来源:bair.berkeley.edu
作者: Jacob Andreas
译者:刘小芹
【新智元导读】本文是伯克利人工智能实验室(BAIR)博客发表的第一篇技术博文,详解了神经模块网络(NMN)在复杂推理任务中的作用及其相对其他方法的优势和挑战。
打开新智元微信公众号,直接回复【NMN】或【神经模块网络】下载涉及的3篇论文

假设我们要做一个家庭机器人,我们希望他能够回答有关周围环境的问题。我们可能会问他这样的问题:

左:这是什么?右:图中跟蓝色圆柱体大小相同的物体是什么颜色的?
我们该怎样确保机器人能够正确回答这些问题呢?深度学习的标准方法是收集大量的问题、图像和答案的数据集,然后训练一个神经网络去直接将问题和图映射到答案。如果大多数问题是类似左图的问题,那么我们要解决的是熟悉的图像识别问题,这类整体式的方法是相当有效的:
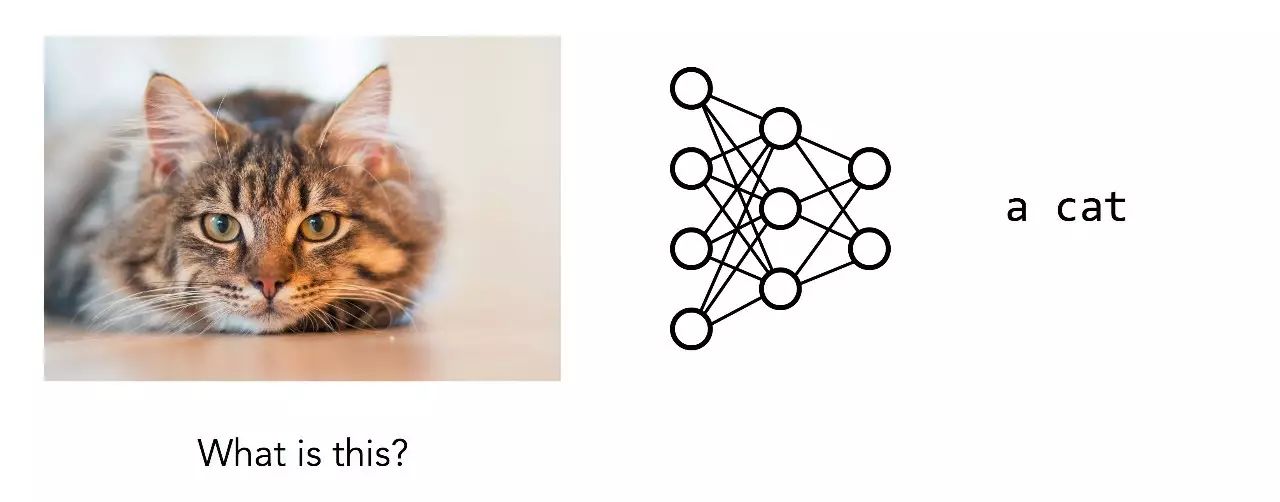
回答问题:这是什么?
但对右边那类的问题,就不是那么简单了:
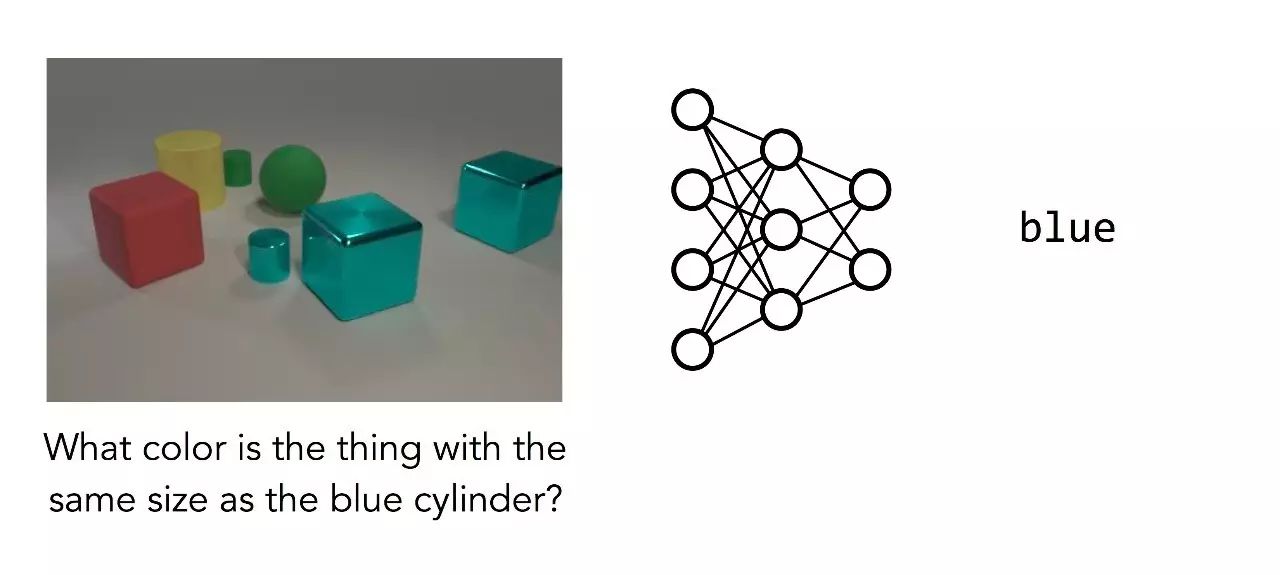
回答问题:跟蓝色圆柱体大小相同的物体是什么颜色的?
