

“置信区间”的英文是confidence interval,也译为“可信区间”、“信赖区间”或“信心区间”。“confidence interval”这个术语跟“logit”类似,没有既精确又易懂的译法(translation),我努力提供一个平易的“解释”(interpretation)。
先咬文嚼字。confidence interval由两个词组成,主词是“interval”(区间);“confidence”(置信)是对“interval”的“界定”,名词扮演形容词。“置信”这个译法比较“雅”,但把问题复杂化了,因为“置信”的通常联想是“难以置信”,有否定意味,老老实实译为“信心”较好。我追求简单明白,但也愿意附庸风雅,下文既用“信心区间”,也用“置信区间”。这样做,不是为了制造混乱,而是提醒各位两个词同义,可以交换使用。
“区间”指的是处在两个端点之间的范围。例如,课间休息的十分钟就是两节课之间的区间,两个端点分别是上节课结束和下节课开始。“信心区间”的区间是个由“下限”(lower bound,即较小的数)和“上限”(upper bound,即较大的数)界定的数值区间,其中的每个值都是对于总体参数的一个估计。
做显著度检验时,“信心”指的是我们放弃零假设时的信心度,比如90%,95%,99%。这个信心度就是100减去p值,p值是犯一类错误的风险。零假设指的是“总体参数是0”,设立零假设的目的是为了放弃它。在这个语境下,“信心”的对象是“犯一类错误”,有95%的信心,意思是“犯一类错误的风险是5%”。
“信心区间”的信心,意思比较绕。在这个语境下,“信心”的对象不是“这个区间”,不是“这个区间中的任何一个数”,也不是“这个区间的中间数”,而是“得到这个区间的程序”,即抽样程序。
说“我们有95%的信心认为眼前这个样本统计值(可以是平均值、回归系数或净回归系数)的置信区间包含总体参数”,意思是:如果我们采用同一个抽样程序,从一个总体中抽到样本量相同的无数个样本,每个样本中得到一个样本统计值,每个样本统计值有一个置信区间,假设这无数个置信区间是百分之百,那么其中95%包括总体参数,我们有95%的信心认为眼前这个置信区间包括总体参数,也就是说,我们有95%的信心认为眼前这个置信区间包括总体参数是那95%中的一个。
若有兴趣“更彻底地”理解“置信区间”,请接着看。我的解释很长,很繁琐,但没有任何深奥的地方。
显著度检验是探索性研究,是研究的第一步。
计算“置信区间”是应用性研究,是做完显著度检验之后的跟进分析。
显著度检验告诉我们能在什么信心度上放弃零假设。零假设的内容是:总体参数(例如平均值、回归系数、净回归系数)等于0或者与0没有值得关注的(显著的)差异。显著度检验中的“p值”是以正话反说的方式表示信心度。例如,p=0.05,意思是信心度为95%,亦即“放弃了零假设,但只冒了5%的犯一类错误的风险”。
详细点说,显著度检验的目的是判断一个观察到的“非零的”样本统计值是否“显著地”不同于0。检验的起点是假定零假设为真,也就是假定总体参数为0,然后预测,如果零假设真,那么有多大的概率观察到这个已经观察到的样本统计值,亦即有多大的概率抽到我们已经抽到的这个样本。如果预测出的概率很小,比如只有5%,就脑筋急转弯,反问一句,我们不是已经抽到这个样本了吗?抽到了,意味着被预测发生概率只有5%的事件发生了,这说明预测不准确,进而说明预测所依据的零假设可能是假的。
显著度检验有两个可能的结果。
第一,不能在选定的信心度上放弃零假设。
第二,能在选定的信心度上放弃零假设。
第一种结果的后续有两个可能。一是中止研究;二是直接或间接降低追求的信心度。直接方式是,仍然做双边检验,但选择较低的信心度,例如把原定的99%降为95%。间接方式是,把双边检验变成单边检验。例如,在95%信心度上做双边检验,结果显示犯一类错误的风险是10%,超过了预期,不能在95%信心度上放弃零假设。如果在相同信心度上做单边检验,结果显示犯一类错误的风险是5%,符合预期,可以在95%信心度上放弃零假设。
