用AMD超越的方式,英特尔开始反击。
作者 |包永刚
本周四,英特尔架构日用长达近两个半小时的时间介绍了其在架构创新以及相关新产品方面的进展。英特尔高级副总裁兼加速计算系统和图形事业部总经理Raja Koduri说:“架构是硬件和软件的‘炼金术’。”
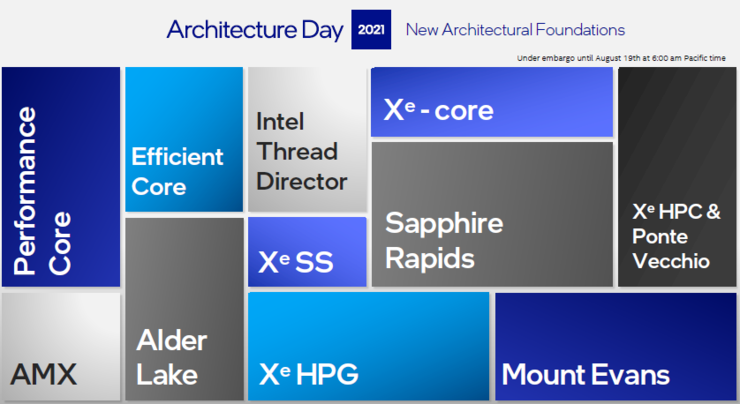
2016年,AMD发布全新CPU微架构ZEN,帮助其在桌面CPU市场几年间迅速接近甚至超越英特尔。今天,英特尔发布了全新的CPU架构和两个核心,将移动SoC中已广泛应用的CPU大小核(BIG.LITTLE)架构率先引入桌面级CPU中。
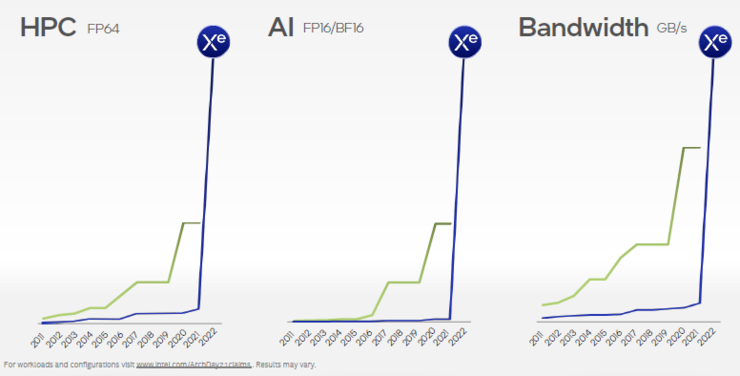
英特尔在升级“看家”产品CPU的同时,也带来了独立GPU更详细的信息。特别值得关注的是,英特尔首次展示了耗时近两年,堪比登月难度创新后的产品Ponte Vecchio GPU,包含1000亿个晶体管,这是英特尔迄今为止最高的计算密度产品,能提供业界最顶级的AI性能。
不止于此,英特尔还进一步介绍了全新的基础设施处理器(IPU)。
从CPU到GPU再到IPU,每一个新的架构和产品都是其XPU架构战略的体现,也用实际产品证明了芯片异构的时代,软件优先的重要性。无论如何,英特尔全新的CPU值得消费者期待,而其GPU以及IPU,也将成为竞争对手重点关注的产品。
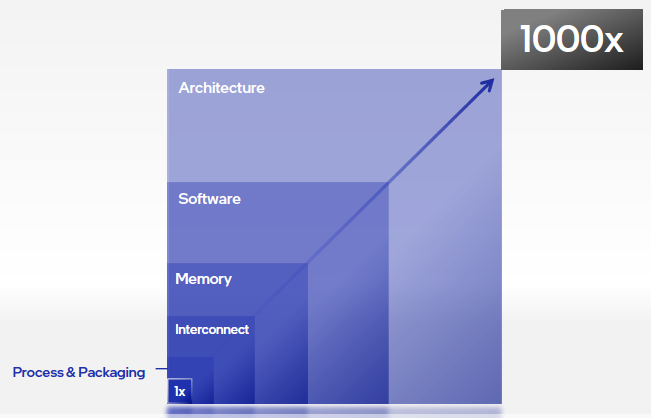
AI、元宇宙、AR,都需要超高性能的处理器。每一位追求创新的客户都给英特尔一个问题,到2025,英特尔能让我们的工作负载处理能力有1000x(千倍级)的提升吗?
