大家好!今天
再推出一篇
泡泡机器人成员付兴银精心创作的原创文章:RGB-D实时重建那点事,带我们走进RGB-D实时重建的世界!
希望这篇干货能够让大家有所收获!
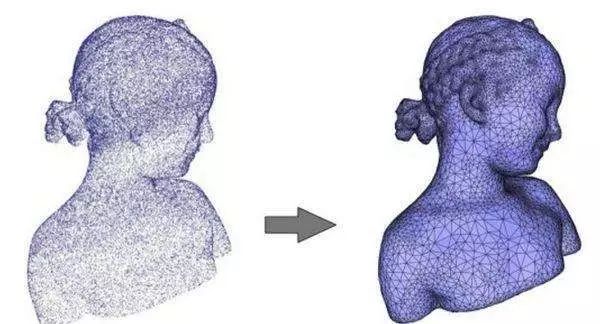
基于
RGB-D
的三维重建要从
RGB-D
相机说起,微软早在
2010
年就把
Kinect
折腾出了,
2011
年发布了
Kinect SDK
,
2012
年发布了可以用来做开发的
Kinect
版本(可以拿来做学术研究),
2011
年
SIGGRAPH
会议上,微软展示了
KinectFusion
实时重建算法,也就是说做研究的内部人员早就开始拿着
Kinect
玩了。
KinectFusin
算法是鼎鼎大名的
Newcombe
、
Davison
和微软的部分研究人员提出来的,
Newcombe
提出单目实时稠密重建算法
DTAM [1]
,
RGB-D
实时稠密重建
KinectFusion
算法
[2]
,和动态非刚体(
4D
)重建
DynamicFusion
算法
[3]
,几个工作在小领域都是开山大作。
Davison
是
Newcombe
导师,在
SLAM
领域是开山鼻祖级人物
。在
RGB-D
相机出现之前,采用普通相机很难实现实时稠密重建的(基于高精度结构光可以),也可以说
KinectFusion
算法首次实现了基于廉价消费类相机的实时刚体重建,把实时三维重建推到可以商业化的地步,也使得实时三维重建这个学科的基础研究,可以支撑得起微软
Hololens
,
Facebook Oculus AR
产品的应用需求。关于
KinectFusion
算法不再多说,前面泡泡有讲,也可以参照博客
[4]
。

在学术界,KinectFusion算法一经展示,大家一看,哇,效果这么好,好了,游戏规则变了,人家用深度传感器直接测深度做实时重建,你用普通的单目脱了鞋也追不上,而且这阵势明显离商业化不远了,一块大肥肉来袭。
话说KinectFusion算法虽然出的早,框架确实好,也不愧是顶级大牛的工作,2011年以来学术界基于RGB-D刚体重建提出了许多工作,但是基本框架都差不太多,如果看大牛们发表的论文,到2013年,做学术研究的顶级大牛们觉得这块的大块肥肉基本被分割没了,转而开始做动态非刚体重建,2014年斯坦福大牛的工作[5]只能完成变化小的非刚体的重建,2015年Newcombe提出的DynamicFusion算法重建动态非刚体,重建的非刚体只能缓慢变化,2016年出现的Fusion4D算法[7],采用多个深度相机,可以重建快速变化的非刚体,也使得非刚体重建可以达到商业化地步,视频序列可以记录变换着的2维的数据,4D动态非刚体重建可以记录变化着的3维数据!