在一定信心度上放弃零假设,只是在该信心度上认定总体参数不是0或者显著地不同于0,不意味着可以在该信心度上认为样本统计值就是总体参数。“显著的”样本统计值仍然只是样本统计值,是对总体参数的一个估计(术语是点估计,point estimate),不等于总体参数。我们写文章时,经常有意无意地忽视这一点,隐含地假设“显著的样本统计值就是总体参数”。写文章时这样想,无伤大雅。但是,如果想把研究成果应用到实践中,不能这样想。这个时候,需要计算“置信区间”。换言之,显著度检验只告诉我们可以有多大的信心认为“总体参数不是0”,是个否定答案;置信区间告诉我们可以有多大的信心认为“总体参数大约是什么”,是个肯定答案。否定也好,肯定也好,都是以“信心度”为标志的概率答案,不是以“必然”、“绝对”为标志的确定答案。
总而言之,计算“置信区间”,是“显著度检验”的后续分析。“显著度检验”告诉了我们总体参数不是0,我们还想知道总体参数大约是什么,于是计算“置信区间”。只有当一个样本统计值“显著”不同于0时,我们才会进而计算它作为总体参数之估计的“置信区间”。如果一个样本统计值等于0或者统计上不显著地不同于0,我们就没有必要计算它作为总体参数之估计的“置信区间”。
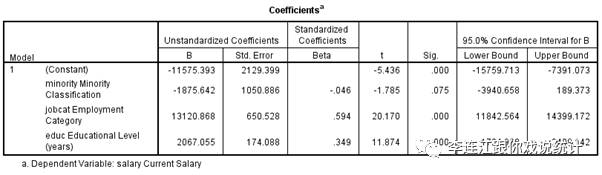
例如,我们分析雇员数据,研究“少数族裔”对年薪的净影响,控制教育程度与工作岗位。我们的研究目的首先是解决一个疑难:在全体雇员中,在教育程度相同而且工作岗位也相同的情况下,相对于白人而言,少数族裔的年薪有“显著”的区别吗?温馨提示:工作岗位实际上是定类变项,我把它视为定序变项,因为这个“歪曲的”分析结果最适合下面的讨论。
多元线性回归的结果如下:
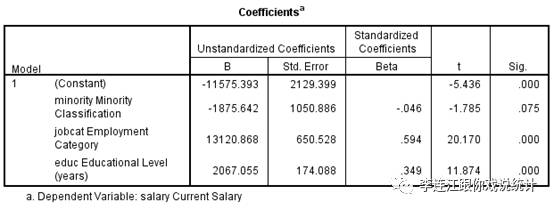
“是否少数族裔”的未标准化的净回归系数是“-1875.642”。意思是:在教育程度相同而且工作岗位也相同的情况下,相对于白人而言,少数族裔的年薪少1875.642美元。
先做双边检验,即,研究预设认为“是否少数族裔”对于年薪有影响,但不预设有正面影响还是有负面影响。犯一类错误的实际风险是7.5%。我们只能在92.5%的信心度上放弃零假设。也就是说,我们愿意承担7.5%的犯一类错误的风险。由于我们通常只用90%,95%,99%作为信心度,我们说:我们在90%的信心度上放弃零假设。也就是说,我们愿意承担10%的犯一类错误的风险。
如果我们希望达到95%的信心度,也就是说,我们只愿意承担5%的犯一类错误的风险,那么我们需要修改研究假设。不是简单地假设“是否少数族裔”对于年薪有影响(也就是假设影响可正可负),而是假设有“负面影响”。这样,净回归系数是负数,双边检验犯一类错误的风险是7.5%,单边检验犯一类的风险是双边检验的一半,即3.75%。我们愿意承担5%的犯一类错误的风险,实际风险是3.75%,低于我们愿意冒的风险,所以我们决定冒这个险,放弃零假设。我们放弃零假设,就是坚持研究假设,就是认为“是否少数族裔”对于年薪有“显著的”(非零的、非随机的)负影响。
如果我们仅仅做探索性理论研究,我们可以用三个净回归系数构建一个回归模型,用来预测每个员工的年薪。回归模型如下:
年薪=-11575.393+-1875.642*少数族裔地位+13120.868*工作岗位+2067.055*教育程度
我们这样做的时候,很容易忽略一点,即,这里的截距与三个净回归系数都是样本统计值,是对总体参数的可信估计,但不等于总体参数。不等于,意思是“可能是但不一定是”。
如果我们做应用研究,就不能像上述那样,隐含地假定显著的样本统计值就是总体参数。我们需要计算样本统计值作为“总体参数之估计”的“置信区间”。换言之,计算“置信区间”的意义在于提醒我们:“显著的”样本统计值仍然只是样本统计值,是对总体参数的估计,但不一定是总体参数。
我们只考虑少数族裔地位对于年薪的净回归系数的“置信区间”,即“-1875.642”这个样本统计值作为对于总体参数的估计的可信度。总体参数就是雇员总体中教育程度相同并且工作岗位也相同的员工中少数族裔地位对于年薪的净影响。