“这个要求只给了我们4年时间,而1000倍可是摩尔定律的5次方。” Raja说,“
为了在2025年满足1000x(千倍级)提升的需求,我们要在每个技术领域,实现至少4倍左右的摩尔定律提升,这些领域包括制程工艺、封装、内存和互连,架构是将它们与软件结合起来的‘炼金术’。
这些技术的集合可以作为乘法因子,与4倍的提升相结合,就能提供处理繁重的工作负载所需的千倍提升,这同时例证了为何如今是成为架构师的大好时代。”
2019年,两位图灵奖得主 John L. Hennessy 和 David A. Patterson发表长报告展望,未来的十年将是计算机体系架构领域的“新的黄金十年”。
已经准备好先进制程(Intel7、Intel4、Intel3、Intel20A,以及外部代工厂),先进封装技术(EMIB、Foveros),内存(傲腾)和互联技术的英特尔,处理能力可以像火箭一样跃升吗?

这需要先看英特尔的看家本领——CPU。
“我们的首要目标是,打造世界上极高能效的x86 CPU内核。与此同时大幅缩小芯片尺寸,以便多核工作负载可以根据需要,使用尽可能多的内核进行拓展。我们还希望提供更宽的频率范围,以满足更高需求的工作负载。”英特尔院士,英特尔x86能效核的首席架构师Stephen Robinson介绍,
“基于全新的微架构,全新的CPU内核在多核性能方面实现了突破,首款产品是Alder Lake。”

Alder Lake是英特尔首个性能混合架构,采用Intel7制程,搭载两款新一代x86内核以及智能英特尔硬件线程调度器。
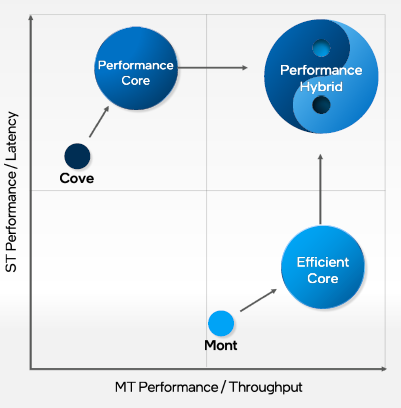
先看能效核,也叫E-Core。
与英特尔迄今为止最多产的CPU微架构Skylake相比,其可在相同功耗下提升40%的单线程性能,或者在提供同样性能时,功耗仅为Skylake的40%不到。如果看吞吐量,与运行四个线程的两个Skylake内核相比,四个能效核在性能提升80%的同时功耗更低,或者在提供相同吞吐量性能时,功耗降低80%。
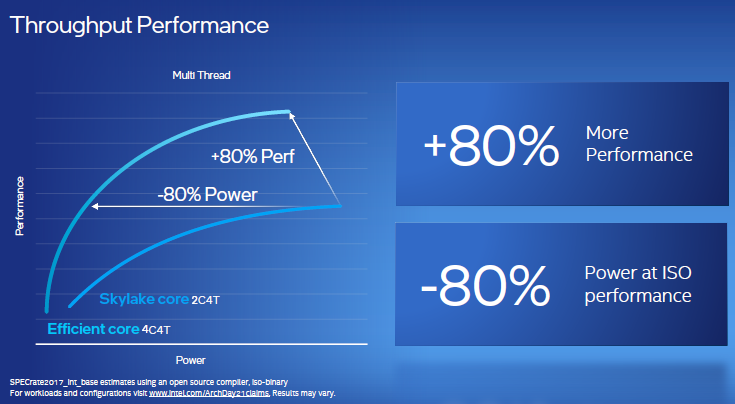
