本文目录
1 MambaOut:在视觉任务中,我们真的需要 Mamba 吗?
(来自 NUS,MetaFormer 原作者)
1 MambaOut 论文解读
1.1 在视觉任务中,我们真的需要 Mamba 吗?
1.2 本文有哪些新的发现?
1.3 概念讨论
1.4 视觉任务有长序列吗?
1.5 视觉任务需要 Causal 的 token mixing 模式吗?
1.6 关于 Mamba 在视觉的必要性的假设
1.7 Gated CNN 和 MambaOut
1.8 ImageNet 实验结果
1.9 COCO 目标检测和实例分割实验结果
1.10 ADE20K 语义分割实验结果
太长不看版
Mamba,一种使用类似 RNN 的状态空间模型 (State Space Model, SSM) 作为 token mixer 的架构,能够解决 Self-attention 的二次计算复杂度,并随后引入视觉任务中。但是,与基于卷积或者 Attention 的模型相比,Mamba 在视觉方面的性能往往不足。
在本文中,作者深入研究了 Mamba 的本质,并得出结论:Mamba 非常适合具有
长序列
和
自回归
特征的任务。视觉任务中的图像分类任务与上面的特征都不匹配,因此作者假设 Mamba 在此任务中不是必需的;检测和分割任务也不是自回归的,但它们遵循长序列特征,因此作者认为探索 Mamba 在这些任务上的潜力仍然是值得的。
为了实证验证这一假设,作者通过在移除核心 token mixer SSM 的同时堆叠 Mamba Block 来构建一系列名为 MambaOut 的模型。实验结果有力地支持了我们的假设。具体来说,对于 ImageNet 图像分类,MambaOut 超过了所有视觉 Mamba 模型,这表明该任务确实没有必要 Mamba。对于检测和分割,MambaOut 无法与最先进的视觉 Mamba 模型的性能相匹配,展示了 Mamba 对长序列视觉任务的潜力。
 图1:左:Gated CNN 和 Mamba Block 的架构。Mamba 模块通过一个额外的状态空间模型 (State Space Model, SSM) 来延展 Mamba。右:MambaOut 在 ImageNet 分类任务上超越了多个 Mamba 模型,包括 PlainMamba,Vision Mamba,VMamba
图1:左:Gated CNN 和 Mamba Block 的架构。Mamba 模块通过一个额外的状态空间模型 (State Space Model, SSM) 来延展 Mamba。右:MambaOut 在 ImageNet 分类任务上超越了多个 Mamba 模型,包括 PlainMamba,Vision Mamba,VMamba
 图2:纪念科比布莱恩特---What can I say, Mamba out; 2016 年于 NBA farewell speech
图2:纪念科比布莱恩特---What can I say, Mamba out; 2016 年于 NBA farewell speech
本文做了哪些具体的工作
-
分析了 SSM 中类似 RNN 的机制,并在概念上得出结论,Mamba 适用于具有长序列和自回归特征的任务。
-
检查了视觉任务的特征,认为 SSM 对于 ImageNet 图像分类任务是没必要的,因为此任务不满足自回归和长序列,但是探索 SSM 在检测分割任务的潜力仍然很有价值,因为这些任务尽管不是自回归的,但是符合长序列的特征。
-
开发了一系列名为 MambaOut 的模型,该模型基于 Gated CNN Block,但没有 SSM。实验表明,MambaOut 在 ImageNet 图像分类中有效地超过了视觉 Mamba 模型。
1
MambaOut:在视觉任务中,我们真的需要 Mamba 吗?
论文名称:MambaOut: Do We Really Need Mamba for Vision? (Arxiv 2024.05)
论文地址:
http://arxiv.org/pdf/2405.07992
代码链接:
http://github.com/yuweihao/MambaOut
1.1 在视觉任务中,我们真的需要 Mamba 吗?
