文章整理自雨帆在苏宁团队内部的 PPT 分享,这是他在 OneAPM 工作两年的实战经验总结。
掐指一算,从 OneAPM 离职也快一个月了,在 OneAPM 工作的种种,仿佛还像是在昨天。细数两年的工作经历,我很庆幸在恰当的时间点和这么一群有激情有活力的人共事。那么,是时候总结一下我在 OneAPM 做的牛(cai)逼(ji)事情了。
大家好,今天由我来分享一下,我在上家公司做的 Ai 和 告警 相关的一些内容。
首先,我先简单介绍一下,今天我要分享的两个项目:
Ai 是 OneAPM 服务器端应用性能监控分析程序,它主要是能收集Java、CSharp、Python等偏后端语言的系统的一些指标数据。然后分析出调用 Trace 和完整的调用拓扑图,还有一些其他图表数据的展示。
告警系统原先作为一个 Ai 系统的子模块,用的是流式计算框架 Flink,后面不能满足对外交付和业务功能需求。我们就重新设计开发了纯粹的CEP计算引擎,依托于此在Ai上构建了新的告警系统,然后服务化拆分成独立的告警系统,并接入了其他类似Ai的业务线。
这次分享,一是我对以前2年工作的整理和思考,二也是和大家交流学习。

对于 Ai,我不属于它的主要研发,我只是在上面剥离开发了现有的告警系统。所以我就讲讲我接触过的架构部分的演进。本身,就功能部分,其实没有东西。 我在说告警的时候会说的比较细一些。

我是15年年底入职OneAPM,17年9月初离职加入咱们这个团队。这期间Ai伴随着业务的需求,也进行了三次大的技术架构演进。最明显的,就是每次演进中,Ai对应的存储在不断变化。同时,比较巧的是,每次架构变化的同时,我们的数据结构也略有不同,并且学习的国外竞品也不大一样。
说老实话,我们每次改变的步子都迈的略大,这中间也走了不少弯路。很多技术、框架,一开始看十分好,但是却不一定契合我们的需求。项目在变革初期就拆分出SaaS和企业级两套代码,并且各自都有比较多的开发分支,这些东西的维护,也让我们的代码管理一度崩溃。
但是,我这里主要想分享的,就是我们在业务和数据量不断增长的同时的架构设计变化,以及最后如何实现灵活部署,一套代码适配各种环境。
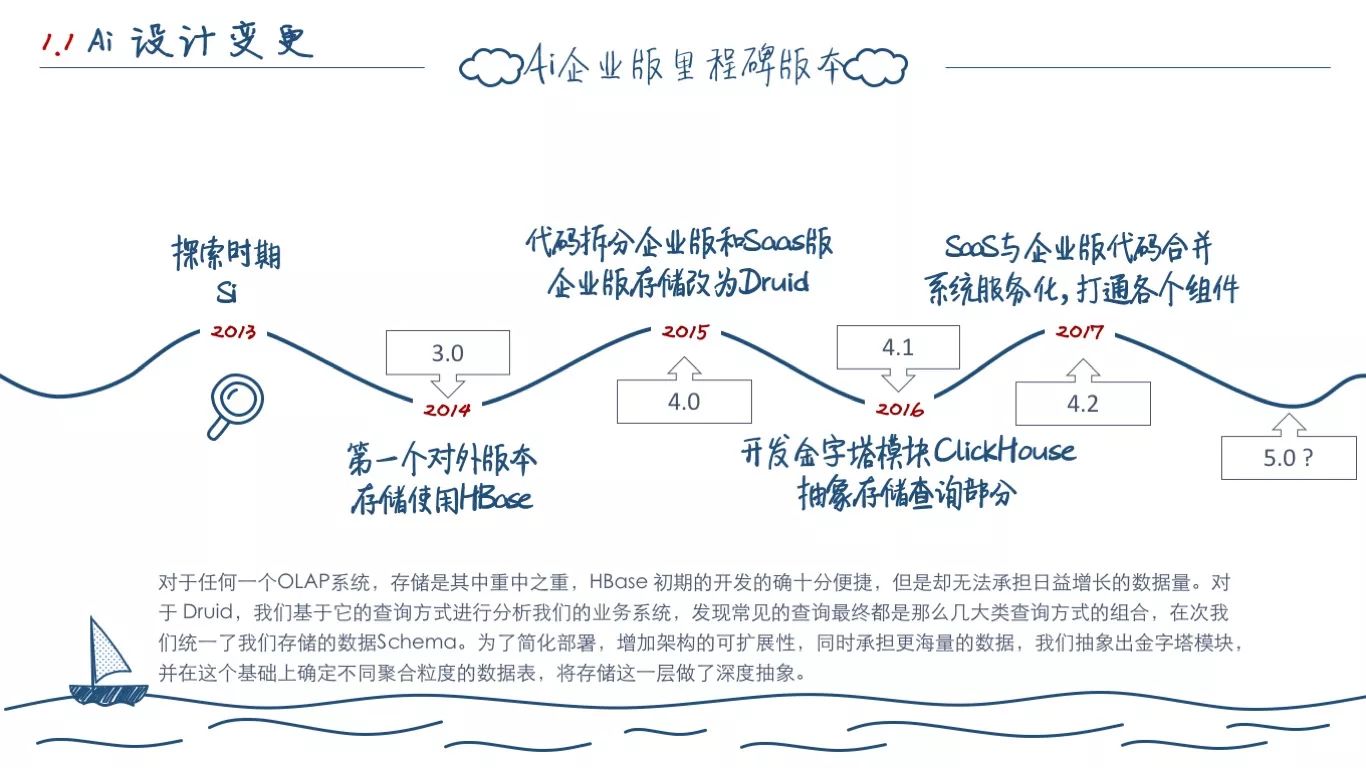
OneAPM 在 2013年开始涉足 APM 市场,当时在13年做了我们的第一代产品 Si ,它是那种庞大的单体应用,功能也十分单一。
在 2014年初 OneAPM 基于用户需求和学习国外同类产品 NewRelic 开发了第一版 Ai 3.0。它的架构非常简单,就是一个收集端收集探针的数据写入Kafka,然后落到HBase里,还有一个数据展示端直接查询HBase的数据做展示。
在2015年初的时候,企业版开始做架构演进,首先是在存储这块,对于之前用 HBase 的聚合查询部分改用 Druid,对于 Trace 和 Transaction 数据转而使用 MySQL,同时,我们学习国外竞品 dynaTrace 完善了我们的分析模型。
2016年的时候,我们发现存储是比较大的问题,无论是交付上,还是未来按照数据量扩容上。且 Druid 的部署、查询等都存在一些问题。在SaaS上线Druid版本之后,我们调研各类存储系统结合业务特点选用ClickHouse,并基于它开发了代号为金字塔的查询和存储模块。
2017年的时候,我们开始梳理各个业务系统、组件,将它们全部拆分,公共组件服务化、Boot化,打通了各个系统。
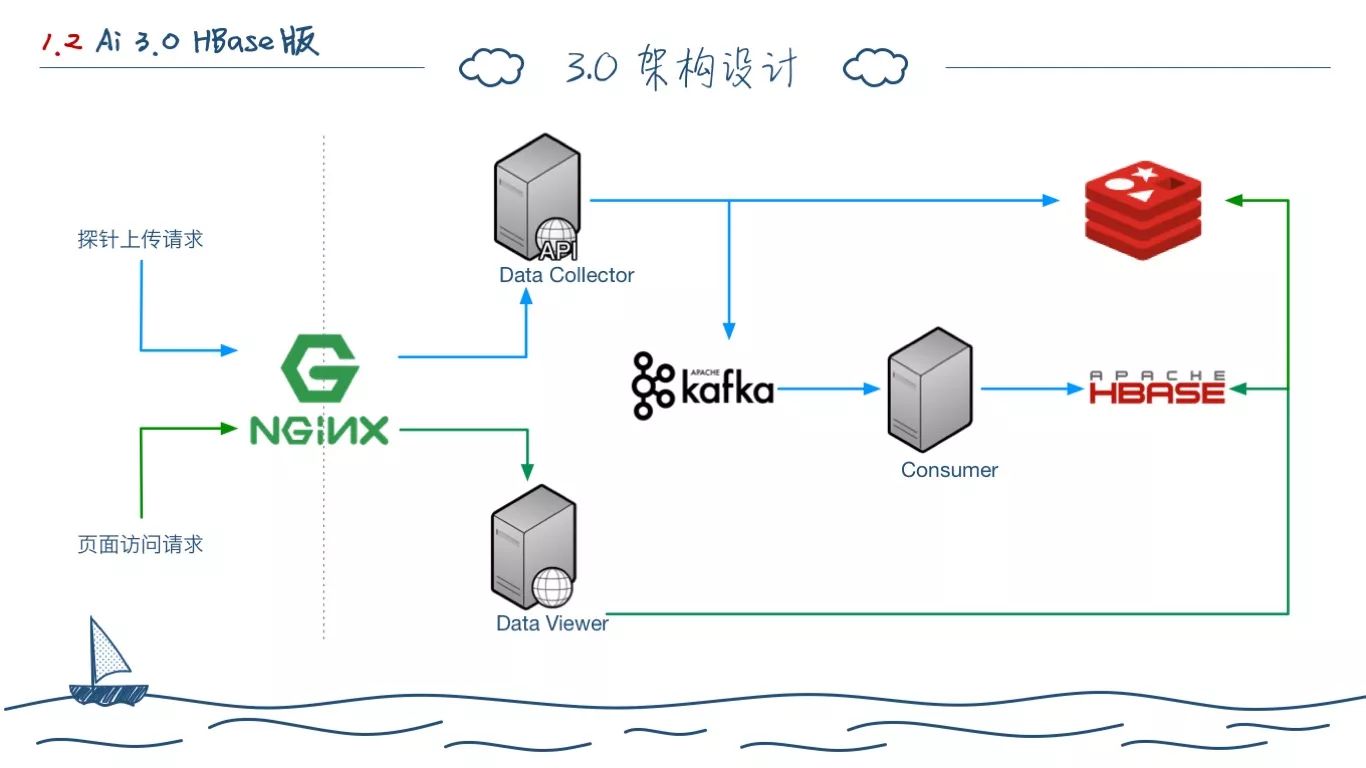
这是2014年初期的第一次封闭开发后的架构,当时正好大数据Hadoop之类的比较火,所以初期的架构我们完全是基于它来做的。我们的前端应用分为 Data Collector 数据收集端,Data Viewer 数据展示层。探针端走 Nginx 将数据上传至DC来进行分析处理,页面访问通过DV获取各种数据。 Data Viewer 初期是直接读取 HBase 的,后面进行简化,部分热数据(最近5分钟调用统计),缓存于 Redis。
这里要提一下它和云迹的应用性能分析的区别,我们为了减少HTTP请求量和流量(小公司)探针端做了聚合和压缩,一分钟上传一个数据包。所以DC端变为解包,然后写入Kafka,对于最新的 Trace 数据,我们写入 Redis 用于快速查询生成拓扑图。
Consumer 主要是处理翻译探针的 Metric 数据,将其翻译为具体的监控指标名称,然后写入 HBase。
这套架构部署到 SaaS 之后,我们的市场部就开始推广,当时的日活蛮高,几十万独立 IP。瞬间,我们就遇到了第一个直接问题——HBase 存在写入瓶颈,HBase在大量数据持续写入的场景下,经常OOM,十分痛苦。
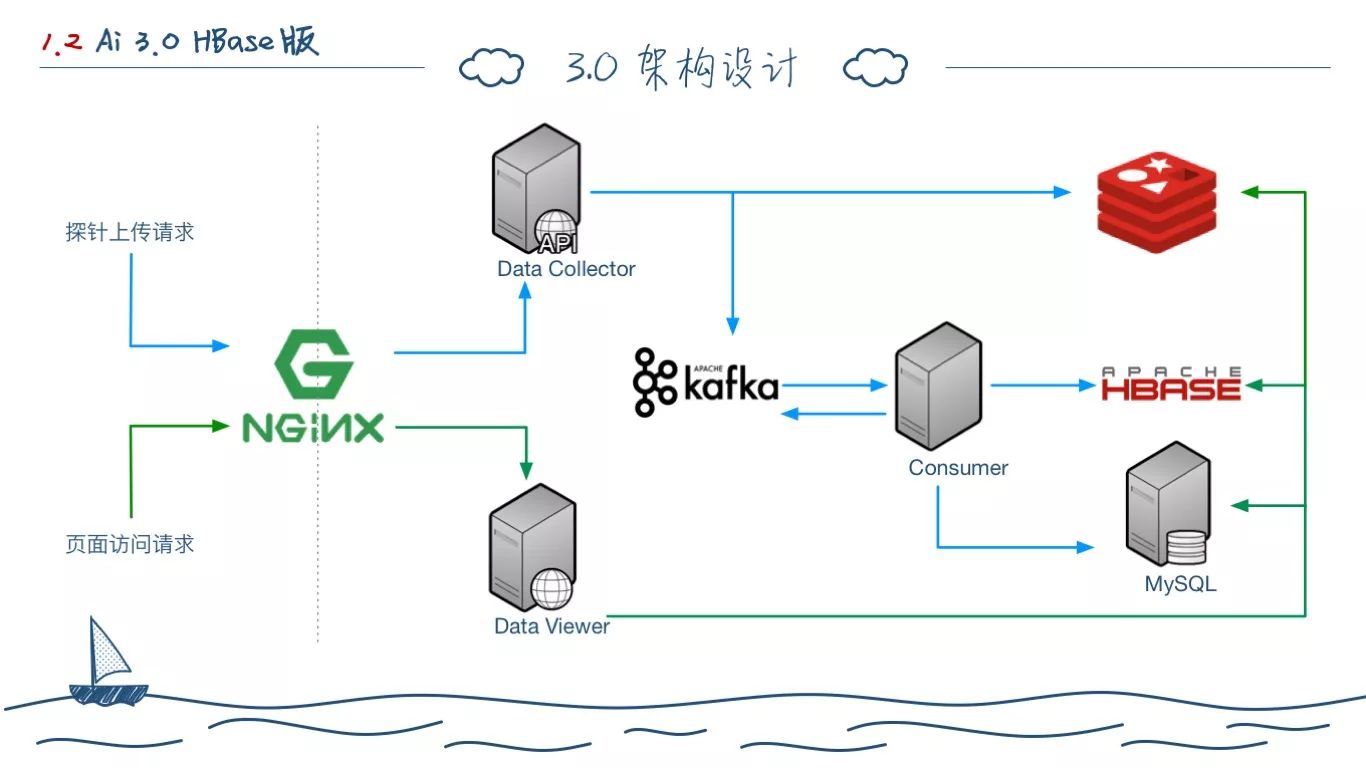
我们开始分析问题,首先,写入上,我们拆成了如图所示的三大部分,而不是之前的单一 HBase。
而就OLAP系统而言,数据读写上最大的特点就是写多读少,实时性要求不高。所以,查询中,HBase主要的性能问题是在对于历史某条具体的 Trace 调用指标的查询(也就是 Select One 查询)。我们在系统中引入了 MySQL,Metric 数据开始双写 HBase 和 MySQL。Redis 负责生成最新的调用拓扑,只有一条最新的 Trace 记录,MySQL 存储 Metric 数据,HBase 存储所有的 Trace 和 Metric 数据进行聚合查询。DV 还会将一些热查询结果缓存于 Redis 中。
这个时候的 Consumer 开始负责一定量的计算,会分出多个 Worker 在 Kafka 上进行一些处理,再将数据写入 Kafka,HBase 改为消费 Kafka 的数据。(这么做的目的,就是为了在线上拆分出不同的 Consumer 分机器部署,因为 SaaS 上的数据量,连 Consumer 都开始出现瓶颈。)
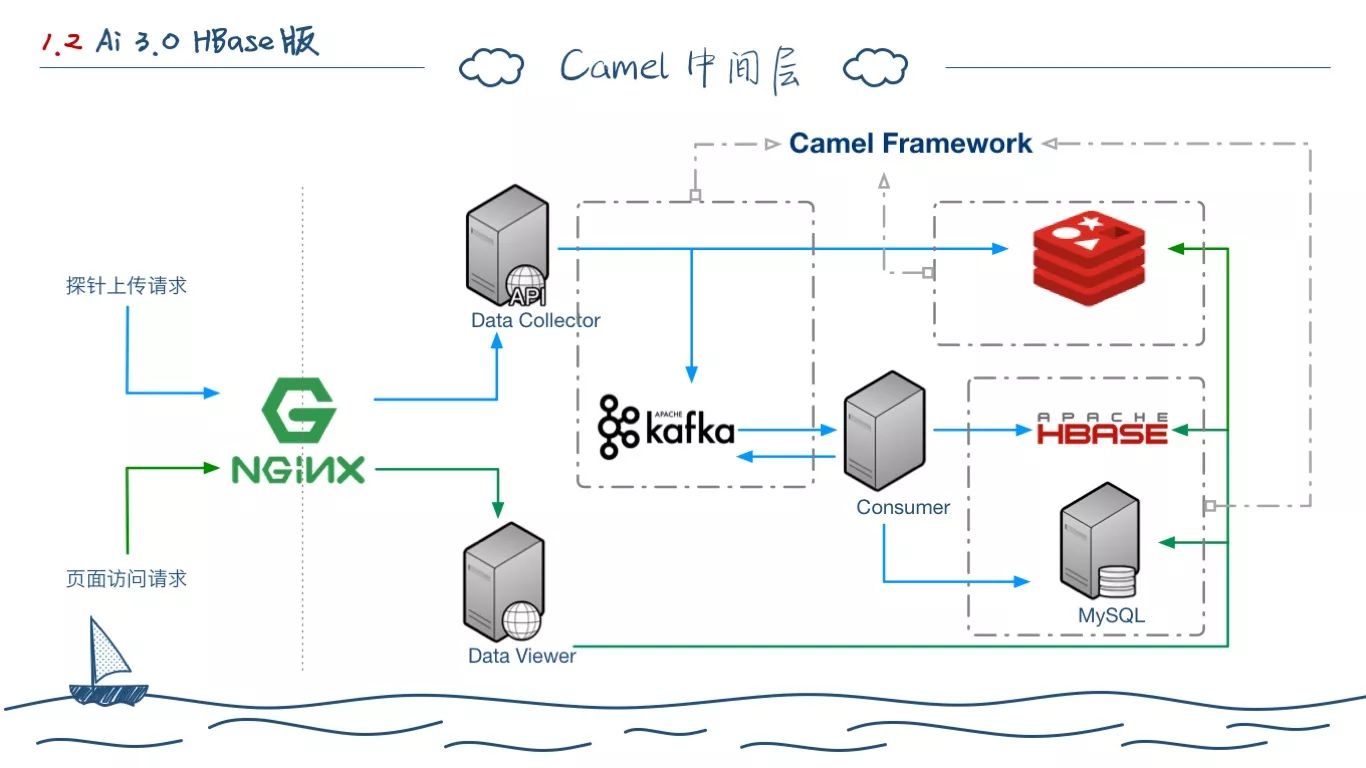
在这个时候,我们引入了 Camel 这个中间件,用它将 Kafka 的操作,MySQL 的操作,还有和 Redis 的部分操作都转为使用 Camel 操作。在我介绍为什么使用 Camel 之前,我想先简单介绍一下它。(下一页PPT)
我们在引入 Camel 的时候,主要考虑几个方面:
第一,屏蔽Kafka这一层。当时SOA还比较流行,我们希望能找到一个类似 ESB 的设计,能将各个模块的数据打通。就比如MQ,它可能是Kafka,也可能是 RabbitMQ,或者是别的东西,但是程序开发人员不需要关心。
第二,我们希望一定程序上简化部署运维的麻烦,因为所有的 Camel 调用 Route 的核心,就是 URL Scheme,部署配置变为生成 URL。而不是一个个变量属性配置。
