模型,以重现人工标注任务;如果模型的输出获得所需的准确性和效度水平,则可用于在非常大的未见文本语料上自动重现任务。如果实施得当,通过自动注释创建的综合统计数据就能帮助回答实质性的研究问题。
政治学家通常使用一些有监督学习的
经典算法
,如SVM、逻辑回归、朴素贝叶斯等(Benoit, 2020)。它们计算效率高,在有大量注释数据的情况下性能良好(Terechshenko et. al, 2020)。它们的输入通常是文档-特征矩阵(document-feature matrix),该矩阵提供了训练语料库中每个文档的预处理词(特征)的加权计数。仅根据这一输入,这些模型尝试学习哪些特征(词)组合与特定类别(如“经济”主题)的关联度最高。
经典算法的主要缺点是在没有任何关于语言或任务的先验“知识”(包括“语言知识”和“任务知识”)的情况下开始训练过程
,因此需要以训练数据作为唯一的信息来源,从头开始学习这些语言模式和任务,只有在大量训练数据的情况下性能较好。
解决“语言知识”限制,与经典算法兼容的第一种方法是
词嵌入
(Mikolov et. al,2013)。单词嵌入表示在相似语境中经常被提及的向量(用以表示语义相似度)相近的单词,其可以作为分类器的输入特征,为它们提供一种“语言知识”,并在政治学领域大受欢迎(Rodman, 2020; Rodriguez & Spirling 2022)。然而,
单靠词语嵌入只能提供“浅层语言知识”
:
它们捕捉的信息有限,对经典算法的改进也仅仅是输入层的不同。
深度迁移学习
深度迁移学习试图通过将训练过程分成两个阶段来创建“先验知识”:
预训练(pre-training)和微调(fine-tuning)
(Howard & Ruder, 2018)。
首先,对算法进行预训练,学习各种领域(如新闻、书籍和博客)中语言模式的一些通用统计“知识”,创建语言模型。
其次,在注释数据上微调预训练模型以适应特定任务。
因此,迁移学习有两个重要组成部分(Pan & Yang, 2010; Ruder, 2019):
(1) 学习语言的统计模式(语言表征)和(2)学习相关任务(任务表征)。
这两类表征都存储在模型的参数中。
对于学习通用的语言表征,最突出的解决方案是
BERT
(Devlin et al., 2019),它是一种transformer(Vaswani et al., 2017)。像BERT这样的transformer首先要通过一个非常简单的任务进行预训练,比如不需要人工标注的掩码语言模型(masked language modeling, MLM)。在MLM中,模型会随机隐藏一些单词,并负责预测正确的隐藏单词。这一过程的总体目标是让模型参数学习语言的统计模式(语言表征),如单词的语义相似性或各种文本中与上下文相关的歧义。