近年来,Transformer[1]已经成为各种任务的主流骨干,支持 BERT、GPT 系列和 ViT 等突出模型。然而,Transformer 的 token mixer Self-attention 有关于序列长度的二次计算复杂度,对长序列任务提出了重大的挑战。为了解决这个问题,前人的工作引入了各种各样的具有线性复杂度的 token mixer,比如动态卷积[2]、Linformer[3]、Longformer[4]、Big Bird[5]和 Performer[6]等。最近,出现了一种新的类似 RNN 的模型浪潮[7][8][9],因其可并行化训练以及对长序列执行有效推理的能力,引起了社区的极大兴趣。值得注意的是,RWKV[8]和 Mamba[9]等模型被证明对大语言模型 (LLM) 的主干[10]有效。
受这些类似 RNN 的模型展示出的 promising 的能力的启发,各种研究工作试图将 Mamba[9]引入到视觉工作中,例如 Vision Mamba[11],VMamba[12],LocalMamba[13]和 PlainMamba[14]等工作。本着 RNN 的精神,Mamba 的令牌混合器是结构化状态空间模型 (State Space Model, SSM)。然而,他们的实验表明,与最先进的基于卷积[15][16]和基于 Attention[17][18]的模型相比,基于 SSM 的视觉模型的性能不足。这就产生了一个研究问题:
在视觉任务中,我们真的是否需要 Mamba?
1.2 本文有哪些新的发现?
在本文中,作者研究了 Mamba 的性质,并在概念上总结了 Mamba 非常适合具有两个关键特征的任务:
长序列 (long-sequence)
和**自回归 (autoregressive)**,原因是 SSM 固有的 RNN 机制[19][20]。但不是所有的视觉任务都具有这两个特征。例如,ImageNet 图像分类两者都不符合,COCO 目标检测和实例分割,ADE20K 语义分割任务仅符合长序列这个特征。另一方面,自回归特性要求每个 token 仅从前一个 token 和当前 token 中聚合信息,也就是一种 causal mode 的 token mixing 策略。事实上,所有的视觉识别任务都属于是理解领域而非生成任务,意味着模型一次可以看到整个图像。因此,在视觉识别模型中对 token mixing 施加额外的 causal 约束可能会导致性能下降。虽然这个问题可以通过添加 Bidirectional 分支[21]来缓解,但这个问题不可避免地存在于每个分支中。
基于上述概念讨论,作者提出以下两个假设:
-
假设1:图像分类任务没必要使用 SSM。因为这个任务既不属于长序列任务,也不属于自回归任务。
-
假设2:SSM 可能对目标检测,实例分割和语义分割任务有益,因为它们尽管不是自回归的,但遵循长序列特征。
为了验证这两个假设,作者开发了一系列模型,称为 MambaOut,通过堆叠 Gated CNN[22]Block。Gated CNN 和 Mamba Block 之间的主要区别在于 SSM 的存在,如图1所示。实验结果表明,更简单的 MambaOut 模型已经超过了视觉 Mamba 模型的性能,这反过来又验证了本文假设1。作者还通过实验证明,MambaOut 在 检测和分割任务中没有达到最先进的视觉 Mamba 模型的性能,表明 SSM 在这些任务上的潜力,并有效地验证了本文假设2。
1.3 Mamba 适合什么任务?
在本节中,作者首先讨论 Mamba 模型适合的任务的特征。接下来,检查视觉识别任务是否符合这些特征。基于检查结果,作者提出了关于 Mamba 在视觉的必要性的假设。
Mamba 模型的 token mixer 是 selective SSM[9][20],其包含4个 input-dependent 的参数
, 并将它们通过下式变为
:
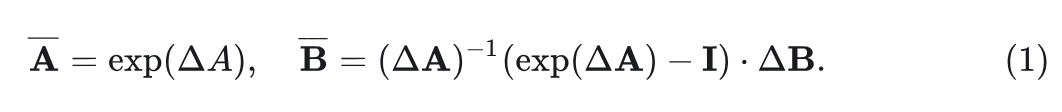
然后,SSM 的序列到序列变换可以表示为:

其中
表示时间步长,
表示输入,
表示隐藏状态,
表示输出, 上式2的循环属性
将 SSM 与 Causal Attention 区分开来。隐藏状态
可以看作是存储所有历史信息的固定大小的 memory。通过式2, 更新此内存, 同时其大小保持不变。固定大小意味着 memory 不可避免地是有损的, 但它确保将 memory 与当前输入集成的计算复杂度保持不变。相反, Causal Attention 将来自先前 token 的所有键和值存储为其 memory, 它通过为每个新输入添加当前 token 的键和值来扩展。这个 memory 在理论上是无损的。然而, 随着输入更多的 tokens, memory 的大小也会增加, 从而增加了将 memory 与当前输入集成的复杂性。图2进一步说明了类似 RNN 的模型和 Causal Attention 之间的记忆机制的差异。