第三,Camel 自身的集成路由,可以实现比较高的可用性,它有多 Source 可以定义选举,还有 Fallback,可以保证数据尽可能不会丢失。(我们就曾经遇到 Kafka 挂了丢数据的情况,大概丢了3个小时,后面通过配置失败写文件的 Camel 策略,数据很大程度上,避免了丢失。)
而且,上面的功能,基本都是写Camel DSL,而无需修改业务代码。核心就是一个词——解耦。

Camel 用官方的话来说,就是基于 Enterprise Integration Patterns 的 Integration Framework。在我看来,Camel 在不同的常见中间件上实现集成,Camel 自身定义好链路调用 DSL(URL Scheme 和 Java、Scala、Spring XML 的实现),还有核心的企业级集成模式的设计思想,组成了 Camel 这个框架。
我们通过定义类似右侧的数据调用路由,将Kafka等各类中间件完全抽象出来,应用程序的逻辑转为,将数据存入Camel Producer,或者从 Camel Router 中注册 Endpoint 获取数据,处理转入另一个数据 Endpoint。(回到前面的架构图)
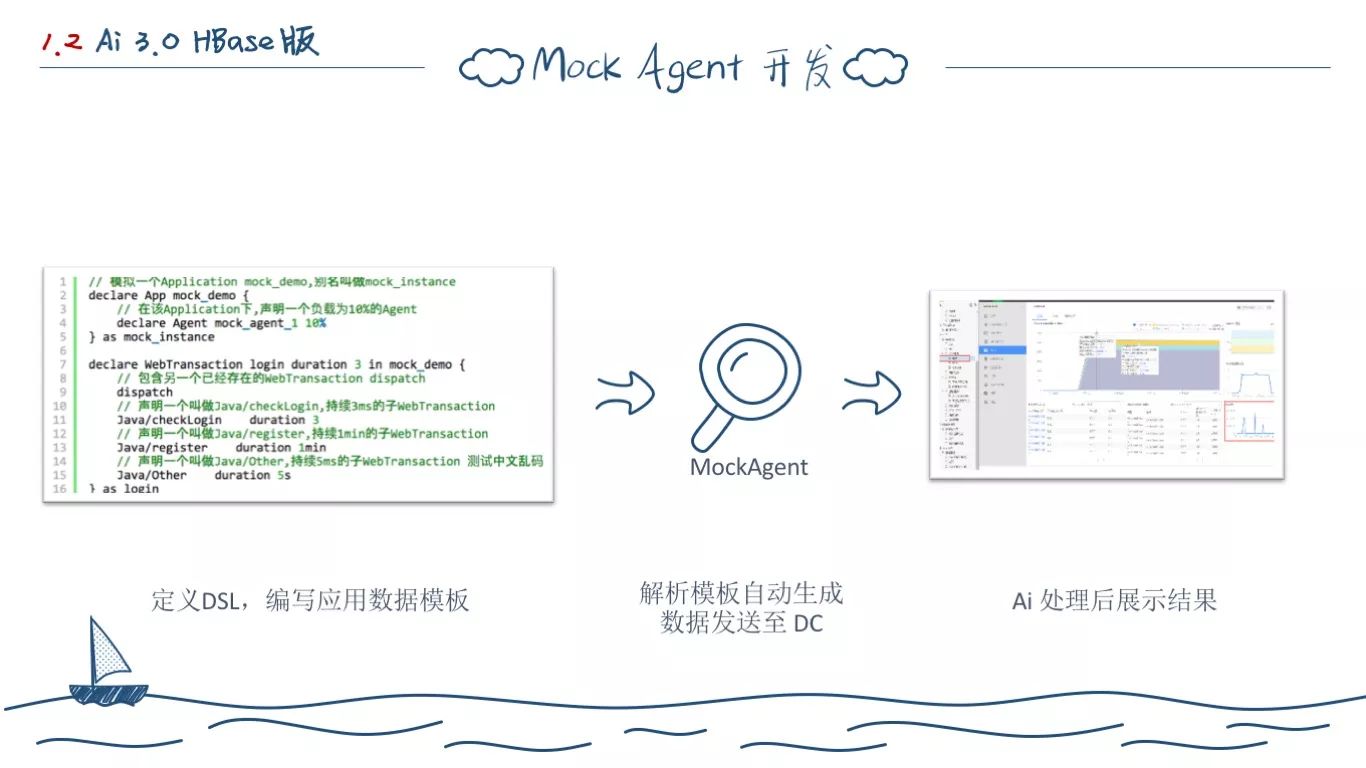
当然我们在开发过程中也设计了很多很有意思的小工具,Mock Agent 便是其中之一。
当时我们经常遇到的开发测试问题是,测试不好造数据来进行测试,无法验证某些特定指标的数据,开发无法脱离探针团队单独验证新功能和数据。于是我们决定自己写一套探针数据生成器,定义了一套DSL语言,完整地定义了应用、探针等数据格式,并能自动按照定义规则随机生成指定数据到后端。
测试需要做的事情,就是写出不同的模拟探针模板。第一,简化了测试。第二,将测试用例能代码化传承。避免人员流动的问题。
后面基于它,我们还写了超级有意思的压测工具,用其生成数据测试后端。还有自动化测试等。
当然,这也是我们尝试开发的第一个 DSL。
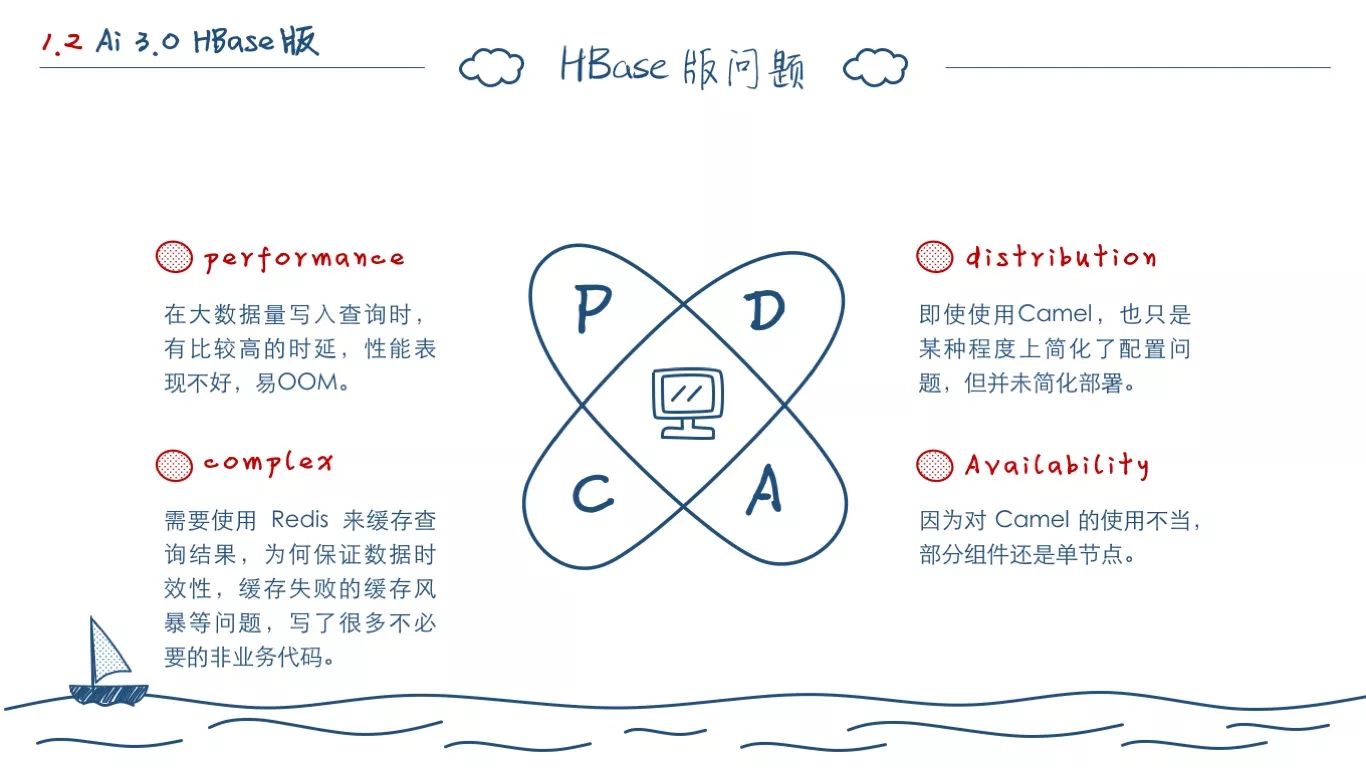
主要是我们无法避免写入热点问题,即使基于 Row Key 进行了写入优化,大数据量的写入也常常把 HBase 搞挂。
最关键的是,持续的 OOM 丢数据,已经给我们的运维带来的太多麻烦,对外的 SLA 也无法保证。(这个时间段你经常听到外面对OneAPM的评价就是数据不准,老是丢数据。)
基于 HBase 的查询时延也越来越高,甚至某种程度上,已经不大能支撑新的数据量。当时最高峰的时候,阿里云机器数量高达 20 台。所以,是时候考虑引入新的数据库了。
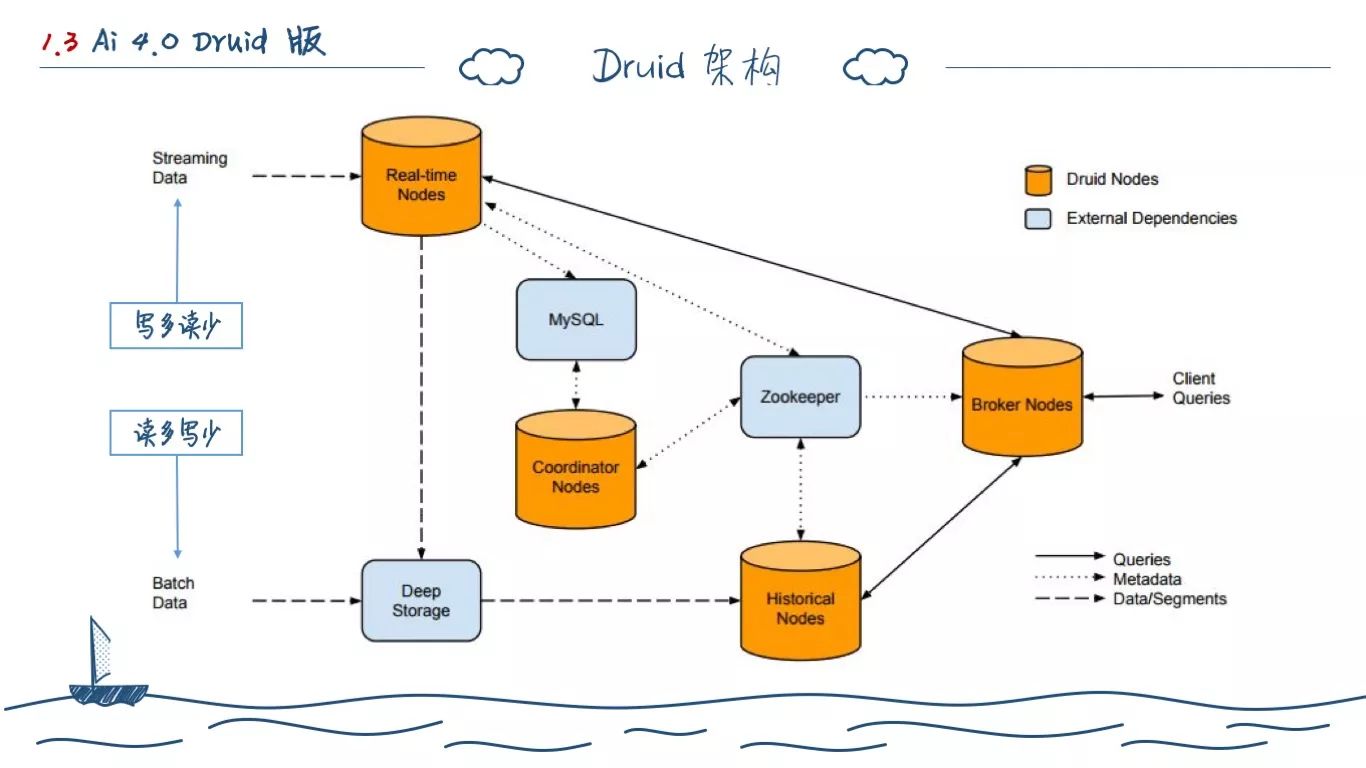
这个时候,来自 IBM 研究院的刘麒赟向我们推荐了Druid,并在我们后面的实践中取代了 HBase 作为主要的 Metric 存储。
2015年的时候 Druid 架构主要就是上述这张图,Druid 由4大节点组成, Real-time、Coordinator、Broker、Historical 节点,在设计之初就考虑任何一个节点挂了,不会影响其他节点。
Druid 对于数据的写入方式有两种,一种是实时的,直接写入 Real-time 节点,对应的是那种写多读少的数据,还有一种是批量的直接写入底层数据存储的方式,一般是对应读多写少的数据。这两种方式在 OneAPM 都有涉及,Ai 作为应用性能监控,对应的是海量的探针数据,主要是使用实时写入。Mi 是移动端性能监控,探针上传数据存在时延等问题,所以是在上层做了简单的处理缓冲后,批量写入 Deep Storage。
Real-time 节点主要接受实时产生的数据,例如 Kafka 中的数据。数据会在实时节点的内存中进行缓存处理,构建 memtable,然后定时生成 Segment 写入 Deep Storage。写入 Deep Storage 的数据会在 MySQL 生成 meta 索引。
Deep Storage 一般是 HDFS 或者是 NFS,我们在查询的时候,数据来源于 Deep Storage 或者是 Real-time 节点里面的数据。
协调节点主要是用于将 Segment 数据在 Historical 节点上分配,Historical 节点会自行动态从 Deep Storage 下载 Segment 至磁盘,并加载到内存查询提供结果。
Broker Nodes 只提供对外的查询,它不保存任何数据,只会对部分热点数据做缓存。它会从 Real-time 节点中查询到还在内存未写入 Deep Storage 的数据,并从 Historical 节点插入已经写入 Deep Storage 的数据,然后聚合合并返回给用户。
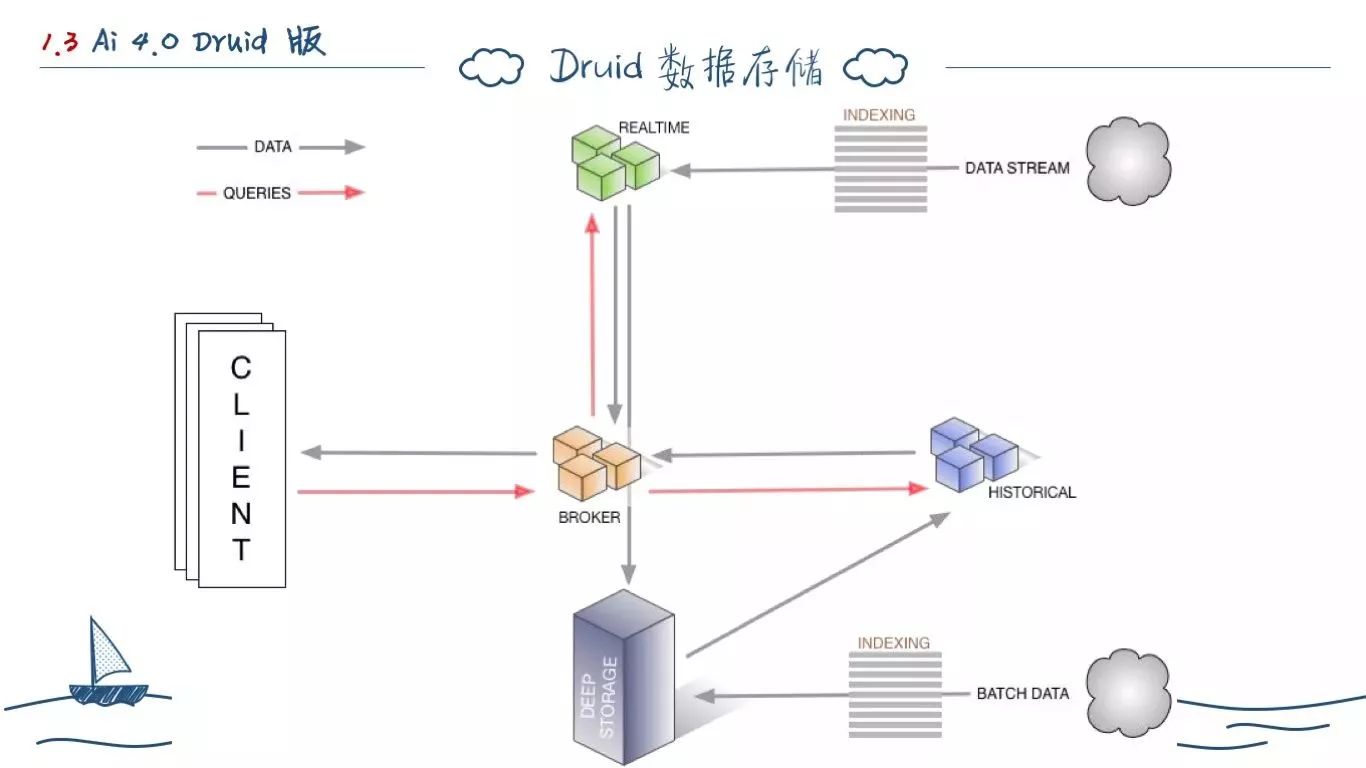
所以,我们可以看到数据写入和查询遵循上面的数据流图,这里我们没有把协调节点画出。
数据在 Druid 上的物理存储单位为 Segment,他是基于 LSM-Tree 模型存储的磁盘最小文件单位,按照时间范围划分,连续存储在磁盘上。 在逻辑上,数据按照 DataSource 为基本存储单元,分为三类数据:
Timestamp:时间戳,每条数据都必须有时间。
Dimension:维度数据,也就是这条数据的一些元信息。
Metric:指标数据,这类数据将在 Druid 上进行聚合和计算,并会按照一定的维度聚合存储到实际文件中。
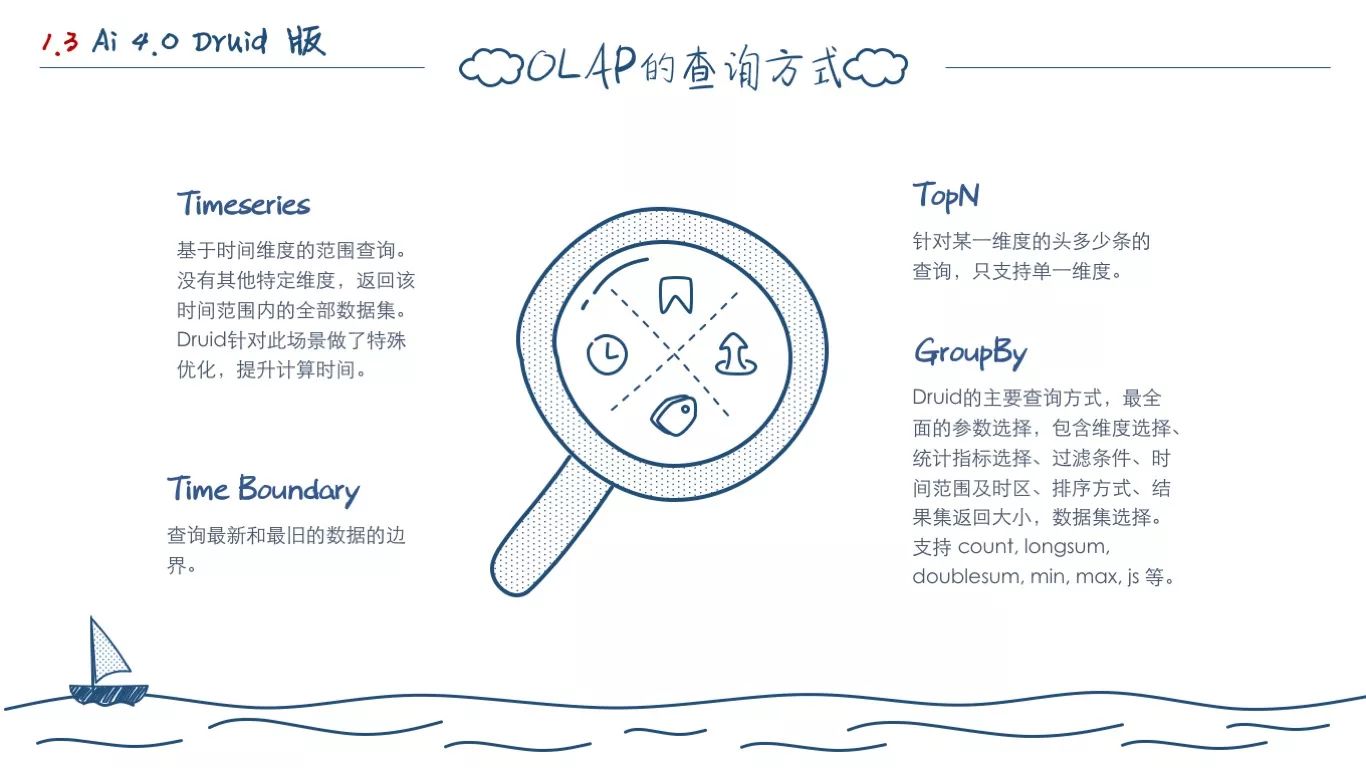
除了上述说的查询方式 OLAP 的数据其实有几大特性很关键:
所以,对于一个 OLAP 系统的数据库,它需要解决的问题也就两个维度:写入 和 查询。
对于 Druid 而言,它支持的查询有且不仅有上面的四种方式。但是,我们进行梳理后发现,OneAPM的所有业务查询场景,都可以基于上述四种查询方式组合出来。
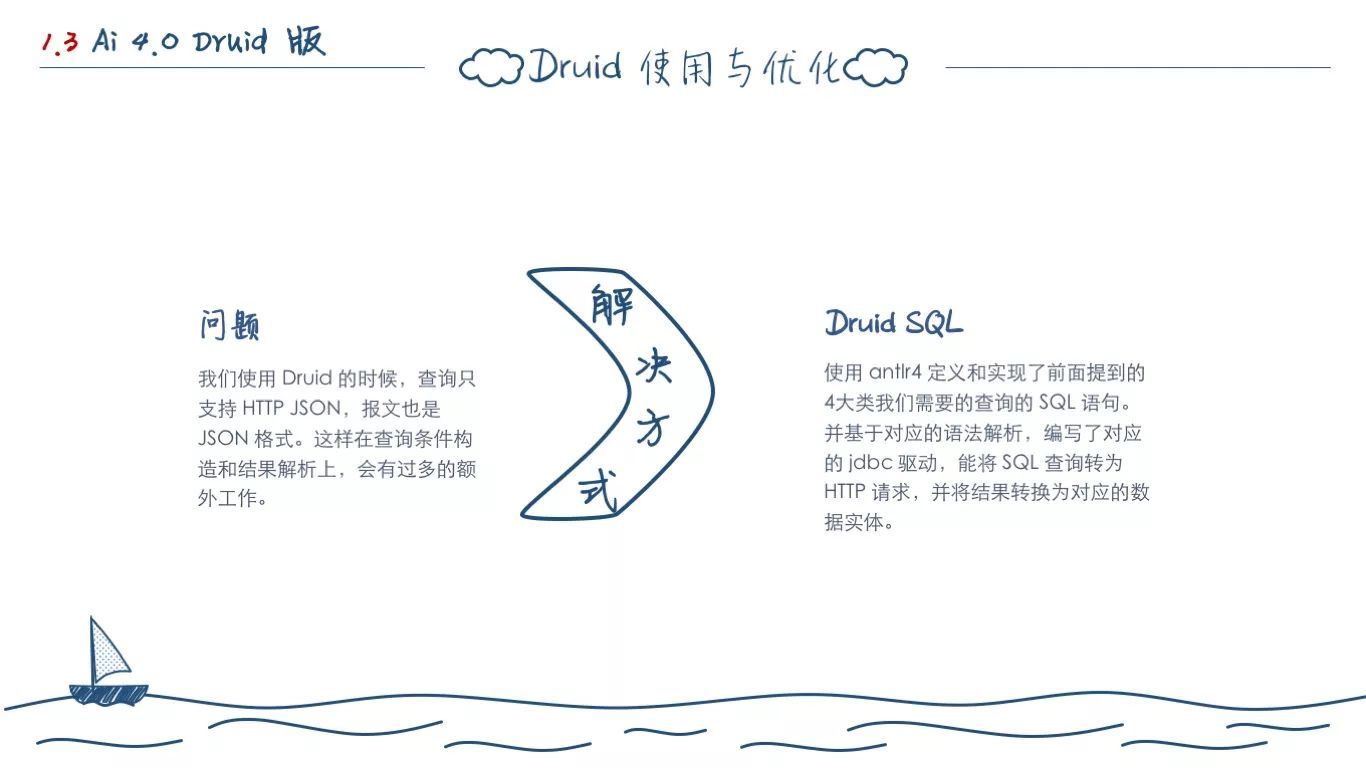
于是在基于 Druid 开发的时候我们遇到的第一个问题就是 Druid 的查询方式是 HTTP,返回结果基本是 JSON。我们用 Druid 比较早,那个时候的 Druid 还不像现在这样子,支持 SQL 插件。
我们需要做的第一个事情,就是如何简化这块集成开发的难度。我们第一时间想到的就是,在这上面开发一套 SQL 查询语法。我们使用 Antlr4 造了一套 Druid SQL,基于它可以解析为直接查询 Druid 的 JSON。
并基于这套 DSL 模型,我们开发了对应的 jdbc 驱动,轻松和 MyBatis 集成在一起。最近这两周,我也尝试在 ES 上开发了类似的工具,SQL 模型与解析基本写完了:
https://github.com/syhily/elasticsearch-jdbc
