引言
机器学习(Machine Learning, ML)可以认为是:通过数据,算法使得机器从大量历史数据中学习规律,从而对新样本做分类或者预测。它是人工智能(Artificial Intelligence, AI)的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域,主要使用归纳、综合的方法获取或总结知识。
很多高校已经开设机器学习这一课程,作为一门交叉领域学科,它涉及到概率论,统计学,凸分析,最优化,计算机等多个学科。专门研究计算机怎样模拟或实现人类的学习行为,从而获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
本文将以时间为顺序,从两个大阶段介绍机器学习,第一部分介绍浅层学习阶段,第二部分介绍深层学习阶段,就是所谓的深度学习。
Arthur Samuel
1959年,IBM的写出了可以学习的西洋棋程序,并在 IBM Journal of Research and Development期刊上发表了一篇名为《Some Studies in Machine Learning Using the Game of Checkers》的论文中,定义并解释了一个新词——机器学习(Machine Learning,ML)。将机器学习非正式定义为”在不直接针对问题进行编程的情况下,赋予计算机学习能力的一个研究领域”。
1957年,Rosenblatt发明了感知机(或称感知器,Perceptron)[1],是神经网络的雏形,同时也是支持向量机的基础,在当时引起了不小的轰动。感知机是二类分类的线性分类模型,其输入为实例的特征向量,输出为实例的类别,取+1和-1二值。感知机对应于输入空间(特征空间)中将实例划分为正负两类的分离超平面,属于判别模型。感知机学习旨在求出将训练数据进行线性划分的分离超平面。
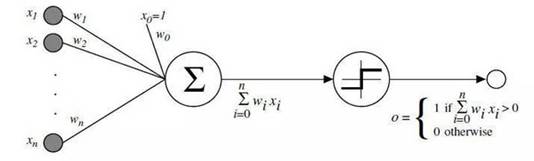
其实设计感知器的初衷是制造一个识别用的机器,而不是一个算法。虽然它的第一次实现是在IBM704上安装的软件中,但它随后在定制的硬件实现“Mark1感知器”。这台机器是用于图像识别,它拥有一个容量为400的光电池阵列,随机连接到“神经元”,连接权重使用电位编码,而且在学习期间由电动马达实施更新。

1960年,Widrow发明了Delta学习规则,即如今的最小二乘问题,立刻被应用到感知机中,并且得到了一个极好的线性分类器。Delta学习规则是一种简单的有导师学习算法,该算法根据神经元的实际输出与期望输出差别来调整连接权,其数学表示如下: 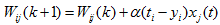
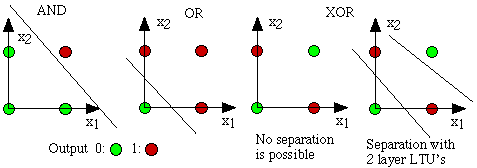
 1969年,Minskey提出了著名的XOR问题[2],论证了感知器在类似XOR问题的线性不可分数据的无力,以至于其后十年被称为“冷静时期”,给感知机画上了一个逗号,以洪荒之力将如火如荼将的ML暂时封印了起来。Rosenblatt在这之后两年郁郁而终与此也不无关系,虽然当时Rosenblatt才43岁,虽然Rosenblatt死于游艇意外事故……
1969年,Minskey提出了著名的XOR问题[2],论证了感知器在类似XOR问题的线性不可分数据的无力,以至于其后十年被称为“冷静时期”,给感知机画上了一个逗号,以洪荒之力将如火如荼将的ML暂时封印了起来。Rosenblatt在这之后两年郁郁而终与此也不无关系,虽然当时Rosenblatt才43岁,虽然Rosenblatt死于游艇意外事故……
1970年,Seppo Linnainmaa首次完整地叙述了自动链式求导方法(Automatic Differentiation,AD)[3],是著名的反向传播算法(Back Propagation,BP)的雏形,但在当时并没有引起重视。
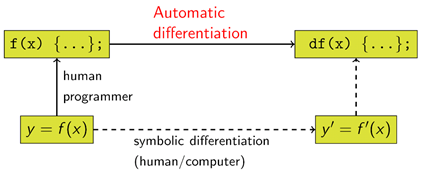
1974年,Werbos首次提出把BP算法的思想应用到神经网络,也就是多层感知机(Multilayer Perception,MLP)[4],并在1982年实现[5],就是现在通用的BP算法,促成了第二次神经网络大发展。MLP或者称为人工神经网络(Artificial Neural Network,ANN)是一个带有单隐层的神经网络。
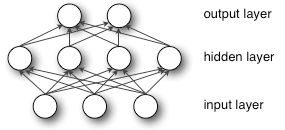
1985-1986年,Rumelhart,Hinton等许多神经网络学者成功实现了实用的BP算法来训练神经网络[6][7],并在很长一段时间内BP都作为神经网络训练的专用算法。