再把目光投回到刚体重建,话说KinectFusion算法开辟了RGB-D实时重建的时代(只用到深度相机),但是SLAM中每个算法都注定是不完美的,你不完美,我就要完善你,大牛们先把大块的补丁补补。
KinectFusion算法用TSDF模型表示重建好的三维场景,TSDF模型也可以参照博客[4],TSDF模型在表示重建的场景时,把场景均匀划分,那我场景大的时候怎么办?采用TSDF模型重建大场景只能增大显存或者缩小网格的密度了,而显存是固定的,网格密度低了重建的精度就差,而且TSDF模型是采用GPU遍历每个网格点进行更新,当分配的网格点多时,更新速度会慢。
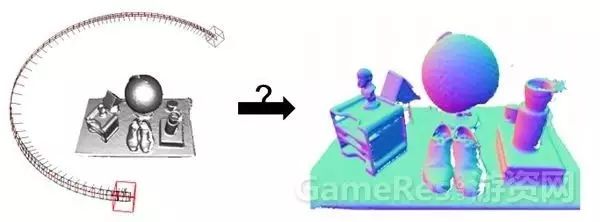
13年SIGGRAPH出的两篇文章[8-9],解决TSDF模型显存消耗和计算消耗的问题,Voxel Hashing [8] 因为算法开源,而且模型更新速度快,显存耗费资源少,在业内广为人知,牛津大学的工作InfiniTAM [10]也是对[8]的改进(算法开源)。Surfel模型是实时三维重建另一个比较常用的三维表示模型,Srufel模型可以参考ElasticFusion算法[15]或者博客[17]。
KinectFusion采用ICP算法估计两帧之间的位姿,在估计位姿时只用到深度图像,采用点云配准的方式计算两帧之间的位姿变换。ICP算法在匹配两幅点运时,需要赋予初始值,而在实时三维重建中,两帧之间的位姿变换小,新获取帧的位姿用上一帧的位姿初始化。
KinectFusion算法和一般SLAM或者VO/VIO算法不同的是,在估算位姿时,将当前帧获取的深度图像和从模型投影获取的深度图像进行配准,这种配准方式被称为frame-to-model,具体可以参见KinectFusion论文和KinectFusion博客,采用frame-to-model的方式配准,比传统意义上的SLAM算法位姿估计和模型重建都更加准确,具体参见KinectFusion论文。
而且这种frame-to-model的方式在近年提出的基于RGB-D的重建算法中被广泛采用(在论文里成为标准化的算法)。

既然说到SLAM,这里阐述下实时三维重建和SLAM的异同(个人观点),一般意义下的SLAM//VO/VIO算法(PTAM、ORB-SLAM、DVO-SLAM、LSD、DSO、SVO、OKVIS、ROVIO)注重位姿估计,建图效果不好或者没有建图,而RGB-D实时重建除了注重位姿估计,还注重建建图。
上述列举的SLAM/VO/VIO算法,在估计位位姿时,只利用CPU,而当前实时三维重建中,基于GPU的frame-to-mode形式的RGB-D直接法[11-13]和ICP算法成为位姿估计的标配方法,TSDF模型更新也通常通过GPU实现,Surfel模型更新通常通过OpenGL实现。
说完实时重建位姿估计和三维模型表示,再说下回环。VO/VIO没有回环检测和回环优化,算法跑的时间越长,累积误差越大。SLAM里通常通过回环检测和回环优化来减小累积误差(在扫描的时候,扫描的轨迹形成不了闭环也不可以)。
ORB-SLAM在处理闭环时,在global BA优化完成后,还需要将优化前后的特征融合,因为回环前后,同一个区域的特征会被初始化两次,如果没有融合,会造成场景中同一个特征点在地图中多次出现。
同理,在实时重建中,如果扫描返回到之前重建过的区域,同一个场景会被重建两次,而位姿轨迹通常是带有误差的,同一个场景两次重建的结果会错开。RGB-D实时重建通常不考虑回环,不做回环检测和回环优化(KinectFusion、Voxel Hashing和InfiniTAM等),尽管RGB-D实时重建采用frame-to-model的形式做位姿估计,比frame-to-frame的形式更加准确,位姿估计不可避免也会有累计误差,没有回环的实时重建算法跑的时间长,或者相机运动轨迹长时,重建的三维场景也会越来越不靠谱,如果考虑回环,回环检测和回环优化和一般意义上的SLAM算法相差不大(特征点基于BA、或者优化pose-graph),但是回环优化好之后怎么更新重建的地图?
