
前言
首先思考一个问题:在高并发的场景中,关于数据库都有哪些优化的手段?常用的有以下的实现方法:读写分离、加缓存、主从架构集群、分库分表等,在互联网应用中,大部分都是
读多写少
的场景,设置两个库,主库和读库。
主库的职能是负责写,从库主要是负责读,可以建立读库集群,通过读写职能在数据源上的隔离达到减少读写冲突、
释压
数据库负载
、保护数据库
的目的
。在实际的使用中,凡是涉及到写的部分直接切换到主库,读的部分直接切换到读库,这就是典型的读写分离技术。本篇博文将聚焦读写分离,探讨如何实现它。
目录
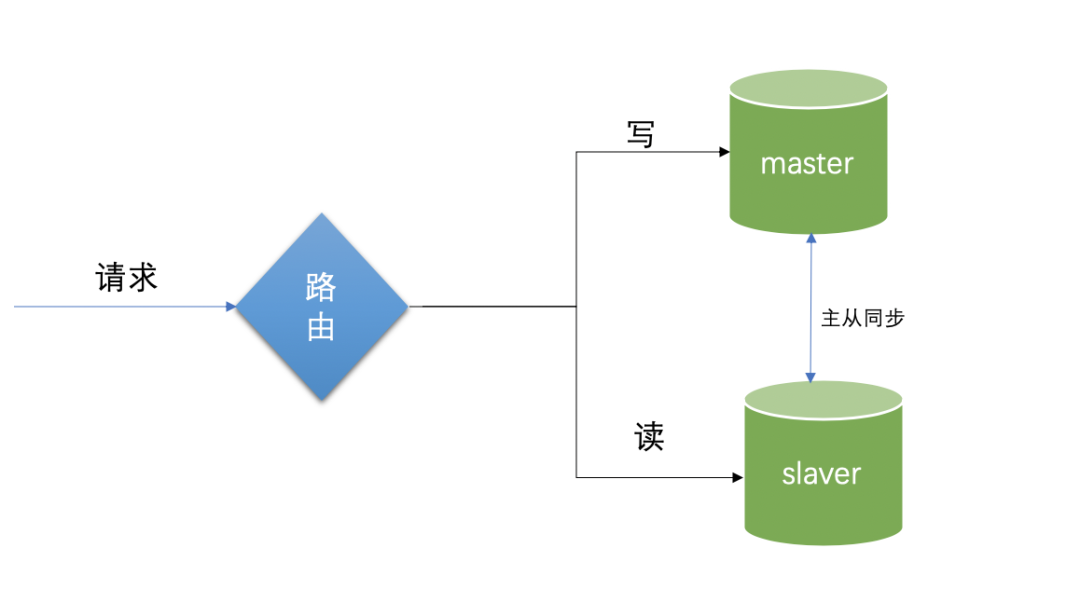
主从同步的局限性
:这里分为主数据库和从数据库,主数据库和从数据库保持数据库结构的一致,主库负责写,当写入数据的时候,会自动同步数据到从数据库;从数据库负责读,当读请求来的时候,直接从读库读取数据,主数据库会自动进行数据复制到从数据库中。不过本篇博客不介绍这部分配置的知识,因为它更偏运维工作一点。
这里涉及到一个问题:主从复制的延迟问题,当写入到主数据库的过程中,突然来了一个读请求,而此时数据还没有完全同步,就会出现读请求的数据读不到或者读出的数据比原始值少的情况。具体的解决方法最简单的就是将读请求暂时指向主库,但是同时也失去了主从分离的部分意义。也就是说在严格意义上的数据一致性场景中,读写分离并非是完全适合的,注意更新的时效性是读写分离使用的缺点。
好了,这部分只是了解,接下来我们看下具体如何通过 java 代码来实现读写分离:
该项目需要引入如下依赖:springBoot、spring-aop、spring-jdbc、aspectjweaver 等
一: 主从数据源的配置
我们需要配置主从数据库,主从数据库的配置一般都是写在配置文件里面。通过@ConfigurationProperties 注解,可以将配置文件(一般命名为:application.Properties)里的属性映射到具体的类属性上,从而读取到写入的值注入到具体的代码配置中,按照习惯大于约定的原则,主库我们都是注为 master,从库注为 slave。
本项目采用了阿里的 druid 数据库连接池,使用 build 建造者模式创建 DataSource 对象,DataSource 就是代码层面抽象出来的数据源,接着需要配置 sessionFactory、sqlTemplate、事务管理器等
/**
* 主从配置
*
* @author wyq
*/
@Configuration
@MapperScan(basePackages = "com.wyq.mysqlreadwriteseparate.mapper", sqlSessionTemplateRef = "sqlTemplate")
public class DataSourceConfig {
/**
* 主库
*/
@Bean
@ConfigurationProperties(prefix = "spring.datasource.master")
public DataSource master() {
return DruidDataSourceBuilder.create().build();
}
/**
* 从库
*/
@Bean
@ConfigurationProperties(prefix = "spring.datasource.slave")
public DataSource slaver() {
return DruidDataSourceBuilder.create().build();
}
/**
* 实例化数据源路由
*/
@Bean
public DataSourceRouter dynamicDB(@Qualifier("master") DataSource masterDataSource,
@Autowired(required = false) @Qualifier("slaver") DataSource slaveDataSource) {
DataSourceRouter dynamicDataSource = new DataSourceRouter();
Map
二: 数据源路由的配置
路由在主从分离是非常重要的,基本是读写切换的核心。Spring 提供了 AbstractRoutingDataSource 根据用户定义的规则选择当前的数据源,作用就是在执行查询之前,设置使用的数据源,实现动态路由的数据源,在每次数据库查询操作前执行它的抽象方法 determineCurrentLookupKey() 决定使用哪个数据源。
为了能有一个全局的数据源管理器,此时我们需要引入 DataSourceContextHolder 这个数据库上下文管理器,可以理解为全局的变量,随时可取(见下面详细介绍),它的主要作用就是保存当前的数据源;
public class DataSourceRouter extends AbstractRoutingDataSource {
/**
* 最终的determineCurrentLookupKey返回的是从DataSourceContextHolder中拿到的,因此在动态切换数据源的时候注解
* 应该给DataSourceContextHolder设值
*
* @return
*/
@Override
protected Object determineCurrentLookupKey() {
return DataSourceContextHolder.get();
}
}
三:数据源上下文环境
数据源上下文保存器,便于程序中可以随时取到当前的数据源,它主要利用 ThreadLocal 封装,因为 ThreadLocal 是线程隔离的,天然具有线程安全的优势。这里暴露了 set 和 get、clear 方法,set 方法用于赋值当前的数据源名,get 方法用于获取当前的数据源名称,clear 方法用于清除 ThreadLocal 中的内容,因为 ThreadLocal 的 key 是 weakReference 是有内存泄漏风险的,通过 remove 方法防止内存泄漏;










