作者丨龚虹宇
学校丨伊利诺伊大学香槟分校博士生
研究方向丨语义、抽象概念表示和文本分类
语言总是随着时间演变,词义不可避免地受到经济、政治或者文化因素的影响。一个很简单的例子就可以反映这种语言的动态演变现象:例如词语“丈夫”, 在古代汉语中指代成年或未成年的男性,而在现代汉语中则仅指已婚女子的配偶。特定的历史时期对于语义的理解非常重要,它提供了所谓的“时间线索”。来自迪士尼研究中心的 Robert Bamler 和 Stephan Mandt 的一篇近期工作就是关于如何表达动态语义。
在近年的自然语言研究中,“词向量”的概念和技术得到了快速的发展和应用。词向量是词的向量表示,向量的一些几何性质能够很好的反映词的句法或者句义。 例如,两个词向量的差值对应词的关系,词向量的距离则对应词的相关或者相似性。如图1所示,对于选定的一组词,将其向量投影到空间中,词义相近的词向量在向量空间中表现出了有趣的聚类现象。例如国家名词聚成一类,大学名称则形成另一个聚类。
有很多工作包括 word2vec 和 GloVe 提出了不同词向量的训练方法,这些工作的基本思路却是一致的:句子中相邻的词对应的词向量的内积应该能反映语料的统计性质比如这些词共同出现的频率。
在介绍动态词义表达之前,我们会花费一点篇幅快速介绍 Skip-Gram 这个静态词向量训练模型,然后这个模型会被拓展到动态应用场景中。Skip-Gram 模型是在 word2vec 中提出的,对于同时处在同一个上下文窗口的两个词,它将其向量的内积作为逻辑 sigmoid 函数的输入,从而估算两个词同时出现的概率。该模型通过不断调整词向量来最大化训练语料中相邻词出现的概率。
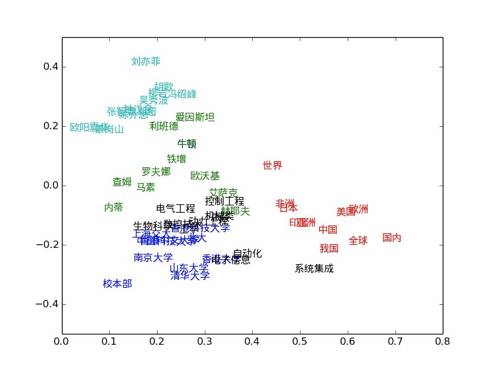
▲ 图1:词向量的空间分布
Bayesian Skip-Gram 模型是 skip-gram 模型的基于图模型的一个变种,它假设所有的词向量都是由潜在向量生成的。这是图 2 a) 所示的静态的模型,即每一个词都只对应一个固定的词向量,表达一种特定的语义。
因为词义是随着时间而动态变化的,我们会很自然地想到用多个向量来表示词在不同时期的含义。因此,我们今天介绍的这篇文章提出将时间信息加入到 Bayesian Skip-Gram 模型中,通过建模潜在向量的时间变化,来捕获词向量随时间的迁移。
动态词义的训练语料是来自不同历史时期的文本的合集。在静态模型中,我们希望训练向量从而最大化训练语料的出现概率;动态模型的目标函数不仅包含语料的概率,而且包含了词向量的迁移概率。迁移概率是为了描述词义的动态变化。也就是说,词向量的训练是为了同时最大化训练语料的概率和词义变化的概率。
如图 2 b),假设训练语料来自 T 个不同时期,我们可以想象动态模型是有 T 个静态的 Bayesian Skip-Gram 模型组成,每一个静态模型都连向下一个静态模型,模拟语义从当前时刻向下一时刻的迁移。
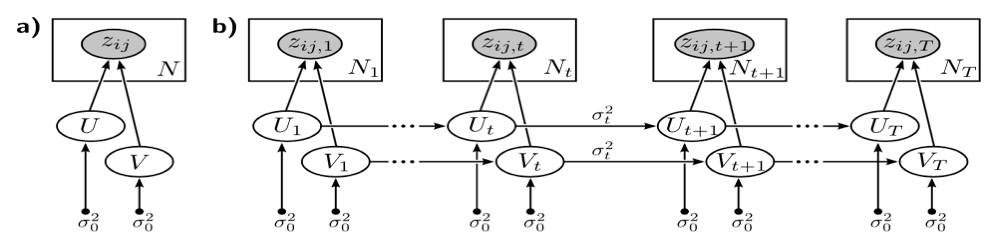
▲ 图2:Bayesian Skip-Gram 模型
在提出动态图模型之后, 我们需要估计模型中的参数比如词向量的生成概率和迁移概率。这篇工作中提出了两种近似的估计算法:筛选算法和平滑算法。前者仅仅使用观测到的文档训练当前模型,而后者则会使用语料中的所有文档。动态模型能够对每一时期生成一组词向量,词向量的质量可以从以下三个方面进行评估:
(1)词义准确:任一时期的词向量需要准确对应该时期下的词义。比如,“丈夫”的早期词模型应该和“男性”等词接近,而其后期此模型应该和“配偶”等更为相似。
(2)平滑迁移:因为语言经历的是一个缓慢的变化过程,因此词向量在向量空间中的变化轨迹是平滑而非突变的,“丈夫”一词在不同时期的语义有差别,但是都与”男性“这一概念相关。
(3)拓展性:训练的词向量将被用来估计测试语料的概率,好的词向量需要能从训练语料拓展到测试语料,给出较高的测试语料概率。
GoolgeNews 提供了大量带有时间标记的语料,这篇工作利用 1850 年到 2000 年之间的文档,利用上述介绍的动态模型训练了不同时期下的词向量。图 3 显示了“电脑”这一词向量在向量空间中的迁移,通过其相邻的词我们可以看出其词义的变化:它从早期跟“计算”,“机器“有关的概念迁移到了与”软件”和“文件”更为相关的概念。
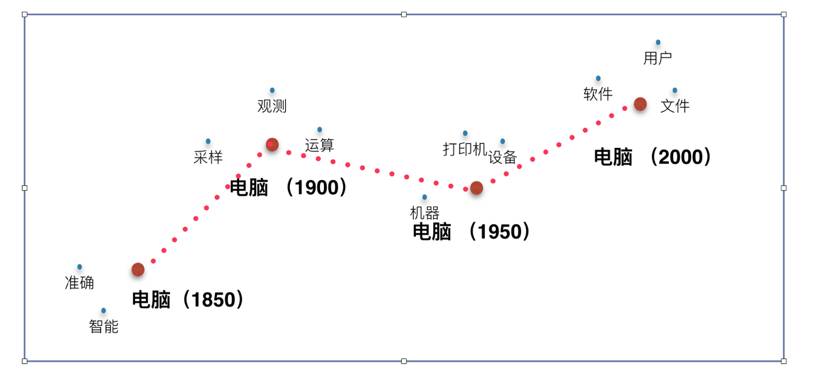
▲ 图3:“电脑”的词义变迁
这期我们介绍的文章将静态的词向量的训练拓展到动态场景,建立了能够描述语言发展变化的图模型。更加深层次上, 这篇工作提供了动态建模的新思路,不仅仅是可以用于词义的动态建模,也可以应用到其他涉及时间序列的场景中。
关于PaperWeekly
PaperWeekly是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事AI领域,欢迎在公众号后台点击「交流群」,小助手将把你带入PaperWeekly的交流群里。











