 「论文访谈间」是由 PaperWeekly 和中国中文信息学会青工委联合发起的论文报道栏目,旨在让国内优质论文得到更多关注和认可。
「论文访谈间」是由 PaperWeekly 和中国中文信息学会青工委联合发起的论文报道栏目,旨在让国内优质论文得到更多关注和认可。
作者 | 吴俣,武威,星辰,李舟军,周明(北航&微软研究院)
特约记者 | 曹东岩(哈尔滨工业大学)
人工智能现在的火热程度大家有目共睹,凯文凯利在《必然》中预测未来时代的人工智能可能会重新定义人类的意义,但时下的人工智能发展水平显然还没有大家想象得那么美好,仍然需要我们不断地探索。目前众多研究人员正深耕其中,作为其中代表的聊天机器人(Chatbot),已然成为科研界研究的热点。
通常来说聊天机器人实现方式有两种:一种是基于生成式,即机器人“自己说话”,一个字一个字创作出回复语句来。另外一种是基于检索式,即机器人“转发”别人的话。从互联网大家的话语中寻找到合适的回答予以转发。
现有的生成结果由于技术所限,或多或少都存在语句不流畅的问题,但能够做到“有问必答”偶尔还能蹦出“彩蛋”。检索的模型一般流畅性方面无须担心,不过随着目前网络资源的日益丰富,语料规模也越来越大,如何从众多语句中选择合适的句子作为回复是检索式聊天机器人的核心问题。
虽然目前市场上的聊天机器人众多,但我们见到的那些貌似都不是那么聪明。最直观的一个体现就是前后不连贯,上下难衔接,因此在进行检索的时候考虑历史信息则显得尤为重要。那么如何让机器人理解对话历史信息从而聪明地进行回复呢?微软亚洲研究院的研究员们提出了一个模型 Sequential Matching Network(SMN)。相关论文的作者吴俣谈到“SMN 模型可以让聊天机器人准确的理解当前和用户的对话历史,并根据历史给出最相关的回复,与用户进行交流,达到人机对话的目的。”
但这在实现的过程中也遇到不少难点,“精准计算聊天历史和候选回复的语义相似度十分困难,主要的挑战有两个方面:(1)由于聊天历史信息繁多,如何将历史中重要的词语、短语以及句子选择出来,并通过这些重要部分刻画聊天历史,是一个亟待解决的问题;(2)如何对聊天历史中的各轮对话进行建模,如何判断对话历史中的跳转,顺承等关系,也是一个棘手的问题。” 那么论文作者提出的 SMN 模型又是如何解决这两个问题的呢,接下来我们将为您解读。
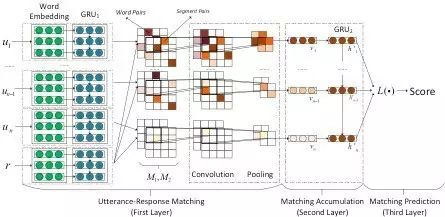
▲ 图1:
SMN网络架构
SMN 模型一共分为三层。第一层为信息匹配层,对之前的历史信息和待回复的句子进行匹配度计算:同时进行词语(embedding 向量)和短语级别(GRU 表示)的相似度计算。然后再把这两个矩阵分别作为卷积神经网络的一个 channel,利用 CNN 的 max-pooling 进行特征抽象,形成一个匹配向量。第二层为匹配积累层,利用一个 GRU 神经网络,将每一句话和回复所计算出的匹配信息进一步融合。第三层为匹配结果预测层,利用融合的匹配信息计算最终的匹配得分,在预测时他们使用三种策略,分别是只利用 GRU2 最后一个隐藏层(SMN_last),静态加权隐藏层(SMN_static),和动态加权隐藏层(
SMN_dynamic
)。在进行检索的时候,他们将最后一句的信息结合上文历史信息中的 5 个关键词(历史信息中用 tf-idf 进行筛选,选择 Top 5 关键词)在系统中进行检索,然后用上述 SMN 网络对候选结果打分从而选出回复句。
作者分别在 Ubuntu 语料(大型公开计算机相关求助与解答语料)和豆瓣语料(作者从豆瓣小组的公开信息中爬取并在论文中公布)上进行了实验,分别以 Rn@K 和 MAP、MRR、P@1 为评价指标,取得的结果均为目前最好。
作者表示“SMN不同以往的模型,第一步不进行上下文的建模学习,而是让每句话和回复进行匹配度计算,这样可以尽可能多的保留上下文的信息,以避免重要信息在学习上下文的向量表示时丢失。而且 SMN 在对上下文句子关系建模时,考虑了当前回复的影响,使得回复成为一个监督信号,这样可以更准确的对上下文历史进行建模。”并且吴俣向我们透露“据我们所知,我们公布的豆瓣语料是第一个人工标注的中文多轮对话语料。”
在谈及目前的方法还有哪些不足之处时,作者表示“目前我们的检索方式有时找不到正确的候选句,所以第一步的检索方法还有待改善,另外虽然我们的模型可以建模当前回复和历史信息的关系,但还是无法避免一些逻辑上的问题,不过这也是我们未来工作的重点,我们将继续提高候选回复在逻辑上的连贯性”,让我们共同期待他们的未来工作。
✎
文末福利
论文中公布的豆瓣语料和代码链接:
https://github.com/MarkWuNLP/MultiTurnResponseSelection
欢迎点击「阅读原文」查看论文:
Sequential Match Network: A New Architecture for Multi-turn Response Selection in Retrieval-based Chatbots
关于中国中文信息学会青工委










