从后端来讲,新浪微博可以分为Java和LNMP两大体系,特别是在LNMP方面积累了很多经验。发展初期,新浪微博侧重从性能角度出发,做架构方面的调整和优化。近两年,它投入人力、物力,把重点放在了弹性扩容方面。
新浪微博作为社交产品,经常出现因某些原因所致的话题突发流量峰值,且峰值不可预估。例如:
话题业务的特点是平时流量比较平稳,波动很小,一旦出现突发事件,10分钟时间流量就会突增2-3倍。像这样的流量,一般持续时间不会长,约1个小时左右。
新浪微博在做架构调整之前,和很多公司的处理方案都相似,采用设备冗余与服务降级两大传统手段。
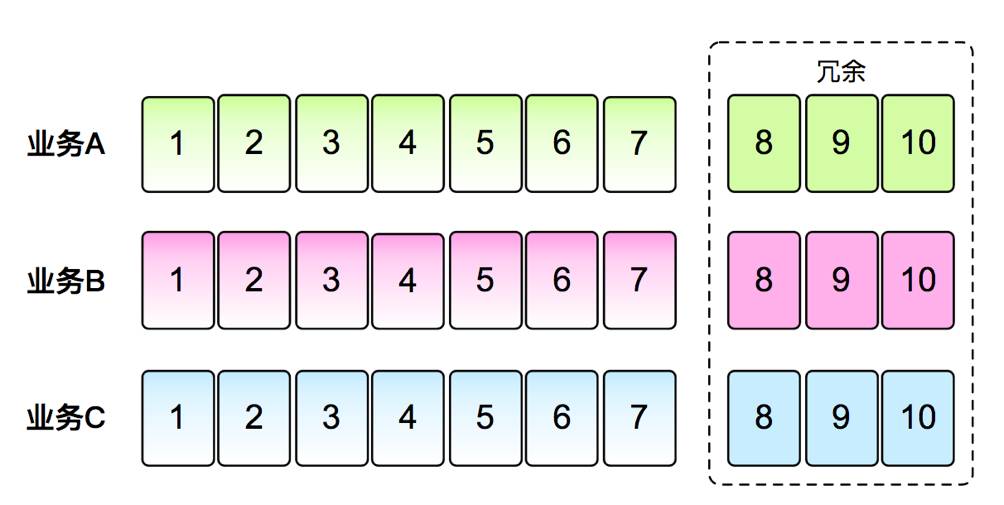
设备冗余。各业务提前申请足够的设备保证冗余,正常情况下一台服务器CPU约在20%-30%左右,当峰值到来会达到60%-70%,系统就会严重警告,需要做服务器扩容。一般情况下,系统会准备一倍左右的冗余。但这就存在一个问题,流量如果翻三倍、四倍怎么办?