1986年,J.R.Quinlan提出了另一个同样著名的ML算法——决策树算法(ID3)[8],决策树作为一个预测模型,代表的是对象属性与对象值之间的一种映射关系,而且紧随其后涌现出了很多类似或者改进算法,如ID4,回归树,CART等。
ID3算法是一种贪心算法,用来构造决策树。ID3算法起源于概念学习系统(CLS),以信息熵的下降速度为选取测试属性的标准,即在每个节点选取还尚未被用来划分的具有最高信息增益的属性作为划分标准,然后继续这个过程,直到生成的决策树能完美分类训练样例。
1995年,Yan LeCun提出了卷积神经网络(Convolution Neural Network,CNN)[14],受生物视觉模型的启发,通常有至少两个非线性可训练的卷积层,两个非线性的固定卷积层,模拟视觉皮层中的V1,V2,Simple cell和Complex cell,在手写字识别等小规模问题上,取得了当时世界最好结果,但是在大规模问题上表现不佳。

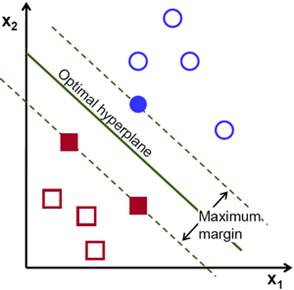
1995年,Vapnik和Cortes提出了强大的支持向量机(Support Vector Machine,SVM)[9],主要思想是用一个分类超平面将样本分开从而达到分类效果,具有很强的理论论证和实验结果。至此,ML分为NN和SVM两派。
1997年,Freund和Schapire提出了另一个坚实的ML模型AdaBoost[10],该算法最大的特点在于组合弱分类器形成强分类器,可以形象地表述为:“三个臭皮匠赛过诸葛亮”,分类效果比其它强分类器更好。