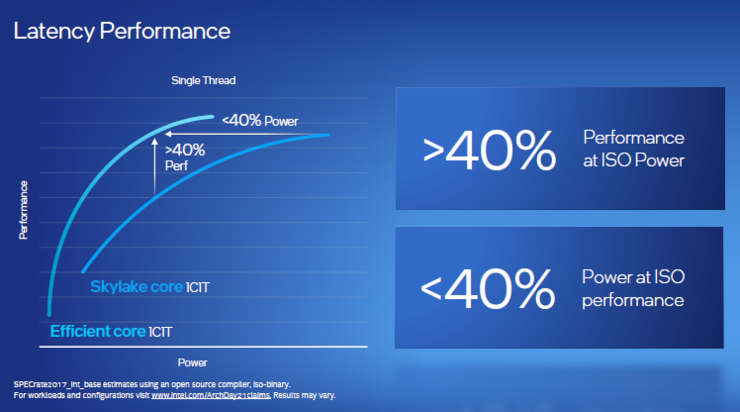
实际上,英特尔是利用各种技术,在不耗费处理器功率的情况下对工作负载进行优先级排序,并通过每周期指令数(IPC)改进功能直接提高性能,具体的功能包括:
-
拥有5000个条目的分支目标缓存区,实现更准确的分支预测
-
64KB指令缓存,在不耗费内存子系统功率的情况下保存可用指令
-
英特尔的首款按需指令长度解码器,可生成预解码信息
-
英特尔的簇乱序执行解码器,可在保持能效的同时,每周期解码多达6条指令
-
后端宽度(Wide Back End)具备5组宽度分配(Five-wide allocation)和8组宽度引退、256个乱序窗口入口和17个执行端口
-
支持英特尔®控制流强制技术和英特尔®虚拟化技术重定向保护等功能
-
实现了AVX指令集以及支持整数人工智能操作的新扩展
再看性能核,也叫P-Core,这是英特尔迄今为止性能最高的CPU内核,它是一个更宽、更深、更智能的架构,展现出更高的并行性,提高执行并行性,降低时延,提升通用性能。

更宽、更深、更智能的性能核架构具体的体现是:
-
更宽:解码器由4个增至6个,6µop 缓存增至8µop,分配由5路增至6路,执行端口由10个增至12个
-
更深:更大的物理寄存器文件(physical register files),拥有512条目的重排序缓冲区
-
更智能:提高了分支预测准确度,降低了有效的一级时延,优化了二级的全写入预测带宽
与第11代酷睿架构(Cypress Cove内核)相比,在相同频率下,性能核在一系列工作负载上平均提升了约19%。
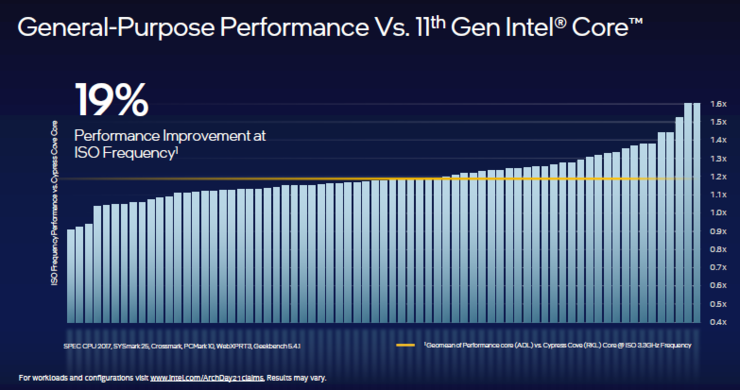
拥有AI硬件加速器是英特尔CPU独有的功能,这一特性在性能核上进一步通过软件结合硬件来提升。凭借英特尔高级矩阵扩展(AMX)来执行矩阵乘法运算,AI加速可以提升约8倍(每个内核每周期可进行2048次int8运算)。AMX可是用过软件的方法,由此就不难理解英特尔一直强调软件优先的原因。
