(点击上方蓝字,快速关注我们)
编译:伯乐在线 - Ree Ray
如有好文章投稿,请点击 → 这里了解详情
2005 年诺贝尔经济学奖得主托马斯·谢林(Thomas Schelling)在上世纪 70 年代就纽约的人种居住分布得出了著名的 Schelling segregation model,这是一个 ABM(agent-based model),当年谢林只能通过铅笔在纸上进行模拟,而这次则利用 Python 进行仿真实现这个模型。
在计算机科学中,基于 Agent 的模型(agent-based models)被用来评估独立(autonomous)agent(诸如个体、群组或物体)在整个系统中的影响。这个强大的分析工具常被用在实验难以开展或者费用太高的时候。在社会科学,计算机科学,经济学和商务各领域,这个模型都有着相当广泛的应用。
在本文中,我会向你介绍用基于 Agent 的模型理解复杂现象的威力。为此,我们会用到一些 Python,社会学的案例分析和 Schelling 模型。
1. 案例分析
如果你观察多民族(multi-ethnic)混居城市的种族(racial)分布,你会对不可思议的种族隔离感到惊讶。举个例子,下面是美国人口普查局(US Census)用种族和颜色对应标记的纽约市地图。种族隔离清晰可见。
许多人会从这个现象中认定人是偏隘的(intolerant),不愿与其它种族比邻而居。然而进一步看,会发现细微的差别。2005 年的诺贝尔经济学奖得主托马斯·谢林(Thomas Schelling)在上世纪七十年代,就对这方面非常感兴趣,并建立了一个基于 Agent 的模型——“Schelling 隔离模型”的来解释这种现象。借助这个极其简单的模型,Schelling 会告诉我们,宏观所见并非微观所为(What’s going down)。
我们会借助 Schelling 模型模拟一些仿真来深刻理解隔离现象。

2. Schelling 隔离模型:设置和定义
基于 Agent 的模型需要三个参数:1)Agents,2)行为(规则)和 3)总体层面(aggregate level)的评估。在 Schelling 模型中,Agents 是市民,行为则是基于相似比(similarity ratio )的搬迁,而总体评估评估就是相似比。
假设城市有 n 个种族。我们用唯一的颜色来标识他们,并用网格来代表城市,每个单元格则是一间房。要么是空房子,要么有居民,且数量为 1。如果房子是空的,我们用白色标识。如果有居民,我们用此人的种群颜色来标识。我们把每个人周边房屋(上下左右、左上右上、左下右下)定义为邻居。
Schelling 的目的是想测试当居民更倾向于选择同种族的邻居(甚至多种族)时会如果发生什么。如果同种族邻居的比例上升到确定阈值(称之为相似性阈值(Similarity Threshold)),那么我们认为这个人已经满意(satisfied)了。如果还没有,就是不满意。
Schelling 的仿真如下。首先我们将人随机分配到城里并留空一些房子。对于每个居民,我们都会检查他(她)是否满意。如果满意,我们什么也不做。但如果不满意,我们把他分配到空房子。仿真经过几次迭代后,我们会观察最终的种族分布。
3. Schelling 模型的 Python 实现
早在上世纪 70 年代,Schelling 就用铅笔和硬币在纸上完成了他的仿真。我们现在则用 Python 来完成相同的仿真。
为了模拟仿真,我们首先导入一些必要的库。除了 Matplotlib 以外,其它库都是 Python 默认安装的。
import matplotlib.pyplot as plt
import itertools
import random
import copy
接下来,定义名为 Schelling 的类,涉及到 6 个参数:城市的宽和高,空房子的比例,相似性阈值,迭代数和种族数。我们在这个类中定义了 4 个方法:populate,is_unsatisfied,update,move_to_empty, 还有 plot)。
class Schelling:
def __init__(self, width, height, empty_ratio, similarity_threshold, n_iterations, races = 2):
self.width = width
self.height = height
self.races = races
self.empty_ratio = empty_ratio
self.similarity_threshold = similarity_threshold
self.n_iterations = n_iterations
self.empty_houses = []
self.agents = {}
def populate(self):
....
def is_unsatisfied(self, x, y):
....
def update(self):
....
def move_to_empty(self, x, y):
....
def plot(self):
....