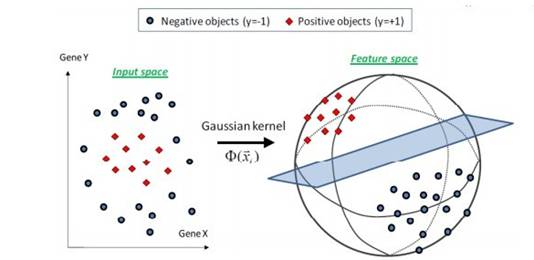
2001年,随着核方法的提出[12],SVM大占上风,它的主要思想就是通过将低维数据映射到高维,从而实现线性可分。至此,SVM在很多领域超过了NN模型。除此之外,SVM还发展了一系列针对NN模型的基础理论,包括凸优化、范化间隔理论和核方法。
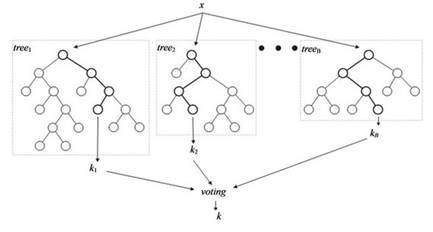
2001年,Breiman提出了一个可以将多个决策树组合起来的模型随机森林(Random Forest,RF)[11],它可以处理大量的输入变量,有很高的准确度,学习过程很快,不会产生过拟合问题,具有很好的鲁棒性。
具体来说,随机森林就是由多棵CART(Classification And Regression Tree)构成的。对于每棵树,它们使用的训练集是从总的训练集中有放回采样出来的,这意味着,总的训练集中的有些样本可能多次出现在一棵树的训练集中,也可能从未出现在一棵树的训练集中。在训练每棵树的节点时,使用的特征是从所有特征中按照一定比例随机地无放回的抽取的
2001年,Hochreiter发现使用BP算法时,在NN单元饱和之后会发生梯度损失(梯度扩散)[17]。简单来说就是训练NN模型时,超过一定的迭代次数后,容易过拟合。NN的发展一度陷入停滞状态。
2006年,Hinton和他的学生在《Nature》上发表了一片文章[13] ,同一年另外两个团队也实现了深度学习[15][16],从此开启了深度学习(Deep Learning)阶段,掀起了深度神经网络即深度学习的浪潮。
Hinton在2006年提出的深度置信网络(Deep Belief Network,DBN)开启了深度学习新纪元,他提出了用神经网络给数据降维,就是所谓的稀疏化编码或者自动编码。他提出了一个新的神经网络模型叫做深度置信网络(Deep Belief Network,DBN),该网络可以看作是限制玻尔兹曼机像垒积木一样一层一层垒起来的。
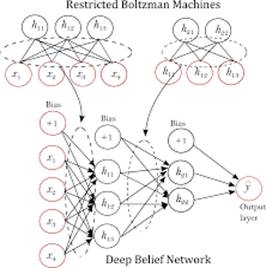
限制玻尔兹曼机(Restricted Boltzmann Machine,RBM)是一个简单的双层神经网络,只有输入、输出层,没有隐层,并且层间全连接,层内无连接。训练RBM的时候用的是一个能量函数,由于无法使用梯度下降等常用算法训练最好的连接权重矩阵,采用Gibbs采样等方法分批次进行训练,训练好的RBM可以看作输出层对输入层的特征提取。
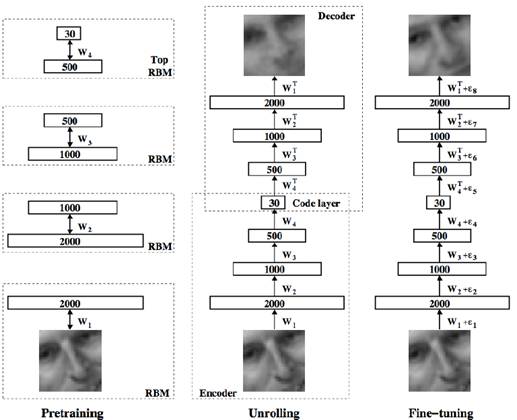
RBM训练好之后把它们垒在一起就是DBN的初始权重,之后对DBN进行训练,这个过程称为DBN的预训练,如图1所示。
预训练阶段结束之后就是调优的过程,该过程也可称为Wake-Sleep过程,包括正向的前馈(Feed Forward,FF)过程和反向传播(Back Propagation,BP)过程,前馈过程是改每一层的数据,反向传播过程是修改权重矩阵,这样反复调优,一直到输出值和预期值误差最小。
2009年,微软研究院和Hinton合作研究基于深度神经网络的语音识别,历时两年取得成果,彻底改变了传统的语音识别技术框架,使得相对误识别率降低25%。
2012年,Hinton又带领学生在目前最大的图像数据库ImageNet上,对分类问题取得了惊人的结果,将Top5错误率由26%大幅降低至15%。ImageNet 是一个计算机视觉系统识别项目,是目前世界上图像识别最大的数据库。是美国斯坦福的计算机科学家,模拟人类的识别系统建立的。能够从图片识别物体。

2012年,由人工智能和机器学习顶级学者Andrew Ng和分布式系统顶级专家Jeff Dean领衔的梦幻阵容,开始打造Google Brain项目,用包含16000个CPU核的并行计算平台训练超过10亿个神经元的深度神经网络,在语音识别和图像识别等领域取得了突破性的进展[4]。该系统通过分析YouTube上选取的视频,采用无监督的方式训练深度神经网络,可将图像自动聚类。在系统中输入“cat”后,结果在没有外界干涉的条件下,识别出了猫脸。

2012年,微软首席研究官Rick Rashid在21世纪的计算大会上演示了一套自动同声传译系统[5],将他的英文演讲实时转换成与他音色相近、字正腔圆的中文演讲。同声传译需要经历语音识别、机器翻译、语音合成三个步骤。该系统一气呵成,流畅的效果赢得了一致认可,深度学习则是这一系统中的关键技术。
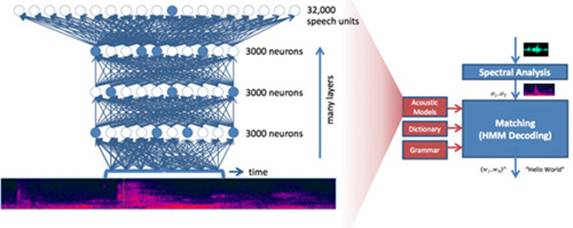
2013年,Google收购了一家叫DNN Research的神经网络初创公司,这家公司只有三个人,Geoffrey Hinton和他的两个学生。这次收购并不涉及任何产品和服务,只是希望Hinton可以将深度学习打造为支持Google未来的核心技术。同年,纽约大学教授,深度学习专家Yann LeCun加盟Facebook,出任人工智能实验室主任[6],负责深度学习的研发工作,利用深度学习探寻用户图片等信息中蕴含的海量信息,希望在未来能给用户提供更智能化的产品使用体验。
2013年,百度成立了百度研究院及下属的深度学习研究所(IDL),将深度学习应用于语音识别和图像识别、检索,以及广告CTR预估(Click-Through-Rate Prediction,pCTR),其中图片检索达到了国际领先水平。2014年又将Andrew Ng招致麾下,Andrew Ng是斯坦福大学人工智能实验室主任,入选过《时代》杂志年度全球最有影响力100人,是16位科技界的代表之一。