计算“置信区间”时,默认的信任度是“双边”显著度检验的信任度,不是“单边”。前面看到了,我们只能在90%的信心度上放弃零假设。所以,我们只能在90%的信心度上计算“-1875.642”的“置信区间”。
SPSS计算线性回归系数的置信区间时,默认信心度是95%,但我们可以修改它,让它计算信心度为90%时的置信区间,结果如下。
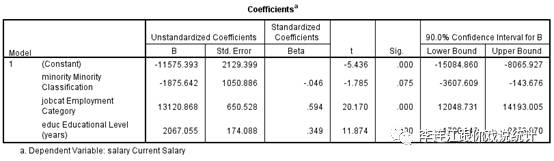
在表格最右侧,我们看到信心度是90%。在这个信心程度上,估算出“置信区间”是:下限是-3607.609,上限是-143.676。温馨提示:回归系数是负的,我们分析自变项对因变项的影响幅度(effect size)时,要看回归系数的绝对值,这里的“下限”与“上限”理论上的,与影响幅度意义上的“下限”与“上限”相反。
说“置信区间”下限是-3607.609,上限是-143.676,意思是:下自-3607.609上至-143.676的所有数值都是对于总体参数的估计,其中包括-1875.642,这些估计构成一个“区间”。
我们有百分之九十的信心认为-3607.609至-143.676这个区间包括总体参数。
问题是:虽然“我们有百分之九十的信心认为-3607.609至-143.676这个区间包括总体参数”是个正确的说法,但这句话究竟是什么意思呢?专家提供的“解释”照例很深奥,而且还分两派,辩论不休。作为用户,我尊重专家的分歧,旁观他们的争论。在他们分出胜负之前,我的“用户解释”包括如下六个成分。
第一,总体参数不是0,我们这样说,犯一类错误的风险是10%。
第二,我们抽取雇员数据时采用了一个抽样程序,设定了样本量,即474。现在我们设想用相同的程序反复从雇员总体中抽取相同样本量(即474人)样本。每抽取一个样本,就计算净回归系数,并在90%的信心度上计算净回归系数的“置信区间”。抽取无数个样本,算出无数个净回归系数,算出无数个“置信区间”。为了简化,我们把“无数”变成“有数”,即把“无限”变成“有限的”“一万个”。(温馨提示,我们必须简化,否则总数是“无数个”,讨论百分比没有意义,这是用非数学语言理解“抽样分布”必然遇到的困难。)
说我们对眼前这个“区间”有90%的信心度,意思就是,根据那个明确的抽样程序,抽一万个样本,计算出一万个“净回归系数”,计算出一万个“置信区间”,这一万个“区间”的90%包括总体参数。我们眼前这个样本是根据那个抽样程序抽出来的,我们有90%的信心认为这个样本中观察到的“置信区间”包括总体参数。也就是说,我们有90%的信心认为已经抽取到的这个样本中观察到的“置信区间”属于那包含总体参数的90%。温馨提示:专家的意见是,我们只能说:我们有很强的信心认为已经抽取到的这个样本中观察到的“置信区间”属于那包含总体参数的90%,不属于那包含总体参数的10%,我们不能肯定眼前这个置信区间究竟是否包含总体参数。
作为用户,具体到雇员数据的例子,我们可以这样说:我们有90%的信心认为,在教育程度与工作岗位相同的情况下,-3607.609至-143.676这个区间包括了是否少数族裔是否以及如何影响雇员年薪的真相。
以下是常见的误解:“已抽取到的这个样本中观察到的置信区间包含总体参数的概率是90%”;“我们有90%的信心认为这个区间内的某个估计是总体参数”;“我们有90%的信心认为这个区间的中间点(即样本统计值)是总体参数”。
据说有些专家也误解“置信区间”,所以这些误解想必无伤大雅。
计算了“置信区间”,我们还是不知道总体参数究竟是什么,因为我们不可能知道。但是,“置信区间”有应用价值。我们可以根据“区间”两个“端点”做大略的估算。以雇员数据为例,我们“应用”置信区间得出的研究结论是:我们有90%的信心认为,在教育程度相同而且工作岗位也相同的情况下,相对于白人而言,少数族裔的年薪“显著地”较低,差别幅度在1875.642至143.676美元。究竟低多少,我们无法给出把握十足的回答,但总比说“低的幅度不是0”准确多了。
下面两点,虽然不那么关键,但容易让人好奇,但也容易令人迷惑。
第一,这个例子里的“下限”与“上限”是怎样计算出来的?