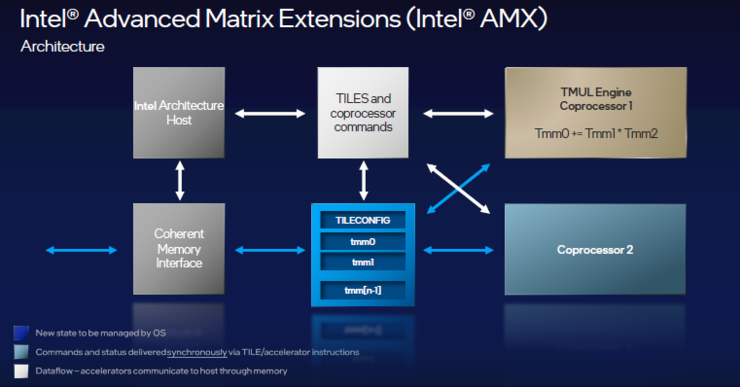
“能效核并不意味着性能就低,只是其优化的方向与性能核不同。”英特尔研究院副总裁、英特尔中国研究院院长宋继强告诉雷锋网。
拥有了不同的内核,就像是拥有了更多武器,能够充分发挥武器的杀伤力才是高手称霸的关键。所以,英特尔开发了独特的硬件线程调度器,能够从开始就动态、智能地分配工作负载,从而优化系统以在真实场景中实现更高的性能和效率。
“英特尔硬件线程调度器与其它调度器一个非常大的区别就是动态、智能地分配工作负载,在合适的时间把合适的线程分配给合适的内核,同时还与操作系统无缝配合。”宋继强指出。

全新性能混合Alder Lake架构CPU由于采用了单一、高度可扩展的SoC架构,这就让其可以支持从超便携式笔记本,到发烧级,到商用台式机的所有客户端设备。
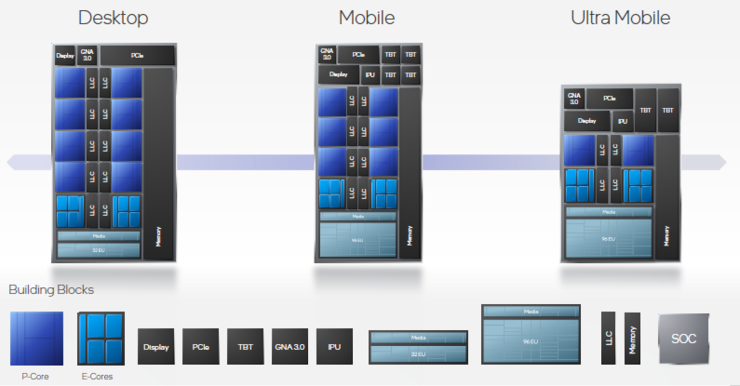
全新的性能核微架构也会用于利润丰厚的数据中心CPU市场,也就是下一代英特尔至强可扩展处理器,代号Sapphire Rapids,其核心是一个分区块、模块化的SoC架构,采用英特尔的嵌入式多芯片互连桥接(EMIB)封装技术,在保持单晶片CPU接口优势的同时,具有显著的可扩展性。
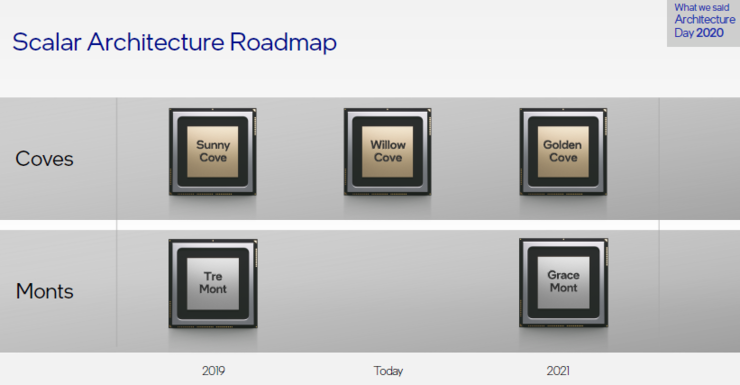
可见,AMD用Zen赶超英特尔,如今英特尔要用Alder Lake反超。这也让我们更期待今年底将会出货的搭载Alder Lake CPU的PC产品。同样,英特尔捍卫其在服务器CPU市场的领导力,代号Sapphire Rapids的下一代至强可扩展处理器也非常重要。

相比看家本领的CPU产品,英特尔过去两次挑战独立GPU市场,都以失败告终。再一次进入独立GPU市场的英特尔面临的是更大的挑战。
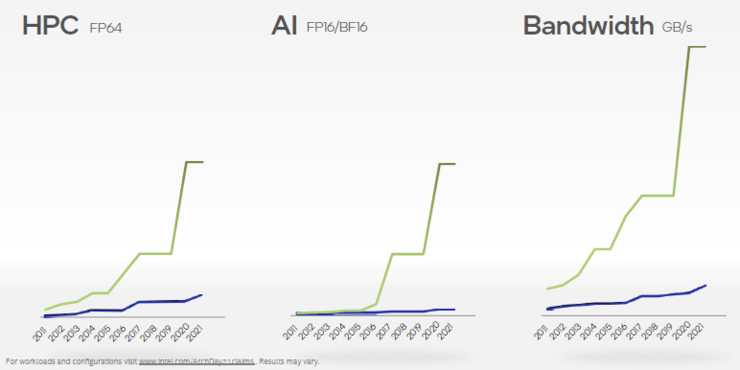
“我们面临的是将近持续十年之久的问题。英特尔在吞吐量计算密度和对高带宽内存的支持方面都落后。这两者都是 HPC和AI的基本指标,也是GPU架构的基石。”Raja给出了图表展示英特尔与业界领先水平的差距。