当然这种实现不是没有代价的,我们压测的同事和我抱怨过,这种方式相比纯 JSON 的方式,性能下降了 50%。我觉得,这里我们当时这么设计的首要考虑,是在于简化开发难度,SQL对每个程序员都是最熟悉的,其次,我们还有一层考虑就是未来更容易适配别的存储平台,比如 ES(当时其实在15年中旬的时候也列入我们的技术选型)。
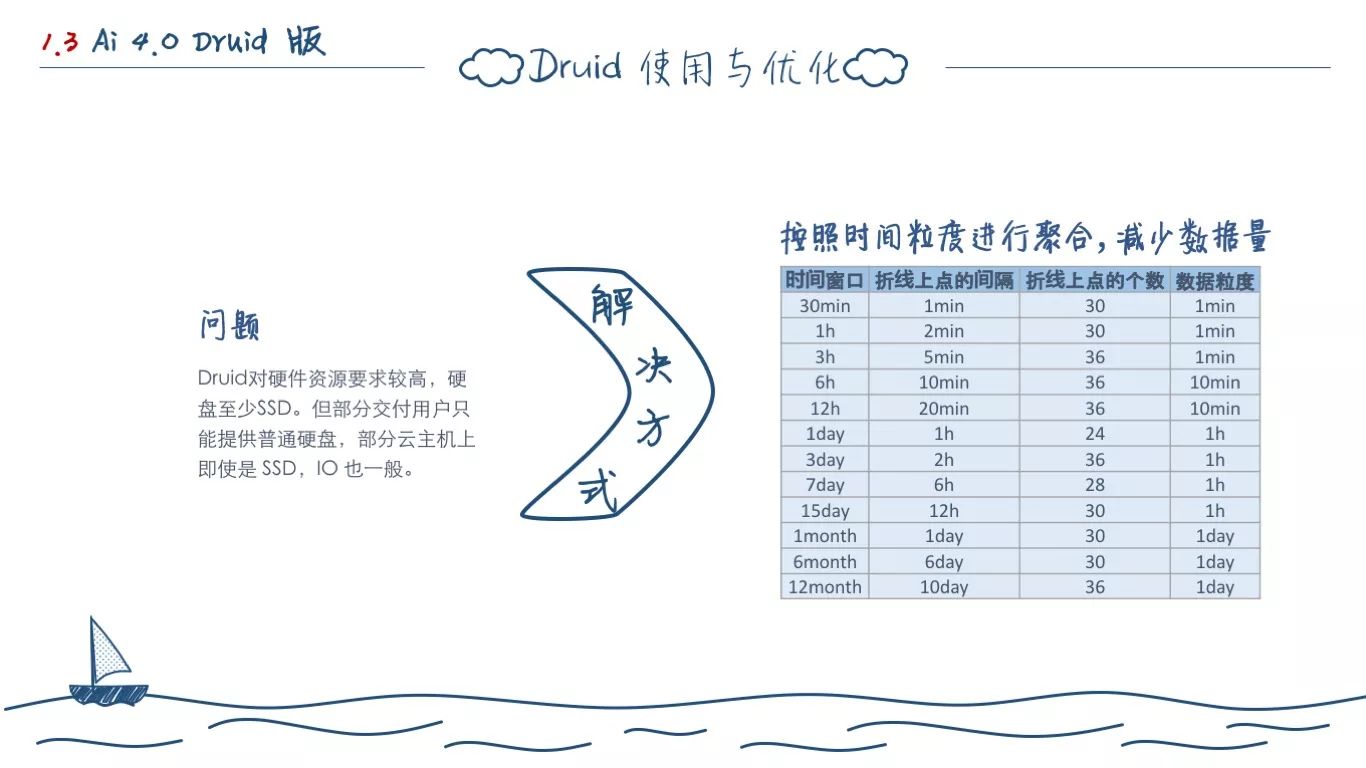
Druid 另一个比较大的问题就是,它实在是太吃硬件了。记得之前和今日头条的广告部门研发聊天,聊到的第一个问题就是 Druid 的部署需要 SSD。
我们在前面的架构分析当中很容易发现,Druid 本质上还是属于 Hadoop 体系里面的,它的数据存储还是需要 HDFS,只是它的数据模型基于 LSM-Tree 做了一些优化。换言之,它还是很吃磁盘 IO。每个 Historical 节点去查询的时候,都有数据从 Deep Storage 同步的过程,都需要加载到内存去检索数据。虽然数据的存储上有一定的连续性,但是内存的大小直接决定了查询的快慢,磁盘的 IO 决定了 Druid 的最终吞吐量。
另外一个问题就是,查询代价问题。Druid 上所有的数据都是要制定聚合粒度的,小聚合粒度的数据支持比它更大粒度的聚合数据的查询。
比如说,数据是按照1分钟为聚合粒度存储的话,我们可以按照比1分钟还要长的粒度去查询,比如按照5分钟一条数据的方式查询结果。但是,查询的时间聚合单位越大,在分钟的聚合表上的代价也就越高,性能损失是指数级的。
针对上面两个问题,我们的最终解决方案,就是数据不是写一份。而是写了多份,我们按照业务的查询间隔设置了3~4种不同的聚合表(SaaS和企业级的不同)。查询的时候按照间隔路由到不同的 Druid 数据表查询。某种程度上规避了磁盘 IO 瓶颈和查询瓶颈。
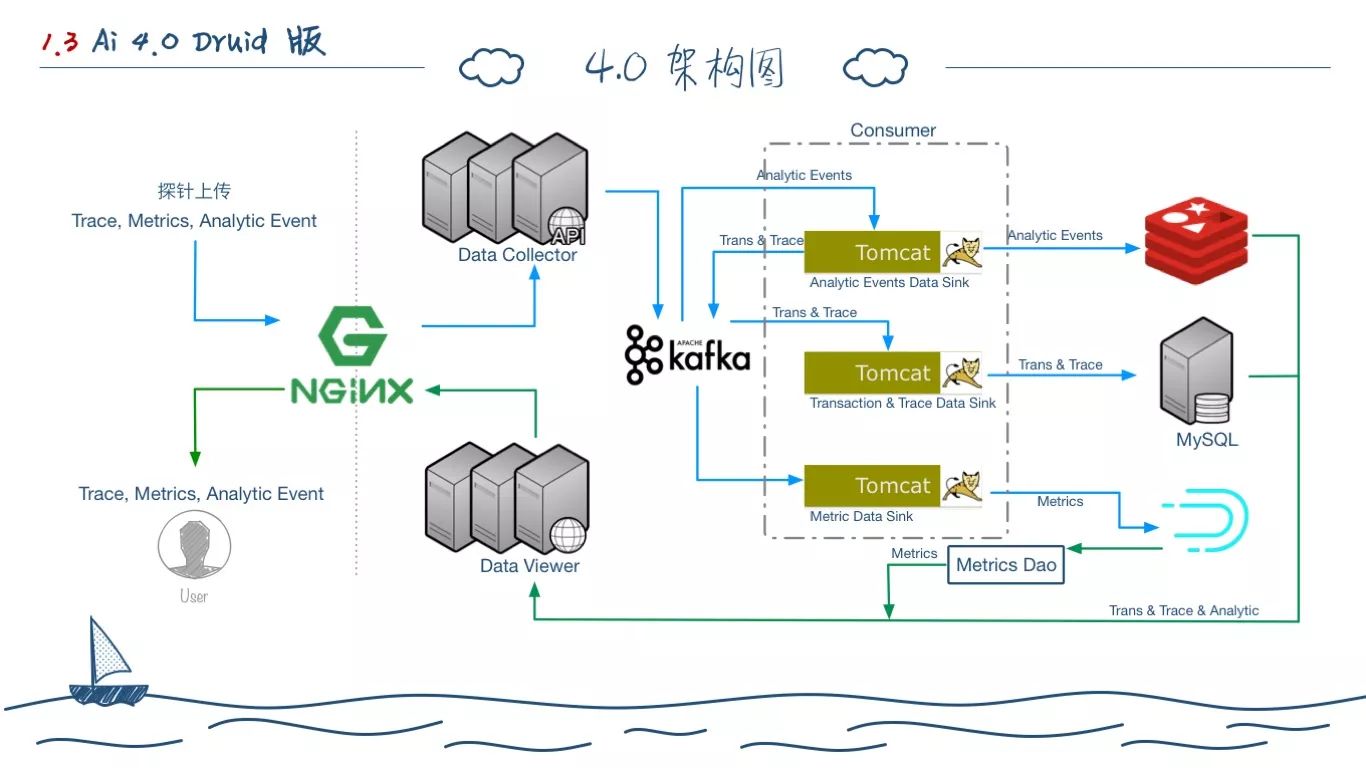
在充分调研和实践后,有了上面的新架构图。3.0 到 4.0 的变化主要在HBase存储的替换,数据流向的梳理。
我们将探针的数据分为三大类,针对每类的数据,都有不同的存储方式和处理方式。
探针上传的数据,分为三大类,Trace、Metrics、Analytic Event。Trace 就是一次完整的调用链记录,Metrics 就是系统和应用的一些指标数据。Analytic 数据使我们在探针中对于一些慢 Trace 数据的详细信息抓取。最终所有的 Metrics 数据都写入 Druid,因为我们要按照不同的查询间隔和时间点去分析展示图表。Trace 和事物类信息直接存储 MySQL,它对应的详细信息还需要从 Druid 查询。对于慢 Trace 一类的分析数据,因为比较大,切实时变化,我们存入到 Redis 内。
但是,Druid 一类的东西从来都不是一个开箱即用的产品。我们前面在进行数据多写入优化,还有一些类似 SelectOne 查询的时候,越来越发现,为了兼容 Druid 的数据结构,我们的研发需要定制很多非业务类的代码。
比如,最简单的一个例子,Druid 中查到一个 Metric 指标数据为 0,到底是这个数据没有上传不存在,还是真的为 0,这是需要商榷的。我们有些基于 Druid 进行的基线数据计算,想要在 Druid 中存储,就会遇到 Druid 无法更新的弊端。换句话说,Druid 解决了我们数据写入这个直接问题,查询上适用业务,但是有些难用。
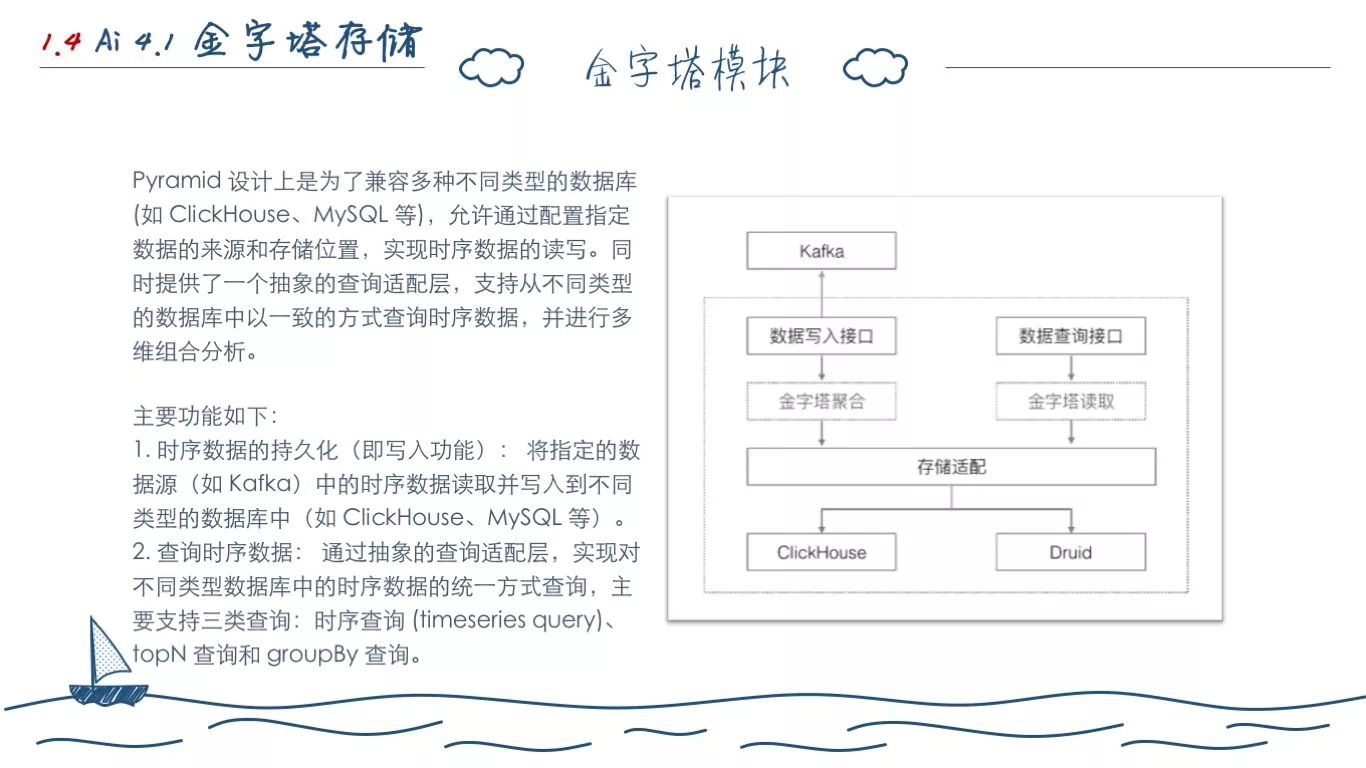
针对上述这些问题,我们在16年初开始调研开发了现有的金字塔存储模块。它主要由金字塔聚合模块 Metric Store 和金字塔读取模块 Analytic Store 两部分组成。
因为架构有一定的传承性。所以它和 Druid 类似,我们只支持 Kafka 的方式写入 Metric 数据,HTTP JSON 的方式暴露查询接口。基于它我们改造 Druid SQL,适配了现有的存储。它的诞生,第一点,解决了我们之前对于数据双写甚至多写的查询问题。第二点,抽象出存储部分的操作,以后可以方便适配别的存储。
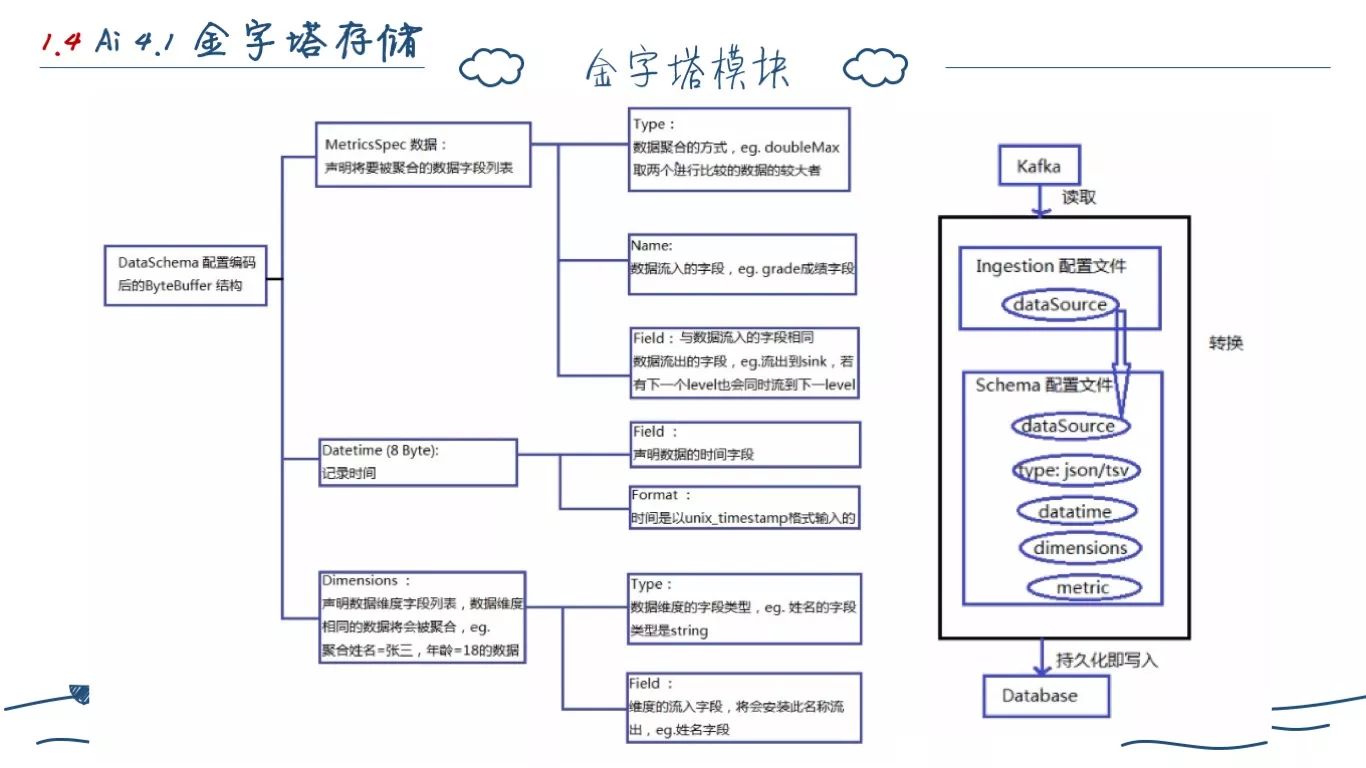
我们在要求业务接入金子塔的时候,需要它提供上述的数据格式定义。然后我们会按照前面定义的聚合粒度表,自动在 Backend 数据库创建不同的粒度表。
金字塔存储引擎的诞生,其实主要是为了 ClickHouse 服务的,接下来,请允许我先介绍一下 ClickHouse。
从某种角度而言,Druid 的架构,查询特性,性能等各项指标都十分满足我们的需求。无论是 SaaS,还是在 PICC 的部署实施结果都十分让人满意。
但是,我们还是遇到了很多问题。
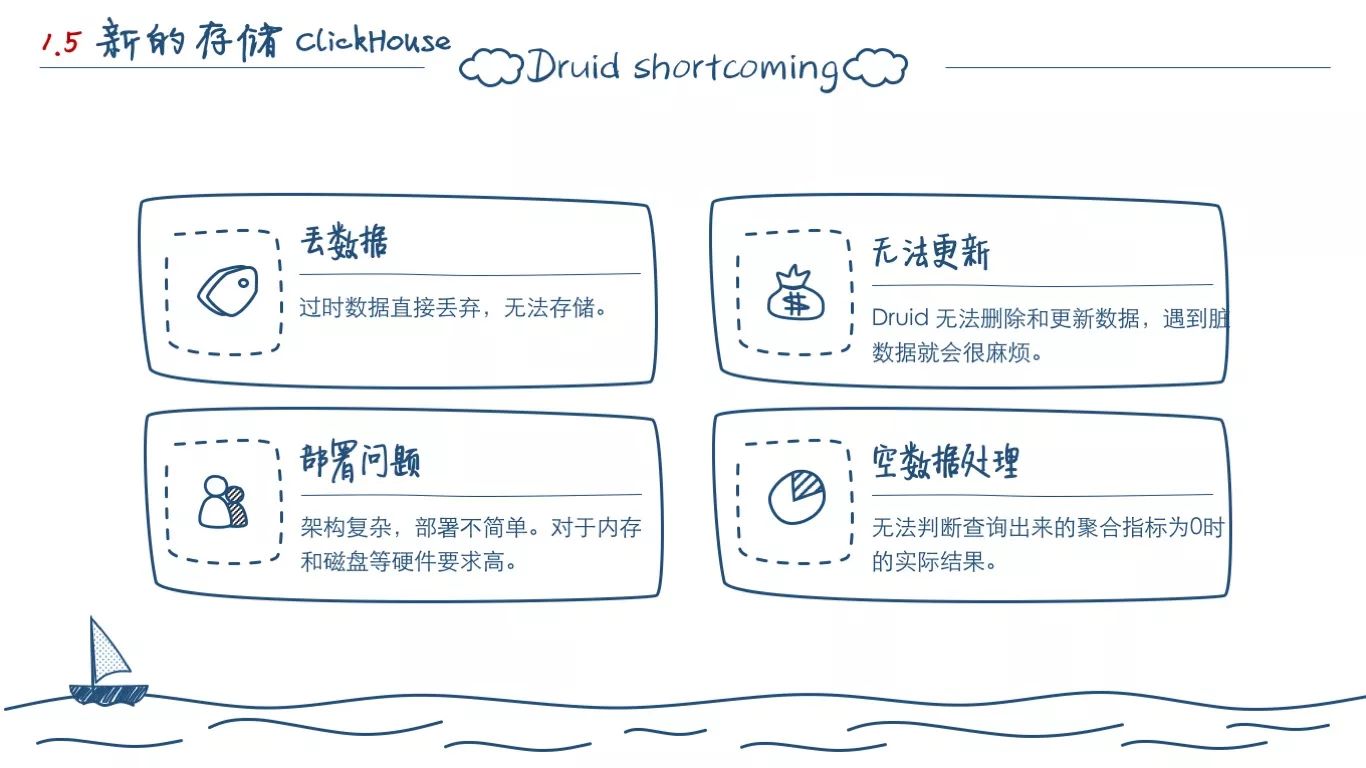
就是 Druid 的丢数据问题,因为它的数据对于时间十分敏感,超过一个指定阈值的旧数据,Druid 会直接丢弃,因为它无法更新已经持久化写入磁盘的数据。
和第一点类似,就是 Druid 无法删除和更新数据,遇到脏数据就会很麻烦。
Druid 的部署太麻烦,每次企业级的交付,实施人员基本无法在现场独立完成部署。(可以结合我们前面看到的架构图,它要MySQL去存meta,用 zk 去做协调,还有多个部署单元,不是一个简单到能傻瓜安装的程序。这也是 OneAPM 架构中逐渐淘汰一些组件的主要原因,包括我们后面谈到的告警系统。)
Druid 对于 null 的处理,查询出来的 6个时间点的数据都是0,是没数据,还是0,我们判断不了。
所以,我们需要在企业级的交付架构中,采取更简单更实用的存储架构,能在机器不变或者更小的情况下,实现部署,这个时候 ClickHouse 便进入我们的技术选型中。
https://yufan.me/evolution-of-data-structures-in-yandexmetrica/
在介绍 ClickHouse 之前,我觉得有必要分享一下常见的两种数据存储结构。
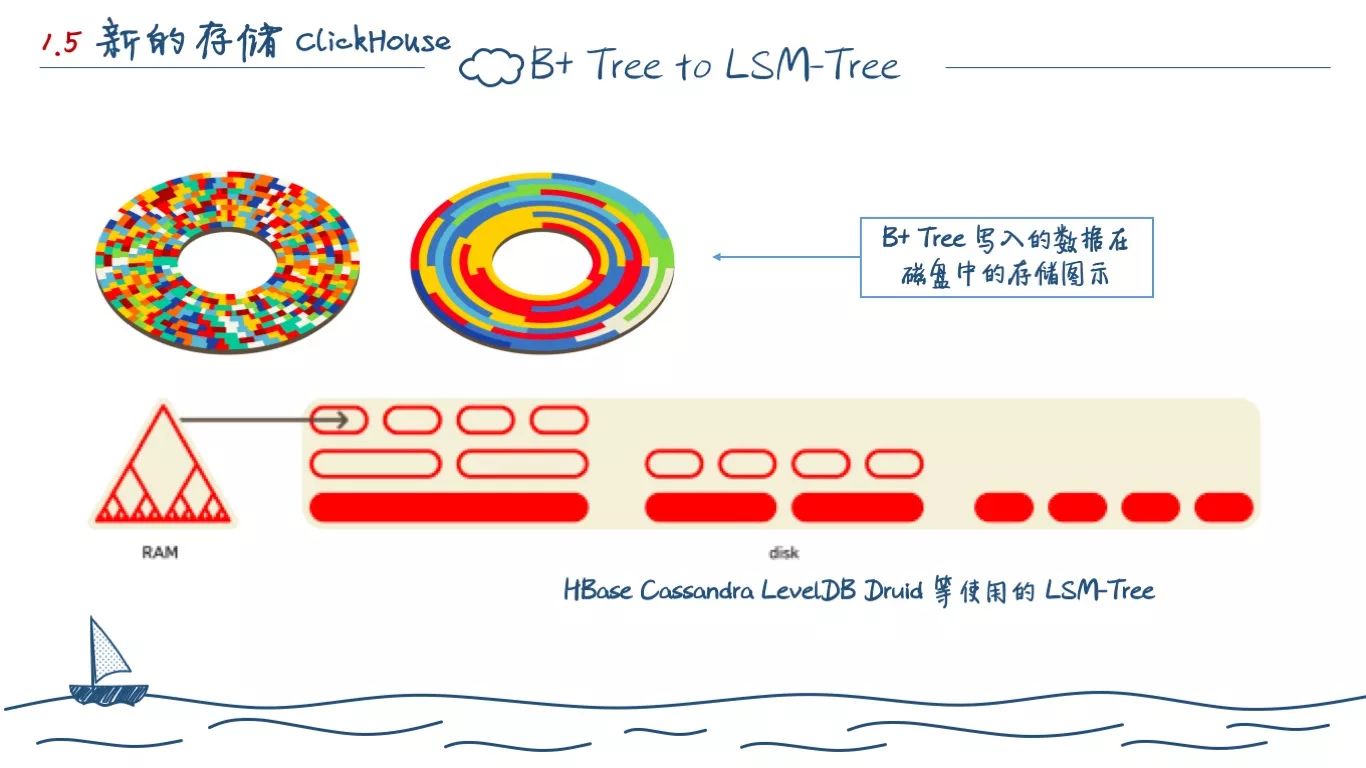
第一种是 B+ Tree或者是基于它的扩展结构,它常见于关系型数据的索引数据结构。我们以 MySQL 的 MyISAM 引擎为例,数据在其上存储的时候分为两部分,按照插入顺序写入的数据文件和 B+ Tree 的索引。叶子节点存储数据文件的位移。当我们读取一个索引中的范围数据时,首先从索引中查出一组满足查询条件的数据文件位移,然后按照查出来的位移依次去从数据文件中查找出实际的数据。
所以,我们很容易发现,我们想要检索的数据,往往在数据库上不是连续的,上图显示常见的数据库磁盘中的文件分布情况。当然我们可以换用 InnoDB,它会基于主机定义的索引,写入顺序更加连续。但是,这势必会导致写入性能十分难看。事实上,如果拿关系型数据库存储我们这种类似日志、探针指标类海量数据,势必会遇到的问题就是写入快,查询慢;查询快,写入慢的死循环。而且,扩容等操作基本不可能,分库分表等操作还会增加代码复杂度。