专家提供的计算方法很复杂。我提供一个简单的解释,还是做思想实验。假设有个员工总体,总体中的净回归系数恰好是-1875.642。但是,因为抽样误差,我们可能抽到净回归系数不是-1875.642的样本。例如,我们可以抽到净回归系数是-1000的样本,也可能抽到净回归系数是-2000的样本,还可能能抽到净回归系数为0的样本,甚至可能抽到净回归系数为正数的样本。假设我们抽一万个样本,计算出一万个净回归系数。计算以后,我们采用《戏说统计》第三章详细介绍的方法把这些净回归系数分别装进玻璃管里,我们会看到它们的分布呈正态分布。然后我们看这些净回归系数的分布情况,毫不奇怪,我们发现频次最高的净回归系数是-1875.642,因为-1875.642是一万个净回归系数的平均值,净回归系数正态分布的标准差(标准误)是表中的1050.886(std. error)。根据正态分布的定义,我们知道正态分布下90%的案例出现在平均值±1.645之间。在这里,因为样本量只有474,计算正态分布下90%的信心区间,不是平均值±1.645,而是平均值±1.648。于是我们看到,在一万个净回归系数(样本统计值)中,90%处于一个区间内,区间的下限是 -1875.642 + (-1.648 * 1050.886)= -3607.659,上限是 -1875.642 -(1.648 * 1050.886)= -143.676。于是我们得到一个下限为-3607.659,中间点-1875.642,上限为-143.676的区间,这个区间中的每个数值都是对总体参数的一个估计。这个区间不包括0,也不包括正数。
温馨提示:作为对总体参数的估计,样本统计值一定不是0,要么是负数,要么是正数。如果样本统计值是负数,那么,因为它是对总体参数的估计,总体参数必定是负数。因此,对总体参数的估计的“置信区间”既不能出现0,也不能出现正数,否则它就不是个“可信的”区间。换言之,如果被视为总体参数之估计的样本统计值是负数,那么它的“置信区间”内出现的总体参数之估计必须都是负数。同理,样本统计值是正数,那么,作为对总体参数的估计,它的“置信区间”内既不能出现0,也不能出现负数,否则这个区间就不“可信”。换言之,如果被设定为总体参数之估计的样本统计值是正数,那么它的“置信区间”内出现的总体参数估计必须都是正数。总而言之,不论被设定为总体参数之估计的样本统计值是正数还是负数,它“置信区间”内都不能出现0。
第二,“信心”的高度与“区间”的宽度是什么关系?
简单的答案:二者成反比;信心度越高,区间越宽;信心度越低,区间越窄。社会科学研究中,常见的信心度有三个,90%,95%,99%。
比较两个不同的信心度下计算出来的“置信区间”,就可以直观地理解“信心”的高度与“区间”的宽度之间的关系。
先看少数族裔地位与年薪的净回归系数在信心度为90%时的置信区间。
区间的下限是-3607.659,中间点是-1874.642,上限是-143.676,不包括0,也不包括正数。
再看同一个样本统计值在信心度为95%时的置信区间。
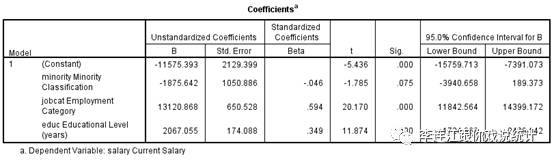
区间的下限是-3940.658,中间点是-1874.642,上限是189点373,包括0,也包括正数。信心度高了,区间宽度大了。可惜,根据定义,样本统计值是负数,是对总体参数的一个可信估计(单边检验下犯一类错误的概率是3.75%),所以包括0和正数的总体参数之估计的“区间”不是个“可信的”区间。
95%信心度上的置信区间的上限与下限的计算如下。在上述思想实验中,总体参数是-1875.642,那么,-1875.642必定是一万个净回归系数的平均值,净回归系数正态分布的标准差是表中的1050.886(std. error)。根据正态分布的定义,我们知道正态分布下95%的案例出现在平均值±1.96之间。在这里,因为样本量只有474,正态分布下95%的案例出现在平均值±1.965之间。这意味着,在一万个净回归系数中,95%处于一个区间内,区间的下限是-3940.658,上限是189。这个区间从负数到正数,包括0,包括正数,不是一个可信的总体参数之估计的区间。
