出品 | AI科技大本营(ID:rgznai100)
曾经,你有没有因为学习与使用 Pandas 进行数据检索等操作而感到厌烦过?
实现同样的功能,Pandas 给用户提供了很多种方法,不少老手开发者们在这么多选择下要乐开花了。但对于初学者来说,情况却恰好相反,即使是一个很简单的操作有时对于他们来说,理解 Pandas 语法可能都是件挺困难的事情。
Bamboolib 的开发者们提出了一个解决问题的好办法 —— 给 Pandas 增加一个 GUI。
我们希望大家“不用写任何代码也可以学习和使用 Pandas”,可以办到吗?接下来,本文就从数据设置及使用 Bamboolib 内容入手,带领大家一起体验这个新鲜奇妙之旅。
安装 Bamboolib 的方式非常简单,一键 pip
为了能让 Bamboolib 与 Jupyter 和 Jupyterlab 在一起运行,还需要安装一些额外的扩展插件,如通过以下的命令安装 Jupyter Notebook 的扩展包:
jupyter nbextension enable --py qgrid --sys-prefixjupyter nbextension enable --py widgetsnbextension --sys-prefixjupyter nbextension install --py Bamboolib --sys-prefixjupyter nbextension enable --py Bamboolib --sys-prefix
要检查是否安装成功,可以打开 Jupyter 记事本,并执行如下命令:
import Bamboolib as bam import pandas as pd data = pd.read_csv(bam.titanic_csv)bam.show(data)
第一次运行这个命令的时候,系统将会要求你提供许可。如果要在 Bamboolib 上使用自己的数据,也需要许可。
Bamboolib 被激活后就可以开始使用了。大家可以通过以下的方式来查看 Bamboolib 的执行结果,还可以选择使用其它的一些选项。
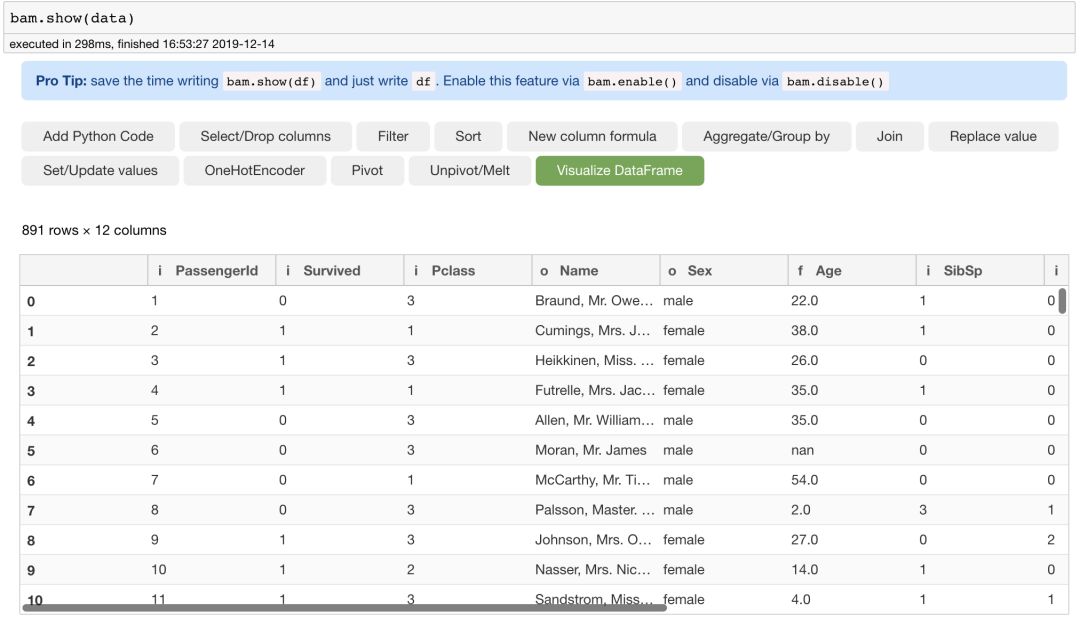
现在,我们尝试在 Bamboolib 中用自己的数据源,看到了大量的 Titanic 数据。
这里使用的是 Kaggle 提供的手机价格分类数据(Mobile Price Classification data)。基于此问题,我们需要创建一个分类器:根据手机的特点来预测价格范围。
train = pd.read_csv("../Downloads/mobile-price-classification/train.csv") bam.show(train)
用一个 bam.show(train)的简单调用来启动 Bamboolib。
Bamboolib 对检索性数据分析有很大的帮助。现如今,数据检索是任何数据科学研究的重要组成部分。为了进行数据检索和创建所有的图表而编写代码是相当麻烦的,需要付出很多的时间和努力,Bamboolib 如何让整个数据检索工作变得轻而易举?