服务降级
。当突发流量峰值,系统将对非核心业务以及周边业务进行降级,PC主站只保留主feed。内部降级的方式有很多,降级后用户基本感觉不到。如极端情况下,系统一定主要保留微博主站,其他功能模块全下线,进而保证服务不会挂掉。
但从公司、老板层面,肯定不愿意出现这样的情况,因为降级对广告的影响很大。但是在传统架构下,面对突然产生的流量,技术只能这样做。
这两种传统手段,面临一系列的扩容和降级难题:
-
设备申请周期长
。如机房从其他业务挪用服务器,周期不会太长。但每年三节都会对常规流量进行预估,做好几倍扩容。假设机器不够,会发起采购,但周期会非常长。
-
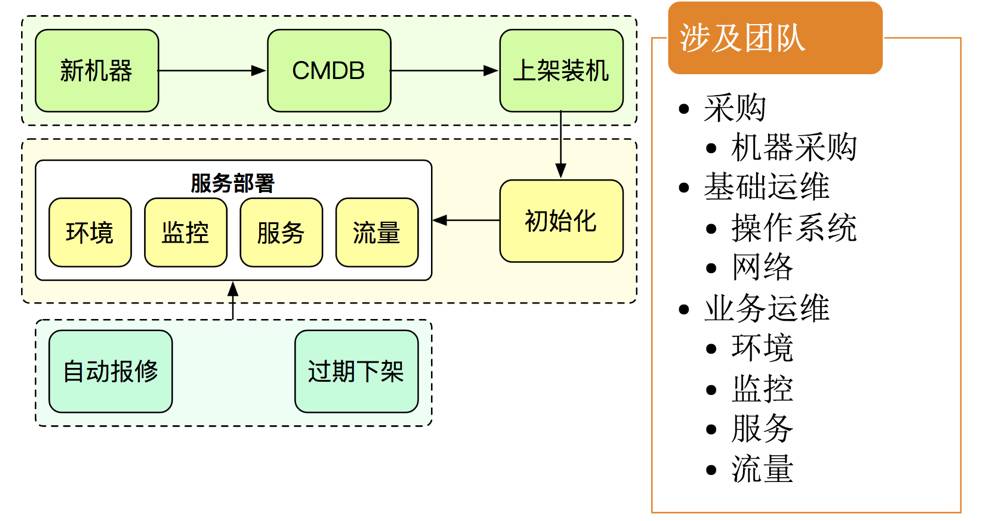
扩缩容繁琐
。如下图,当服务器到位,做扩容,又是一个繁琐流程,还需要多部门共同合作。
-
设备运营成本高
。如每个业务都做一定的冗余,假设一百台服务器,要用二百台来保证正常运营,可以想象这个成本会非常高。举例,PC和手机端,业务峰值不在一个点,峰值不在一起,利用率也有所差别,就算同一事件,每个业务的负载也会不一。业务之间拆借,也是行不通。因为短时间内,无法应对服务器之间的环境差异、代码等差异,初始化完毕,峰值也消失了。
