 「论文访谈间」是由 PaperWeekly 和中国中文信息学会青工委联合发起的论文报道栏目,旨在让国内优质论文得到更多关注和认可。
「论文访谈间」是由 PaperWeekly 和中国中文信息学会青工委联合发起的论文报道栏目,旨在让国内优质论文得到更多关注和认可。 论文作者 | 张嘉成,刘洋,栾焕博,许静芳,孙茂松
(清华大学 & 搜狗公司)
特约记者 | 张诗悦(北京邮电大学)
在神经机器翻译(Neural Machine Translation, NMT)中,由于机器不具有人类的智慧,因此常常会犯一些低级的错误。例如,在中-英翻译中,原中文句子含有 10 个词,而机器却有时翻译出一个含有 50 个词的句子或者是只含有 2 个词的句子。 不管内容如何,在人类看来这样的翻译很显然是不对的。那么如何能让机器拥有人类的智慧,从而避免这种低级的错误呢?近日,我们有幸采访到了清华大学的张嘉成,介绍他发表在 ACL2017 上的工作 - Prior Knowledge Integration for Neural Machine Translation using Posterior Regularization。
我们常常将“人类的智慧”称为“先验知识(prior knowledge)”。如何将“先验知识”融合到机器学习模型中?该工作沿用了 Kuzman Ganchev 等人在 2010 年提出的“后验正则化(Posterior Regularization, PR)”方法。该方法可以表示为公式 (1),(2)。其中公式 (2) 代表先验知识的约束;公式 (1) 表示为使得模型求出的后验分布 P(y|x) 和先验分布 q(y) 尽可能地接近,将两者的 KL 距离作为模型目标函数的正则项。但是这个方法难以直接应用到 NMT 领域,原因有两点:1)对于不同的先验知识,很难给出一个固定的 b 作为边界值;2)训练目标是一个 max-min 问题,需要通过 EM 算法求解,难以通过基于导数的优化方法训练。
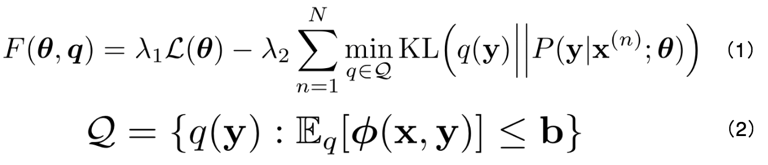
因此在张嘉成等人的工作中,他们将公式 (2) 中的约束集合替换为对数线性模型表示的先验分布,如公式 (3),(4) 所示。公式 (4) 中的 ϕ(x,y) 代表“特征函数”,对于不同句对 (x, y),先求出其特征值并乘以权重参数 γ,再经过 softmax 得到先验分布 Q(y|x),该分布即为原方法中的 q(y)。经过这种改进,使得模型可以直接利用基于导数的优化方法训练,而不需使用 EM 算法进行求解。同时,特征函数 ϕ(x,y) 可以有不同的定义,因此增大了模型的通用性和可扩展性。
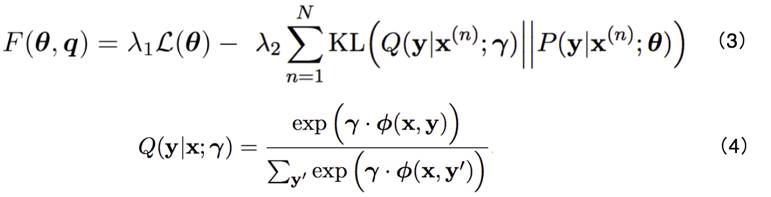
为引入不同的先验知识,文章中采用了 4 类特征:
1. 双语词典特征:人的先验知识中包含词和词的对应关系,例如,爱-love。因此,对于双语词典 D 中的任意一个词对 ,该特征值定义为公式 (5)。含义为,如果该词对出现在翻译句对中,则记 1。也就是对于一个翻译句对,该特征表示“原句和翻译句中出现的词对的数量”。目的是鼓励按照词典进行翻译。