在 Bamboolib 中,如果点击“Visualize Dataframe”按钮的话,就可以得到以下的数据了,如下图所示:
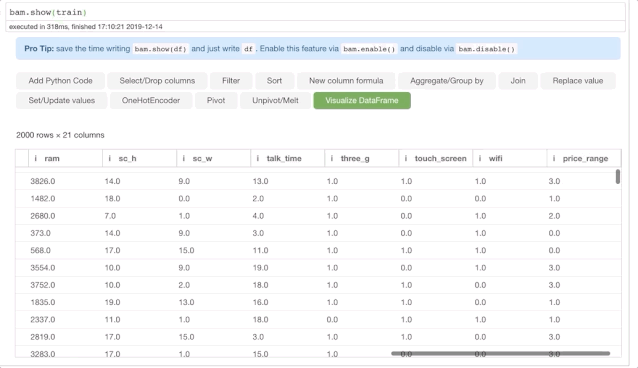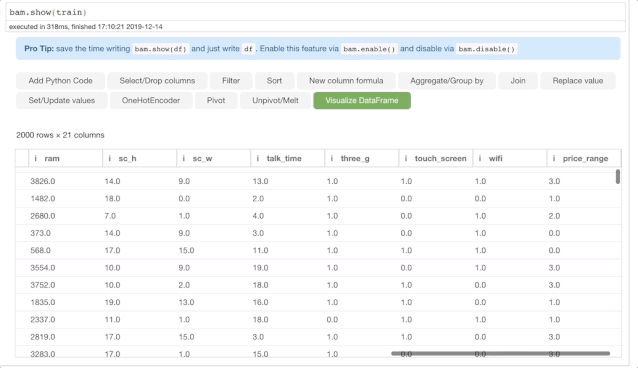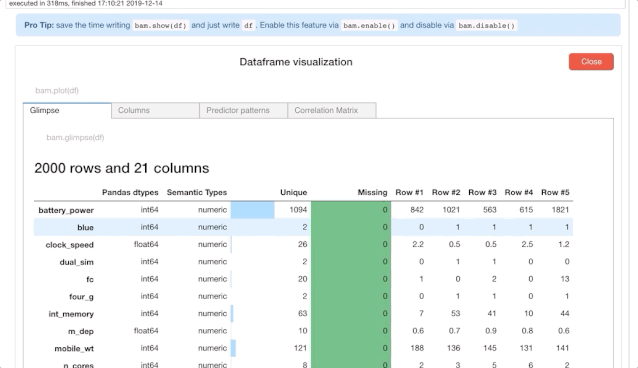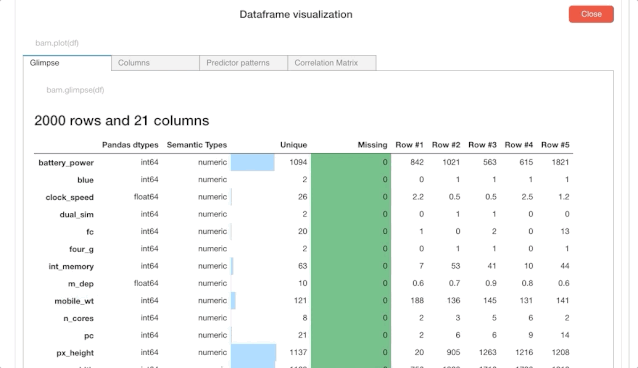
我们会从上面的结果中看到每一列中的缺失值,以及唯一值和实例的数量。
但这还不够,我们还可以得到单变量列级的统计量和信息。然后,我们再深入了解一下目标变量——价格范围(Price Range)。
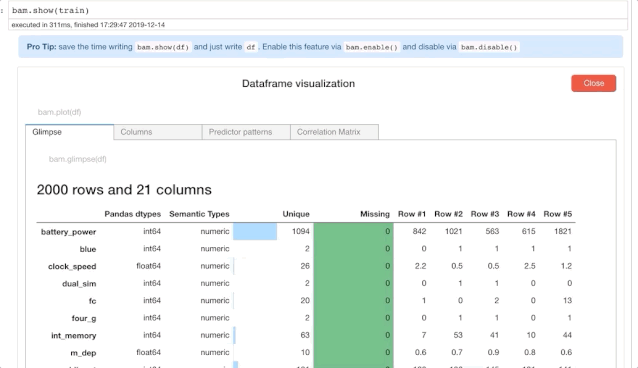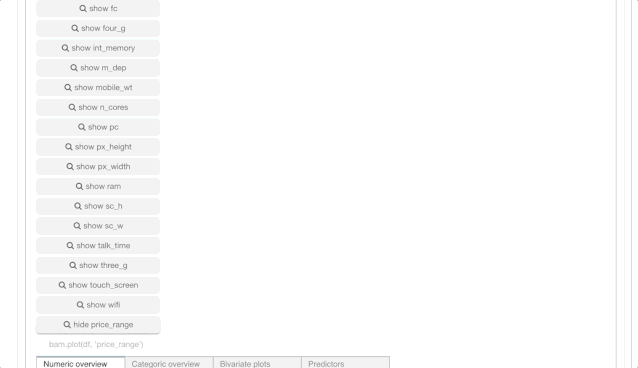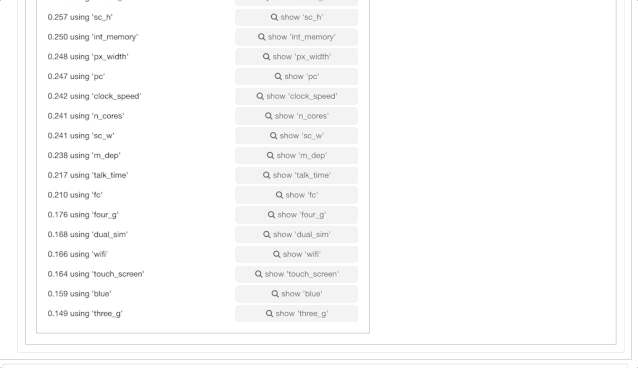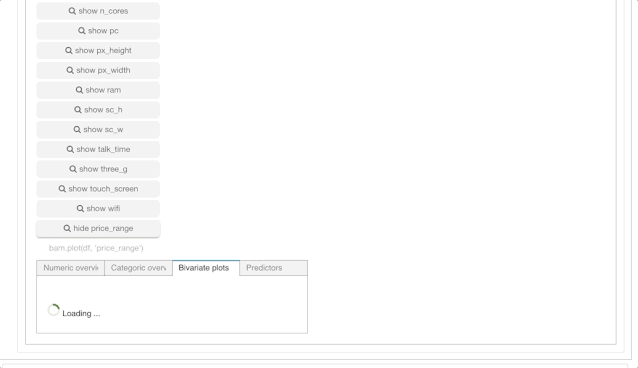
从这里深入到目标列,可以看到单变量列统计信息以及对于目标列的最重要的预测因素,看起来手机内存和电池电量是影响预测价格范围最重要的因素。
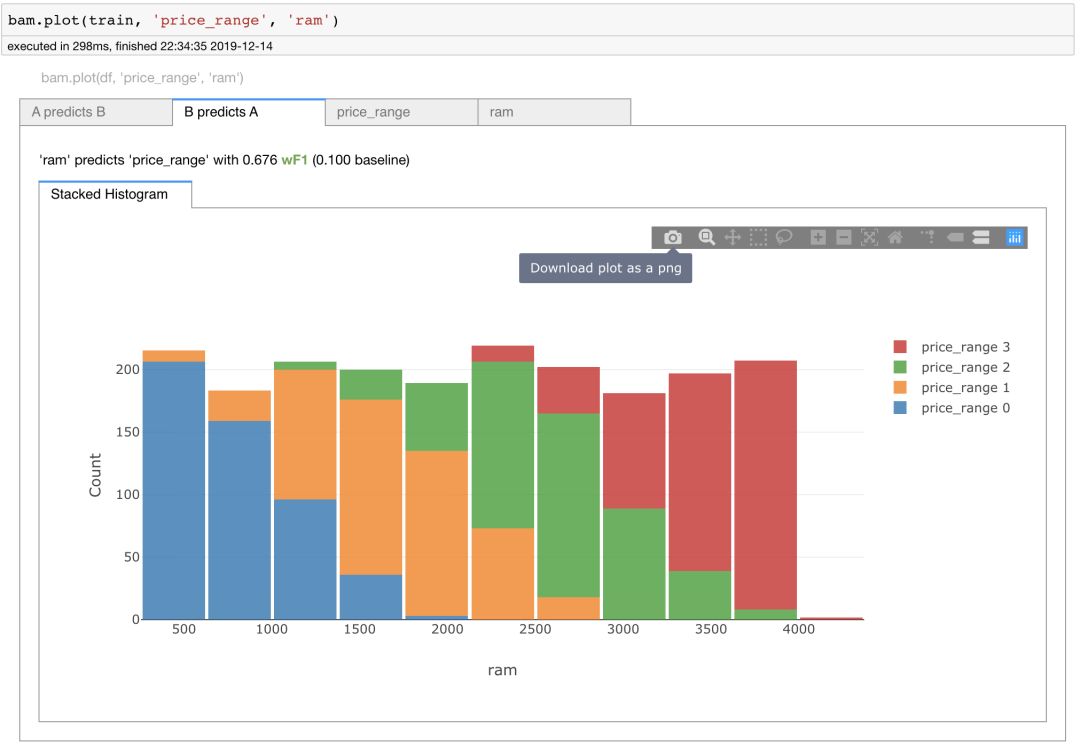
内存是如何影响价格范围的?可以用一个二元图来表示。
使用标准的 Python 库(如 seaborn 或 plotly)获得上面这么漂亮的图表通常都会需要一定的代码开发量。plotly_express 为大多数的图表绘制提供了一些简单的功能,但 Bamboolib 会自动为我们创建许多各种各样的图表。