所以,在非关系型数据库里面,常见的存储结构是 LSM-Tree(Log-Structured Merge-Tree)。首先,对于磁盘而言,顺序写入的性能是最理想的。所以常见的 NoSQL 都是将磁盘看做一个大的日志,每次直接在后端批量增加新的数据以达到连续写入的目的。但就和 MyISAM 一样,会遇到查询时的问题。所以 LSM-Tree 就应运而生。
它在内存中和磁盘中分别使用两种不同的树结构存储数据,并同时对外提供查询能力。如 Druid 为例,在内存中的数据,会按照时间范围去聚合排序。然后定时写入磁盘,所以在磁盘中的文件写入的时候已经是排好序的。这也是为何 Druid 的查询一定要提供时间范围,只有这样,才能选取出需要的数据块去查询。
当然,聪明的你一定会问,如果内存中的数据,没有写入磁盘,数据库崩溃了怎么办。其实所有的数据,会先以日志的形式写入文件,所以基本不会丢数据。
这种结构,从某种角度,存储十分快,查询上通过各种方式的优化,也是可观的。我记得在研究 Cassandra 代码的时候印象最深的就是它会按照数据结构计算位移大小,写入的时候,不足都要对齐数据,使得检索上有近似 O(1) 的效果。
昨天汤总说道 Schema On Read,觉得很好,我当时回复说,要在 HDFS 上动手脚。其实本质上就可以基于 LSM-Tree 以类似 Druid 的方式做。但是还是得有时间这个指标,查询得有时间的范畴,基于这几个特点才有可能实现无 Schema 写入。

Druid 的特点是数据需要预聚合,然后按照聚合粒度去查询。而 ClickHouse 属于一种列式存储数据库,在查询 SQL 上,他和传统的关系型数据库十分类似(SQL引擎直接是基于MySQL的静态库编译的)它对数据的存储索引进行优化,按照 MergeEngine 的定义去写入,所以你会发现它的查询,就和上面的图一样,是连续的数据。
因为 ClickHouse 的文档十分少,大部分是俄文,当时我在开发的时候,十分好奇去看过源码。他们的数据结构本质上还是树,类似 LSM-tree。印象深刻的是磁盘操作部分的源码,是大段大段的汇编语句,甚至考虑到4K对齐等操作。在查询的时候也有类似经验性质的位移指数,他们的注释就是基于这种位移,最容易命中数据。
对于 ClickHouse,OneAPM 乃至国内,最多只实现用起来,但是真正意义上的开发扩展,暂时没有。因为 ClickHouse 无法实现我们的聚合需求,金字塔也为此扩展了聚合功能。和 Druid 一样,在 ClickHouse 上创建多种粒度聚合库,然后存储。
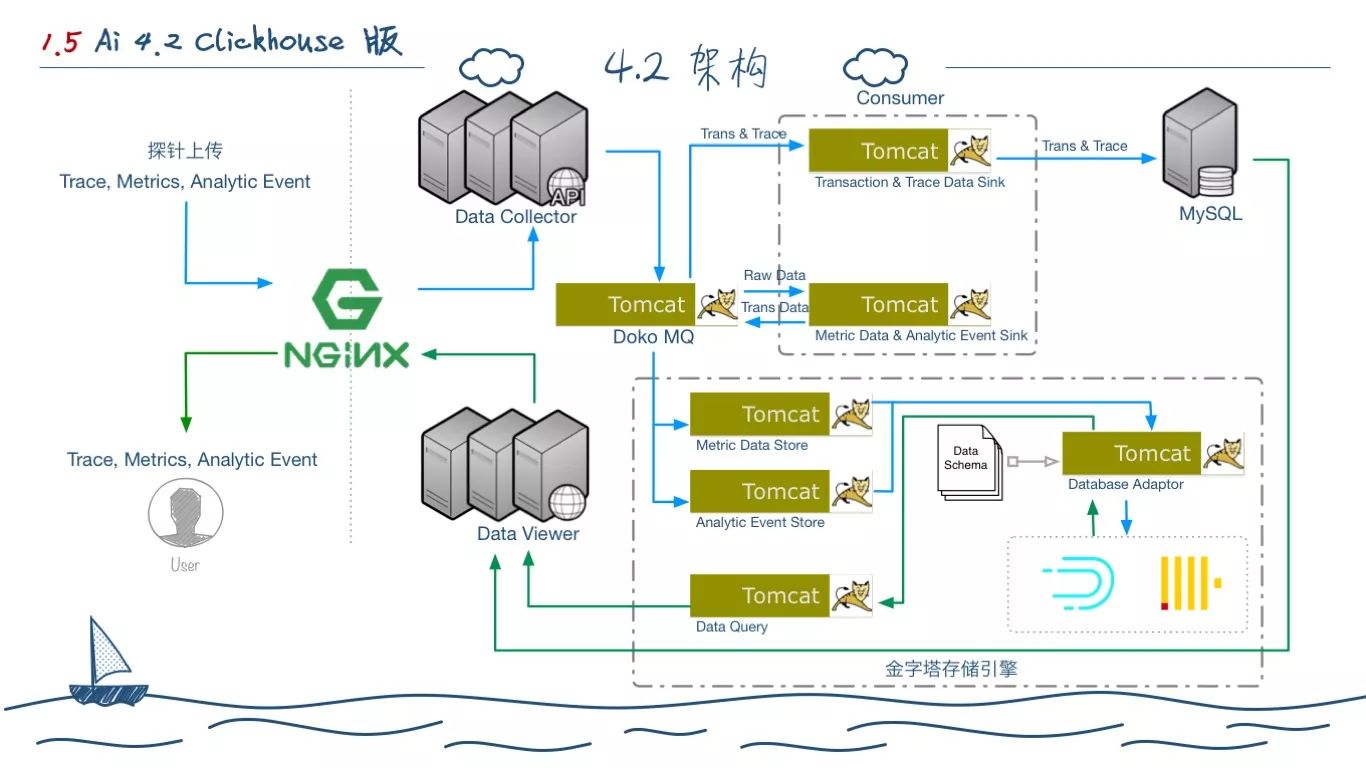
这个阶段的架构,就已经实现了我们最初的目标,将所有的中间件解耦,我们没有直接使用 Kafka 原生的 High Level API,而是基于 Low Level API开发了 Doko MQ。目的是为了实现不同版本 Kafka 的兼容,因为我们现在还有用户在使用 0.8 的 Kafka 版本。Doko MQ 只是一层外部的封装,Backend 不一定是 Kafka,考虑到有对外去做 POC 需求,我们还原生支持 Redis 做MQ,这些都在 Doko 上实现。
存储部分,除了特定的数据还需要专门去操作 MySQL,大部分直接操作我们开发的金字塔存储,它的底层可以适配 Druid 和 ClickHouse,来应对 SaaS 和企业级不同数据量部署的需要。对外去做 POC 的时候,还支持 MySQL InnoDB 的方式,但是聚合一类的查询,需要耗费大量的资源。
部署与交付是周一按照汤总的要求临时加的,可能 PPT 准备的不是很充分,还请大家多多包涵。
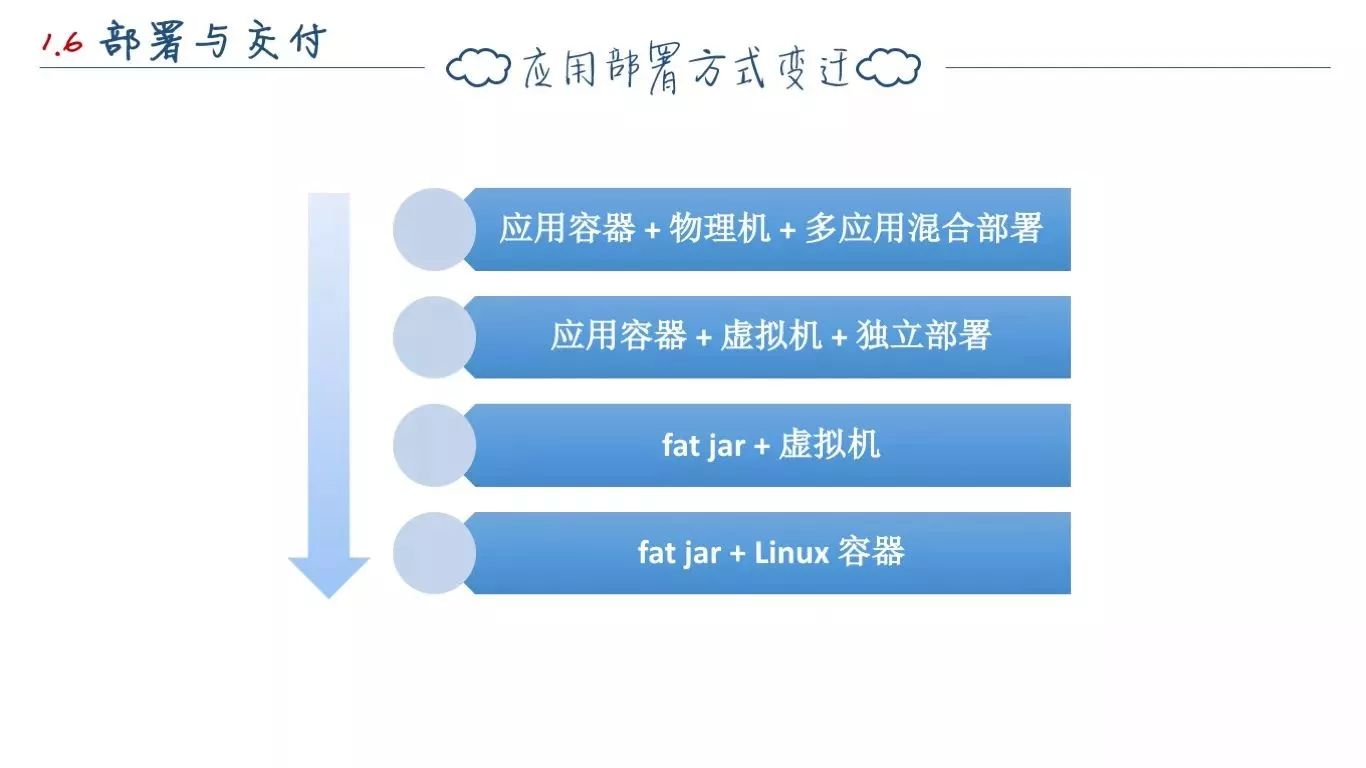
Java 应用部署于应用容器中,其实是受到 J2EE 的影响,也算是 Java Web 有别于其他 Web 快速开发语言的一大特色。一个大大的 war 压缩包,包含了全部的依赖,代码,静态资源,模板。
在虚拟化流行之前,应用都是部署在物理机上的,为了节约成本,多 war 包部署在一个 Servlet 容器内。
但是为了部署方便,如使用的框架有漏洞、项目 jar包的升级,我们会以解压 war 包的方式去部署。或者是打一个不包含依赖的空 war 包,指定容器的加载某个目录,这样所有的war项目公用一套公共依赖,减少内存。当然缺点很明显,容易造成容器污染。
避免容器污染,多 war 部署变为多虚拟机单 war、单容器。
DevOps 流行,应用和容器不再分离,embedded servlet containers开始流行, Spring Boot 在这个阶段应运而生。于是项目部署变为 fat jar + 虚拟机。
Docker的流行,开始推行不可变基础设施思想,实例(包括服务器、容器等各种软硬件)一旦创建之后便成为一种只读状态,不可对其进行任何更改。如果需要修改或升级某些实例,唯一的方式就是创建一批新的实例以替换。
基于此,我们将配置文件外置剥离,由专门的配置中心下发配置文件。
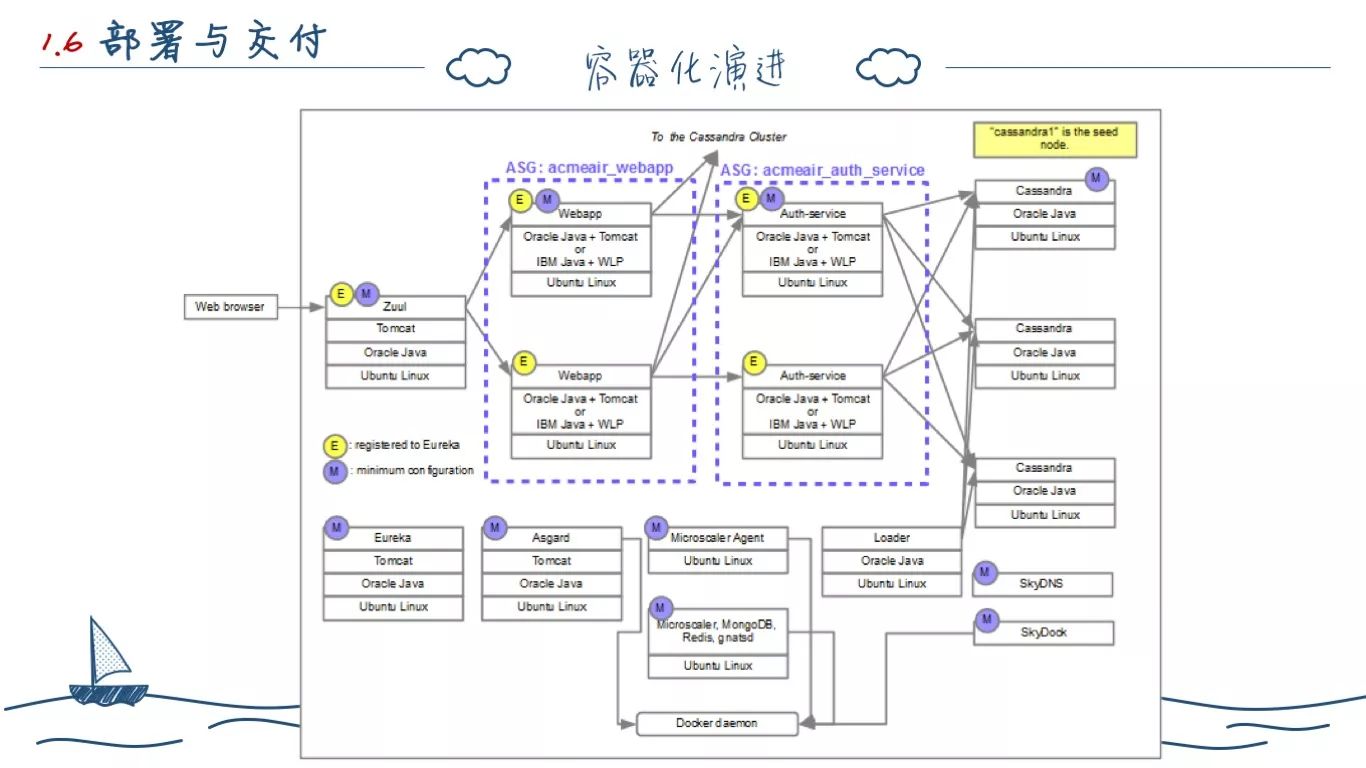
最初的时候,Docker 只属于我们的预研项目,当时 Docker 由刘斌(他也是很多中文 Docker 书的译者)引入,公司所有的应用都实现了容器化。这一阶段,我们所有的应用都单独维护了一套独立的 Docker 配置文件,通过 Maven 打包的方式指定 Profile 的方式,然后部署到专门的测试环境。换句话说,Docker 只是作为我们当时的一种测试手段,本身可有可无。
2015年上半年,红帽的姜宁老师加入 OneAPM,他带来了 Camel 和 AcmeAir。AcmeAir 本来是 IBM 对外吹牛逼卖他的产品的演示项目,Netflix 公司合作之后觉得不好,自己开发了一套微服务架构,并把 AcmeAir 重写改造成它组件的演示项目,后面 Netflix 全家桶编程了现在很多北京企业在尝试的 Spring Cloud。而 AcmeAir 在 PPT 中的 Docker 部署拓扑也成了我们主要的学习方式。
那个时候还没有 docker-compose、docker-swarm,我们将单独维护的配置文件,写死的配置地址,全部变为动态的 Hosts,本质上还是脚本的方式,但是已经部分实现服务编排的东西。
然后我们开始调研最后选型了 Mesos 作为我们主要的程序部署平台,使用 Mesos 管理部署 Docker 应用。在上层基于 Marthon 的管理 API 增加了配置中心,原有脚本修改或者单独打包的配置文件变为配置中心下发的方式。最后,Mesos 平台只上线了 SaaS 并部署 Pinpoint 作为演示项目,并未投产。
后面,在告警系统的立项开发过程中,因为要和各个系统的集成测试需要,我们慢慢改写出 docker-compose 的方式,废弃掉额外的 SkyDNS。