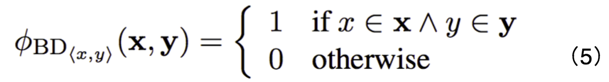
2. 短语表特征:同样,人还知道词组和词组的对应关系,例如:纽约- New York。因此这个特征的定义和双语词典特征类似,如公式(6)所示。对于外部短语表中的任意短语对, 如果出现在翻译句对中,则记1。也就是对于一个翻译句对,该特征表示“原句和翻译句中出现的短语对的数量”。目的是鼓励按照短语表进行翻译。
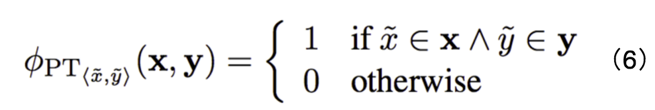
3. 覆盖度惩罚特征:人的先验知识认为原句中的词都会提供信息量,都应该参与翻译。文章沿用了 Yonghui Wu 等人在提出的覆盖度惩罚的定义,如公式 (7) 所示。其中 α_ij 是 NMT 注意力机制中第 j 个目标词对第 i 个源端词的注意力,因此在很少得到注意的源端词处惩罚较大。目的是惩罚源语言中没有被充分翻译的词。
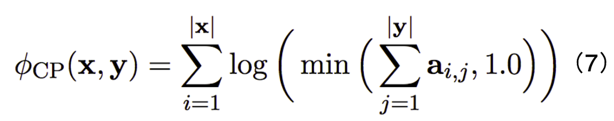
4. 长度比例特征:例如,人知道一般情况下英文句长度约为对应中文句的 1.2 倍。因此文章定义了公式 (8) 所示的长度比例特征,目的是鼓励翻译长度落在合理的范围内。
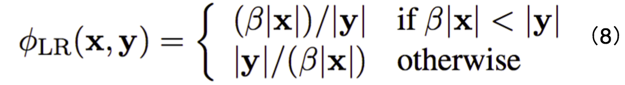
最后,因为在训练过程中不可能穷尽所有可能的翻译,因此采用了近似的方法,采样一部分可能的翻译进行 KL 距离的估计,如公式 (9) 所示。在解码时,采用“重排序”的方法,即先使用 NMT 得到 k 个候选翻译,然后使用特征对其进行重新打分,选择得分最高的作为最终翻译结果。
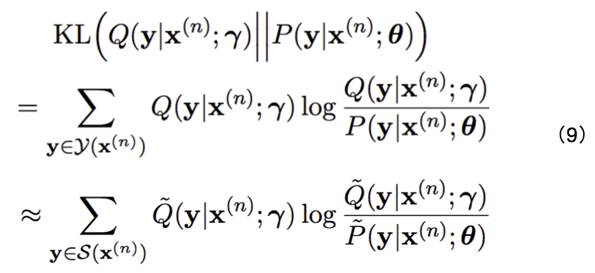
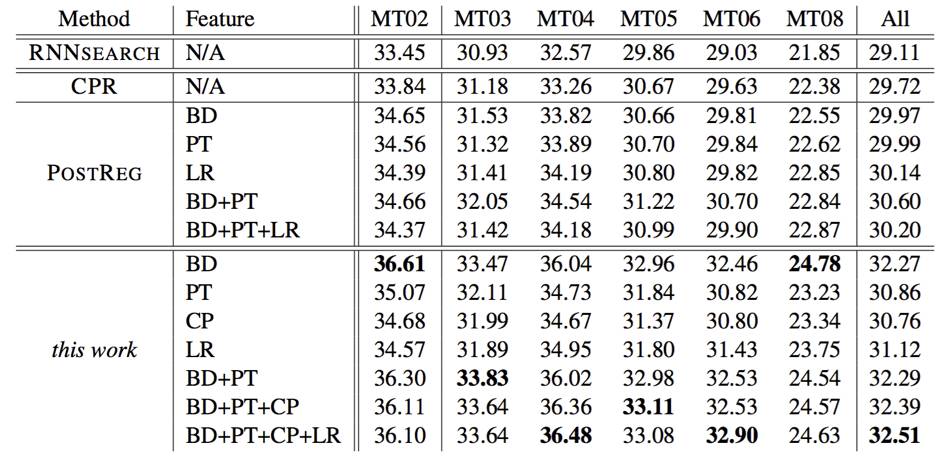
文章中使用的数据集是 1.25M 的中英句对,实验显示该模型能有效地增强翻译效果,可以提升 2+ 的 BLEU 值,如下图所示。
作者表示该工作的创新点在于利用后验正则化思想,将离散的先验知识融入 NMT 框架中 。同时,改进了原后验正则化方法,使其可以直接基于导数优化,并能利用上不同的先验知识。对于该工作尚存在的不足,作者认为权重参数因为具有先验知识重要性的物理意义,应该存在比训练得到更优的获取方案。
欢迎点击「阅读原文」查看论文:
Prior Knowledge Integration for Neural Machine Translation using Posterior Regularization
关于中国中文信息学会青工委
中国中文信息学会青年工作委员会是中国中文信息学会的下属学术组织,专门面向全国中文信息处理领域的青年学者和学生开展工作。

关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。









