来源:
炼数成金
1. Introduction
第一次接触到 Markov Chain Monte Carlo (MCMC) 是在 theano 的 deep learning tutorial 里面讲解到的 RBM 用到了 Gibbs sampling,当时因为要赶着做项目,虽然一头雾水,但是也没没有时间仔细看。趁目前比较清闲,把 machine learning 里面的 sampling methods 理一理,发现内容还真不少,有些知识本人也是一知半解,所以这篇文章不可能面面俱到详细讲解所有的 sampling methods,而是着重讲一下这个号称二十世纪 top 10 之一的算法—— Markov chain Monte Carlo。在介绍 MCMC 之前,我们首先了解一下 MCMC 的 Motivation 和在它之前用到的方法。本人也是初学者,错误在所难免,欢迎一起交流。
这篇文章从零开始,应该都可以看懂,主要内容包括:
-
随机采样
-
拒绝采样
-
重要性采样
-
Metropolis-Hastings Algorithm
-
Gibbs Sampling
2. Sampling
我们知道,计算机本身是无法产生真正的随机数的,但是可以根据一定的算法产生伪随机数(pseudo-random numbers)。最古老最简单的莫过于 Linear congruential generator:
式子中的 a 和 c 是一些数学知识推导出的合适的常数。但是我们看到,这种算法产生的下一个随机数完全依赖现在的随机数的大小,而且当你的随机数序列足够大的时候,随机数将出现重复子序列的情况。当然,理论发展到今天,有很多更加先进的随机数产生算法出现,比如 python 数值运算库 numpy 用的是 Mersenne Twister 等。但是不管算法如何发展,这些都不是本质上的随机数,用冯诺依曼的一句话说就是:
Anyone who considers arithmetic methods of producing random digits is, of course, in a state of sin.
要检查一个序列是否是真正的随机序列,可以计算这个序列的 entropy 或者用压缩算法计算该序列的冗余。
OK,根据上面的算法现在我们有了均匀分布的随机数,但是如何产生满足其他分布(比如高斯分布)下的随机数呢?一种可选的简单的方法是 Inverse transform sampling,有时候也叫Smirnov transform。拿高斯分布举例子,它的原理是利用高斯分布的累积分布函数(CDF,cumulative distribution function)来处理,过程如下图:
假如在 y 轴上产生(0,1)之间的均匀分布的随机数,水平向右投影到高斯累计分布函数上,然后垂直向下投影到 x 轴,得到的就是高斯分布。可见高斯分布的随机数实际就是均匀分布随机数在高斯分布的 CDF 函数下的逆映射。当然,在实际操作中,更有效的计算方法有 Box–Muller_transform (an efficient polar form),Ziggurat algorithm 等,这些方法 tricky and faster,没有深入了解,这里也不多说了。
3. Motivation
MCMC 可解决高维空间里的积分和优化问题:
-
上面一个例子简单讲了利用高斯分布的 CDF 可以产生高斯随机数,但是有时候我们遇到一些分布的 CDF 计算不出来(无法用公式表示),随机数如何产生?
-
遇到某些无法直接求积分的函数,如 e^{x^2},在计算机里面如何求积分?
-
如何对一个分布进行高效快速的模拟,以便于抽样?
-
如何在可行域很大(or large number of possible configurations)时有效找到最优解——RBM 优化目标函数中的问题。
-
如何在众多模型中快速找到更好的模型——MDL, BIC, AIC 模型选择问题。
3.1 The Monte Carlo principle
实际上,Monte Carlo 抽样基于这样的思想:假设玩一局牌的赢的概率只取决于你抽到的牌,如果用穷举的方法则有 52! 种情况,计算复杂度太大。而现实中的做法是先玩几局试试,统计赢的概率,如果你不太确信这个概率,你可以尽可能多玩几局,当你玩的次数很大的时候,得到的概率就非常接近真实概率了。
上述方法可以估算随机事件的概率,而用 Monte Carlo 抽样计算随即变量的期望值是接下来内容的重点:X 表示随即变量,服从概率分布 p(x), 那么要计算 f(x) 的期望,只需要我们不停从 p(x) 中抽样
当抽样次数足够的时候,就非常接近真实值了:
Monte Carlo 抽样的方法还有一个重要的好处是:估计值的精度与 x 的维度无关(虽然维度越高,但是每次抽样获得的信息也越多),而是与抽样次数有关。在实际问题里面抽样二十次左右就能达到比较好的精度。
但是,当我们实际动手的时候,就会发现一个问题——如何从分布 p(x) 中抽取随机样本。之前我们说过,计算可以产生均匀分布的伪随机数。显然,第二小节产生高斯随机数的抽样方法只对少数特定的问题管用,对于一般情况呢?
3.2 Rejection Sampling
Reject Sampling 实际采用的是一种迂回( proposal distribution q(x) )的策略。既然 p(x) 太复杂在程序中没法直接采样,那么我设定一个程序可抽样的分布 q(x) 比如高斯分布,然后按照一定的方法拒绝某些样本,达到接近 p(x) 分布的目的:
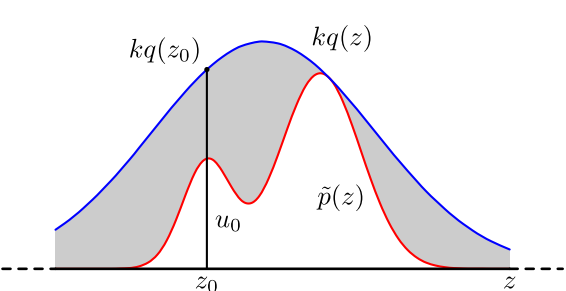
具体操作如下,设定一个方便抽样的函数 q(x),以及一个常量 k,使得 p(x) 总在 kq(x) 的下方。(参考上图)
-
x 轴方向:从 q(x) 分布抽样得到 a。(如果是高斯,就用之前说过的 tricky and faster 的算法更快)
-
y 轴方向:从均匀分布(0, kq(a)) 中抽样得到 u。
-
如果刚好落到灰色区域: u > p(a), 拒绝, 否则接受这次抽样
-
重复以上过程
在高维的情况下,Rejection Sampling 会出现两个问题,第一是合适的 q 分布比较难以找到,第二是很难确定一个合理的 k 值。这两个问题会导致拒绝率很高,无用计算增加。