这里,我们训练的网络已经弃疗,用图中最多的颜色(蓝色)作为猜测。为什么这个问题难了许多?哪怕我们的图像更加清楚简洁,这个问题也还是需要多步的推理:它不是简单识别图像中主要对象的问题,模型必须先找到蓝色的圆柱体,然后找到跟它大小一致的另一个物体,然后确定这个物体的颜色。这是一种复杂的计算,而且是针对被提问的特定问题的特定计算。不同的问题需要用不同的步骤来解决。
深度学习中的主流范式是“一刀切”的方法:对于我们想要解决的任何问题,我们会写一个固定的模型架构,希望它能捕捉到有关输入和输出之间关系的一切,并从有注释的训练数据为这个固定的模型学习参数。
但真实世界中的推理不能以这种方式工作:它涉及各种不同的能力,混合了我们在外部世界遇到的每一个新的挑战。我们需要一个可以动态地确定如何对前面提出的问题进行推理的模型——一个可以在运行中选择自己的结构的网络。在这篇文章中,我们将讨论一类被称为神经模块网络(neural module networks , NMNs)的模型,它能将这种更灵活的方法结合到解决方案中,同时保持深度学习的强大效用。
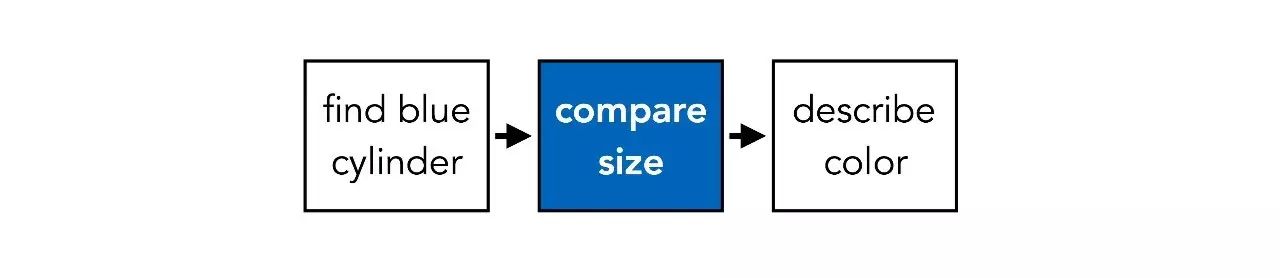
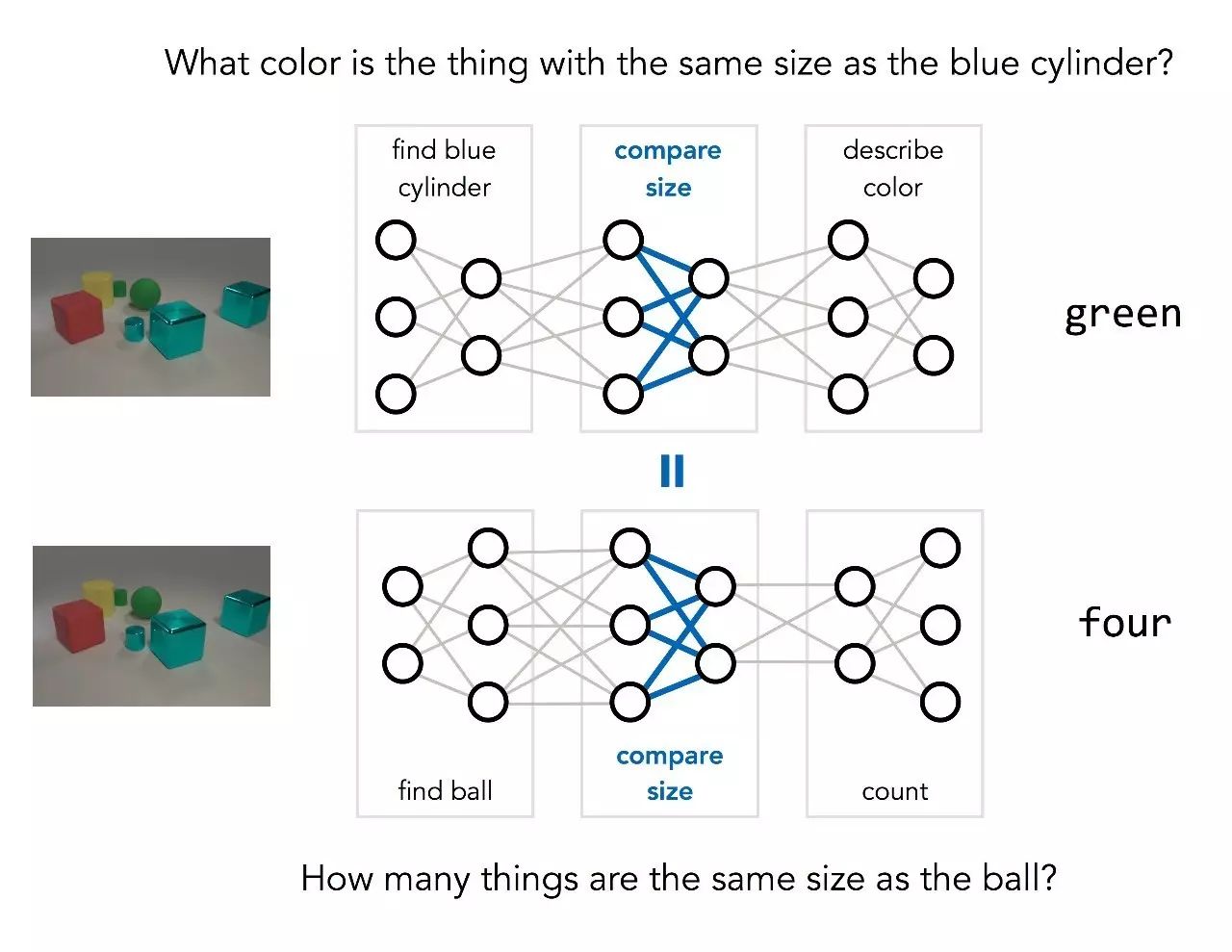