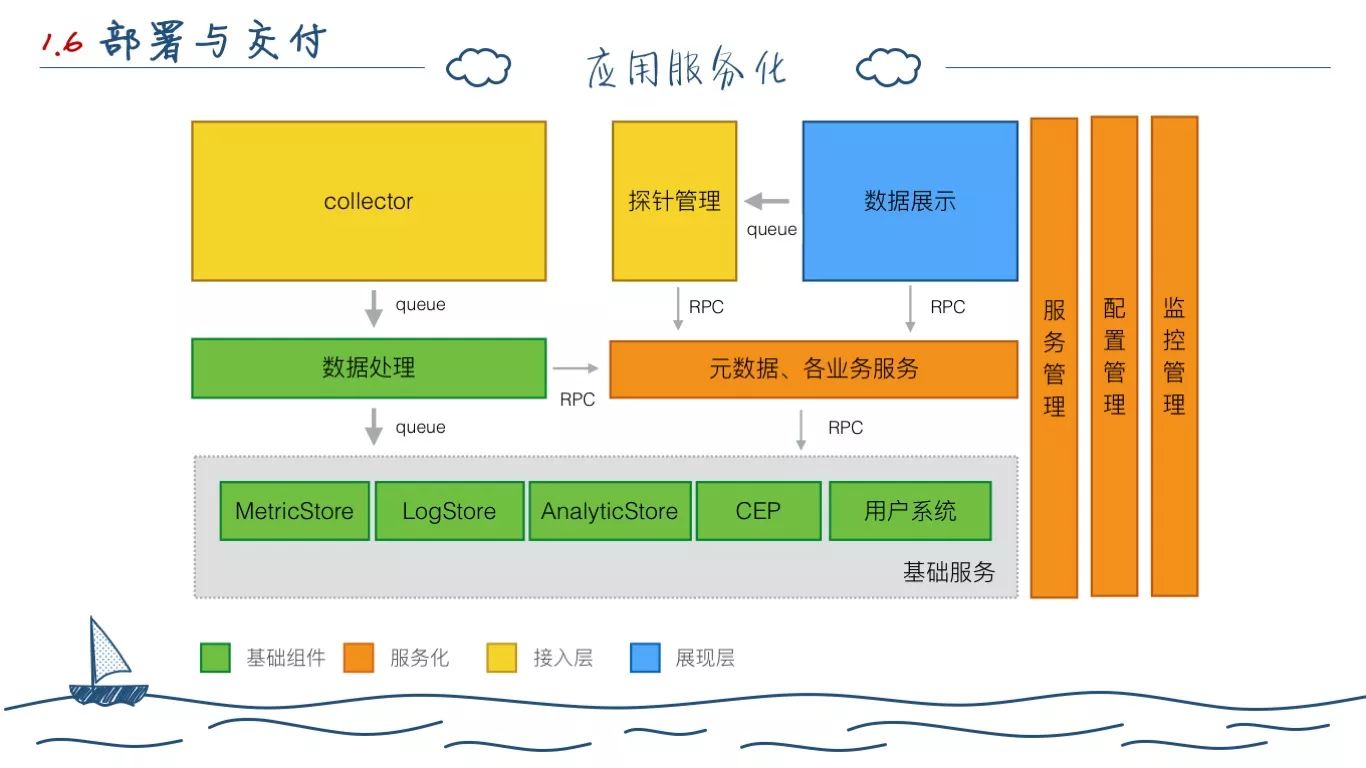
Mesos 计划的夭折,主要原因是我们当时应用还没有准备好,我们的应用主要还都是单体应用,各个系统间没有打通。于是在 16年我们解决主要的存储问题之后,就开始着力考虑应用集成的问题。
应用服务化是我们的内部尝试,是在一次次测试部署和对外企业交付中的血泪总结。当时我们考虑过 Spring Integration,但是它和 Camel 基本如出一辙,也调研过 Nexflix 全家桶,最后我们只选用了里面的 zuul 做服务网关。
在应用层面,我们按照上图所示,将所有的应用进行服务化拆分,分成不同的组件开发维护,并开发了注册中心等组件。RPC 这边,我们没有使用 HTTP,而是和很多公司一样包装了 Thrift。
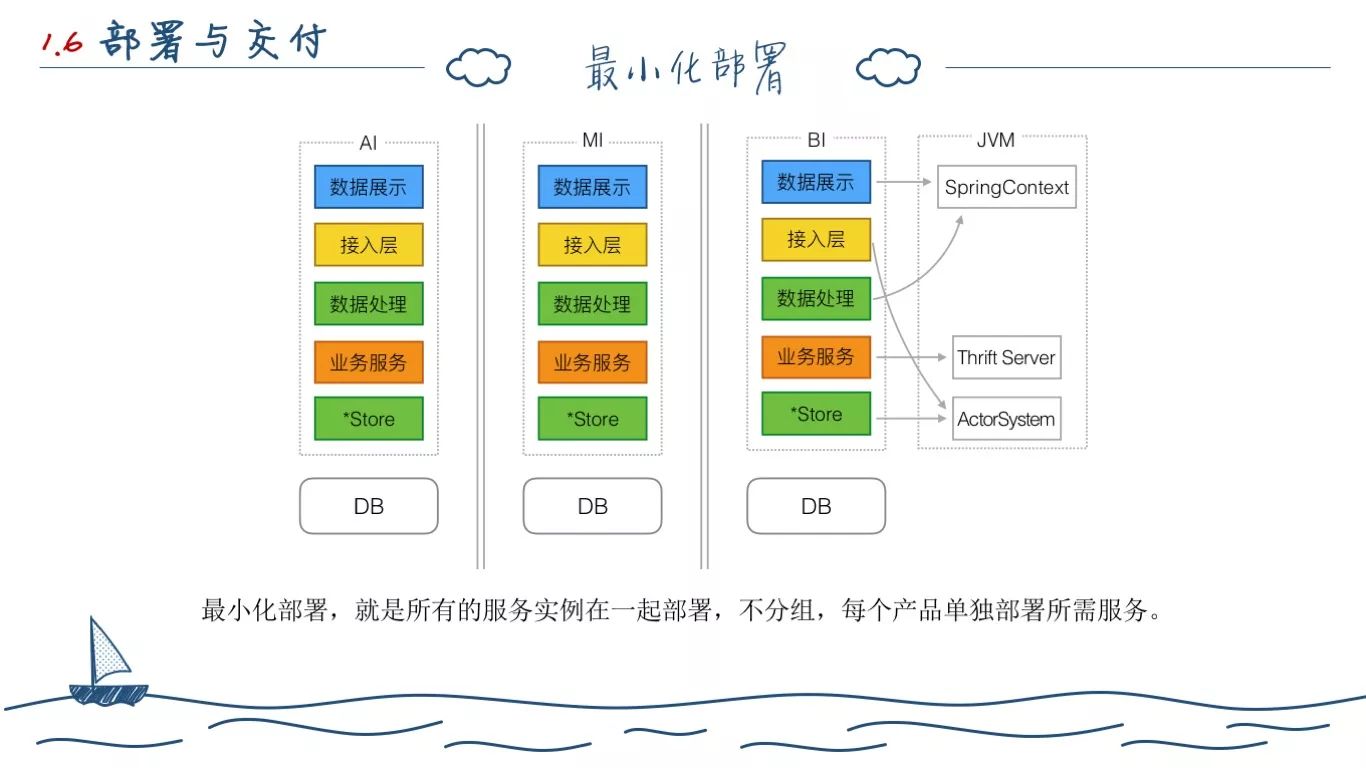
我们基于前面的服务拆分,每个应用在开发的时候,都是上述5大模块。中间核心的中间件组件,业务系统均无需操心。在交付的时候,也属于类似公共资源,按照用户的数据量业务特点弹性选择。
最小化部署主要是为了给单独购买我们的某一产品的用户部署所采用的。
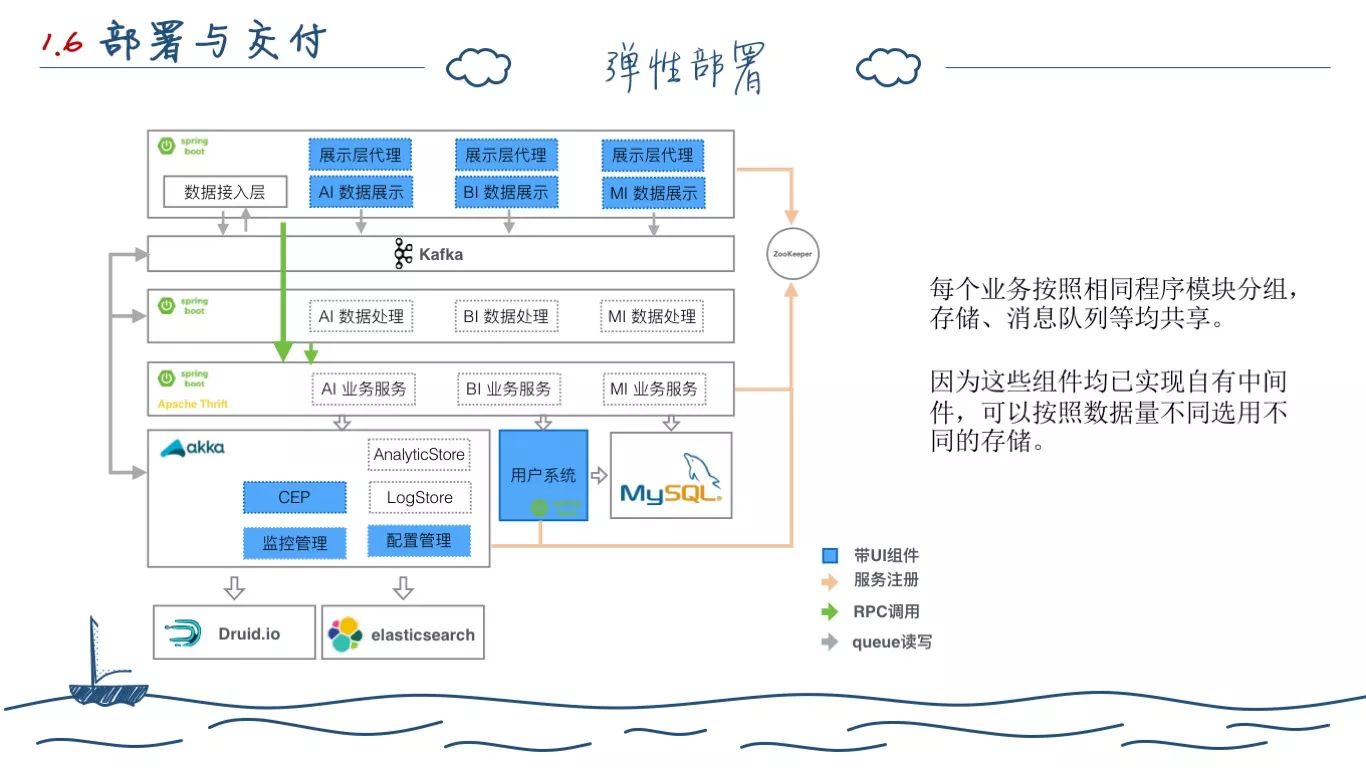
但是我们已经受够了一个项目维护多套代码的苦楚,我们希望一套代码能兼容 SaaS、企业级,减少开发中的分支管理。于是我们拆分后的另一大好处就体现了,它很容易结合投产未使用的 Mesos 在 SaaS 上实现部署。
为了打通各个产品,我们在原有的前后端分离的基础上,还将展示层也做了合并,最后实现一体化访问。后端因为实现了服务化,所有的应用都是动态 Mesos 扩容。CEP 等核心计算组件也能真正意义上和各个产品打通,而不是各做各的。

到了这里,我的第一阶段就算是讲完了,大家有问题么?(有问题留言哈~)

告警系统的开发,我们和 Ai 一样,经历了几个阶段,版本迭代的时间点也基本一致。整个开发过程中,我们最核心的问题其实不在于告警功能本身,而是其衍生的产品设计和开发设计。
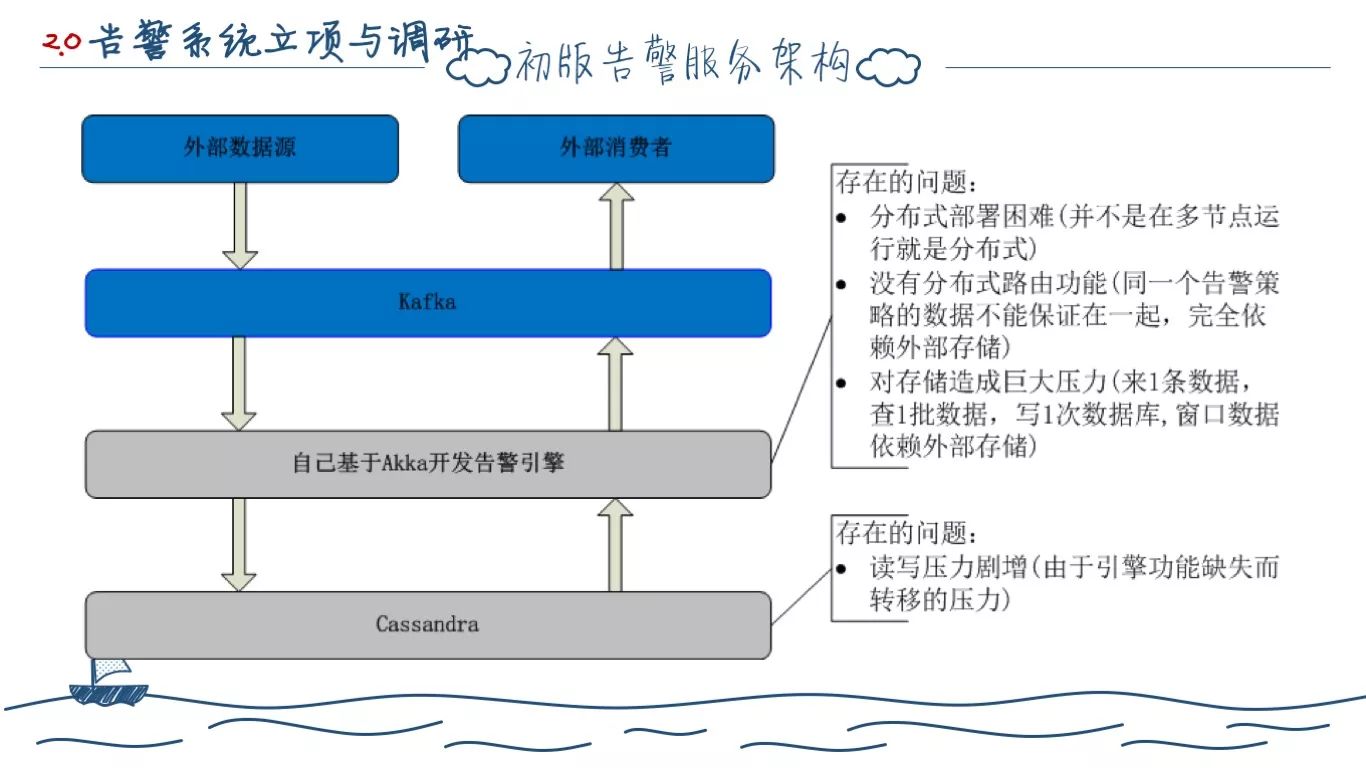
和 Ai 一样,初期的告警实现特别简单。当时来自 IBM 研究院的吴海珊加入 OneAPM 团队,带来了 Cassandra 存储,我们当时用的比较早,是 2014 年 2.0 版本的 Cassandra,我们在充分压测之后,对它的数据存储和读写性能十分满意,基于它开发了初版告警(草案)。
初版告警的实现原理极其简单,我们从 Kafka 接收要计算的告警指标数据,每接收到一条指标数据,都会按照配置的规则从 Cassandra 中查询对应时间窗口的历史指标数据,然后进行计算,产生警告严重或者是严重事件。然后将执行的告警指标写入 Cassandra,将告警事件写入 Kafka。(看下一页)
所以你会发现初版的告警,从设计上就存在严重的 Cassandra 读写压力和高可用问题。
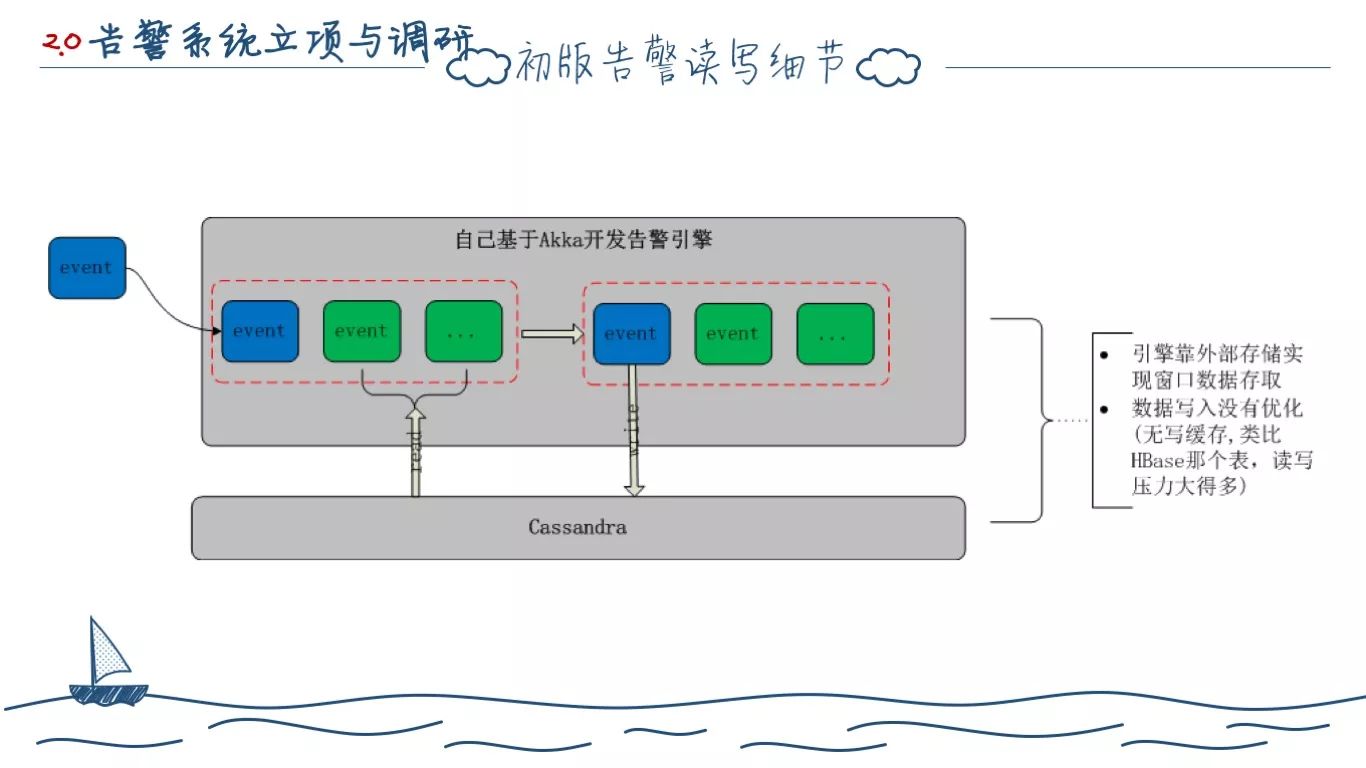
你会发现,每从业务线推送一条指标数据,我们至少要读写两次 Cassandra。和同时期的 Ai 架构相比,Ai 对 HBase 只有写入瓶颈,但读取,因为量不高,反而没有瓶颈。(回上页)
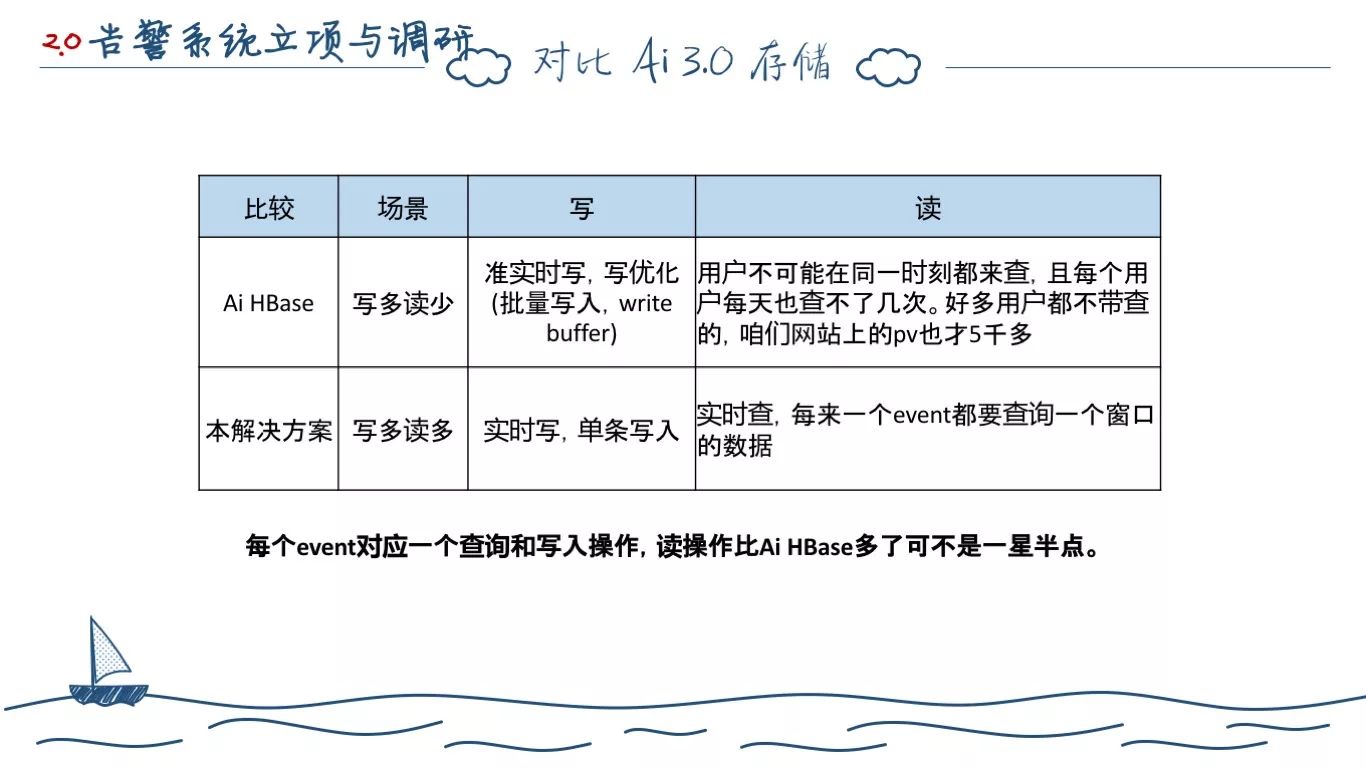
这里是我们和 Ai HBase的对比总结。我们初版的设计和 Ai 一样都需要全量地存储指标数据,而且 Cassandra 的存储分片本身是基于 Partition Key 的方式,数据必须基于 Partition Key 去查询,我们对于计算指标,按照 业务系统、应用 ID、时间 作为 Partition Key 去存储。很意外的是几乎和 HBase 同时出现了读写瓶颈。而且比较尴尬的地方也和 Ai 类似,因为 Partition Key 的定义,完全无法解决写入热点问题。
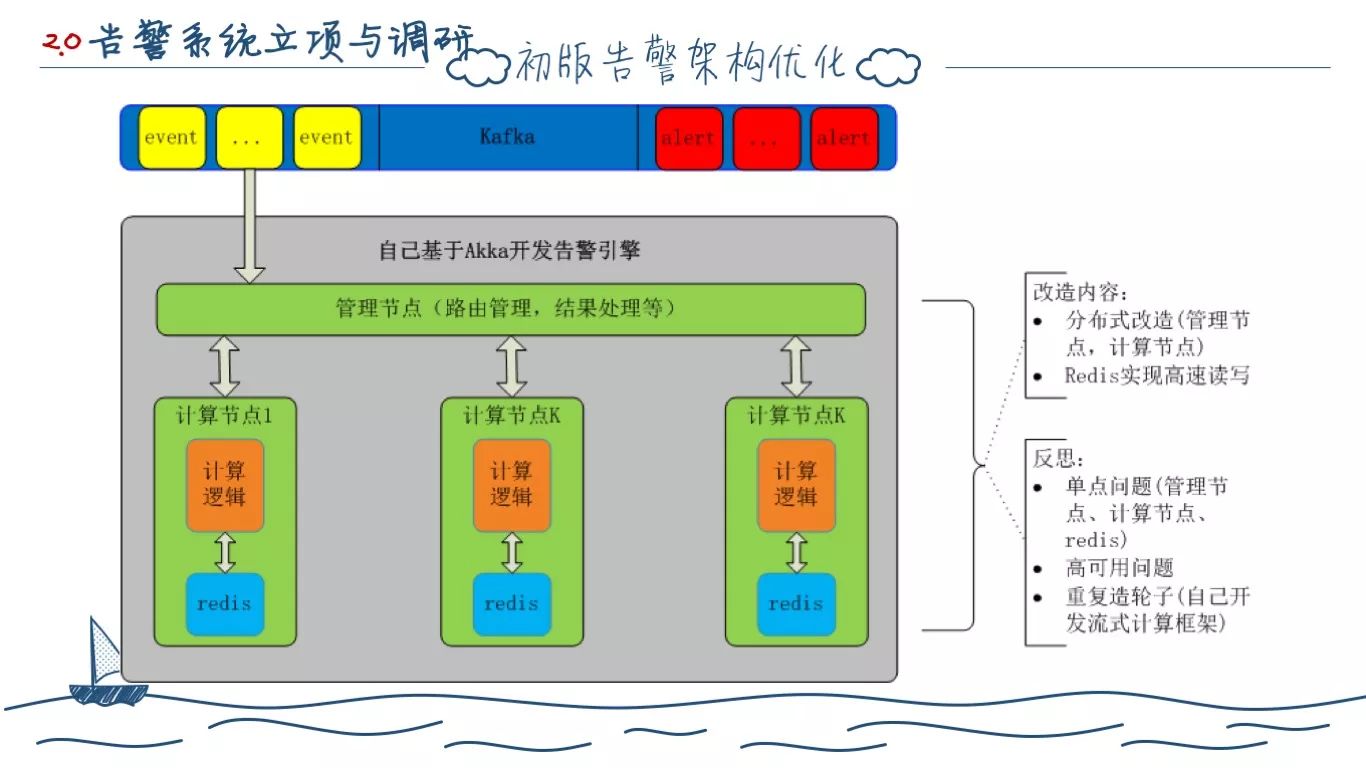
所以我们首先想到的是,对于当前的告警架构进行优化,我们有了上述的新架构设计。但是在评审的时候,我们发现,我们做的正是一个典型的分布式流式处理框架都会做的事情,这些与业务逻辑关系不大的完全可以借助现有技术实现。
由于这个时期(15年)公司整体投产大数据,我们自然把眼光也投入了当时流行的大数据计算平台。
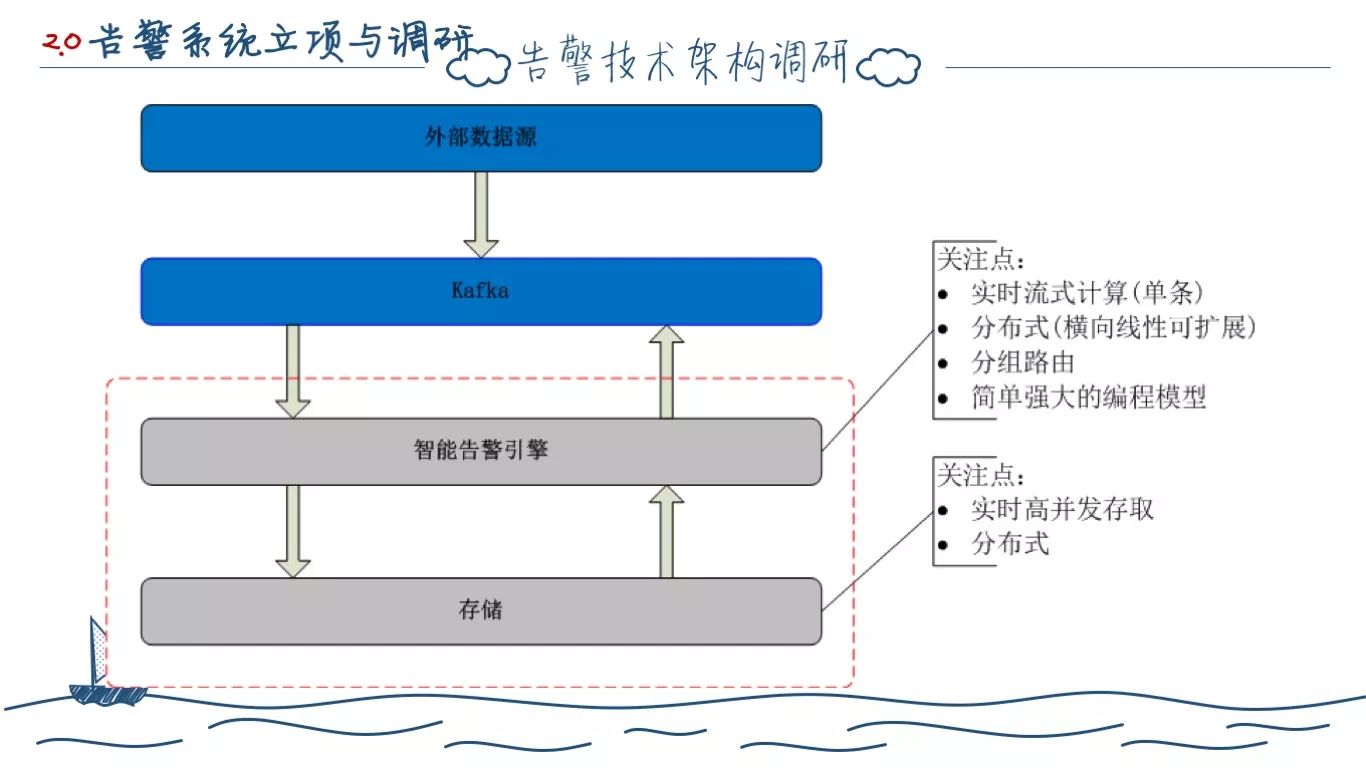
首先,对于初版的架构,我们需要保留的是原有的计算数据结构和 Kafka 的写入方式,对于核心的告警计算应用需要去改造。
我们需要实现的是基于单条数据的实时流式计算。需要能分布式水平扩展。能按照规则分组路由,避免热点问题。需要有比较好的编程接口。
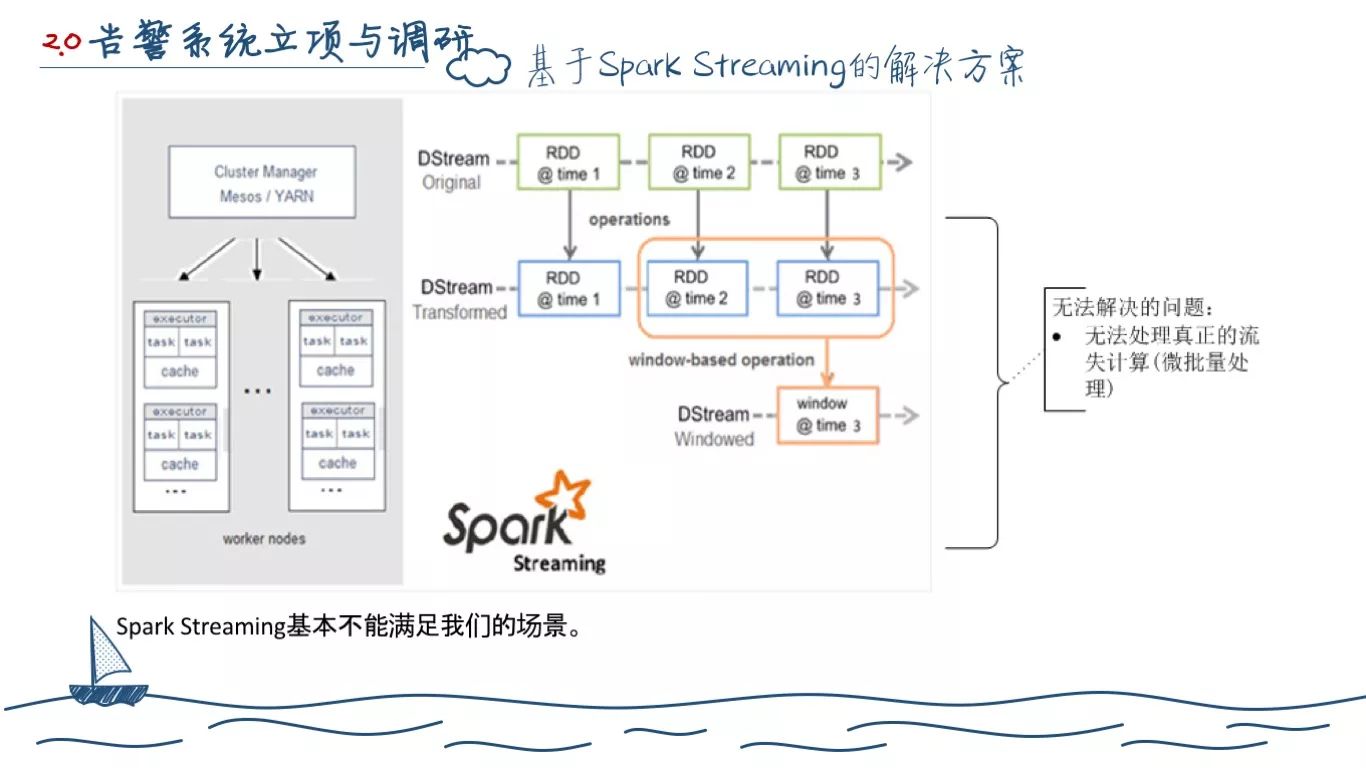
首先我们考察的便是 Spark,Spark 最大的问题是需要我们人为指定计算的时间窗口,计算的数据也是批量的那种而非单条,这和告警的业务需求本身就不匹配。
因为当时我们想设计的告警计算是实时的,而非定时。Spark Streaming 在后面还因为执行模式进一步被我们淘汰。
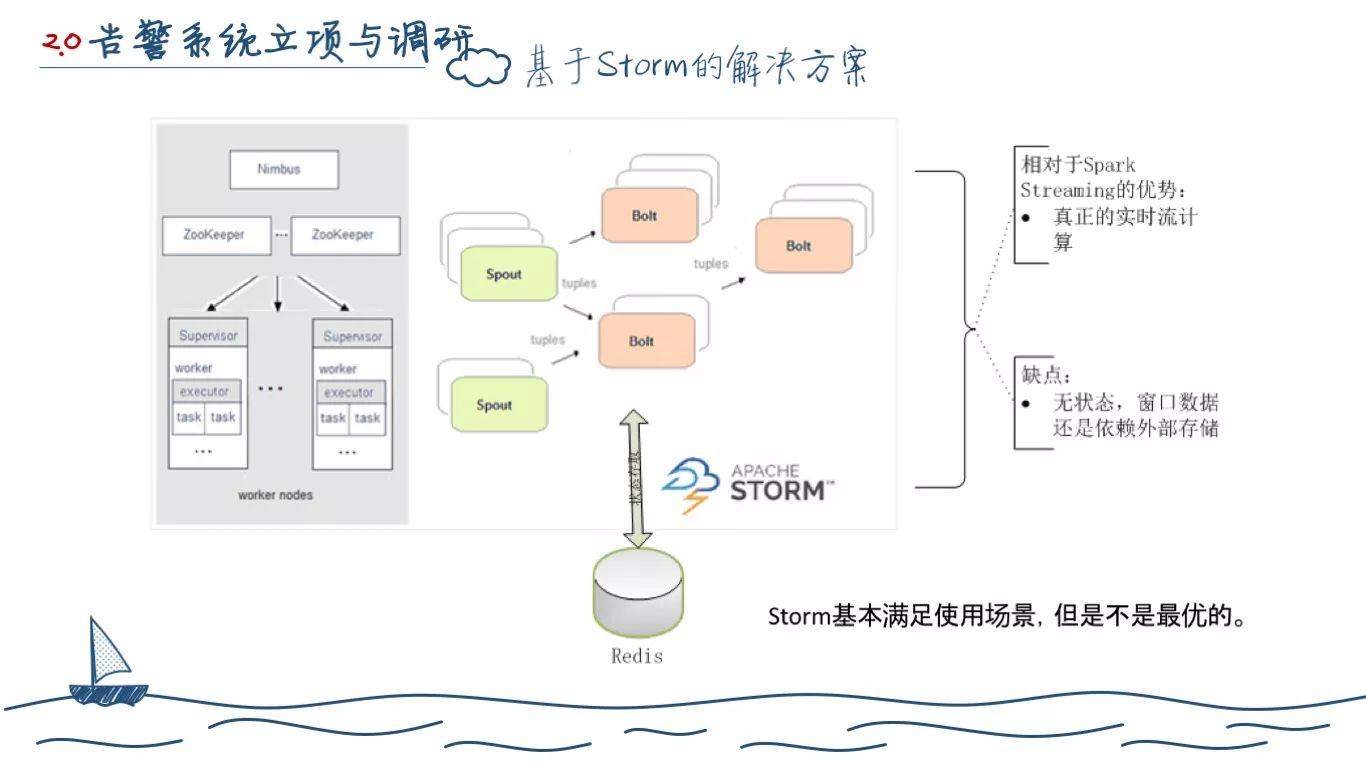
Storm 各方面其实都蛮符合我们需求的,它也能实现所谓的单条实时计算。但是,它的计算节点不持有计算状态,某些时候的窗口数据,是需要有类似 Redis 一类的外部存储的。
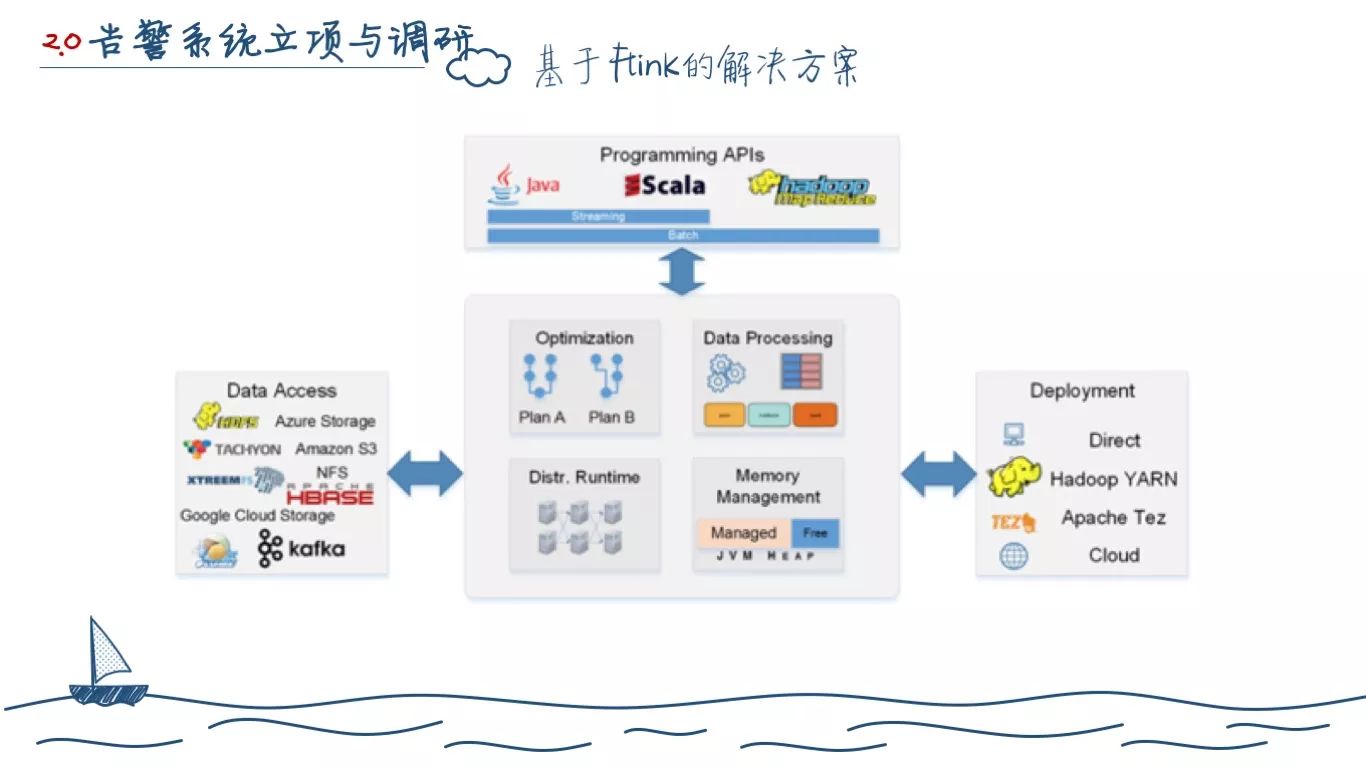
Flink优势:
Spark 有的功能 Flink 基本都有,流式计算比 Spark 支持要好。
Spark是基于数据片集合(RDD)进行小批量处理,所以Spark在流式处理方面,不可避免增加一些延时。
而 Flink 的流式计算跟 Storm 性能差不多,支持毫秒级计算,而 Spark 则只能支持秒级计算。
Flink 有自动优化迭代的功能,如有增量迭代。它与 Hadoop 兼容性很好,还有 Pipeline 模式增加计算性能。
这里,我需要重点说一下 Pipeline 模式。
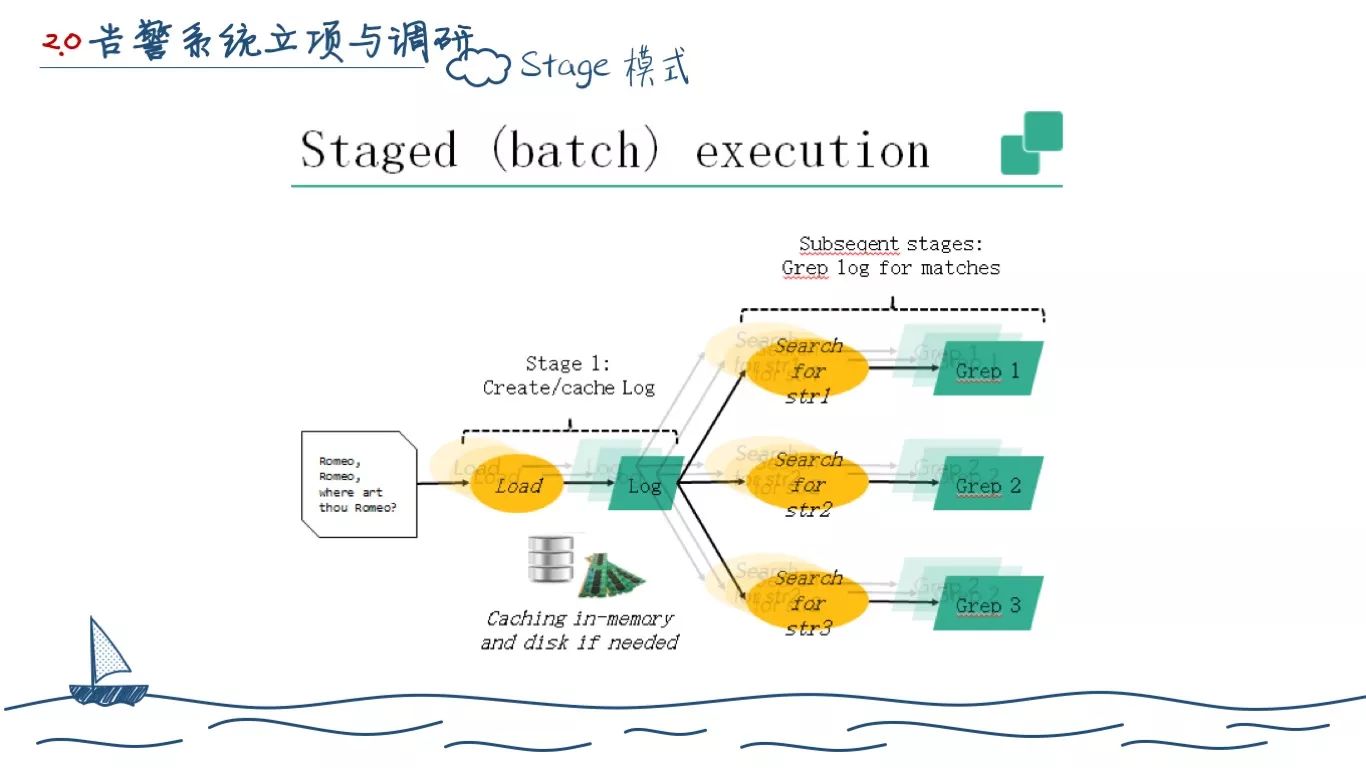
Staged execution 就如它的名字一样,数据处理分为不同的阶段,只有一批数据一个阶段完全处理完了,才会去执行下一个阶段。典型例子就是 Spark Streaming
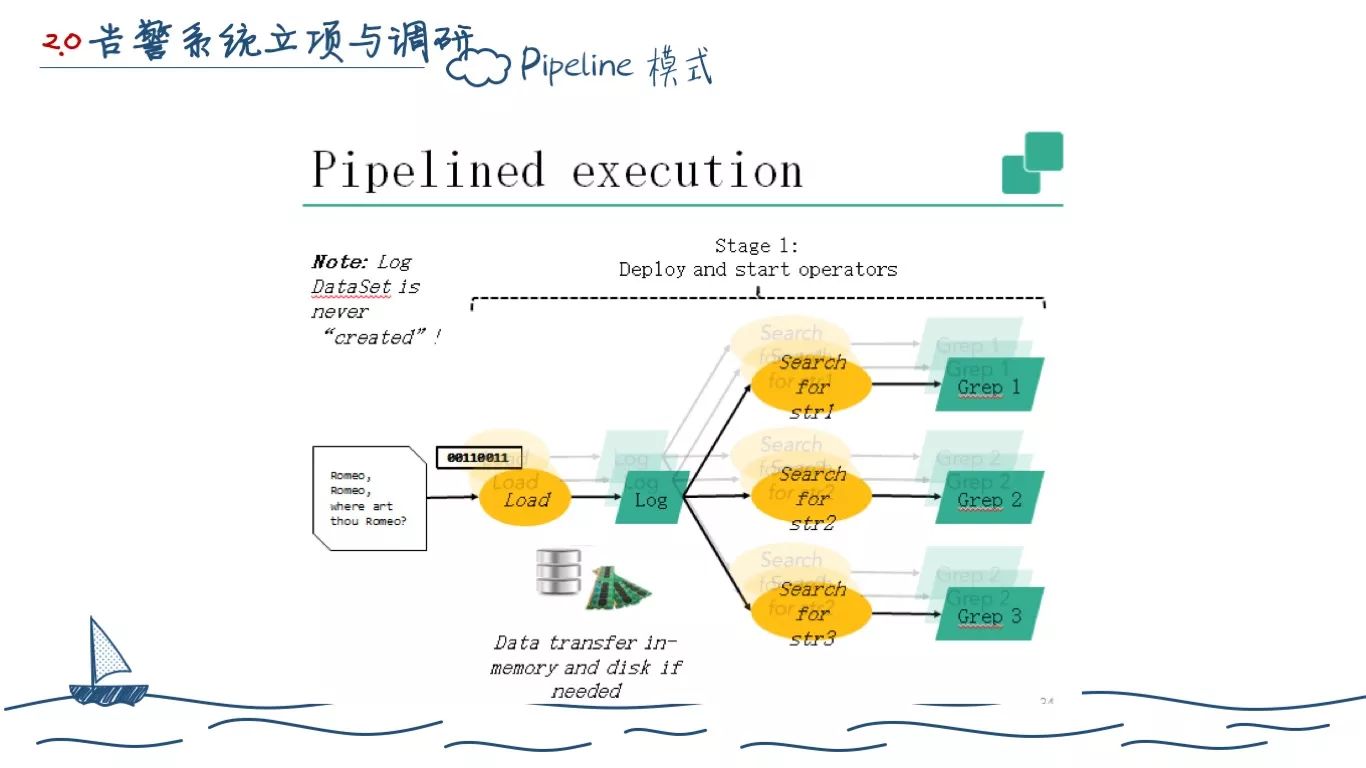
Pipeline 则是把执行串行在了一起,只要有计算资源空闲,就会去执行下一个的操作。在外部表象是只有一个阶段。
上面的不好理解,我们思考一个更形象的例子:
某生产线生产某钟玩具需要A,B,C三个步骤,分别需要花费10分钟,40分钟,10分钟,请问连续生产n个玩具大概需要多少分钟?