 图3:从 memory 的角度说明 Causal attention 和 RNN-like 模型的区别,x_i 代表第 i 步的输入 tokens。(a): Causal attention 将之前的所有 key 和 value 存入 memory。memory 是无损的;(b):RNN-like 模型将之前的 tokens 压缩为固定大小的状态,存入 memory。memory 是有损的
图3:从 memory 的角度说明 Causal attention 和 RNN-like 模型的区别,x_i 代表第 i 步的输入 tokens。(a): Causal attention 将之前的所有 key 和 value 存入 memory。memory 是无损的;(b):RNN-like 模型将之前的 tokens 压缩为固定大小的状态,存入 memory。memory 是有损的
SSM 的 memory 在本质上是有损的,它在逻辑上落后于 Attention 的无损 memory。因此,Mamba 无法展示处理短序列方面的优势。而 Attention 在短序列处理上很容易处理好。然而,在涉及长序列的场景中,Attention 会因其二次复杂度而发生变化。在这种情况下,Mamba 可以突显其在将内存与当前输入合并时的效率,从而平滑地处理长序列。因此,Mamba 特别适合处理长序列。
虽然 SSM 的循环性质 (式2) 允许 Mamba 有效地处理长序列,但它引入了一个显著的局限性:
只能访问前一个时间步和当前时间步的信息。如图3所示,这种类型的 token mixing 称为 Causal Mode,可以表示为:

其中
和
分别表示第
个 token 的输入和输出。由于其因果性质,这种模式非常适合自回归生成任务。
另一种模式称为完全可见模式,其中每个 token 都可以聚合来自所有先前和后续 tokens 的信息。这意味着每个 token 的输出取决于所有 tokens 的输入:
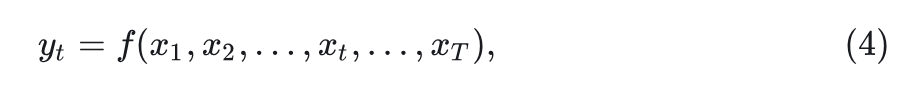
式中,
代表总的 token 数。完全可见模式适用于理解任务,其中模型可以同时访问所有输入。
默认情况下,Attention 处于完全可见的模式,但它可以通过将 Causal Mask 应用于注意力图轻松转变为 Causal Mode。RNN-like 模型由于其循环特性固有地以因果模式运行。由于这种固有特性,RNN-like 模型无法转换为完全可见的模式。尽管 RNN 可以使用双向分支近似完全可见的模式,但每个分支仍然是 Causal Mode。因此,由于 Mamba 的循环特性的固有限制,导致它非常适合需要 Causal token mixing 的任务。
总之,Mamba 非常适合显示以下特征的任务:
-
-
特征2:该任务需要 Causal 的 token mixing 模式。
接下来,作者将讨论视觉识别任务是否表现出这两个特征。
1.4 视觉任务有长序列吗?
作者探讨了视觉识别任务是否需要长序列建模。作者使用 Transformer 作为案例研究。考虑一个常见的 MLP 比为 4 的 Transformer Block; 假设其输入
的长度为
, Embedding dimension 的维度为
, Block 的 FLOPs 可以计算为:
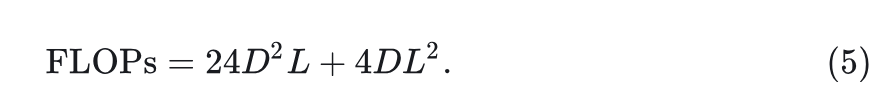
由此,推导出二次项与线性项的比率为:

如果
,则二次项的计算负载超过了线性项的计算量。这提供了一个简单的指标来确定任务是否涉及长序列。例如, 在 ViT-S 中有384个 channel, 阈值
, ViT-B 中有 768 个 channel, 阈值
。
对于 ImageNet 图像分类任务, 典型的输入图像大小为
, 就会有
个 token, Patch Size 为
。显然, 196 远小于
和
, 这表明 ImageNet 图像分类任务不属于长序列任务。
对于
目标检测和实例分割任务, 推理图像大小为
, 在 ADE20K 语义分割任务, 推理图像大小为
, 给定 Patch Size 为
, token 的数量约为
。由于
以及
, 因此
检测和 ADE20K 语义分割都可以被认为是长序列任务。
1.5 视觉任务需要 Causal 的 token mixing 模式吗?