前文提到,在回答上述问题时涉及3个不同的步骤:找到一个蓝色圆柱体,找到与它大小相同的其他物体,确定这个物体的颜色。这个过程可以用下图表示:
一旦问题发生改变,就可能导致一系列不同的步骤。比如说,假如我们问“图中与球的大小相同的物体有多少个?”,步骤就会变成:
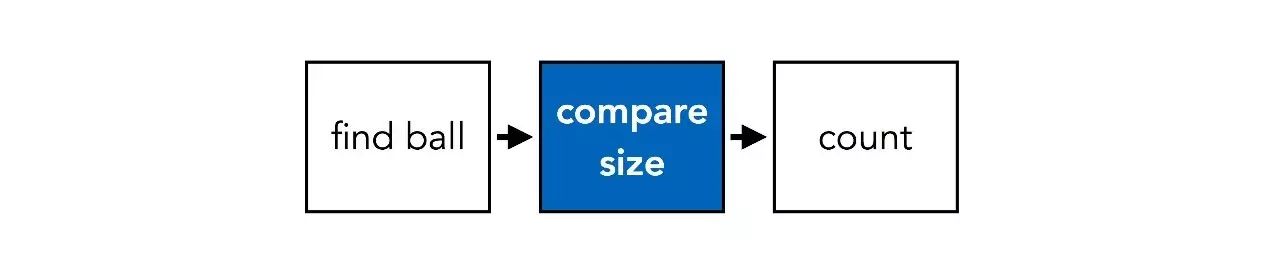
基本的操作,例如“比较大小”,在不同的问题中是共享的,但是使用的方式不同。NMN的关键思想是使这种共享成为显式:我们使用两个不同的网络结构去回答上面的两个问题,但两个网络中包含相同的基本操作的部分权重是共享的。
那么,怎样学习一个这样的模型?我们实际上是同时训练大量的不同的网络,并在适当的时候尝试将它们的参数结合起来,而不是在大量的输入/输出对上训练一个单一的网络。
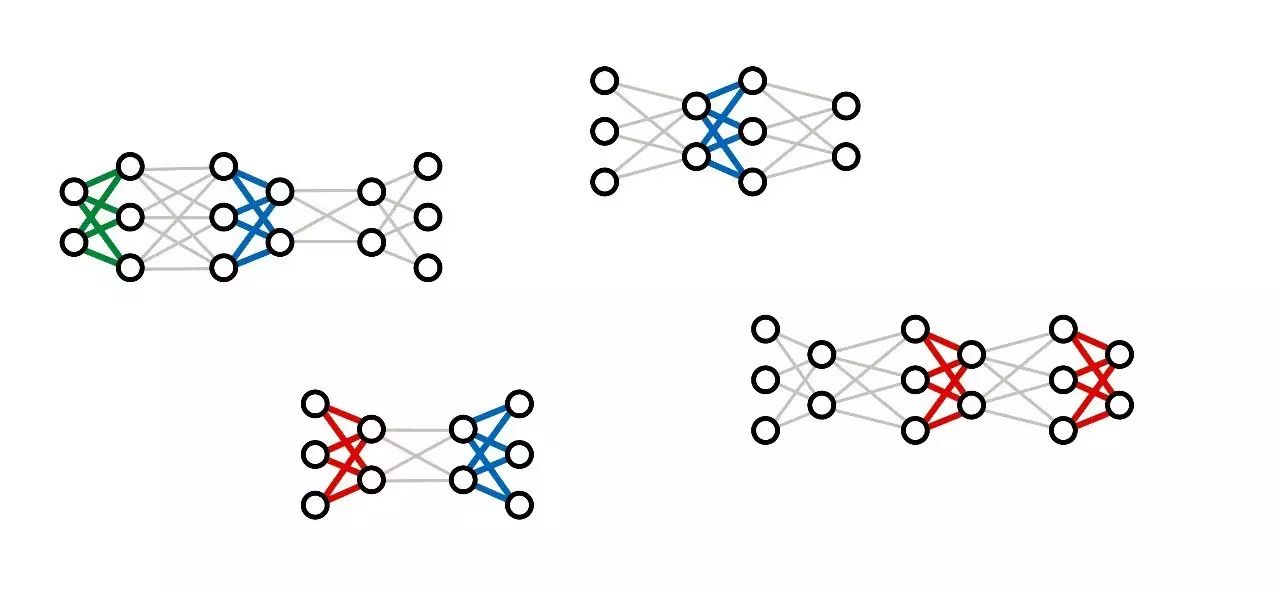
图:最近的一些深度学习架构,包括DyNet和TensorFlow Fold,都是以这种动态计算的方式设计的。
这样的训练过程结束后,我们得到的不是一个单一的深度网络,而是一个神经“模块”(modules)的集合,每一个模块都实现推理的一个步骤。当我们想在新的问题上使用已经训练的模型时,我们可以动态地组合这些模块,使之成为一个针对该问题的新的网络结构。