虽然基于“语言知识”,使用BERT-base模型的性能可能大幅提高(Devlin et al., 2019),但对数据的要求仍然相对较高。例如,Widmann和Wich(2022)在一项情感检测任务中发现很强的性能提升,但他们指出,
训练数据量仍然是一个重要的限制因素,数据量较少的类表现不佳
。造成这种情况的一个重要原因是,BERT-base学习的预训练任务(MLM)与研究人员感兴趣的实际最终分类任务非常不同。这就是为什么BERT的最后一个特定任务层(为 MLM 调整的任务头)通常会被完全删除,并在微调前随机重新初始化——这构成了“任务知识”的重要损失。然后,BERT需要在人工标注的数据上进行微调,从头开始学习新的、有用的任务及其每个类别。
为了弥补BERT-base模型在“任务知识”上的损失,有人使用Transformer的先验“任务知识”的方法。
本文采用的是一种基于
自然语言推理(natural language inference, NLI)
的方法,该方法最早由 Yin, Hay和Roth(2019)提出,后经Wang等人(2021)改进。
NLI是一种任务和数据格式,由两个输入文本和三个输出类别组成。
输入文本是“语境(context)”和“假设(hypothesis)”
。
任务是根据上下文语境判断假设为真(true)、假(false)或中性(neutral)。
譬如,一个假设可以是“欧盟是值得信赖的”,语境是“欧盟在周日的谈判中背叛了它的合作伙伴”。在这种情况下,正确的分类是假,因为上下文语境与假设相矛盾
(见表1)
。NLI并非找出科学假设的客观真理,而只是要确定语境字符串是否推导出假设字符串。

表1
从迁移学习的角度来看,NLI 有三个重要特点:
数据丰富,通用性强,可以实现标签语言化。
第一,NLI是NLP中使用广泛、数据丰富的任务。现有许多NLI数据集,众包码农已经创建了超过一百万个独特的“假设-语境”对。利用这些数据,可以在NLI分类任务中进一步微调预训练的BERT-base,从而创建BERT-NLI。
第二,NLI 是一项通用任务。
经典算法或BERT-base
以训练数据作为任务信息的唯一来源,只能解决某个具体的研究任务,而
NLI可以将任何任务转换为通用格式
。方法是将
每个主题类别表述为“类别-假设”,例如“这是关于经济的”、“这是关于民主的”等,随后给予语境,例如
“我们需要提高关税”,来测试每个类别假设。