从上面的图中,我们可以看到,随着手机内存容量的增加,价格范围也在不断地扩大。我们还看到内存变量的加权 F1 分数为 0.676。你可以对数据集里面的每个变量都执行这个操作,并尝试分析这些数据。
当然,还可以导出这些图表的代码,以便在某些文档展示中使用,这些图表导出的是 PNG 格式的文件。
上述操作只需复制显示在每个图表上方的代码片段即可。例如,可以通过运行导出的代码,以图表的形式展现 price_range 和 ram 这两个列,你就会看到一个将这些图表以 PNG 格式下载的选项。
bam.plot(train, 'price_range', 'ram')
你有没有遇到过这样的情况:突然忘了某段 pandas 代码用来实现什么功能了,并且还出现了内存溢出,而且在不同的线程中找不到了。如果有的话,这里有一个 Pandas 的小窍门儿。
通过 Bamboolib,你要做的事情变得非常容易,并且不会被复杂的代码搞得晕头转向。通过使用简单的 GUI,你可以进行删除、筛选、排序、联合、分组、视图、拆分(大多数情况下,你希望对数据集执行的操作)等操作。
例如,这里我将删除目标列中的多个缺失值(如果有的话)。当然,还可以添加多个条件。
最好的功能就是,Bamboolib 也提供了代码。如下所示,用于删除缺失值的代码将会自动添加到单元格中。
train = train.loc[train['price_range'].notna()]train.index = pd.RangeIndex(len(train))
其实它用起来就跟微软的 Excel 一样,还为高级用户提供了数据切片和分块的所有代码。你也可以根据自己的喜好使用 Bamboolib。
train = train.groupby(['price_range']).agg({'battery_power': ['mean'], 'clock_speed': ['std']}) train.columns = ['_'.join(multi_index) for multi_index in train.columns.ravel()] train = train.reset_index()
你可以看到它是如何处理 multi_index 和 ravel 这两个列的。
Bamboolib 的 GUI 做的非常直观,在工作中使用它绝对是一种乐趣。这个项目目前还处于初始阶段,但已经有了一个非常不错的开始。
确切地说,Bamboolib 对于那些想要学习使用 Pandas 来编写代码的初学者来说是非常有用的,让他们不费吹灰之力就可以访问到所有的函数。
同时大家也需要继续了解 Pandas 的一些基本功能,为了更好地学习 Pandas,也可以尝试大家多看一下使用 Bamboolib 之后的输出结果,让我们一起来期待未来 Bamboolib 还会发生哪些变化。
https://towardsdatascience.com/bamboolib-learn-and-use-pandas-without-coding-23a7d3a94e1
(*本文为AI科技大本营编译文章,
转载
请
微信联系 1092722531)