这个过程中值得注意的是,我们不需要为单个模块提供低级的监督:模型不会将“蓝色物体”或“左侧”关系作为孤立的示例。模块只在更大的组合的结构中学习,只有(问题,答案)的配对作为监督。但训练过程能够自动推理结构中的部件和其负责的计算之间的正确关系:
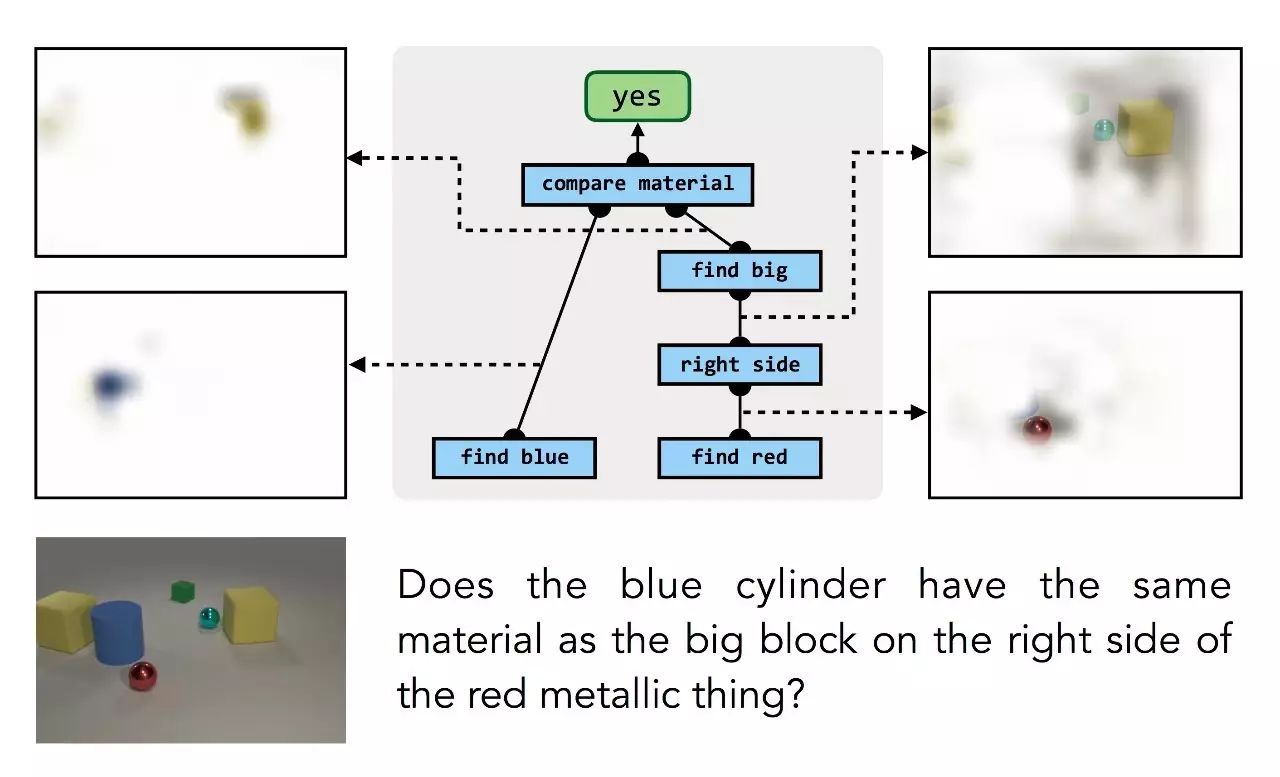
问题:蓝色圆柱体与红色金属块右边的大块材质相同吗?
同样的过程也对有关更逼真的照片的回答工作,甚至对数据库等其他知识来源也工作:
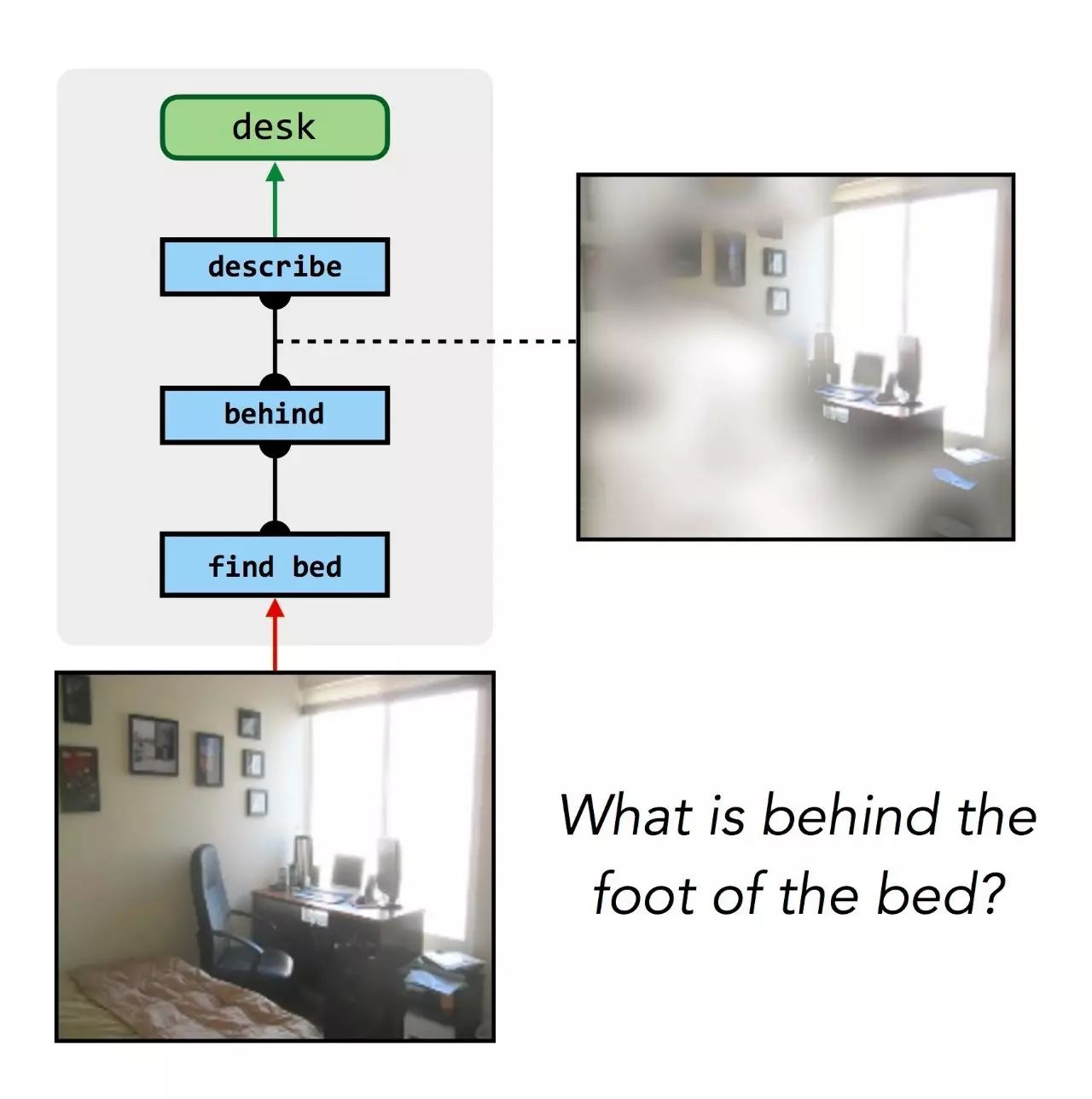
问题:床脚后面有什么?佛罗里达州有哪些海滩?
这个过程的关键要素是如上所述的“推理蓝图”的集合。这些蓝图可以告诉我们,每个问题的网络应该怎样布局,以及不同的问题之间如何相互关联。但这些蓝图是从哪里来的呢?
在有关这些模型的初步工作中,我们发现特定问题(question-specific)的神经网络的设计问题和语法结构的分析问题之间有惊人的关联。语言学家很早就发现,问题的语法与回答问题所需的计算步骤的顺序(sequence)密切相关。多亏自然语言处理方面的最新进展,我们得以使用现成的语法分析工具来自动地提供这些蓝图的类似版本。