每一个语境-假设对(context-hypothesis pair)都作为
BERT-NLI的输入,输出则是每个类别-假设(class-hypothesis)的真/假/中性预测结果。然后,根据预测结果为“最真”(truest)的类别-假设对确定主题的分类(如图1)。
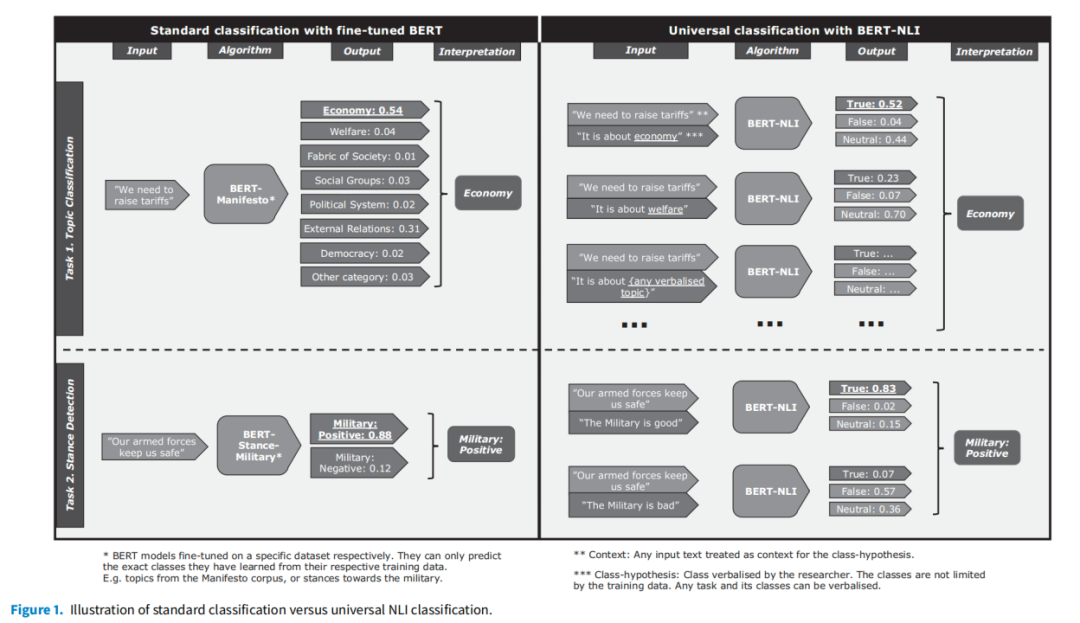
图1
第三,标签语言化(Schick & Schütze, 2021)。标准分类器(经典算法和BERT-base)只接收与相应类别的初始无意义数字相关联的示例,它们从未见过纯语言的类别描述,只能根据训练数据从统计学角度猜测底层分类任务是什么。有了NLI任务格式,就可以在基于代码集的假设中明确说出类别(见图1)。因此,BERT-NLI可以更贴近人工注释者,利用其先前的语言表征,更快地理解每个类别的含义。
数据和算法
本文选取了一组代表了政治科学家感兴趣的典型分类任务的数据集,它们在规模、领域、分析单位和特定任务的研究兴趣方面各不相同(见表2)。
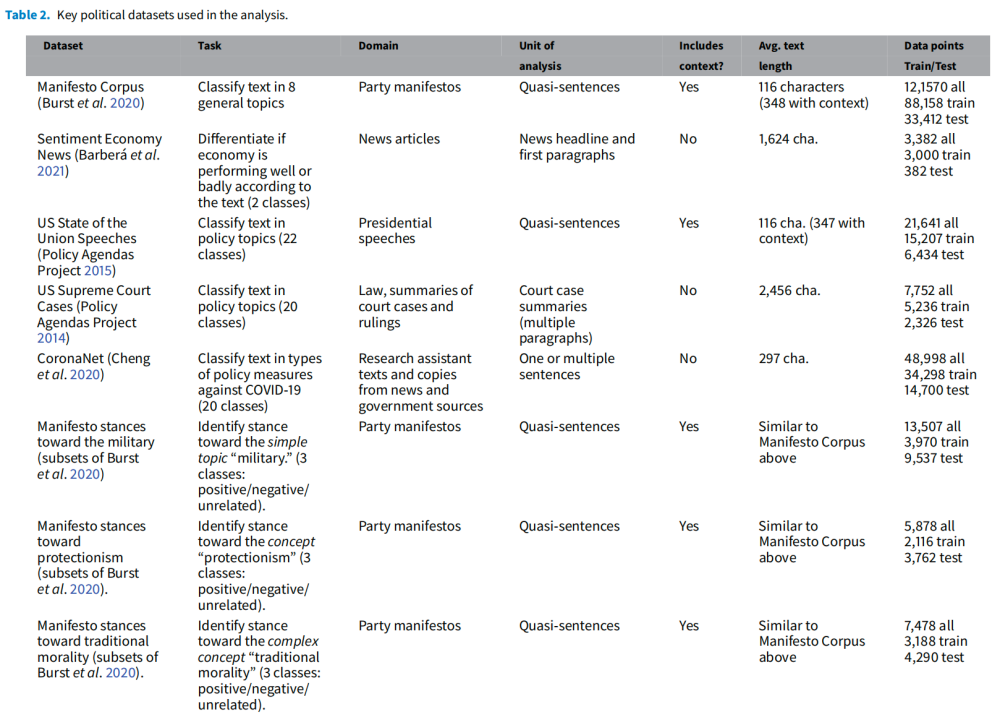
表2
对于所有数据集,人工编码的总体任务是将文本分类到多个预定义的实质性政治兴趣类别之一。对数据进行预处理,使分类器输入与人工注释者收到的输入更加一致。
在一些数据集中,分类的分析单位是从较长的演讲或政党宣言中提取的单个
准句子(quasi-sentence)
(Burst et al., 2020; Policy Agendas Project 2015)。这些准句子通常需要在阅读上下文后才进行解释。因此,受 Bilbao-Jayo和Almeida(2018)的启发,本文在超参数搜索过程中用两种类型的输入对每种算法进行了测试:只有单个注释的准句子,或准句子与其前后句子的串联。
本文比较了
经典算法(SVM和逻辑回归)
、
标准transformer模型(BERT-base)
和
使用了NLI的transformer模型(BERT-NLI)的结果
。其中:
(1)针对两种经典算法,分别对其测试两种类型的特征表示:TF-IDF向量化和平均词嵌入(如前所述,词嵌入提供了一种“浅层语言知识”);
(2)针对标准transformer模型,选择DeBERTaV3-base,它是在更多数据上训练的原始BERT的改进版本,具有比MLM更好的预训练目标和一些架构改进(He, Gao & Chen, 2021);
(3)针对使用NLI的模型,以现有的八个通用NLI数据集中的1.279.665 NLI假设-语境对微调DeBERTaV3-base。
本文共选取了三个评价指标:
精度
(
accuracy
