TL;DR:
Representation learning
can eliminate the need for large la
beled data sets to train deep neural
networks, opening up new domains to machine learning and transforming
the practice of Data Science.
Check out “Notes on Representation Learning” in these three parts.
-
Notes on Representation Learning
-
Notes on Representation Learning Continued
-
Representation Learning Bonus Material
Deep Learning and Labeled Datasets
The greatest strength of Deep
Learning (DL) is also one of its biggest weaknesses. DL models
frequently have many millions of parameters. The extreme number of
parameters—compared to other sorts of machine learning models—gives DL
models tremendous flexibility to learn
arbitrarily complex functions
that
simpler models cannot learn. But this flexibility makes it very easy to
“overfit” on a training set (essentially, memorize specific examples
instead of learning underlying patterns that allow generalization to
examples not in the training set).
The conceptually simplest way to
prevent overfitting is to train on very large datasets. If the dataset
is big in relation to the number of parameters, then the network will
not have enough capacity to memorize examples and will be “forced” to
instead learn underlying patterns when optimizing a loss function. But
creating large, labeled datasets for every task we want to perform is
cost prohibitive (and may even be impossible if the goal is general
purpose intelligent agents).
This need for large training-sets is
often the biggest obstacle to apply DL to real world problems. On small
datasets, other types of models can outperform DL to the extent that the
constraints of those models match the task at hand. For instance, if
there is a simple linear relationship in the data, a linear regression
can greatly outperform a DL model trained on a small dataset because the
linear constraint of the model corresponds to the data.
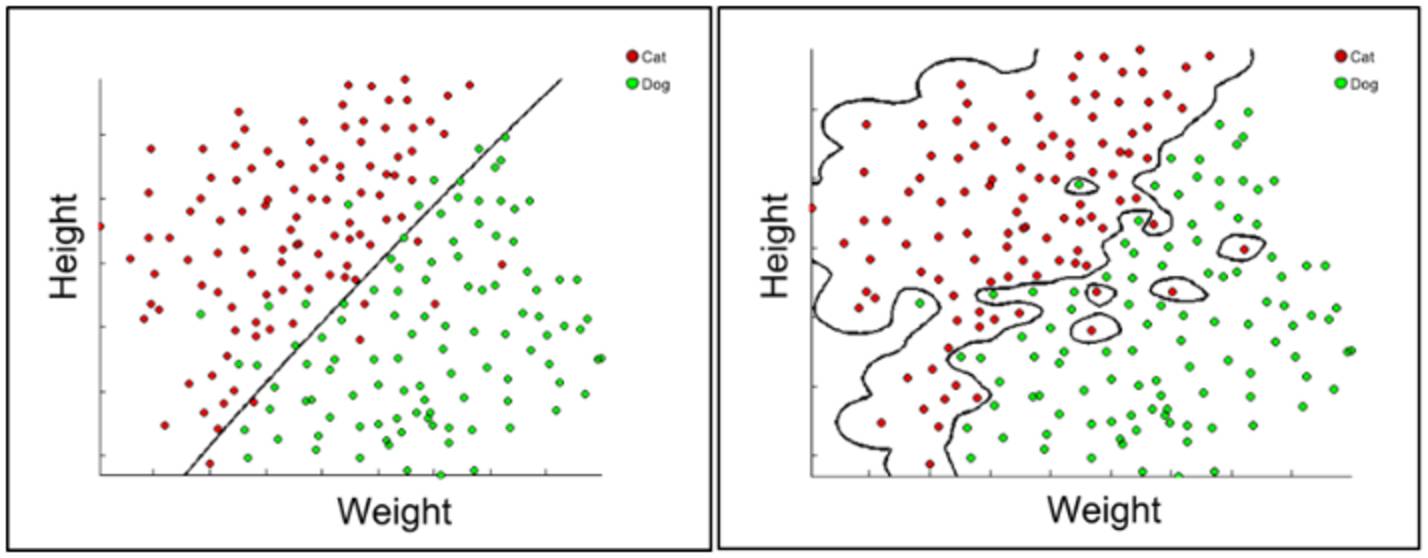
Figure 1. Neural Nets have a
tendency to over fit when datasets are too small. Here the true
relationship between the height and weight of an animal and whether it
is a dog or cat, is essentially linear. A linear classifier assumes
this relationship and uses the data merely to determine the slope and
intercept. A large neural network will require much more data to learn a
straight-line partition. With a small dataset, relative to the size of
the neural network it will overfit on unusual examples, reducing
predictive performance. (Source:
https://kevinbinz.files.wordpress.com/2014/08/ml-svm-after-comparison.png)
That correspondence allows the model
to learn from a small dataset much more efficiently than a DL model
because a DL model needs to learn the linear relationship whereas a
linear regression simply assumes it. Simple linear classifiers are
sufficient for a simple problem like that illustrated above, however
more complex problems require models capable of modeling complex
relationships within the data. Much of the work in applying machine
learning involves choosing models with constraints and power that match
the dataset. While DL has dramatically outperformed all other models on
many tasks, to a large extent it has only done so for complex problem
where there are big labeled datasets available for training.
Representation Learning
This blog post describes how the need
for large, labeled datasets to train DL models is coming to an end.
Over the last year there have been many research results demonstrating
how DL models can learn much
more
efficiently
than other models—outperforming alternatives even with very small
labeled training sets. Indeed, in some remarkable cases, described
below, DL models can learn to perform complex tasks with only a single
labeled exampled (“one shot learning”) or even
without any labeled data at all
(“zero-shot
learning”). Over the next few years, these research results will be
rolled out to production systems, and further innovations will continue
to improve data efficiency even more.
The key to this progress is what DL researchers call “
representation learning
“—a topic considered so important that prominent researchers named the premier DL conference the
International Conference on Learning Representations
.
Part of the enthusiasm for learning representations is that rather than
training DL models on labeled data specific to a target task, you can
train them on labeled data for a different problem, or more importantly,
on unlabeled data. In the process of training on unlabeled data, the
model builds up a reusable internal representation of the data. For
instance, in an image classification example (further described below), a
network first learns to generate bedroom scenes. To do this
convincingly it must develop an internal representation of the world:
its 3-dimensional structure, visual perspective, interior design,
typical bedroom furniture, etc. In other words, using
unsupervised learning
(on
unlabeled data
) the
model builds an understanding of how the world of bedrooms actually
works to produce pictures of bedrooms. Once a network has an internal
representation like this it can learn to recognize objects in images
much more easily. Learning to recognize a “bed” could become almost as
simple as learning to associate the word “bed” with an object that the
network already knows a lot about—it’s 3-dimensional shape, colors,
location in rooms, typical surrounding furniture, etc. As a result,
instead of needing hundreds or thousands of labeled examples of objects,
the model could learn from just a handful of examples.

Figure 2. Bedroom scene generated
by a DL model. No information about bedrooms, bedroom furniture,
lighting, visual perspective, etc. was programmed into the network but
it learns enough about those things to produce realistic looking images
and plausible bedroom arrangements purely by training on bedroom images.
(Source: https://arxiv.org/pdf/1511.06434v2.pdf)