但从语言结构准确映射到网络结构仍然是一个具有挑战性的问题,转换的过程容易出错。在后来的研究中,我们不再依赖这种语言学分析,而是使用由人类专家创造的数据,他们用理想化的推理蓝图直接为一系列问题进行注释。通过学习模仿这些人类的方法,我们的模型能够大大提高预测的质量。更令人惊讶的是,当我们采用模仿人类专家的模式训练,并允许模型对这些专家的预测进行自己的修改,它可能在许多问题上找到比专家们的更好的解决方案。
尽管近年来深度学习方法有许多显著的成功,但仍有许多挑战,例如 few-shot 学习和复杂推理。但这些问题正是哪些更加结构化的经典技术,例如语义分析(semantic parsing)和程序归纳(program induction)真正起作用的地方。神经模块网络(NMN)在这两个挑战中都有优势:离散组合的灵活性和数据有效性,以及深度网络的能力。NMN已经在视觉和文本推理的许多任务上取得成功,我们很期待将其应用于其他AI问题。
本文基于以下论文(打开新智元微信公众号,直接回复【NMN】或【神经模块网络】下载论文):
Neural Module Networks. Jacob Andreas, Marcus Rohrbach, Trevor Darrell and Dan Klein. CVPR 2016. (arXiv)
Learning to Compose Neural Networks for Question Answering. Jacob Andreas, Marcus Rohrbach, Trevor Darrell and Dan Klein. NAACL 2016. (arXiv)
Modeling Relationships in Referential Expressions with Compositional Modular Networks. Ronghang Hu, Marcus Rohrbach, Jacob Andreas, Trevor Darrell and Kate Saenko. CVPR 2017. (arXiv)
原文链接:http://bair.berkeley.edu/blog/2017/06/20/learning-to-reason-with-neural-module-networks/
作者:Jacob Andreas
协作写作者:Ronghang Hu, Marcus Rohrbach, Trevor Darrell, Dan Klein & Kate Saenko