好了,问题来了,Thomas Whelan的两个工作Kintinuous [14]和ElasticFusion [15]有处理回环,方法是采用embedded deformation graph对齐回环处重建的点云,算法可以参考论文,也可以参考博客[16-17],此外斯坦福大学的工作BundleFusion [18]也有处理回环。个人认为不处理回环的实时重建算法适合做AR,而处理回环的时候,回环检测和回环处重建地图的对齐都不好处理,当前回环检测算法不够鲁棒,回环处地图对齐Kintinuous算法效果并不好(也可能只是开源代码处理的不好,作者有可以处理的好的方法),BundleFusion算法现在还未开源,很值得期待开源。
上面提到的大部分算法在我的博客中都有相关介绍,欢迎做实时重建/SLAM/VIO/VO的小伙伴多多指教。
【参考文献
】
[1] Newcombe R A, Lovegrove S J, Davison A J. DTAM: Dense tracking and mapping in real-time[C]//Computer Vision (ICCV), 2011 IEEE International Conference on. IEEE, 2011: 2320-2327.
[2] Newcombe R A, Izadi S, Hilliges O, et al. KinectFusion: Real-time dense surface mapping and tracking[C]//Mixed and augmented reality (ISMAR), 2011 10th IEEE international symposium on. IEEE, 2011: 127-136.
[3] Newcombe R A, Fox D, Seitz S M. Dynamicfusion: Reconstruction and tracking of non-rigid scenes in real-time[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 343-352.
[4]
http://blog.csdn.net/fuxingyin/article/details/51417822
[5] Zollhöfer M, Nießner M, Izadi S, et al. Real-time non-rigid reconstruction using an RGB-D camera[J]. ACM Transactions on Graphics (TOG), 2014, 33(4): 156.
[6] Dou M, Khamis S, Degtyarev Y, et al. Fusion4d: Real-time performance capture of challenging scenes[J]. ACM Transactions on Graphics (TOG), 2016, 35(4): 114.
[7] Dou M, Khamis S, Degtyarev Y, et al. Fusion4d: Real-time performance capture of challenging scenes[J]. ACM Transactions on Graphics (TOG), 2016, 35(4): 114.
[8] Nießner M, Zollhöfer M, Izadi S, et al. Real-time 3D reconstruction at scale using voxel hashing[J]. ACM Transactions on Graphics (TOG), 2013, 32(6): 169.
[9] Chen J, Bautembach D, Izadi S. Scalable real-time volumetric surface reconstruction[J]. ACM Transactions on Graphics (TOG), 2013, 32(4): 113.
[10] Kahler O, Adrian Prisacariu V, Yuheng Ren C, et al. Very high frame rate volumetric integration of depth images on mobile devices[J]. IEEE Transactions on Visualization and Computer Graphics, 2015, 21(11): 1241-1250.
[11] Steinbrücker F, Sturm J, Cremers D. Real-time visual odometry from dense RGB-D images[C]//Computer Vision Workshops (ICCV Workshops), 2011 IEEE International Conference on. IEEE, 2011: 719-722.
[12] Whelan T, Johannsson H, Kaess M, et al. Robust real-time visual odometry for dense RGB-D mapping[C]//Robotics and Automation (ICRA), 2013 IEEE International Conference on. IEEE, 2013: 5724-5731.
[13] Kerl C, Sturm J, Cremers D. Robust odometry estimation for RGB-D cameras[C]//Robotics and Automation (ICRA), 2013 IEEE International Conference on. IEEE, 2013: 3748-3754.
[14] Whelan T, Kaess M, Johannsson H, et al. Real-time large-scale dense RGB-D SLAM with volumetric fusion[J]. The International Journal of Robotics Research, 2015, 34(4-5): 598-626.
[15] Whelan T, Leutenegger S, Salas-Moreno R F, et al. ElasticFusion: Dense SLAM Without A Pose Graph[C]//Robotics: science and systems. 2015, 11.
[16]
http://blog.csdn.net/fuxingyin/article/details/51647750
[17]
http://blog.csdn.net/fuxingyin/article/details/51433793
[18]
http://blog.csdn.net/fuxingyin/article/details/52921958
[19] http://blog.csdn.net/fuxingyin