为了理解“信心”的高度与“置信区间”的宽度成反比,我们还可以设计一个“撒网捕鱼”思想实验。这个思想实验的步数比较多,但每一步都简单。
(1)我们把总体参数比作一条“真鱼”,进而假定“真鱼”分黑白二色,有重量。真鱼可能是无色无重的“空鱼”,即“总体参数是0或不显著地有别于0”。“真鱼”可能是条“白鱼”,即“总体参数显著地有别于0”并且是负数。“真鱼”也可能是条“黑鱼”,即“总体参数显著地有别于0”并且是正数。“真鱼”的重量是“总体参数的绝对值”。
(2)我们按照精心设计的方法从总体中抽样,然后分析样本,得到一个样本统计值,相当于遵照一个精心设计的程序、使用一根精心设计的鱼竿在随机选定的地方下竿,钓到了一条鱼。出于对钓鱼程序的信心,我们假定钓到的这条白鱼是“真鱼”的“忠实样品”或“忠实代表”。
(3)我们得到的样本统计值要么是正数要么是负数,其绝对值可能极小,但一般来说不会等于0。也就是说,我们钓到的一般不是“空鱼”,而是一条“鱼”,要么是“白鱼”,要么是“黑鱼”。检验一个样本统计值的显著度,就是判断这条“白鱼”或“黑鱼”是否“显著地”有别于我们可以想象但看不见摸不着的“空鱼”。也就是说,判断它的绝对值是否小得可以忽略不计。
(4)做双边显著度检验,零假设是“总体参数不是空鱼”。做单边显著度检验,零假设有两种可能。其一,研究假设预设总体参数是负数,则零假设是“总体参数不是空鱼也不是黑鱼”。其二,研究假设预设总体参数是正数,则零假设是“总体参数不是空鱼也不是白鱼”。
(5)显著度检验显示,样本统计值是负数并且显著地有别于0,标志着总体参数既不是“空鱼”也不是“黑鱼”,很可能是条“白鱼”。相反,如果显著度检验显示样本统计值是正数并且显著地有别于0,那就标志着总体参数既不是“空鱼”也不是“白鱼”,很可能是条“黑鱼”。
(6)不管钓到的是“白鱼”还是“黑鱼”,都只是“真鱼”的一个样品、样本或代表。我们对“钓鱼程序”的科学性有多大的信心,我们就可以在该信心度上认为钓到的鱼是“真鱼”的“忠实样品”或“忠实代表”。
(7)我们在一定信心度上认定钓到的这条鱼是“真鱼”的“代表”,首先是肯定“真鱼”颜色与“代表”相同。但是,我们还想根据“代表”估计“真鱼”的重量。真鱼的重量有两种可能。其一,这条“鱼代表”就是“真鱼”,它的重量就是“真鱼”的重量,这个样本统计值就是总体参数。其二,这条鱼不是“真鱼”,而是真鱼若干“代表”中的一个,“真鱼”的重量不等于它的重量,要么比它重,要么比它轻;重或轻的程度可能很大。
(8)我们只有一个样本,相当于手里只有一条“鱼代表”,别无选择,只能根据这个代表估计“真鱼”的重量。于是,我们以手里这条“鱼”视为“真鱼”的忠实代表,以它的重量为基准线,假定它是正态分布中的平均值,看一看在它两侧按正态方式分布的“鱼代表”的“重量”最大是多少,最小是多少。从最小到最大的重量,构成一个“重量区间”。温馨提示:从事实角度看,这个“重量区间”要么包括“真鱼”的重量,要么不包括,这里不存在概率问题。
(9)事实上,我们是抽了一个概率样本,在一个信心度上计算了一个置信区间。理论上,我们可以抽很多样本,相当于下很多竿钓鱼。理论上,总体是无限的,可以无限次抽样。实际上,抽样次数是有限的。假定我们以钓到鱼的地方为中间点,左右两侧分别划定50个下杆点,也就是说,原来的下竿点标记为0,往0的左侧,每隔10厘米设一个下竿点,一共设50个,标记为-1到-50;往0的右侧,每隔10厘米设一个下竿点,一共设50个,标记为1到50。这样,最多能下一百竿。假定我们左右开弓,先左后右,实际下了九十竿,每次钓到的都是一条白鱼,只是重量不一。