总结:
stage的弊端是不能提前计算,必须等数据都来了才能开始计算(operateor等数据,空耗时间)。Pipeline的优势是数据等着下一个operateor有空闲就立马开始计算(数据等operateor ,不让operateor闲着,时间是有重叠的)。
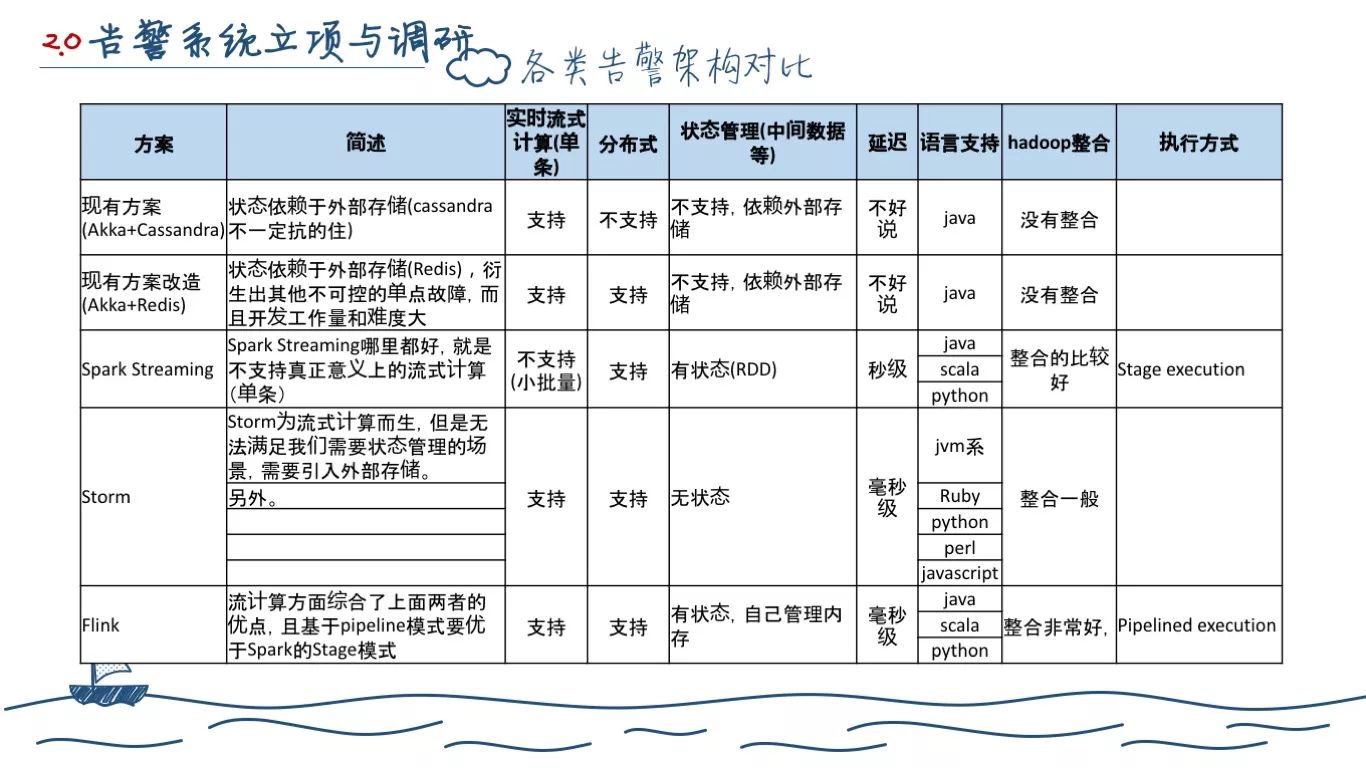
综合前面的调研分析,我们有了上面这张表格。对于我们而言,其实在前面的分析中 Flink 就已经被我们考虑了,尤其是它还有能与 Hadoop 体系很好地整合这种加分项。
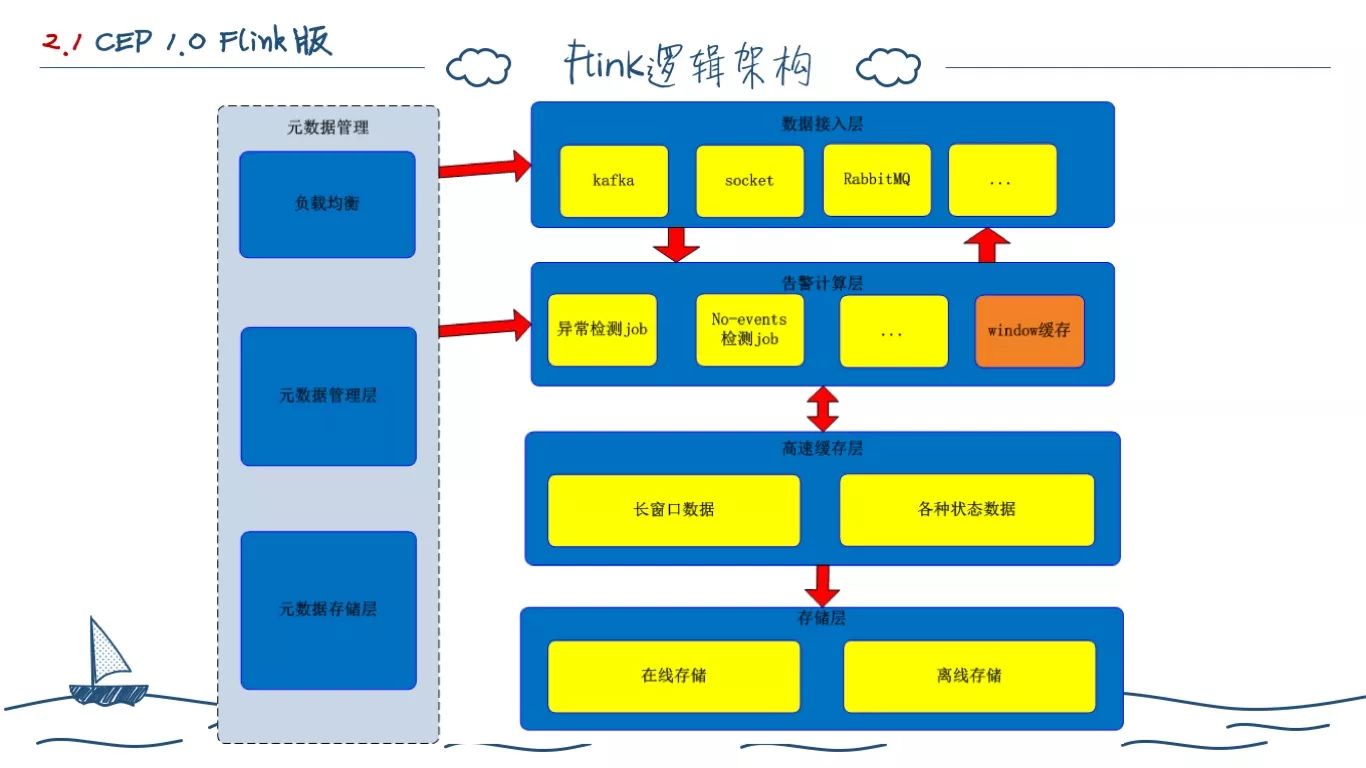
综合前面的分析,我们最终选择 Flink 来计算告警,因为:
在架构逻辑上面,我们当时分成了上述五大块。
元数据管理主要指的是告警规则配置数据,数据接入层主要是对接业务系统的数据。
计算层主要是两类计算,异常检测:按照配置的静态阈值进行简单的计算对比、No Event 无事件监测,主要是监控应用的活动性。
缓存区主要是计算数据队列的缓存和应用告警状态的缓存。存储区第一块是从原有架构继承的 Cassandra。离线存储是考虑给别的大数据平台共享数据使用的。
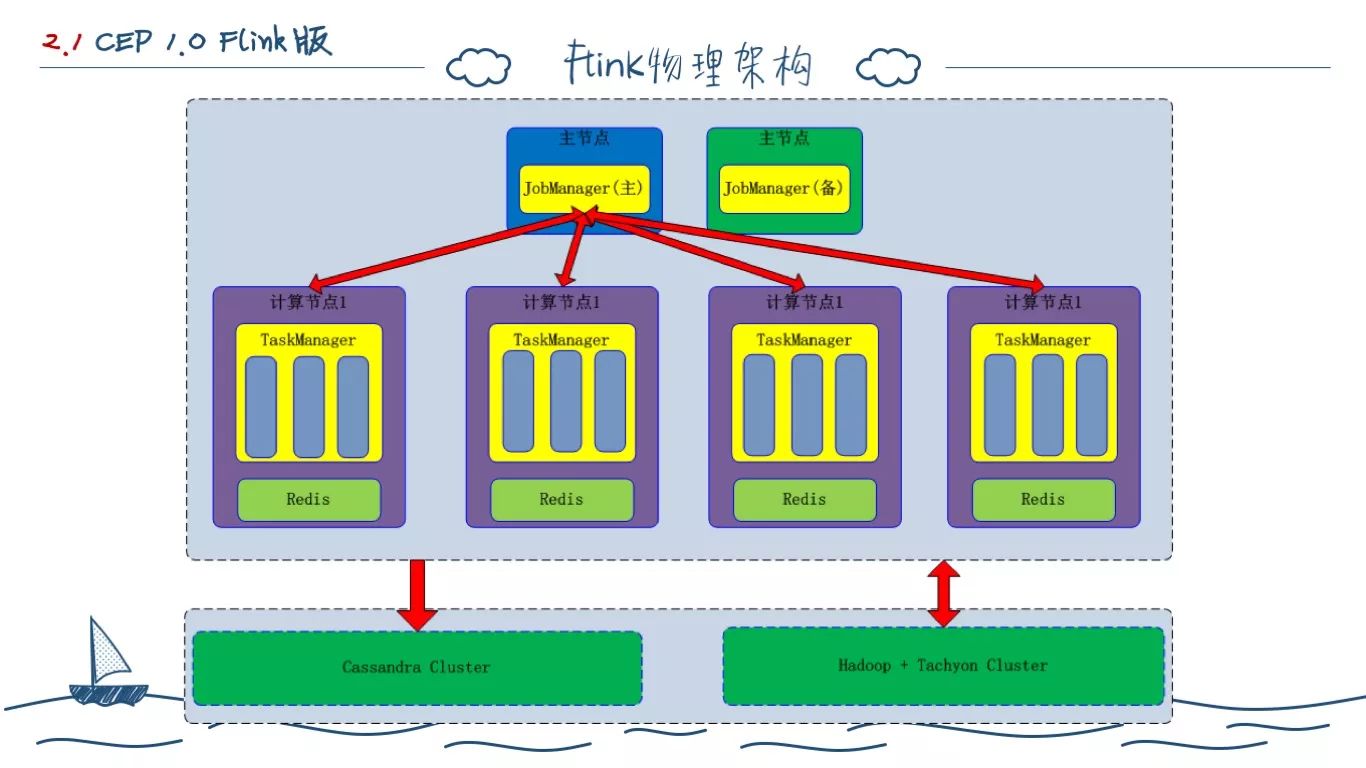
这里画的是 Standalone 的部署方式,也是我们在本地开发测试的架构,在生产上,我们采用了 Flink on YARN 的部署模式。
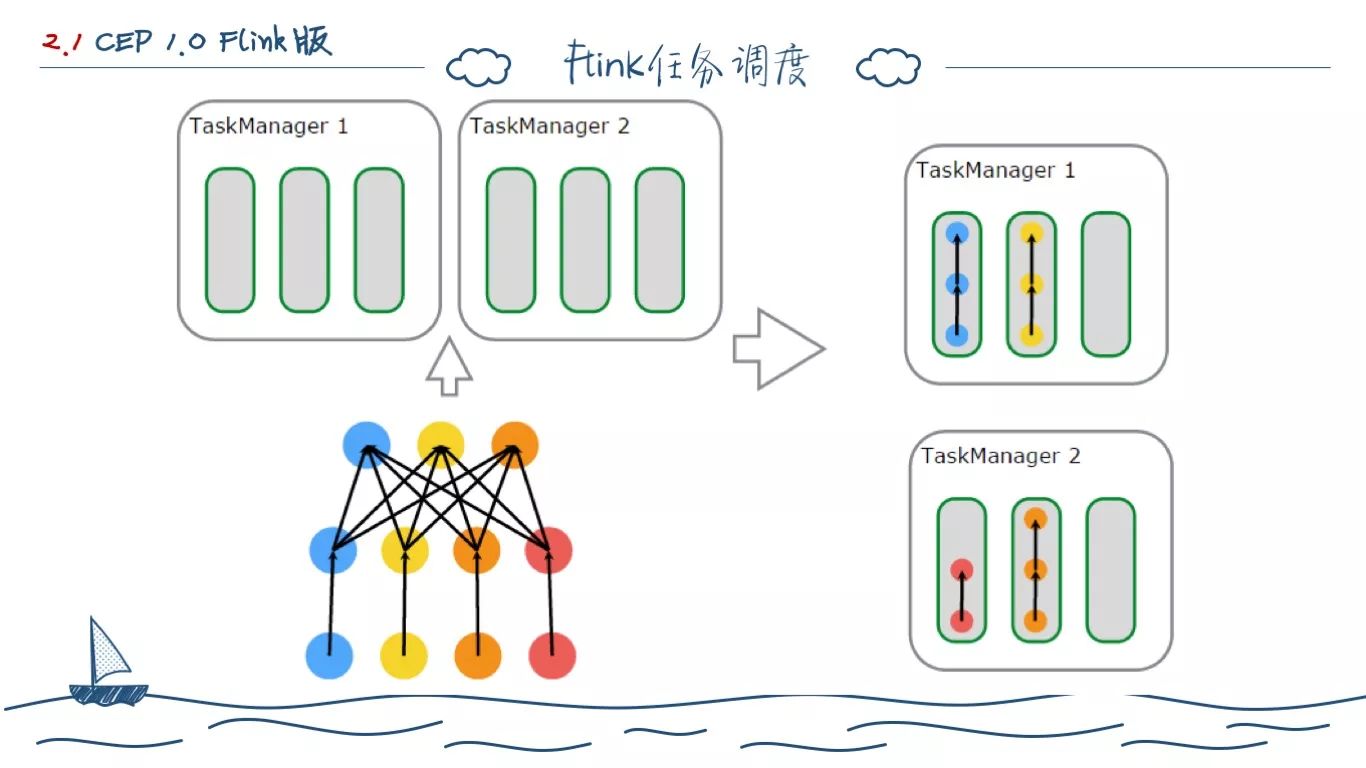
对于 Flink 的任务调度,我们以左下角的一个简单操作为例,它是一个 source(4) -> map(4) -> reduce(3),其调度在 Flink 中如图所示,会分成几个不同的 TaskManager来操作,每个 TaskMananger 中有多个执行单元,但呈管道式。将外部网状的处理流程变为独立的线性处理任务。
我们基于 Flink 首先需要开发的,就是异常检测流程。告警的异常检测就相当于 Flink 的一个 Job(Streaming),借助 Flink 简单易用的编程模型,我们可以快速的构建我们的 Flow。
在设计的初期,我们考虑了几个方面的问题:
作为通用的计算引擎,谁可以使用这个 Job。
如果后面某些产品提出一些变态的需求,我们是否可以快速开发一个针对特殊需求的 Job 提交到同一的平台去运行?
平台是否可以提供稳定的运行环境、可维护性、可扩展性、可监控性以及简单高效的编程模型,咱们可以把更多的精力放在两个方面:a.业务;b.平台研究(确保稳定性)。
生产上统一到 Yarn 上之后,我们可以在一个集群上公用一份数据,根据不同场景使用不同的计算引擎做它适合做的事情。比如,暴露数据给 Spark 团队使用。
Akka 集群化研究,我们原有的 Akka 开发经验,不能浪费。对于企业交付,还是需要有一个小而美的程序架构。Akka 那个时候是 2.3 版本,提供了 Akka Cluster,重新被我们纳入研究范畴。
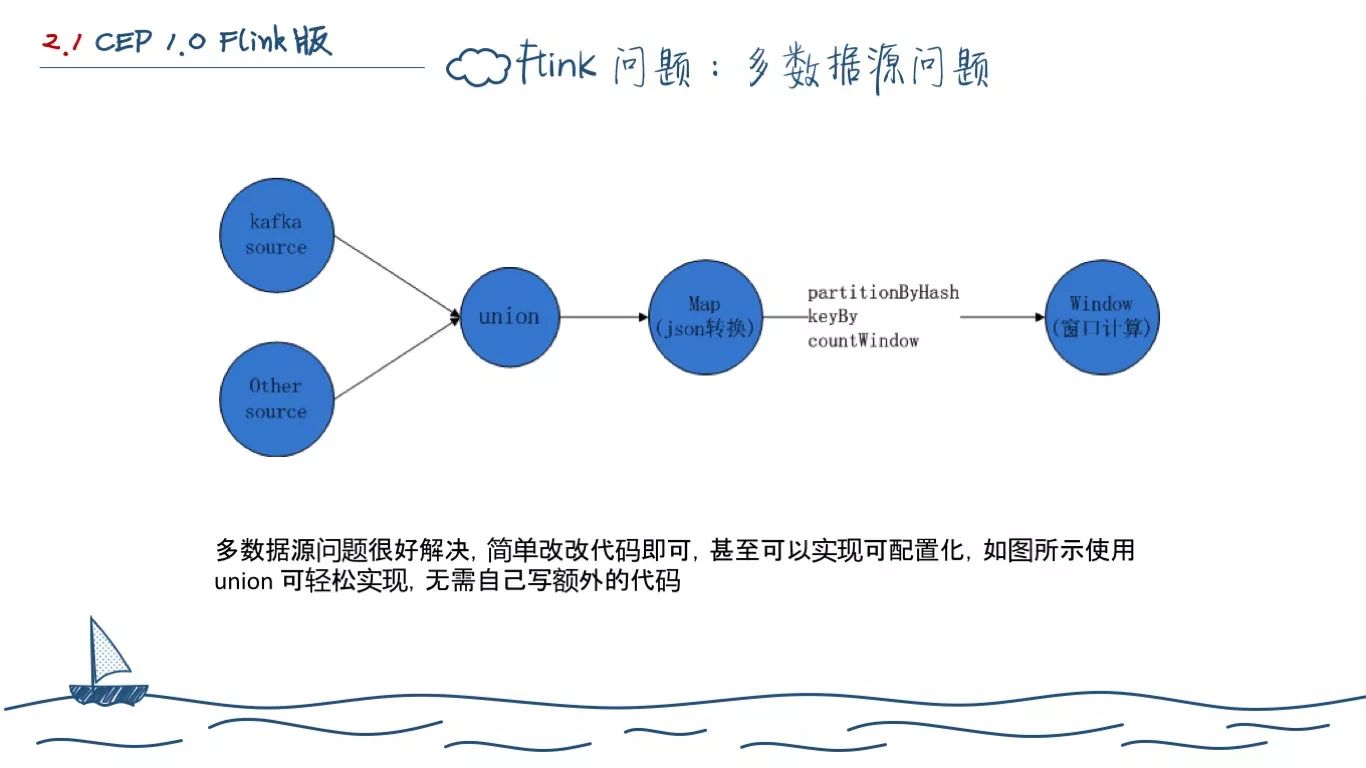
我们遇到的第一个问题,就是多数据源,生产上提供计算数据源的可能不仅仅是 Ai 一个产品,还有别的产品。我们研究后发现,Flink 原生支持多数据源。
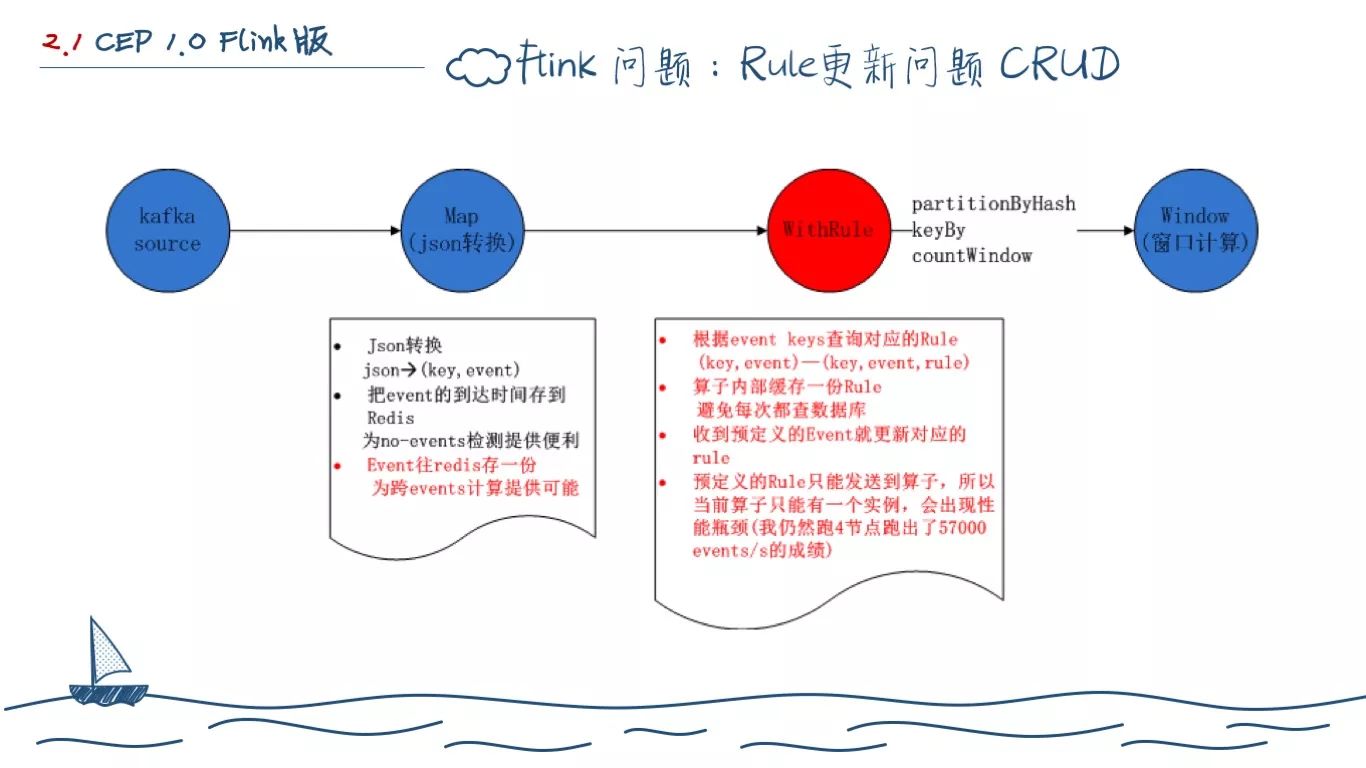
说到Rule的问题,我们逃不开一个问题:Rule管理模块到底应不应该拆出来。
首先,元数据管理的压力不大,数据量也不会大到哪里去,他的更新也不是频繁的。 其次,让 Flink 在各个节点上启动一个 Web服务去更新规则是不现实的,也不值当。
所以,把Rule管理模块单独抽取出来是合适的。
抽取出来之后,自然就涉及告警计算的 Job 如何感知 Rule 变更的问题:
完全依赖外部存储,例如 Redis,Job 每次都去查存储获取 Rule(这样完全规避了 Rule 更新问题,但是外部存储能够扛得住是个问题,高并发下 Redis 还是会成为瓶颈)。 Job内存里自己缓存一份 Rule,并提供更新机制。
无论怎么搞都得依赖外部通知机制来更新 Rule,比如元数据管理模块更新完 Rule 就往 Kafka 发送一个特殊的 Event。算子收到特殊的 Event 就去数据库里把对应的 Rule 查询出来并更新缓存。
有了更新机制,我们要解决的就是如何在需要更新的时候通知所有的算子,难点是一个特殊的Event只能发送给一个算子实例,所以我们上面采用了单实例,存在两个问题。
其实,我们忽略了一个问题,当Rule有更新的时候我们完全没必要通知所有的算子实例。
虽然我们不是一个 Rule 对应一个算子,但是 Flink 是提供分区机制的,我们已经用 key 做了hash。Rule 的更新不会更新 key,产生的特殊 Event 会分区到固定的算子具体实例,具有相同 key 的 Event 也必然被分区到相同的算子实例。所以我们的担心是多余的,而且借助分区机制,我们对内存的占用会更小,每个算子实例只缓存自己要用的Rule。
所以 Rule 的更新只有三种场景:初始化时不做预加载缓存,第一次使用Rule时查数据库并缓存,收到内置Event时更新缓存。

No Events 检测主要的问题是 Flink 是实时数据计算,他是来一条数据计算一次。无事件本身的特点就是没有数据推送过来,无法触发计算。
这个问题其实已经非常好解决了,我们在告警计算的流程里已经更新每个Rule对应Event的最后达到时间到Redis了。我们可以单起一个批处理job简单运算一次即可,逻辑非常简单,我测了一下16000个Rule,5个并发度,可以在5s内计算一次。注:带注释才用了不到120行java代码,稍加改进即可在生产上使用。
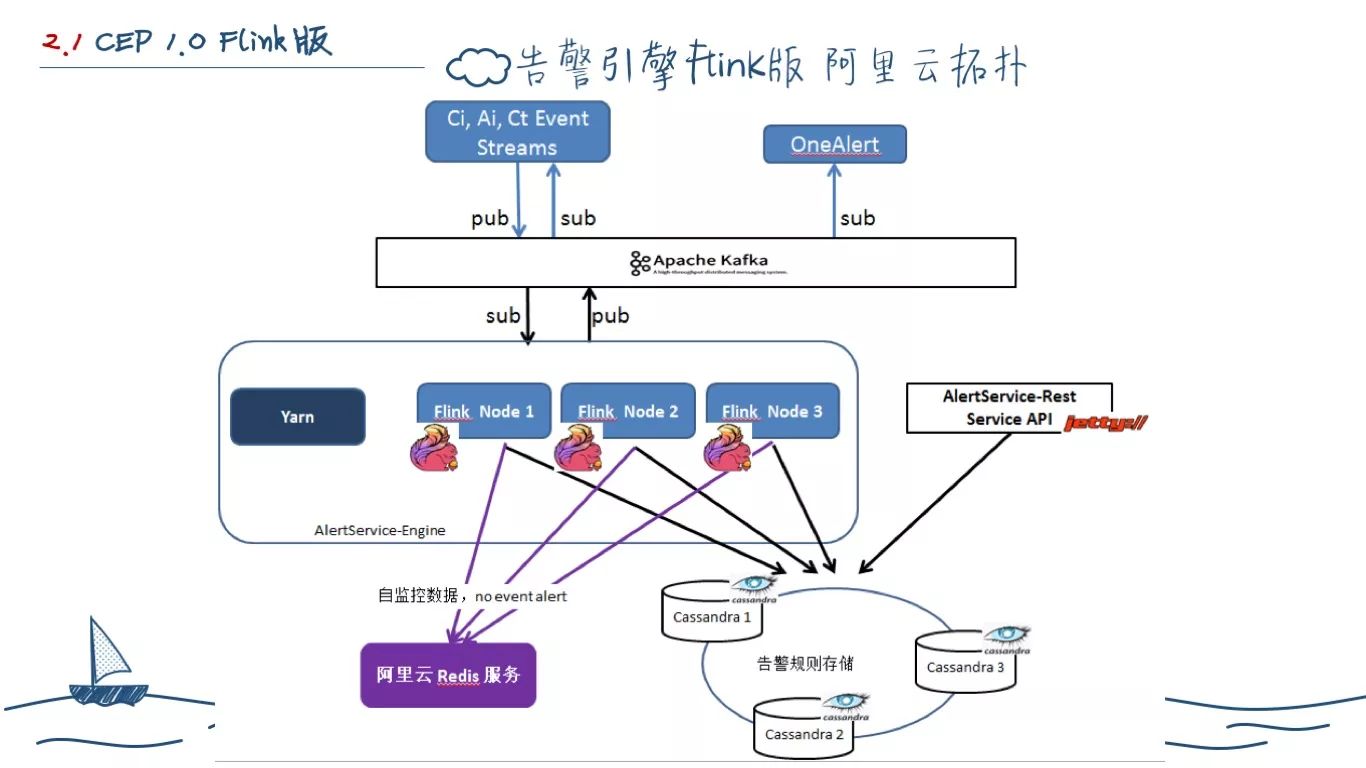
最终,我们在解决上述问题之后在阿里云上实现了上述的告警计算平台。

从某种角度而言 Flink 版本是第一个在 SaaS 上投产的系统,然而,它并不完美,有着上述这些问题。
从某种角度而言,Flink 计算告警有些大材小用,我们需要更轻量的架构。(这里中断,展示一下我们的告警系统。)

在 Flink 版本开发3个月后,我们开始着手开发新的企业级告警平台。因为现有的 Flink 版本,因为很多原因无法对外交付。
我也是从这个时候开始参与 OneAPM 告警的研发,我们做的第一件事情,就是结合之前 DSL 开发的经验,思考如何重新定义告警规则。这是因为 Flink 上定义的告警规则,就和现有的云迹 CTMAM 的告警规则一样,比较死板,不好扩展,且较为复杂。
这期间也参考了 Esper 之类的开源项目,比较后我们惊喜地发现,最好的告警规则定义方式就是 SQL。
我们在定义好规则模板之后,便开始由解析计算引擎 -> 处理队列引擎 -> 分布式管理平台 -> 操作接口的顺序,开发了现有的告警引擎。
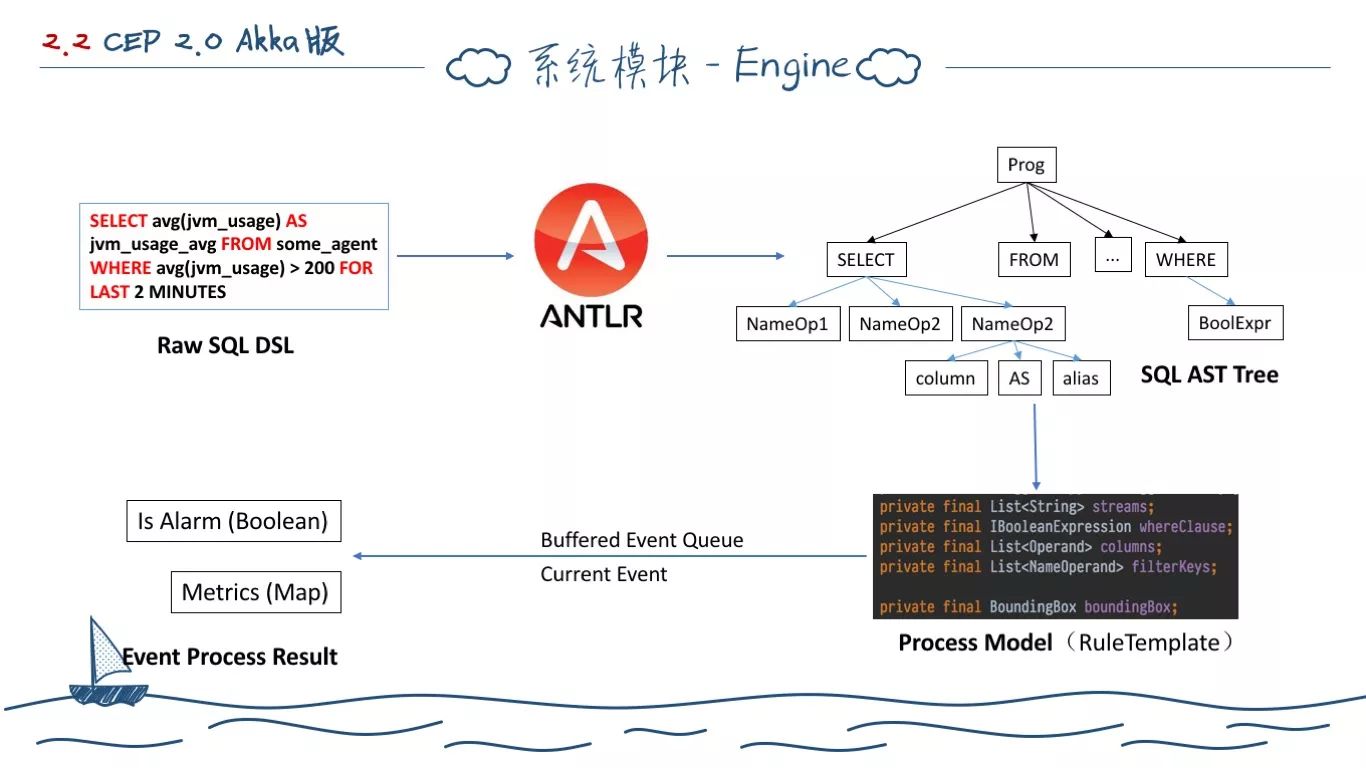
首先是基于规则 DSL 的解析计算引擎。之前的 Mock Agent,我们使用的是 Scala 原生提供的语法分析组合子设计的。Druid SQL 使用的是 Antlr4,先解析出基本的 AST 语法树,然后转义为 Druid JSON 查询模型,最后序列化为查询 JSON。
这里的告警规则 SQL,我们用的是类似 Druid SQL 的方式。语法模板定义甚至都是类似的。只是增加了四则混合运算表达式的解析和运算,还有 avg 一类的计算函数的实现。