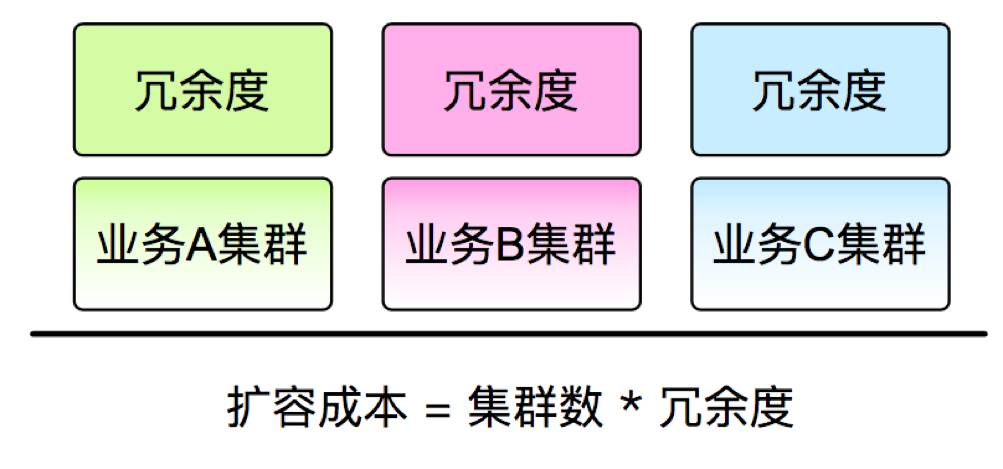
综上所述,扩容和峰值是面对突发流量峰值的两个解决维度,但存在的问题是扩容不能针对服务器快速扩容、降级又对服务器损害相对较大。
新浪微博决定从架构层面解决这两个问题,通过引入混合云DCP平台,达到下面的效果:

DCP(Docker Container Platform)平台解决思路是从业务的弹性角度,在各业务之间,无论是Java还是PHP等,通过抹平所有的环境,快速应对峰值,同时在基础设施上支持跨云。之后,在内容服务器用完的情况下,可借用公有云这份解决方案,把流量峰值问题迁移到公有云。
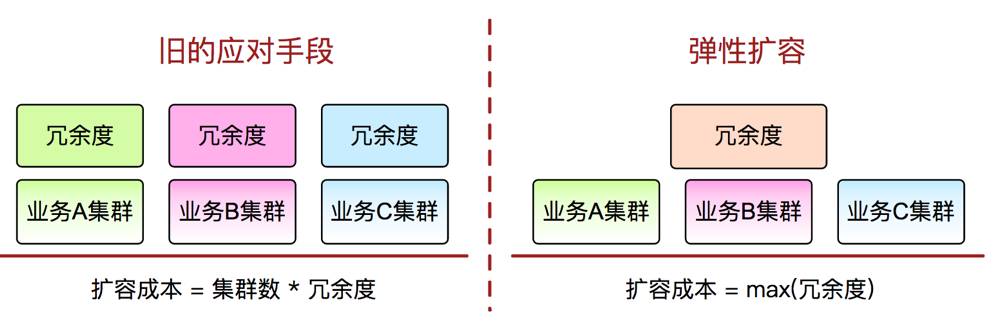
业务弹性调度
。如下图,是旧的应对手段和弹性扩容手段的对比。实现弹性扩容后,系统会使用容器化来抹平各业务环境,把各业务之间的冗余部分放到共享池。这样一来,哪个业务需要扩容,就可以很简单地从共有池把这部分设备扩容。
因各个业务之间的峰值和负载程度不一,把其他业务的冗余设备拆借过来,实际扩容能力相比以前的1~2倍,可以提升到2-3倍。
基础设施支持跨云