)、
平衡精度
(
balanced accurracy
)和
F1 Macro
。
第一,精度计算的是正确预测的总体比例(相当于F1 Micro),缺点是高估了分类器的性能,
过度预测了多数类别而忽略了少数类别
。假定在大多数社会科学应用案例中,任务包含的所有类别的重要性大致相同,那么精度是一个误导性的性能指标。
第二,平衡精度分别计算每个类别的精度,然后取每个类别精度得分的平均值(相当于“Recall Macro”)。这样,所有类别的权重都相同,与类别的大小无关,而且假定类别具有相似的实质价值,因此是一个更合适的指标。不过,假阴性(高“Recall”)较少的分类器的准确度较高,但没有适当考虑假阳性(“Precision”较低的风险)。因此
平衡精度更适合对少数类别预测较好,但对少量的多数类别预测较差的分类器
。
第三,F1 Macro是精确度和召回率的调和平均数,
对所有类别给予同等权重,且与类别的大小无关
。对于有监督机器学习的许多社会科学用例来说,F1 Macro是最合适的指标。
结果
图2显示了所有数据集的总平均分,图3显示了每个数据集的结果。
本文主要整体数据效率和处理不平衡数据的能力。
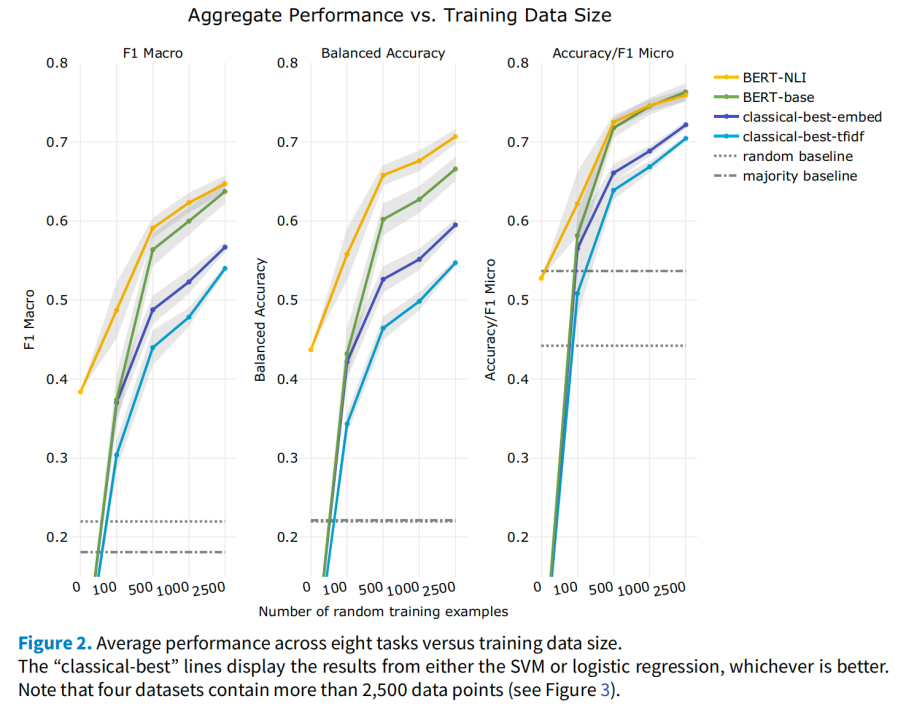
图2
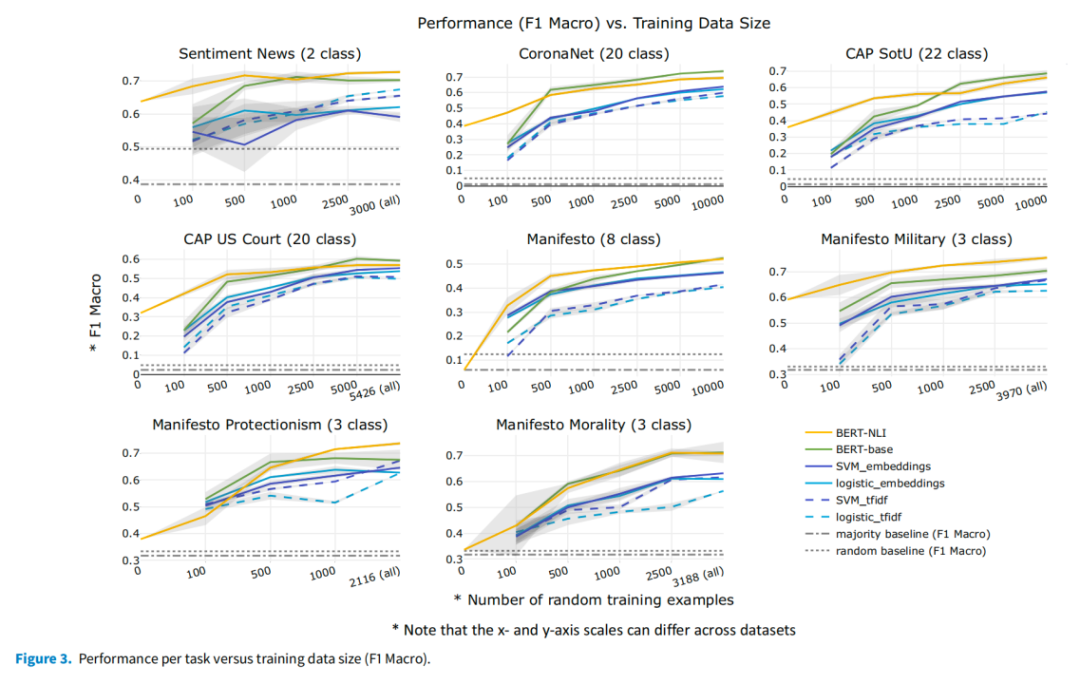
图3
在数据效率方面,
在所有任务中,
深度迁移学习模型在数据较少的情况下的表现都明显优于经典模型
。结果表明,当有100到2,500个注释数据点时,BERT-NLI的性能比经典的TF-IDF的性能平均高出10.7到18.3个百分点(F1 Macro)(BERT-base为7.9到12.4)。通过利用平均词嵌入的“浅层语言知识”,经典模型可以得到改进,但F1 Macro的差异仍为8.0到11.7(使用BERT-base时为0.4到7.7)。BERT-NLI在500个数据点时的平均F1 Macro性能与经典模型在约5,000个数据点时相近。随着采样数据量的增加(5,000-10,000 个),性能差异依然存在,并且适用于不同领域、分析单位和任务。
模型使用的迁移学习组件越多,处理不平衡数据的能力就越强。
通过比较accuracy/F1 Micro和F1 Macro在100到2,500个数据区间的平均值,发现F1 Macro的改进幅度更大,表明处理不平衡数据的能力得到了提高。在经典模型中加入词嵌入的“浅层语言知识”时,F1 Macro被提升了+4.6个百分点,而accuracy/F1 Micro仅被提升了+2.9——F1 Macro比accuracy/F1 Micro的提升高出了+1.7。