最终,它的解析处理流程就和 PPT 图示的一样。规则 SQL 语句被 Antlr4 做词法语法分析,将部分非逻辑单元符号化,然后构建出一棵 SQL 语法树。我们按照 Antlr4 提供的 Visitor 模式,以深度优先检索的方式遍历,然后不断地将结果按照定义的算子单元组合。最后对外暴露出两个方法,一个返回布尔值表示是否满足规则运算定义,另一个返回计算中想要获取的指标数据。
我们基于解析出来的规则对象,在 Engine 层对计算的事件队列和当前事件结合起来,就产生了实际想要的计算结果。
Engine 就相当于最小粒度的计算单元,但是,它缺少一些上下文管理。我们需要事件队列管理,规则和计算数据的关联,才能真正意义上调用 Engine 去计算。
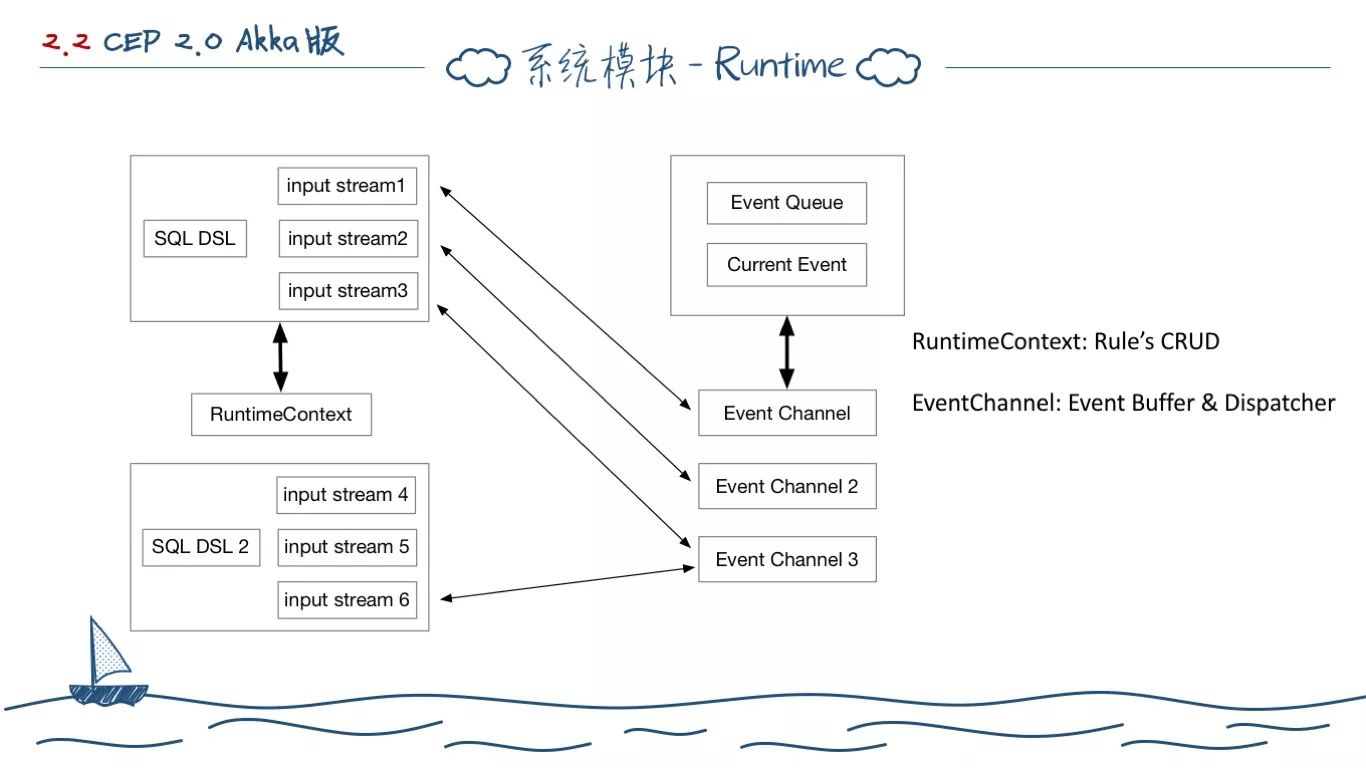
基于这个需求,我们开发了 Runtime 模块。它在逻辑上有两大抽象,一个是 RuntimeContext,一个是 EventChannel。
RuntimeContext 就和它的名称一样,表示运行时上下文,每个RuntimeContext 对应一条具体的规则示例,内部会维护对应的 RuleTemplate。我们在设计初期就考虑类似多数据源的情况,一条计算规则可能对应多个探针数据,于是内部定义了 InputStream 的概念。
它相当于实际的一条计算指标数据流,实际存储在 EventChannel 上,EventChannel 为在内存中存储的一个指标数据队列。它有两块数据:一个是一个 Event Queue,一个是当前才来的一条要计算的指标数据。Event Queue 的设计参考了 Guava Cache 里面的队列,因为规则创建时对应的数据窗口大小是确定的,于是这个 Queue 的大小也是确定的。
一个 RuntimeContext 示例可能对应多个 EventChannel,一个 EventChannel 也可能对应多个 RuntimeContext,二者基于一个唯一的 key 关联起来。我们修改规则的时候,需要修改对应的 RuntimeContext。事件来了要计算的时候,是直接 sink 到 EventChannel 中。
Runtime 相当于 Flink 里面最小的计算任务,有着自己的状态,能解析 SQL 并进行运算。
但是对于分布式、集群等部署环境,它还存在着较大的问题。在其之上,我们使用 Akka 开发了核心的运行模块。
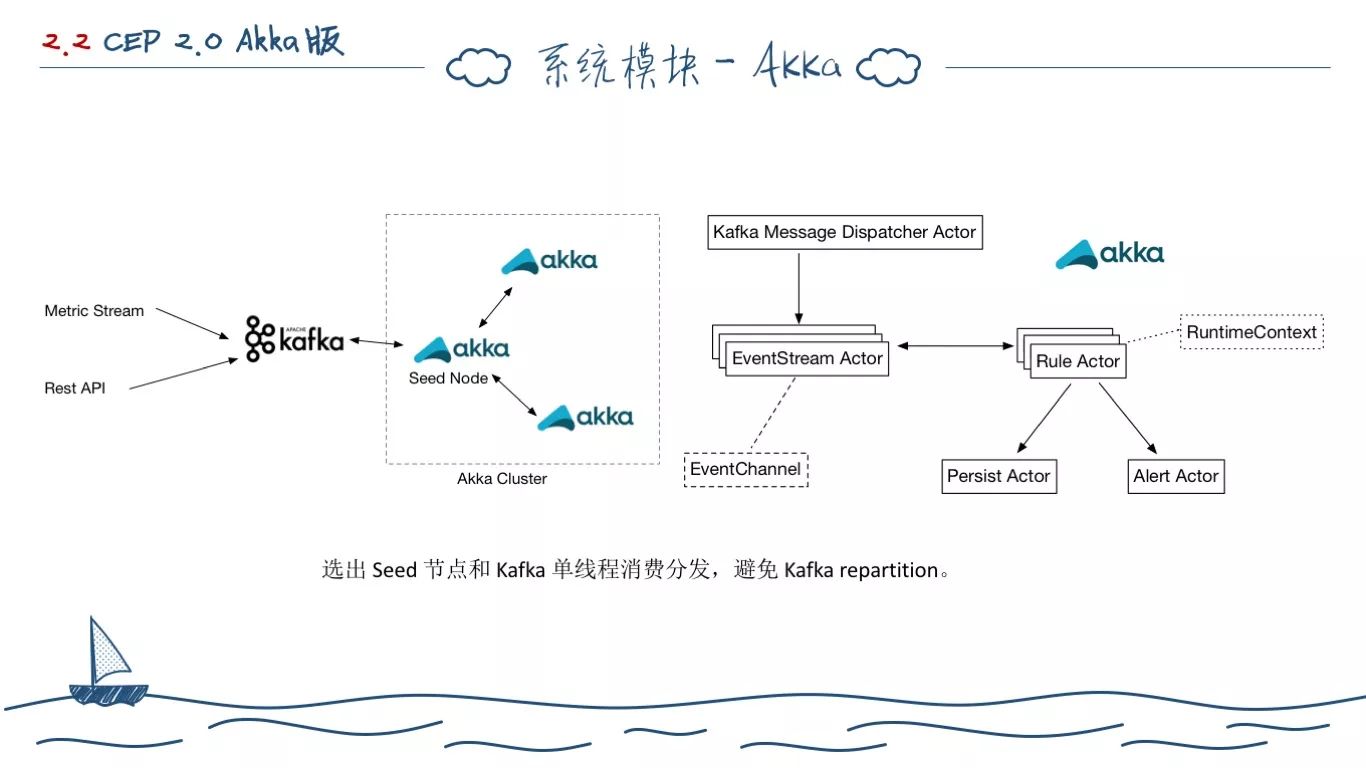
我们使用 Akka Cluster 开发了计算集群,Akka Cluster 将 Akka 应用分为 Seed Node 和一般 Node。启动的时候,要先启动 Seed Node,才能启动子 Node。但是启动后如果 Seed Node 挂了,Akka 可以选出一个新的存活节点当做 Seed Node。
我们在 Akka 集群启动后,会使用 Seed Node 创建 Kafka Message Dispatcher Actor 来和 Kafka 消费数据,然后分发到各个子节点上。这么做的话,同一时刻,只有一个线程在从 Kafka 消费数据。使用单线程的考虑有很多,比如避免 Kafka repartition。其次,我们测试后发现,从 Kafka 消费这块使用单线程不存在瓶颈。
每个 Akka 节点都分为 EventStreamActor、RuleActor 两类核心处理计算单元,EventStreamActor 除了管理 EventChannel 之外,还会将数据分发到别的 Akka 节点,做二次计算。RuleActor 管理 RuntimeContext,其下包含 Persist Actor 将告警事件和应用实时状态持久化到金字塔存储,Alert Actor 将告警数据写入至 Doko MQ 用于接入系统执行告警行为(如短信、邮件、WebHook 等)。
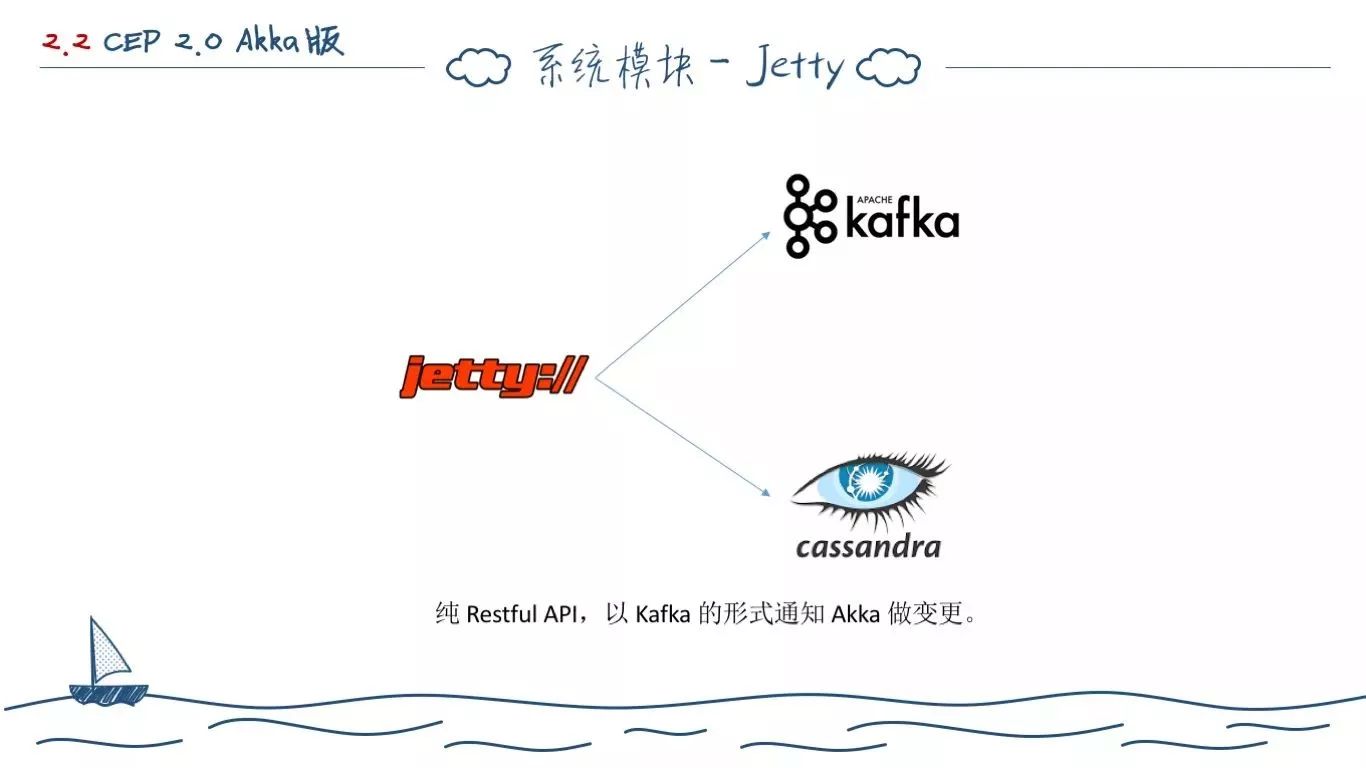
Jetty模块本身用于暴露接口对外提供规则、事件、数据源管理。和 Flink 版本一样,我们遇到了一个问题就是如何在所有的 Akka 集群上更新告警规则。
后面我们的实现策略和 Flink 的版本一样,规则在 Cassandra 上更新完毕后,会以特定的更新消息写入 Kafka 中。这个时期,所有的告警规则配置,使用用户,告警数据源的配置,都保存在 Cassandra 中。因为 Partition Key 的创建不大合理,也给我们在做检索,分页等操作时,尤其是告警事件的筛选,带来了极大的麻烦。这也直接导致我们在 3.0 版本里面将所有的配置数据存于 MySQL,告警事件改为使用金字塔存储。
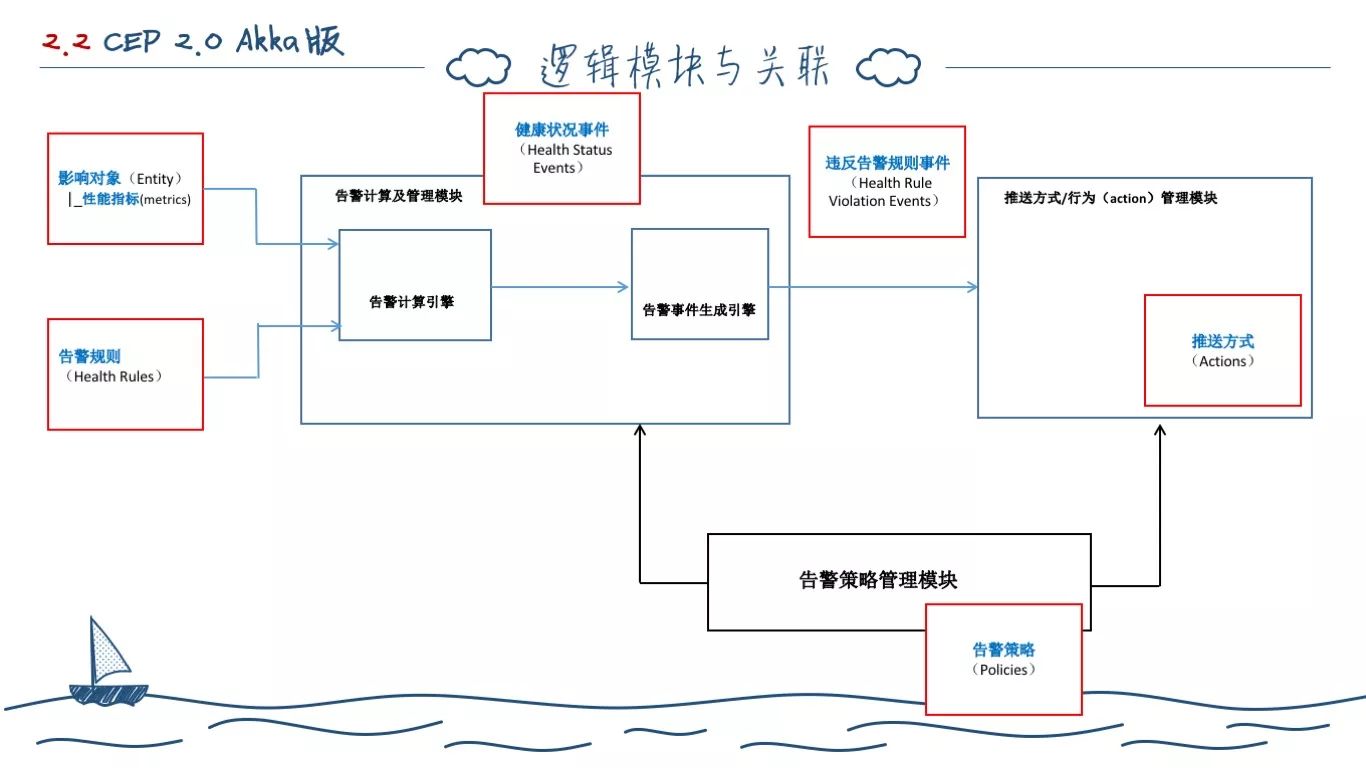
基于计算引擎,我们抽象出三大逻辑模块,告警计算和管理模块、告警策略管理模块、推送行为管理模块。
计算引擎,也就是前面说的 Runtime 模块那层、它只关心什么规则,基于数据算出一个 true/false 的布尔值表示是否告警,同时返回计算的指标集。
事件生成引擎,它基于前面的计算结果,还有指标的元数据等组合生成实际的告警事件。2.0 版本只有三种:普通、警告、严重。
推送行为模块,其实就是配置支持哪些通知用户的方式,在 2.0 里面只有发邮件、执行 Shell,3.0 之后支持 Web Hook 和短信。
策略模块,就是关联某个规则应该用那些现存的通知配置。
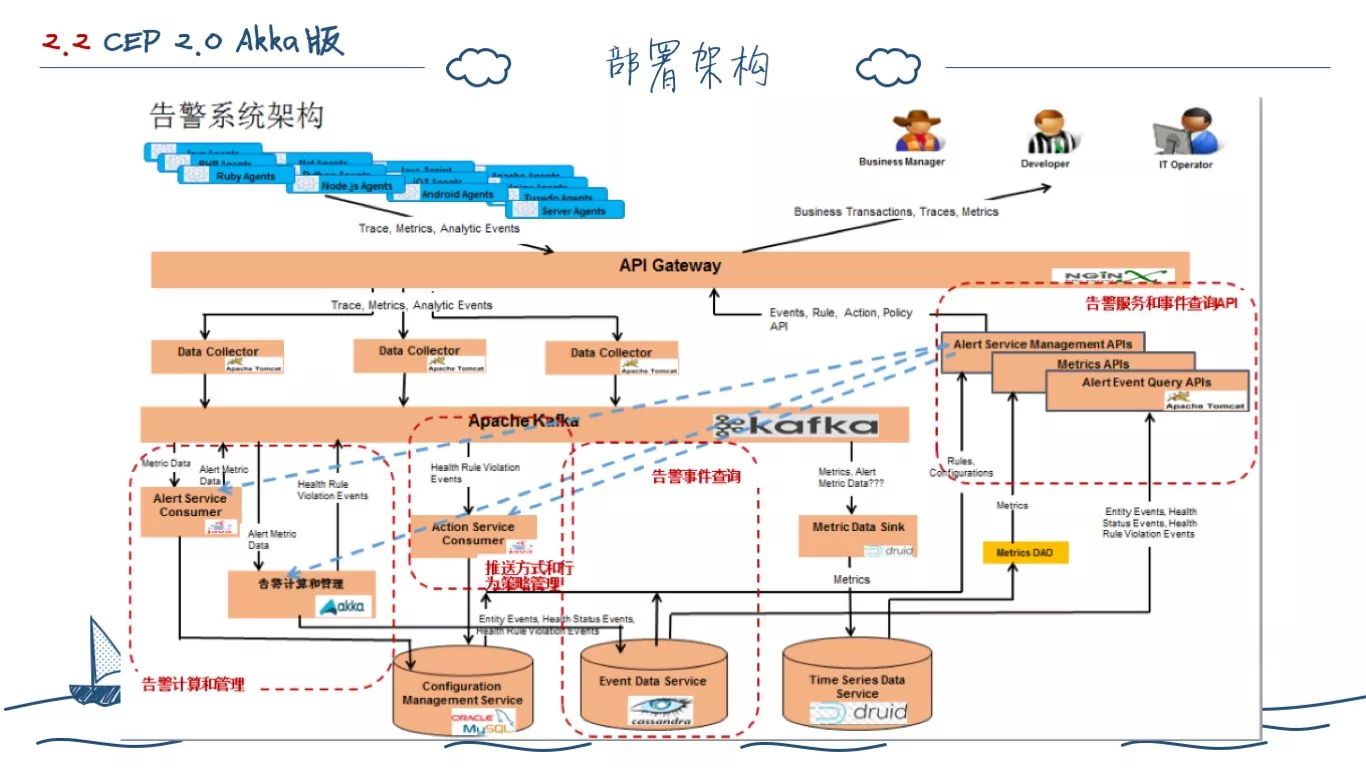
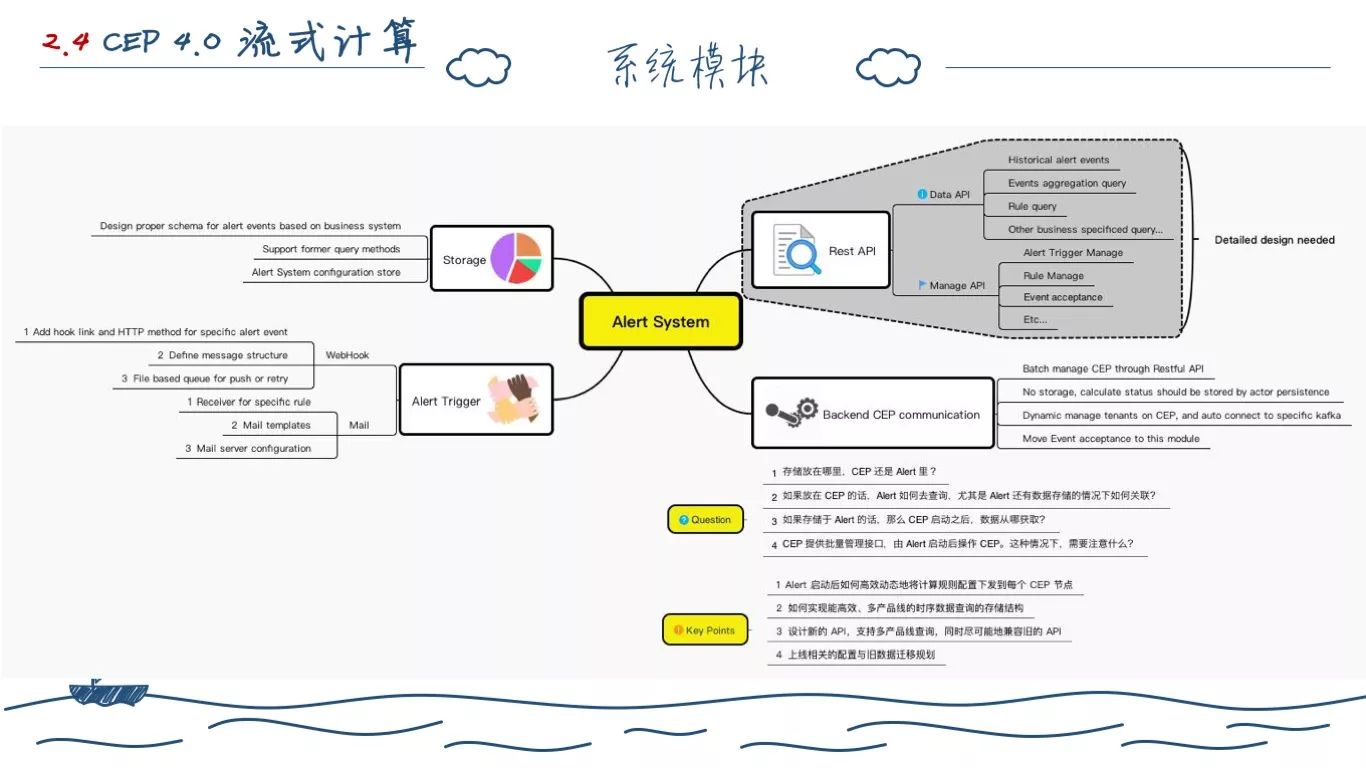
2.0 版本的告警系统主要是 CEP 计算引擎模块,所以在部署上,他是集成在各个业务系统上的。
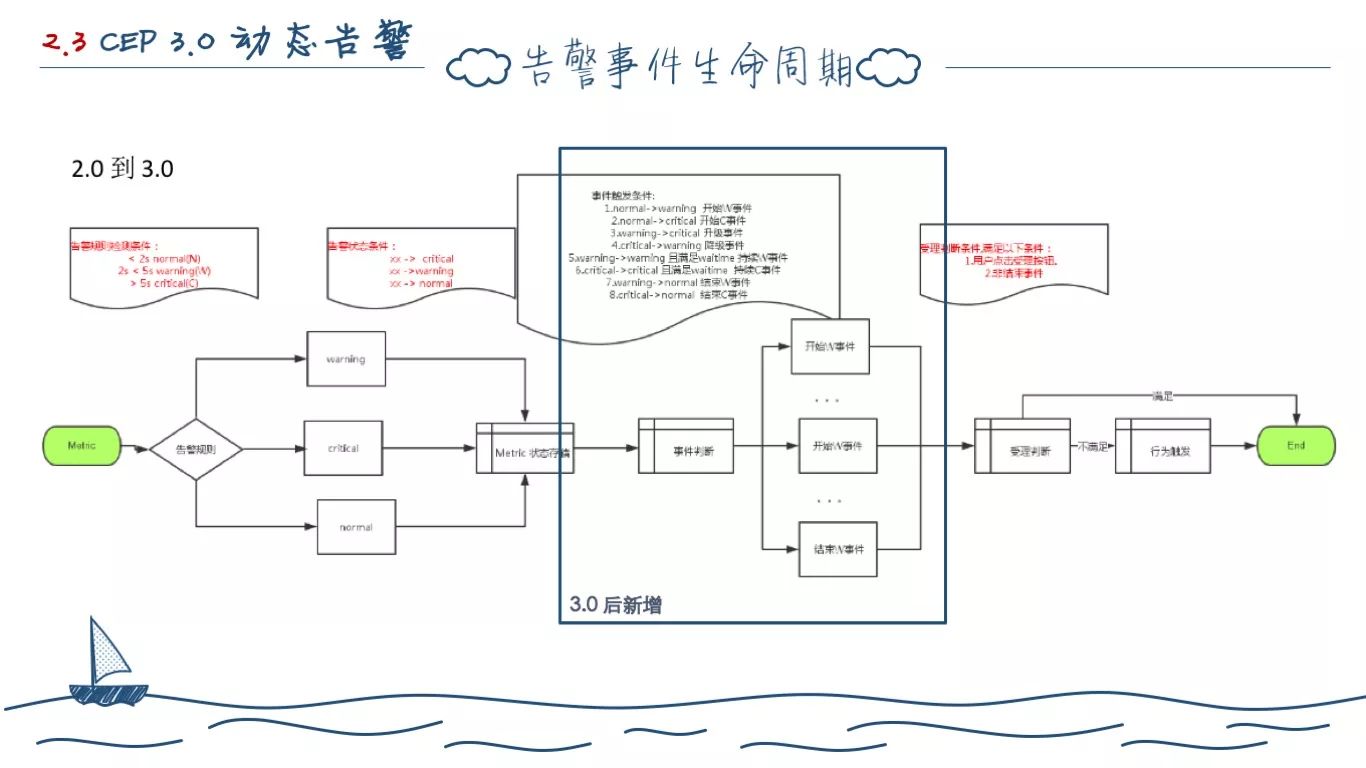
2.0 的时候,告警系统只产生三类事件,普通事件、警告事件、严重事件。我们调研之后发现,其实用户在意的不是这类事件,而是这三类事件相互转换之后产生的事件。
于是我们重新定义了告警事件。
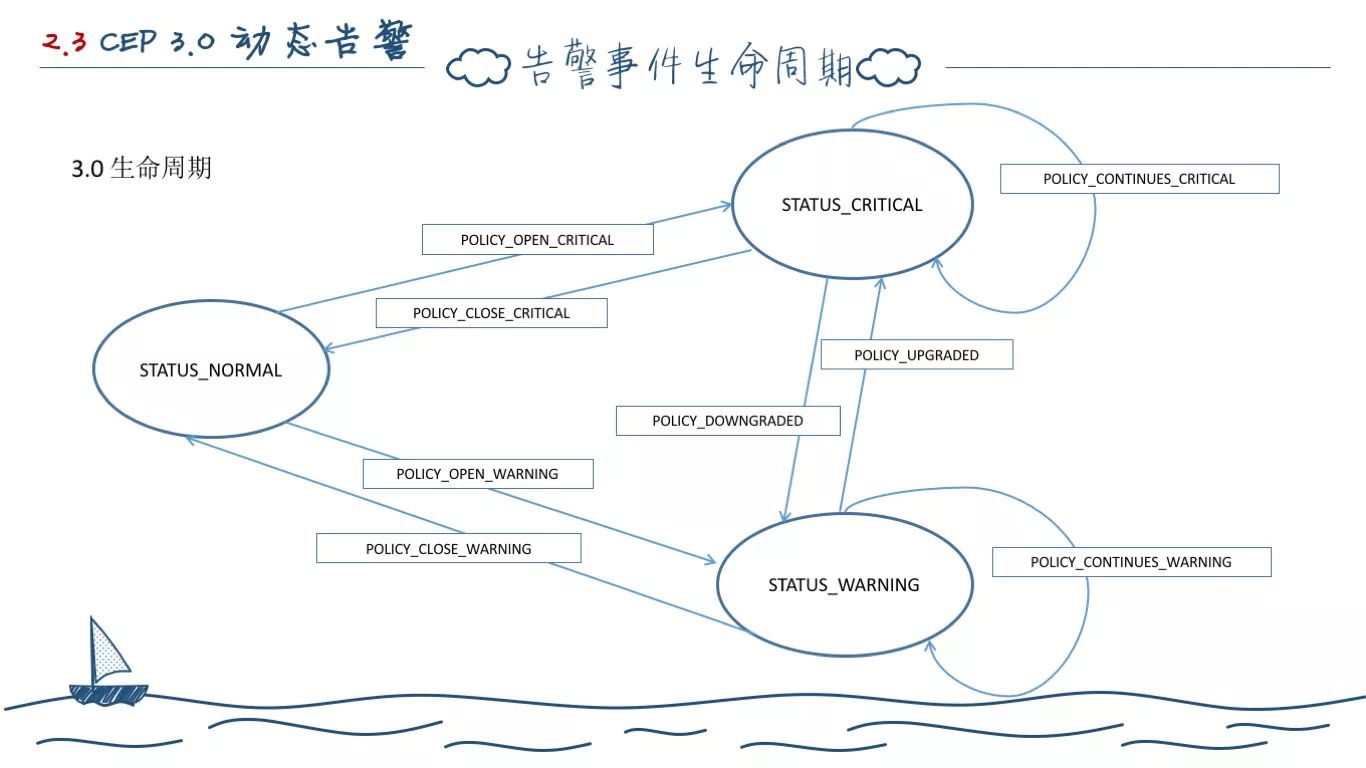
所以我们将告警引擎产生的事件分为两大类:HealthStatusEvent、HealthRuleVolatation 事件。
前者就是图上的三个圈,也就是前面的正常、警告、严重。(做鼠标指点状)应用状态从“普通”到“严重”会产生“开启严重”事件。应用状态从“警告”到“普通”会产生“关闭警告”事件,应用状态持续在“警告”或者“严重”会产生持续类事件。我们对于告警的触发配置转为这种状态转换的事件。
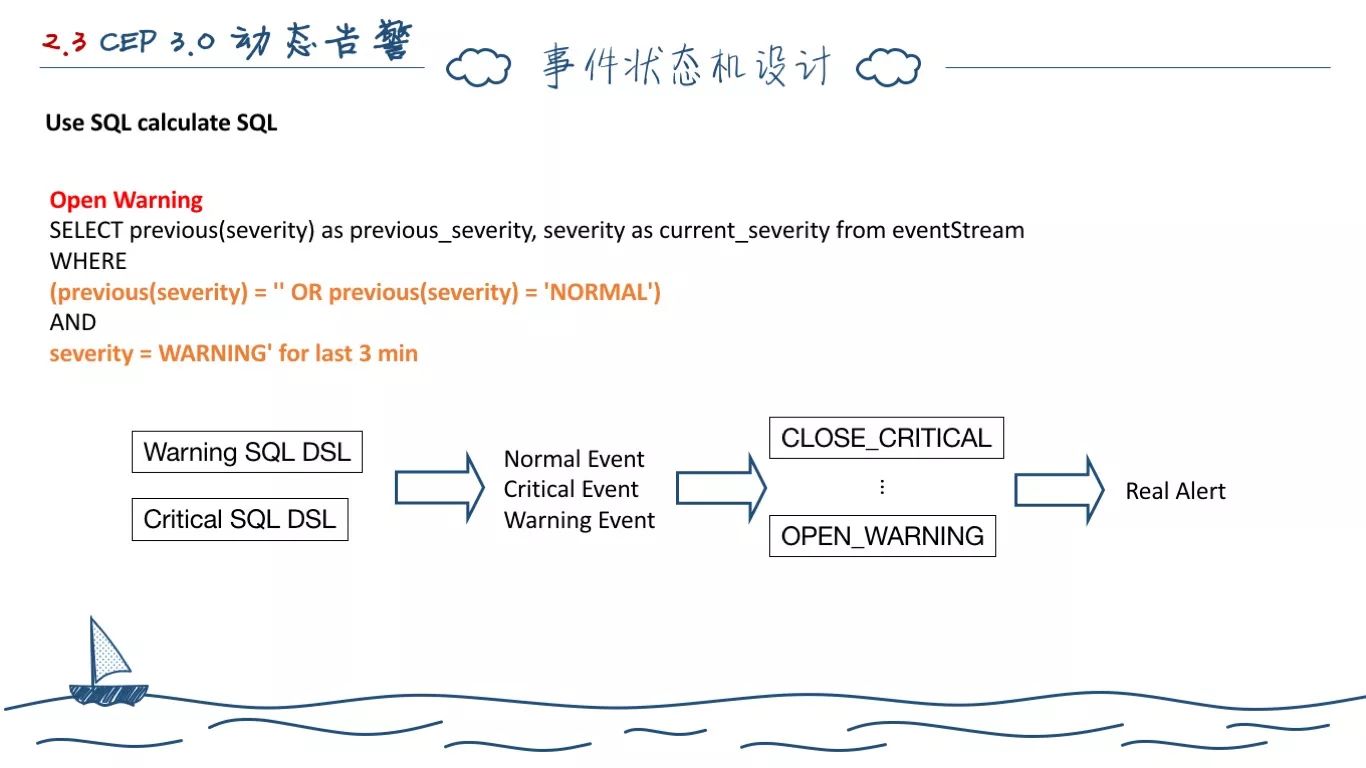
有了前面的设计之后,我们遇到了第一个问题,如何在现行的 Akka 应用上设计一个告警事件状态机。我们想了很多方式,后面我们发现,自己完全想岔了。
之前开发的 Engine 模块结合 Runtime 模块完全可以解决这个问题,我们只需要按照之前定义的 8 个事件转换状态定义 8条 SQL,配置三个子 RuntimeContext 即可解决这个问题。比如开启警告事件,它的 SQL 定义如上。也就是之前一个告警事件如果为空或者为NORMAL事件,当前这条事件为警告事件,则生成开启告警事件。

我们对于不同时间段应用的期望运行情况可能是不一样的,比如一天当中的几个小时,一星期中的几天或者一年当中的几个月。举个例子来说,淘宝应用在周末两天可能会存在较多的交易从而产生高于平时的吞吐量。一个工资支付应用可能相较于一个月中的其他事件,会在月初和月末产生较大的流量。一个客户管理的应用在周一的营业时间相较于周末来说会有较大的工作负荷压力。
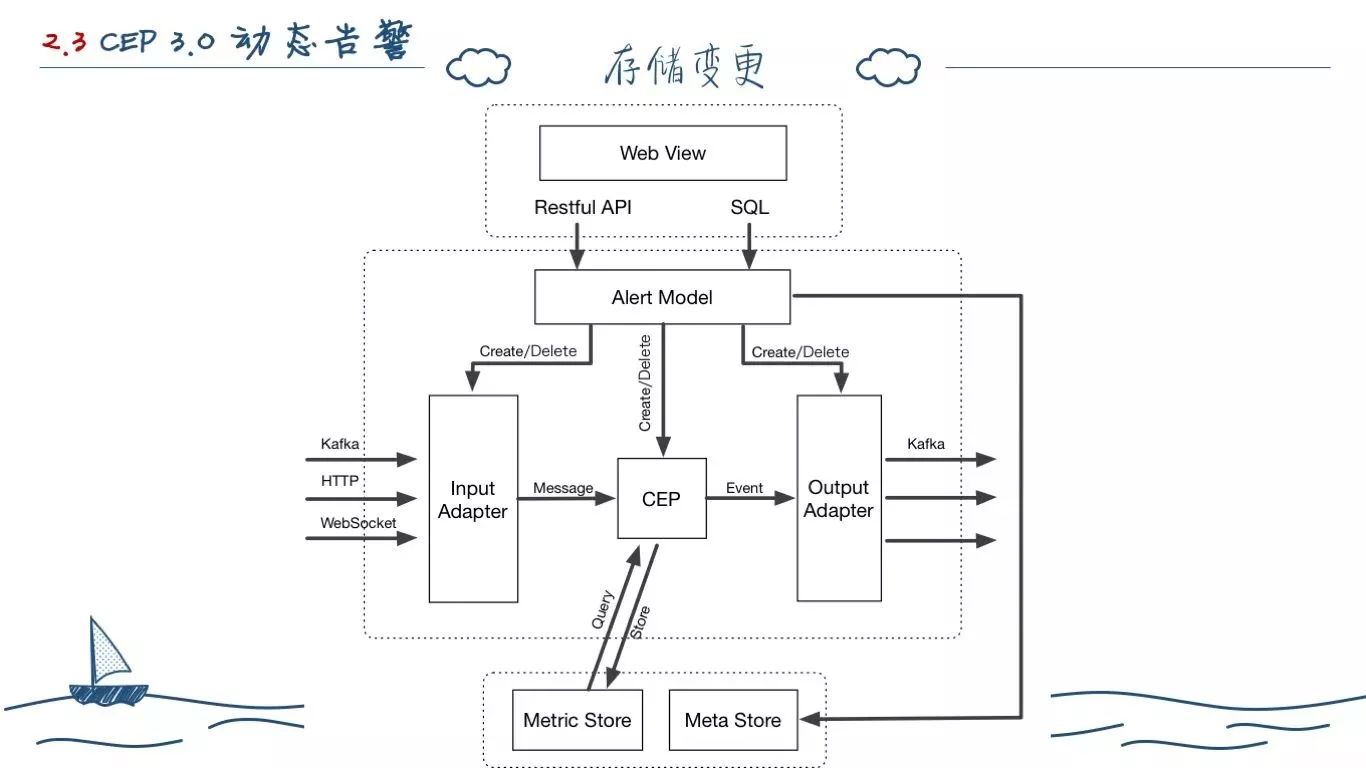
我们在 2.0 的版本开始受制于 Cassandra。