以最轻的哪条白鱼的重量为下限,以钓到的那条白鱼的重量为中点,以最重的哪条白鱼的重量为上限,我们就得到了一个“重量区间”,也就是“真鱼重量”的“置信区间”。我们有90%的信心认为“真鱼”的重量在这个置信区间。同理,我们左右开弓实际下了九十五竿,每次钓到的都是白鱼。以最轻的哪条白鱼的重量为下限,以钓到的那条白鱼的重量为中点,以最重的哪条白鱼的重量为上限,我们就得到了一个“重量区间”,也就是“真鱼重量”的“置信区间”;我们有95%的信心认为“真鱼”的重量在这个置信区间。当然,这里有个隐含假定,就是最轻的白鱼的重量也“统计上显著地不等于0”。
(10)为了省时省力,我们不下竿,用鱼网。我们以“鱼代表”为圆心撒网。网的半径由三个要素决定:一是样本统计值的标准差(参见《戏说统计》第三章关于2.0 版正态分布的讨论);二是我们放弃零假设的信心度;三是样本量。根据正态分布的定义,我们知道正态分布下90%的案例出现在平均值±1.645个标准差之间;95%的案例出现在平均值±1.96个标准差之间;99%的案例出现在平均值±2.58个标准差之间。给定信心度,样本量与渔网半径成反比:样本量越大,渔网半径越小;样本量越小,渔网半径越大。这背后的逻辑是:渔网半径是样本统计值+1.645个标准差,捞到的都是“白鱼”,没有“空鱼”与“黑鱼”,我们有信心认为“真鱼”是白的并且其重量在得到的“区间”内,但我们的信心度只是90%;渔网半径是样本统计值+1.96个标准差,捞到的都是“白鱼”,没有“空鱼”与“黑鱼”,我们有信心认为“真鱼”是白的并且其重量在得到的“区间”内,我们的信心度是95%;渔网半径是样本统计值+2.58个标准差,捞到的都是“白鱼”,没有“空鱼”与“黑鱼”,我们有信心认为“真鱼”是白的并且其重量在得到的“区间”内,我们的信心度是99%。
(11)我们以白色的“鱼代表”为中心撒网,但不是希望捞到“空鱼”和“黑鱼”。相反,我们最担心捞到“空鱼”和“黑鱼”。如果我们在一个信心度上放弃了零假设,那么我们肯定是在相同的信心度上计算置信区间。例如,我们在90%的信心度上放弃了零假设,也就是90%的信心度上断定不会捞到“空鱼”和“黑鱼”。我们扩大的网的半径,目的是找到更强的证据,反证“真鱼”为“空鱼”和“黑鱼”的概率小到我们可以有信心地忽略不计的程度。我们永远做不到信心十足,但我们总是希望信心高一些。我们希望达到的信心度越高,就越需要撒更大网。网越大,捞到的“白鱼”越多,捞到“真鱼”的概率越大,但捞到“空鱼”与“黑鱼”的概率也随之增加。温馨提示:捞到了“非鱼”或“黑鱼”,并不断然证明“真鱼”不是白鱼。在概率世界上,一切都可能,无物是必然。
“置信区间”的理论意义是提醒我们不要简单地把样本统计值等同总体参数。我在《戏说统计》中解释过,统计分析是“由此及彼”,“此”是“样本”,“彼”是“总体”,“由此及彼”是根据“样本统计值”估计“总体参数”。统计分析这个“由此及彼”的过程是“惊险的一跃”,原因是:总体参数不仅是“未知的”,而且是“不可知的”。统计分析的背后是概率思维,概率思维的特点是不确定,表现在语言上,概率思维的特点是用“否定”简介表示“肯定”。例如,我们用“放弃零假设”间接表示“接受研究假设”。需要留心的是,日常的思维方式的特点是确定性,非此即彼,非黑即白,所以,在日常语言中,“放弃A”等于“接受非A”,“并非有罪”等于“无辜”,但这种思维方式预设的是百分之百认识世界,预设掌握绝对真理。要判断是否还持这种非黑即白的方式,最简单明了的方法就是问问自己:如果犯一类错误的风险是5%,那么犯二类错误的风险是多少?如果答95%,就证明仍然没有建立概率思维方式;如果说很大,但说不清背后的逻辑,就证明表面上建立的概率思维方式,但仍然停留在语言上,没有真正融入思维。