2014年,谷歌宣布其首款成型的无人驾驶原型车制造完毕,将会在2015年正式进行路测。
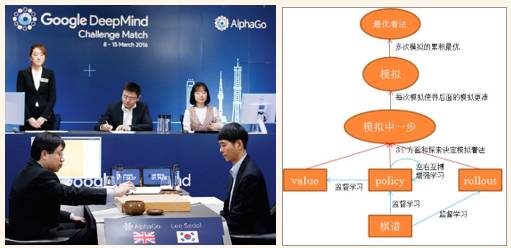
2016年,谷歌旗下DeepMind公司开发的人工智能程序AlphaGo击败围棋职业九段选手李世石。AlphaGo这个系统主要由几个部分组成[18]:
(1)走棋网络(Policy Network),给定当前局面,预测/采样下一步的走棋。
(2)快速走子(Fast rollout),目标和(1)一样,但在适当牺牲走棋质量的条件下,速度要比(1)快1000倍。
(3)估值网络(Value Network),给定当前局面,估计是白胜还是黑胜。
(4)蒙特卡罗树搜索(Monte Carlo Tree Search,MCTS),把以上这三个部分连起来,形成一个完整的系统。
参考文献:
[1] Rosenblatt, Frank. “The perceptron: a probabilistic model for information storage and organization in the brain.” Psychological review 65.6 (1958): 386.
[2] Minsky, Marvin, and Papert Seymour. “Perceptrons.” (1969).
[3] Seppo Linnainmaa. The representation of the cumulative rounding error of an algorithm as a Taylor expansion of the local rounding errors. Master's Thesis (in Finnish), Univ. Helsinki, (1970): 6-7.
[4] Paul Werbos. Beyond regression: New tools for prediction and analysis in the behavioral sciences. PhD thesis, Harvard University (1974).
[5] Paul Werbos . Applications of advances in nonlinear sensitivity analysis. In System modeling and optimization (pp. 762-770). Springer Berlin Heidelberg(1982).
[6] Rumelhart, David E.; Hinton, Geoffrey E.; Williams, Ronald J. (8 October 1986). "Learning representations by back-propagating errors". Nature 323 (6088): 533–536.
[7] Hecht-Nielsen, Robert. “Theory of the backpropagation neural network” Neural Networks, 1989.IJCNN. International Joint Conference on. IEEE, 1989.
[8] Quinlan, J. Ross. “Induction of decision trees.” Machine learning 1.1 (1986): 81-106.
[9] Cortes, Corinna, and Vladimir Vapnik. “Support-vector networks.” Machine learning 20.3 (1995): 273-297.
[10] Freund, Yoav, Robert Schapire, and N. Abe. “A short introduction to boosting.” Journal-Japanese Society for Artificial Intelligence 14.771-780 (1999): 1612.
[11] Breiman, Leo. “Random forests.” Machine learning 45.1 (2001): 5-32.
[12] Andre Elisseeff and Jason Weston. “A kernel method for multi-labelled classification” (2001)
[13] Hinton, Geoffrey E., Simon Osindero, and Yee-Whye Teh. “A fast learning algorithm for deep belief nets.” Neural computation 18.7 (2006): 1527-1554.
[14] LeCun, Yann, and Yoshua Bengio. “Convolutional networks for images, speech, and time series.” The handbook of brain theory and neural networks3361 (1995).
[15] Bengio, Lamblin, Popovici, Larochelle, “Greedy Layer-Wise Training of Deep Networks”, NIPS’2006.
[16] Ranzato, Poultney, Chopra, LeCun ” Efficient Learning of Sparse Representations with an Energy-Based Model “, NIPS’2006.
[17] Hochreiter, S., Bengio, Y., Frasconi, P., and Schmidhuber, J. A field guide to dynamical recurrent network, chapter Gradient flow in recurrent nets. IEEE Press, 2001.
[18] Silver D, Huang A, Maddison C J, et al. Mastering the game of Go with deep neural networks and tree search.[J]. Nature, 2016, 529(7587):484-489.