 图4:(a) 两种模式的 token mixing 策略。共计 T 个 tokens,全部可见模式允许 token t 根据所有的 tokens 来计算输出,而 Causal 模式则限制 token t 根据当前以及之前的所有的 tokens 来计算输出。(b) 作者将完全可见模式修改为 Causal 模式,并观察到 ImageNet 的性能下降
图4:(a) 两种模式的 token mixing 策略。共计 T 个 tokens,全部可见模式允许 token t 根据所有的 tokens 来计算输出,而 Causal 模式则限制 token t 根据当前以及之前的所有的 tokens 来计算输出。(b) 作者将完全可见模式修改为 Causal 模式,并观察到 ImageNet 的性能下降
如上图3所示,完全可见模式进行 token mixing 时候不限制范围,而 Causal 模式限制仅仅访问之前 token 的信息。视觉识别被归类为理解任务,其中模型一次可以看到整个图像,消除了对 token mixing 的限制。对 token mixing 施加额外的约束可能会降低模型性能。如图 3(b) 所示,当 Causal 的限制应用于 Vision Transformers (ViT) 时,可以观察到性能的显着下降。一般来说,完全可见的模式适用于理解任务,而因果模式更适合自回归任务。这也是为什么 BERT 和 ViT 比 GPT-1/2 和 Image GPT 更多用于理解任务。
1.6 关于 Mamba 在视觉的必要性的假设
基于之前的讨论,作者总结了假设,即为视觉识别任务引入 Mamba 的必要性:
-
假设 1:没有必要在 ImageNet 上引入 SSM 进行图像分类,因为此任务不满足特征1或特征2。
-
假设 2:仍然值得进一步探索 SSM 在检测和分割方面的潜力,因为这些任务与特征2一致,尽管不满足特征1。
1.7 Gated CNN 和 MambaOut
接下来, 作者通过实验来验证之前的假设。如图 1(a) 所示, Mamba Block 基于 Gated CNN Block
。Gated CNN 和 Mamba 的元架构都可以被认为是 MetaFormer
中的 token mixer 和 MLP 的简化集成, 类似于 MetaNeXt
。形式上, 给定输入
, 元架构表示为:
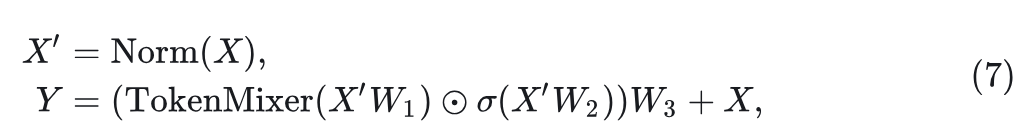
式中, TokenMixer(
)代表 token mixer,其在 Gated CNN 和 Mamba 中分别为:
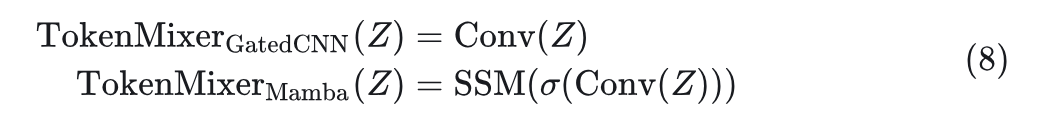
可以发现,Gated CNN 和 Mamba Block 之间的主要区别在于 SSM 的存在。作者开发了一系列模型,称为 MambaOut,它基于没有 SSM 的 Gated CNN Block。通过 MambaOut 来评估 Mamba 对视觉识别任务的必要性。
具体而言,作者按照 ConvNeXt 的做法将 Gated CNN 的 token mixer 指定为 7×7 的 Depth-Wise Convolution。此外,为了提高实际速度,我们仅对部分 channels 进行 Depth-Wise Convolution。如下图5所示,Gated CNN 的实现简单而优雅。与 ResNet 类似,我们采用 4 阶段框架,通过在每个阶段堆叠 Gated CNN 的来构建 MambaOut,如图6所示。
 图5:Gated CNN Block 的 PyTorch 代码
图5:Gated CNN Block 的 PyTorch 代码
 图6:(a) MambaOut 的总体架构;(b) Gated CNN Block 的设计
图6:(a) MambaOut 的总体架构;(b) Gated CNN Block 的设计
1.8 ImageNet 实验结果
ImageNet 实验结果如下图7所示。本文不包含 SSM 的 MambaOut 模型始终优于包含所有模型大小的 SSM 的视觉 Mamba 模型。比如,MambaOut-Small 模型实现了 84.1% 的 top-1 精度,比 LocalVMamba-S 高 0.4%,同时只需要 79% 的 MAC。这些结果有力地支持了本文假设 1,即没有必要在 ImageNet 上引入 SSM 进行图像分类,这与 Occam 的 razor 的原理对齐。