掌握研究方法,固然要学很多技术,但最重要的是培养方法意识。方法意识有三个要点。首先是意识到做事有门道、有窍门、有捷径、可以事半功倍。这是正面看,负面看,就是意识到有些做事方法是歧路、是傻功夫、是舍近求远、可能事倍功半。其次是意识到,每个人有自己独特的方法,没有普遍适用的方法。最后一点最重要,就是,为了找到最适合自己的方法,要自觉地把自己一分为二,一个自己做事,另一个自己观察并分析如何可以做得更有效、更好,同时比较自己的作法与他人的作法,评估不同作法的效果。聂卫平棋圣小时学棋,师父过惕生先生教导他:棋是两个人下。树立“棋是两个人下”,就是树立了“围棋意识”,不树立这个意识,不可能成为围棋高手。
理解抽象概念,最有效的方式是“用实例思考”(think with examples)。例如,要理解“信心”的高度与“置信区间”的宽度为什么成反比,最直观的方法就是用同一个样本,在不同的信心度上计算几个“置信区间”,然后比较这几个“置信区间”的异同。
同理,要理解为什么“信心”的对象是抽样程序而不是根据眼前这个样本计算的这个“置信区间”,最直观的方法是走下列四步。
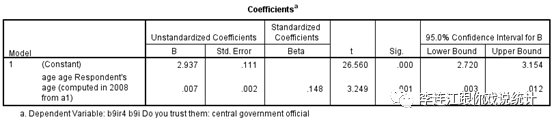
(1)我们用样本量为3909人的“中国调查”数据,假定这个样本是个总体,分析年龄与对中央政府官员的信任度之间的关系。结果显示,年龄越大,对中央的信任度越高。我们计算出的回归系数“0.008”,我们假定它是总体参数,因为是假定,所以我们把它称为“准总体参数”。
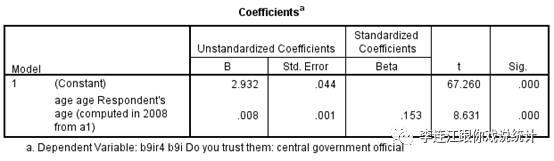
(2)让SPSS从“中国调查”的数据中随机抽样,每次抽样的样本量相同,比如600人。抽一个600人的样本,分析样本中年龄与对中央政府官员的信任度之间的关系。结果显示,回归系数是“0.007”,我们在95%信心度(实际上信心度是99%)上放弃零假设。我们想知道“真正的回归系数”大致是什么范围,于是计算95%信心度的“置信区间”,结果显示置信区间是“0.003-0.012”。这个区间包括0.008,即“准总体参数”,不包括0,也不包括负数,是个“可信的”区间。
(3)再抽一个600人的随机样本,重复上述分析。结果显示,回归系数是“0.010”正数,我们可以在95%信心度(准确说,我们可以在0.004%信心度)上放弃零假设。我们想知道“真正的回归系数”大致是什么范围,于是计算95%信心度的“置信区间”,结果显示置信区间是“0.005-0.014”。这个区间也包括0.008,即“准总体参数”,不包括0,也不包括负数,是个“可信的”区间。
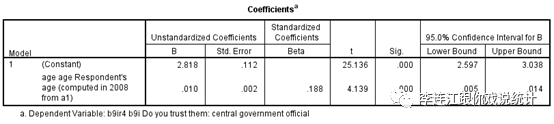
(4)比较第二和第三步计算的两个“置信区间”,我们会看到,根据两个600人样本计算的“置信区间”都包括“准总体参数”(0.008),但这两个“置信区间”的上限与下限不同,中间点也不同。这两个“置信区间”之间的差异,反映的是抽样误差。
“顿悟”时刻终于来临:对“置信区间”的“信心”的对象不是某一个“置信区间”,而是获得这个“置信区间”的抽样程序。我们对一个抽样程序有多大的信心,我们对根据这个抽样程序抽到的样本有相同的信心,从而也就对样本统计值的置信区间有相同的信心。

补充:计算置信区间是做完显示度检验的后续研究,意思是,计算置信区间有个前提条件,就是在某个足够的信心度上认为总体参数不是0。如果只有10%的信心认为总体参数不是0,显然“不足够”,计算样本统计值作为总体参数之估计的置信区间没有意义。SPSS计算置信区间的默认设置是信心度等于或大于50%并且小于100%。信心度不能小于50%,意思是必须有起码的信心(五五开)认为总体参数不是0,否则计算“置信区间”没有意义。信心度必须小于100%,意思是不能追求有十足信心认为置信区间包括总体参数,否则就是想计算一个“无限宽”的区间。