。如下图,是私有云和公有云各自的优势。针对各自的特点,在部署流量时,需做一些侧重操作。如针对常规的流量,优先会部署到私有云,保障体验、性能等都是最优。这里涉及公有云安全性和私有云之间有一定差异以及在性能上会有一定下降的问题。
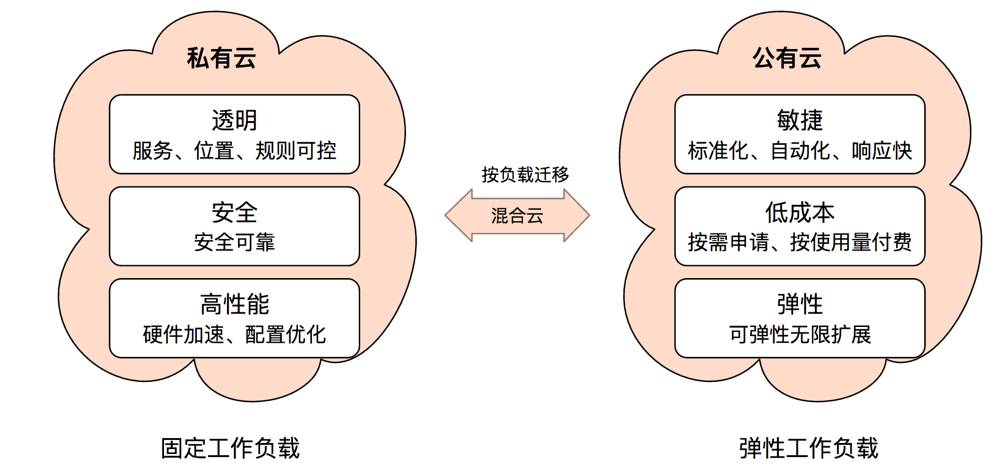
假设在公有云流量部署1小时,其中可能公有云一些服务还会依赖于私有云服务,这样就会出现跨机房调用的情况。可服务只是微慢,而不是降级或停用,和之前相比优势很大。另外,假设把常规的负载也部署到公有云,只要把所有底层全部做多机房部署,根据不同业务做流量分配即可。
DCP平台架构
。如下图,是DCP平台抽象版架构,主要分为主机、环境、服务和业务四层:
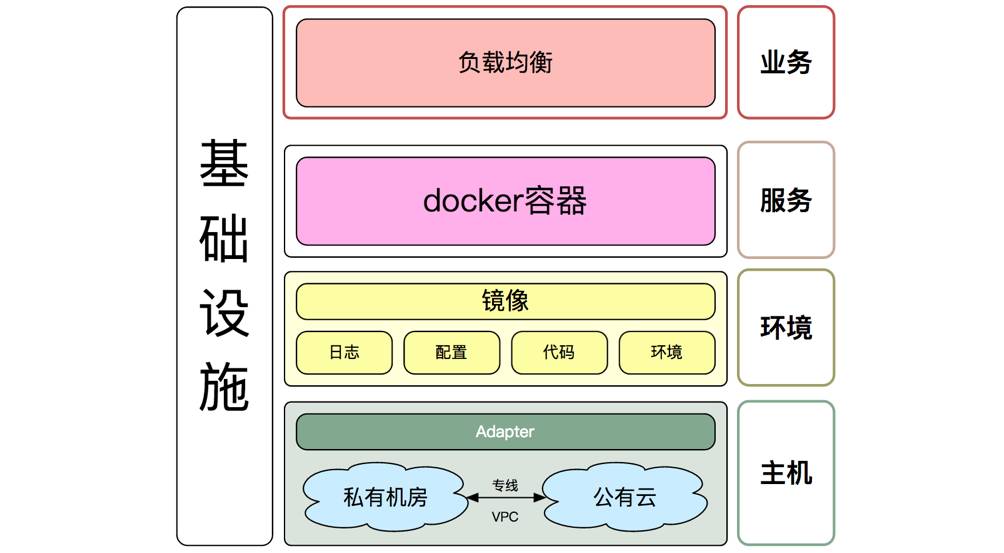
DCP平台抽象版架构
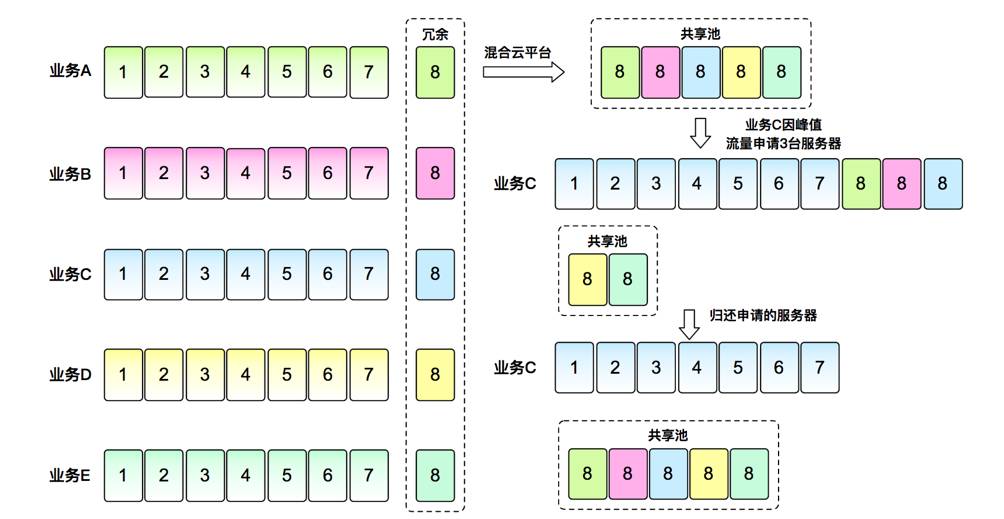
私有云“化零为整”
。如下图,是一个基于DCP的模型,左侧是传统架构,假设长方形是每个业务需要的机器,如A业务要扩充两台,就承载不了,就需降级。右侧接入到混合云后,把所有业务的环境抹平,所有设备放到共享池,假设C业务需要三台设备,在新的架构下,可轻松从共有池选取。