一方面,我们建表的时候,为了某些性能在 Partition Key 内增加了时间戳导致查询的时候必须要提供时间区间。另一方面,沿用的是2年前的 Cassandra 版本,无法像 3.0 之后的版本一样有更丰富的查询方式,比如基于某一列的查询。
其次,在 2.0 之前的版本,每条指标的计算结果,就算是 Normal 都会存入 Cassandra,这是因为 Flink 版本计算的遗留问题。而我们在设计了告警事件的状态变化告警之后,存储 Normal 变为意义不大。
最后,除了告警事件,其他的数据:如规则、策略、行为等配置数据,撑死了也就几十万条,完全没有必要用 Cassandra 来存储。它的使用,反而会增加企业级的部署麻烦。
所以我们进行了变更,用 MySQL 去存储除告警事件之外的数据。告警事件因为有了金字塔模块,所以我们直接写入 Kafka 即可。
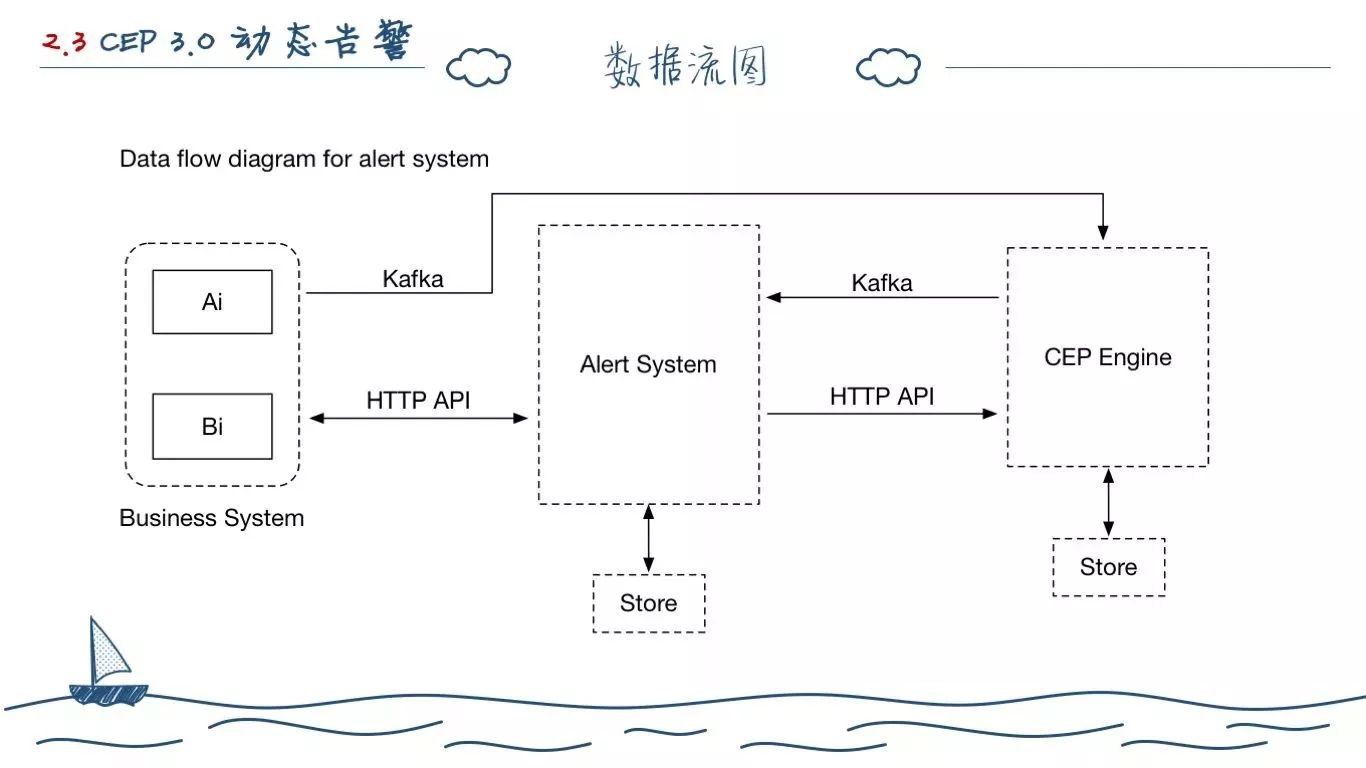
为了应对 2.0 版本的接入麻烦,因为构造 SQL、告警通知行为等在 2.0 版本都是外包给业务线自己做的,我们只是打造了一个小而美的 CEP 引擎。所以只有主要的产品 Ai 接入了我们系统。为此,我们把 Ai 中开发的和告警相对于的代码剥离,专门打造了 CEP 上层的告警系统,并要求业务方提供了应用、指标等 API。自行消费处理 Kafka 中的告警事件,触发行为。
其次,做的一个很大改动就是适配了各个业务线的探针数据,直接接受全量数据。
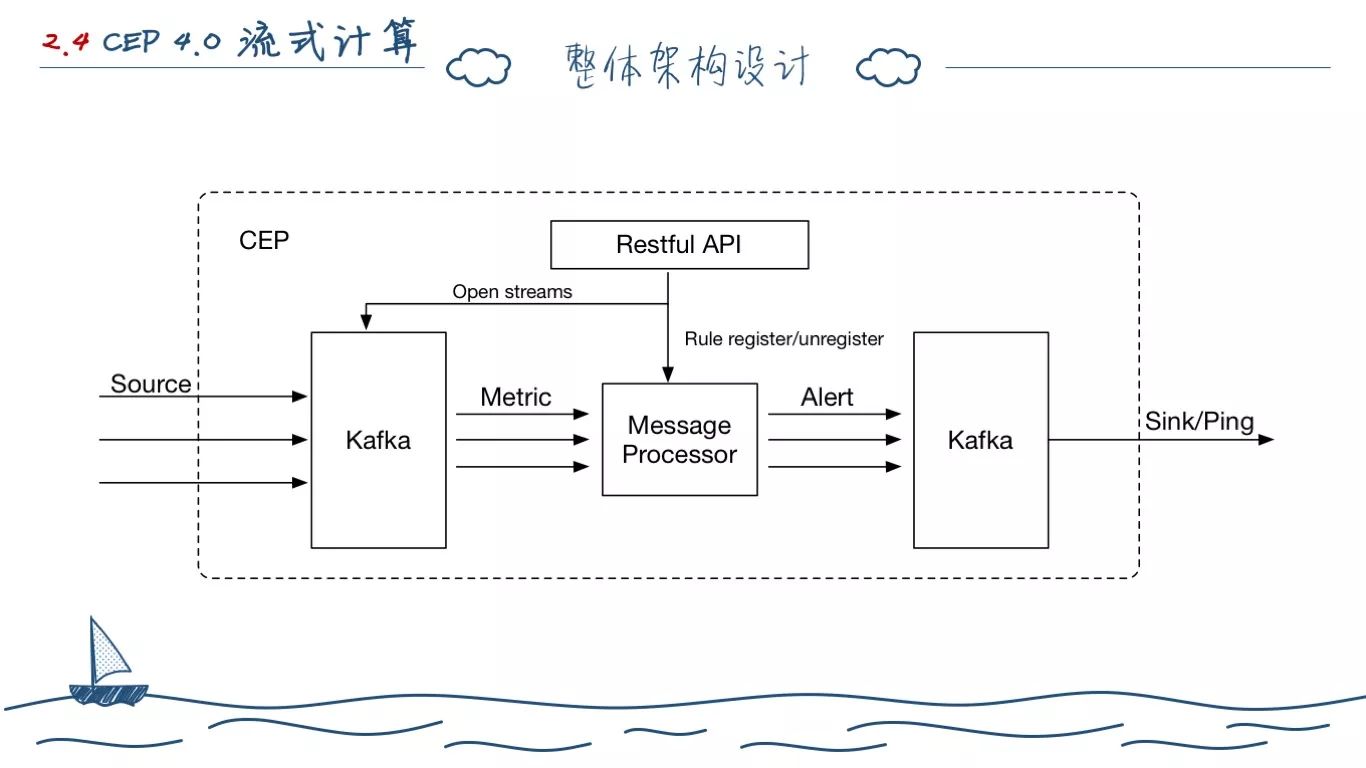
4.0 阶段的告警其实并没有开发,当时主要协作的另一位同事在6月离职,我在8月底完成 3.0 的工作后也离职,但是设计在年初就完成了。
我们在开发金子塔存储的时候,很大的一个问题就是如何流式消费 Kafka 的数据,当时正好 Kafka 提供了 Stream 编程。我们使用了 Akka Stream 去开发了对应的聚合应用 Analytic Store。
同样,我们希望这个单独开发的 CEP 应用,也能变成 Reactive 化。对应的我们将上下行的 Kafka 分别抽象为 Source 和 Sink 层,它们可以使用 Restful API 动态创建,而非现在写死在数据库内。
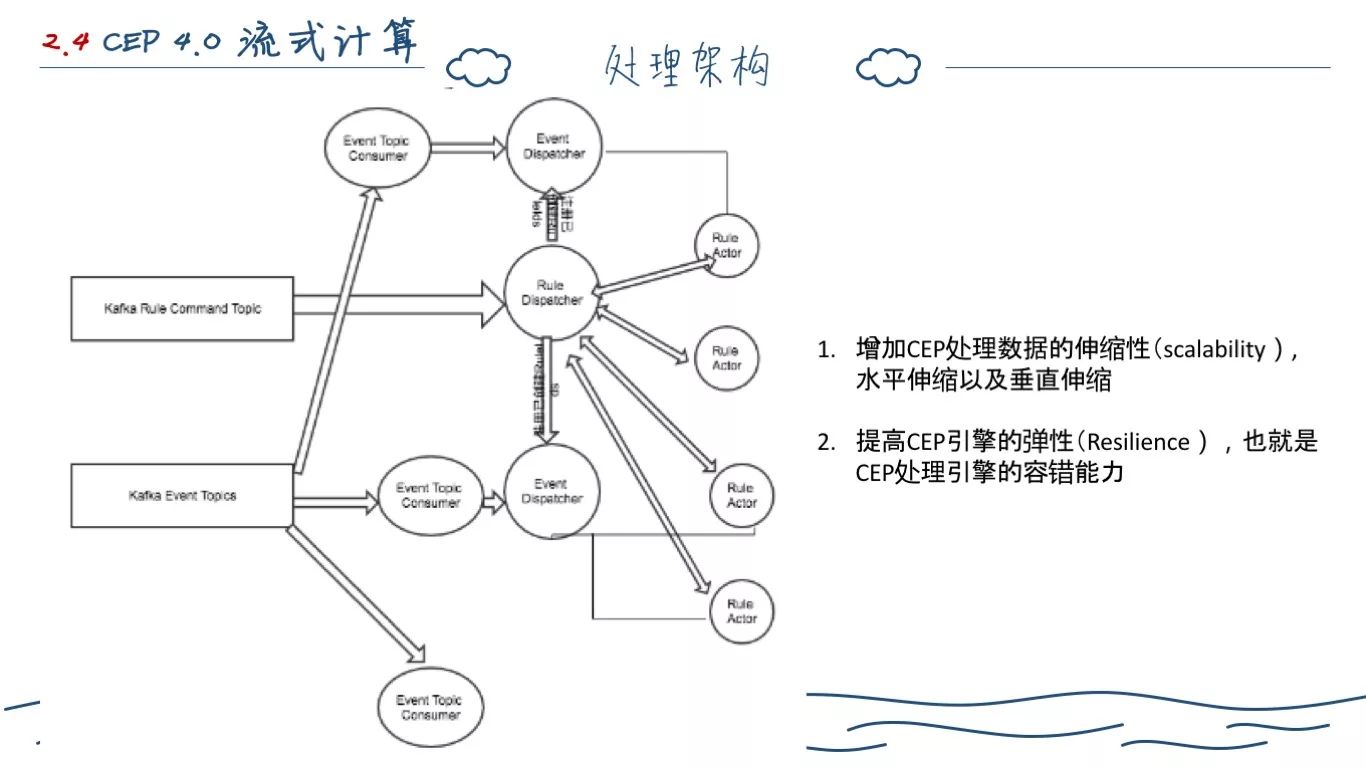
基于这一思想,我们大概有上述的技术架构(图可能不是很清晰)。
设计目标:
增加CEP处理数据的伸缩性(Scalability),水平伸缩以及垂直伸缩 提高CEP引擎的弹性(Resilience),也就是CEP处理引擎的容错能力。
设计思路:
在数据源对数据进行分流(分治);在Akka集群里,创建Kafka Conumser Group, Conumser个数与Topic的分区数一样,分布到Akka的不同节点上。这样分布到Akka某个节点到Event数据就会大大减少。
在数据源区分Command与Event;把Rule相关到Command与采集到Metric Event打到不同的topic,这样当Event数据很大时,也不会影响Command的消费,减少Rule管理的延迟。
对Rule Command在Akka中采用singleton RuleDispatcher单独消费,在集群中进行分发,并且把注册ruleId分发到集群中每个EventDispatcher里。因为Rule Command流量相对于Event流量太少,也不会出现系统瓶颈。
因为RuleDispatcher在Akka集群是全局唯一的,容易出现单点故障。因为RuleDispathcer会保存注册后的RuleIds,需要对RuleId进行备份,这个可以采用PersitentActor来实现。
对于RuleDispatcher down掉重启的这段时间内,因为RuleDispatcher分发过RuleId到各个节点的EventDispatcher,因此各个节点事件分发暂时不会受到影响。 在Akka集群里每一个Kafka conumser,对于一个EventDipatcher,负责把事件分发对感兴趣对RuleActor(根据每个RuleId对应感兴趣对告警对象)。
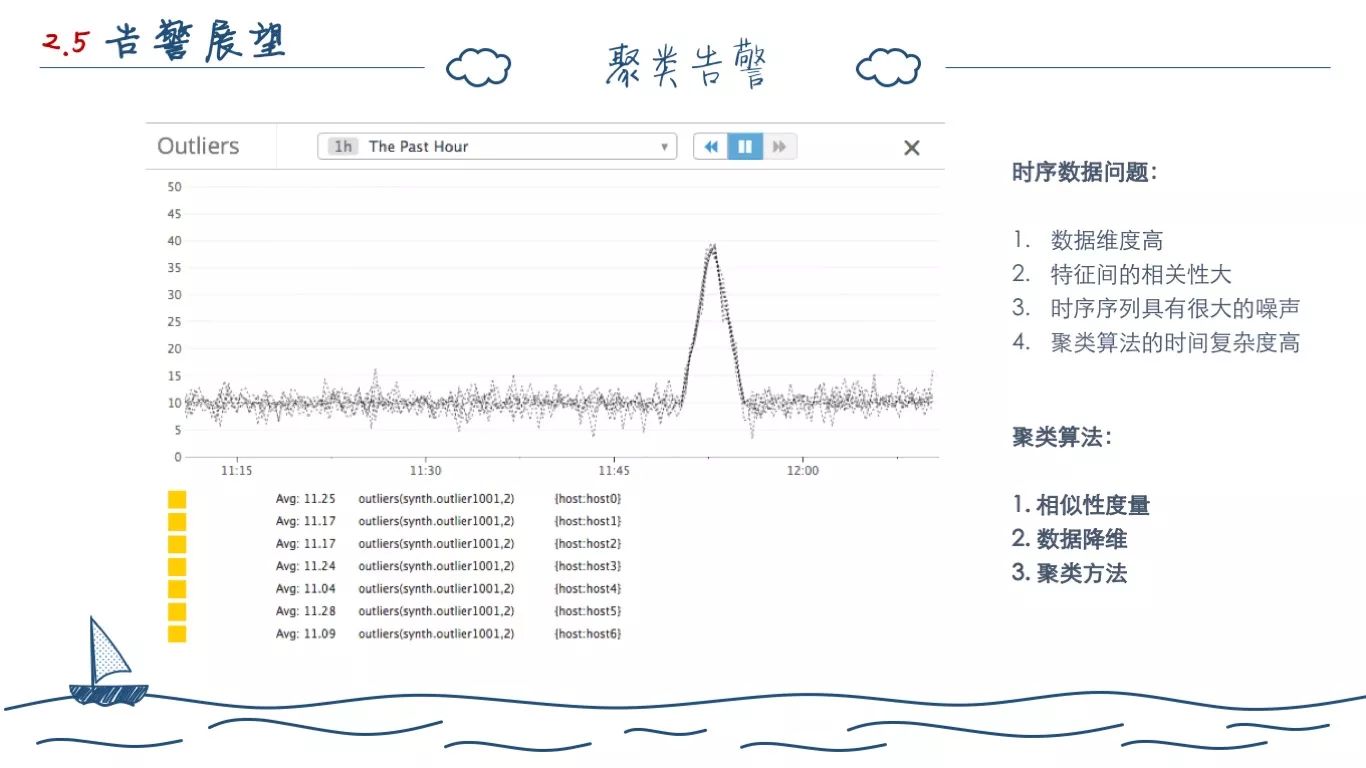
常见的聚类算法有三类:基于空间划分的、基于层次聚类的和基于密度聚类的方法。聚类算法一般要求数据具有多个维度,从而能够满足对海量样本进行距离(相似性)度量,从而将数据划分为多个类别。其中维度特征一般分为CPU利用率、磁盘利用率、I/O使用情况、内存利用率、网络吞吐量等。
相似性度量方法
相似性度量一般采用LP范式,如L0、L1、L2等,其一般作为两个样本间的距离度量;Pearson相关系数度量两个变量的相似性(因为其从标准分布及方差中计算得到,具有线性变换不变性);DTW(动态时间规整算法)用于计算两个时序序列的最优匹配。 其中基于LP范式的时间复杂度最低O(D)。
数据压缩(降维)方法
在数据维度较大的情况下,通过数据压缩方法对时序序列进行降维是聚类算法的必备步骤。其中较为常用的数据降维方法有Discrete Fourier Transform, Singular Value Decomposition, Adaptive Piecewise Constant Approximation, Piecewise Aggregate Approximation, Piecewise Linear Approximation and the Discrete Wavelet Transform。下采样方法也是一类在时序序列中较为常用的技术。 降维方法的时间复杂度一般在O(nlogn)到O(n^3)不等。
聚类方法
基于空间划分的、基于层次聚类的和基于密度聚类的方法。如 K-means,DBSCAN 等。K-Means 方法是通过对整个数据集计算聚类中心并多次迭代(时间复杂度降为O(n*K*Iterations*attributes)),而Incremental K-Means方法是每加入一个数据项时,更新类别中心,时间复杂度为O(K*n),所以其对初始化中心不敏感,且能很快收敛。 时间复杂度一般在 O(nlogn) 到 O(n^2)

之前看 Openresty 的作者章亦春在 QCon 上的分享,他谈到的最有意思的一个观点就是面向 DSL 编程方式。将复杂的业务语义以通用 DSL 方式表达,而非传统的重复编码。诚然,DSL 不是万金油,但是 OneAPM 的告警和 Ai 数据分析,很大程度上受益于各类 DSL 工具的开发。通过抽象出类 SQL 的语法,才有了非常可靠的扩展性。
Akka 和 Scala 函数式编程的使用,很大程度上简化了开发的代码量。我在16年年初的时候,还是拒绝 Scala 的,因为当时我看到的很多代码,用 Java 8 的 Lambda 和函数式都能解决。直到参与了使用 Scala 开发的 Mock Agent 之后才感受到 Scala 语言的灵活好用。函数式语言在写这种分析计算程序时,因为其语言本身的强大表达能力写起来真的很快。这也是为什么目前大数据框架,很多都是 Scala 编写的缘故。
Akka 的使用,我目前还只停留在表面,但是它提供的 Actor 模型,Actor Cluster 等,在分布式平台还是极其便捷的。
Antlr4 的学习,符号化与 SQL 生成。在编写 DSL 的时候,最大的感受就是解析与语言生成,它们正好是两个相反的过程。一个是将语言符号化解析成树,另一个是基于类似的定义生成语言。这一正一反的过程,在我们适配旧的告警规则配置数据的时候,感受颇深,十分奇妙。

点击【阅读原文】是图灵社区发布的版本。如果有任何问题,大家可以在留言中提出。