使用BERT-base及其“深度语言知识”,比经典TF-IDF的accuracy/F1 Micro提高了+7.2个百分点,F1 Macro被提升了+10.3 个百分点——差值为+3.1。使用BERT-NLI及其附加“任务知识”后,accuracy/F1 Micro提高了+8.3,F1 Macro提高了+14.6——差值为+6.3。差值越大,表明迁移学习越少依赖于多数类。
由于对文本的同义词和语义相似度的先验表示(“语言知识”),两种BERT(和词嵌入)对少数类别使用的词所需的示例较少。BERT-NLI在F1 Macro特别是平衡精度上表现更好,且性能在不同类别之间差异最小,其先验的“任务知识”进一步减少了对较小类别数据的需求。
在BERT-base和BERT-NLI之间选择时,主要标准是数据量和不平衡的程度。
BERT-NLI适用于可用数据较少(≤1,000)且非常不平衡的情况,
在(大量的)少数群体类别上表现更好,而在(少量的)多数群体类别上表现较差。
随着从头开始学习新任务(和少数类别)的数据越来越多,考虑到收敛性能,应该使用更简单的BERT-base模型(≥2,000)。另一个会影响BERT-NLI价值的数据集特征是
概念复杂度(concept complexity)
。当测量的概念可以在假设中清晰表达时,BERT-NLI的效果更好。例如,BERT-NLI在“宣言-军事”任务中的表现尤为出色,它测量的是对相对简单的主题“军事”的态度。然而,它在“宣言-道德”任务中的表现则相对较差,该任务测量的是复杂的概念“传统道德”,它涵盖了从传统家庭价值观、宗教道德价值观到“不体面行为”等不明确概念的多个子维度。可见,
BERT-NLI更难将假设中的简单语言映射到复杂概念上
。
最后,超参数和文本预处理对所有模型的性能都有重要影响。例如,虽然BERT-base模型的训练时间通常少于10轮,但在小型数据集上,训练时间长达100轮会提高性能。此外,在预处理方面,如果分析单位是准句子,那么在预处理过程中加入前后句可以系统地提高所有模型的性能;通过对平均嵌入值进行重新加权,并使用词性标注筛选更重要的词,可以提高词嵌入值;通过简单的预处理步骤,可以提高BERT-NLI的性能。
首先,深度学习模型的计算速度较慢,需要特定的硬件。类似
BERT
的
transformer
需要几分钟到几个小时才能在高性能
GPU
上进行微调,而经典模型在笔记本电脑
CPU
上几分钟就能完成训练。本文提供了选择正确超参数的经验和一组在不同任务和数据规模下都表现良好的标准超参数,可以缓解这一点。