不论在“等于或大于50%但小于100%”之间的哪个信心度上估算某个样本统计值作为总体参数之估计的置信区间,目的都是要把眼前已经获得的这个样本统计值作为总体参数之估计的置信区间“用作”“可信的区间”,亦即当成一个“可信的区间”使用。所以,对于某个抽样程序有某个信心度,蕴含着一个意思:有某个信心度认为,从依照该抽样程序抽出的眼前这个样本中获取的样本统计值的置信区间,是总体参数之估计的诸多个可信的“置信区间”中的一个。
要体会这一点,不妨重复对雇员数据的分析。我们在90%的信心度上认为,控制教育程度与工作岗位,是否少数族裔对于年薪的影响不是0。我们在90%的信心度上计算置信区间,结果是“区间的下限是-1875.642,中间点是-1874.642,上限是-143.676”。这个区间不包括0,也不包括正数,是总体参数之估计的诸多个“可信区间”中的一个,可用。
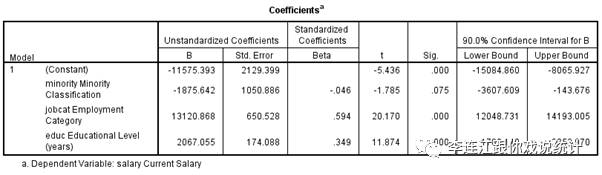
但是,这个“区间”的宽度没有达到“极限”。显著度检验显示我们可以在92.5%的信心度上认为总体参数不是0,也就是说,我们选择在92.5%的信心度上计算置信区间。
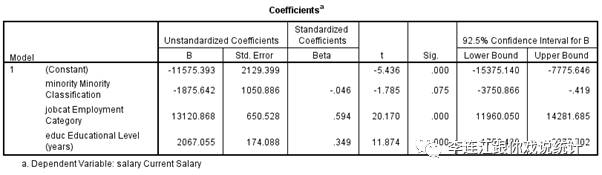
现在我们“物尽其用”,在92.5%的信心度上计算置信区间,结果是“区间的下限是-3750.866,中间点是-1874.642,上限是-0.419”。这个“区间”宽了很多,不包括0与正数,仍然是个“可信的区间”。但是它的“上限”离高压线“0”已经非常接近,十分危险。
如果我们“揠苗助长”,盲目追求高信心度,立刻就会碰钉子。例如,我们在93%的信心度上计算置信区间,结果是“区间的下限是-3784.101,中间点是-1874.642,上限是32.816”。这个“区间”更宽了,但是既包括0,也包括正数,“上限”碰上了高压线“0”,不是个“可信的区间”,不可用。
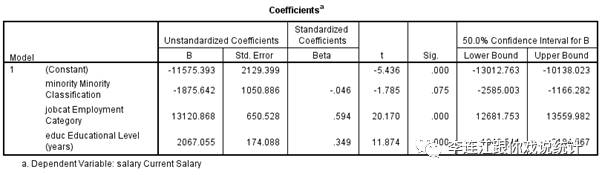
相反,如果我们“大材小用”,在50%的信心度上计算置信区间,结果是“区间的下限是-2585.003,中间点是-1874.642,上限是-1166.882”。这个“区间”,不包括0,也不包括正数,但窄了很多,“信心度”从90%降到了50%,漏掉“真鱼”的概率随之增大很多,也不可用。
给定一个样本,计算“置信区间”时设定的“信心度”越高,“区间”越宽;设定的“信心度”越低,“区间”越窄。我在前面把总体参数比作“真鱼”。我们也可以换个比方,把总体参数比作“真鸟”。我们不是神枪手,枪法有限,要提高“命中”“真鸟”的“信心度”,必须牺牲弹着点的“精准度”,用散弹。散弹出膛后爆成很多钢珠,形成的不是一个“弹着点”,而是一个“弹着区”。弹着区越大,击中“真鸟”的概率越大。我们想打的“真鸟”非黑即白,也就是总体参数非负即正。样本统计值是负数,是“白鸟”,它所“代表”的总体参数一定也是“白鸟”。如果我们想打“真白鸟”(负数),结果打中了“非鸟”(0)或“黑鸟”(正数),就输了,错过了目标。
自然科学家是神枪手,做实验,“指哪儿打哪儿”,精确度高,信心度也高。哲学家是另一类神枪手,“打哪儿指哪儿”,精确度高,信心度也高。可怜的社会科学家既没有自然科学家的实验条件,也没有哲学家信口雌黄的特权,只能做统计分析,是普通射手,做不到“指哪儿打哪儿”(精准算出总体参数),又不肯“打哪儿指哪儿”(盲目乐观地认为样本统计值就是总体参数),只能在“精确度”与“可信度”之间求“可以接受的妥协”:求较高的“精确度”,要牺牲一定的可信度;求较高的“可信度”,就要牺牲一定的精确度。
《计量经济圈社群》
写在后面:各位圈友,一个等待数日的好消息,是计量经济圈应圈友提议,09月04日创建了“计量经济圈的圈子”知识分享社群,如果你对计量感兴趣,并且考虑加入咱们这个计量圈子来受益彼此,那看看这篇介绍文章和操作步骤哦(戳这里)。进去之后一定要看“群公告”,不然接收不了群信息。