poplate 方法被用在仿真的开头,这个方法将居民随机分配在网格上。
def populate(self):
self.all_houses = list(itertools.product(range(self.width),range(self.height)))
random.shuffle(self.all_houses)
self.n_empty = int( self.empty_ratio * len(self.all_houses) )
self.empty_houses = self.all_houses[:self.n_empty]
self.remaining_houses = self.all_houses[self.n_empty:]
houses_by_race = [self.remaining_houses[i::self.races] for i in range(self.races)]
for i in range(self.races):
# 为每个种族创建 agent
self.agents = dict(
self.agents.items() +
dict(zip(houses_by_race[i], [i+1]*len(houses_by_race[i]))).items()
is_unsatisfied 方法把房屋的 (x, y) 坐标作为传入参数,查看同种群邻居的比例,如果比理想阈值(happiness threshold)高则返回 True,否则返回 False。
def is_unsatisfied(self, x, y):
race = self.agents[(x,y)]
count_similar = 0
count_different = 0
if x > 0 and y > 0 and (x-1, y-1) not in self.empty_houses:
if self.agents[(x-1, y-1)] == race:
count_similar += 1
else:
count_different += 1
if y > 0 and (x,y-1) not in self.empty_houses:
if self.agents[(x,y-1)] == race:
count_similar += 1
else:
count_different += 1
if x < (self.width-1) and y > 0 and (x+1,y-1) not in self.empty_houses:
if self.agents[(x+1,y-1)] == race:
count_similar += 1
else:
count_different += 1
if x > 0 and (x-1,y) not in self.empty_houses:
if self.agents[(x-1,y)] == race:
count_similar += 1
else:
count_different += 1
if x < (self.width-1) and (x+1,y) not in self.empty_houses:
if self.agents[(x+1,y)] == race:
count_similar += 1
else:
count_different += 1
if x > 0 and y < (self.height-1) and (x-1,y+1) not in self.empty_houses:
if self.agents[(x-1,y+1)] == race:
count_similar += 1
else:
count_different += 1
if x > 0 and y < (self.height-1) and (x,y+1) not in self.empty_houses:
if self.agents[(x,y+1)] == race:
count_similar += 1
else:
count_different += 1
if x < (self.width-1) and y < (self.height-1) and (x+1,y+1) not in self.empty_houses:
if self.agents[(x+1,y+1)] == race:
count_similar += 1
else:
count_different += 1
if (count_similar+count_different) == 0:
return False
else:
return float(count_similar)/(count_similar+count_different) < self.happy_threshold
update 方法将查看网格上的居民是否尚未满意,如果尚未满意,将随机把此人分配到空房子中。并模拟 n_iterations 次。
def update(self):
for i in range(self.n_iterations):
self.old_agents = copy.deepcopy(self.agents)
n_changes = 0
for agent in self.old_agents:
if self.is_unhappy(agent[0], agent[1]):
agent_race = self.agents[agent]
empty_house = random.choice(self.empty_houses)
self.agents[empty_house] = agent_race
del self.agents[agent]
self.empty_houses.remove(empty_house)
self.empty_houses.append(agent)
n_changes += 1
print n_changes
if n_changes == 0:
break
move_to_empty 方法把房子坐标(x, y)作为传入参数,并将 (x, y) 房间内的居民迁入空房子。这个方法被 update 方法调用,会把尚不满意的人迁入空房子。
def move_to_empty(self, x, y):
race = self.agents[(x,y)]
empty_house = random.choice(self.empty_houses)
self.updated_agents[empty_house] = race
del self.updated_agents[(x, y)]
self.empty_houses.remove(empty_house)
self.empty_houses.append((x, y))
plot 方法用来绘制整个城市和居民。我们随时可以调用这个方法来了解城市的居民分布。这个方法有两个传入参数:title 和 file_name。
def plot(self, title, file_name):
fig, ax = plt.subplots()
# 如果要进行超过 7 种颜色的仿真,你应该相应地进行设置
agent_colors = {1:'b', 2:'r', 3:'g', 4:'c', 5:'m', 6:'y', 7:'k'}
for agent in self.agents:
ax.scatter(agent[0]+0.5, agent[1]+0.5, color=agent_colors[self.agents[agent]])
ax.set_title(title, fontsize=10, fontweight='bold')
ax.set_xlim([0, self.width])
ax.set_ylim([0, self.height])
ax.set_xticks([])
ax.set_yticks([])
plt.savefig(file_name)
4. 仿真
现在我们实现了 Schelling 类,可以模拟仿真并绘制结果。我们会按照下面的需求(characteristics)进行三次仿真:
创建并“填充”城市。
schelling_1 = Schelling(50, 50, 0.3, 0.3, 500, 2)
schelling_1.populate()
schelling_2 = Schelling(50, 50, 0.3, 0.5, 500, 2)
schelling_2.populate()
schelling_3 = Schelling(50, 50, 0.3, 0.8, 500, 2)
schelling_3.populate()
接下来,我们绘制初始阶段的城市。注意,相似性阈值在城市的初始状态不起作用。
schelling_1_1.plot('Schelling Model with 2 colors: Initial State', 'schelling_2_initial.png')
下面我们运行 update 方法,绘制每个相似性阈值的最终分布。
schelling_1.update()
schelling_2.update()
schelling_3.update()
schelling_1.plot('Schelling Model with 2 colors: Final State with Similarity Threshold 30%', 'schelling_2_30_final.png')
schelling_2.plot('Schelling Model with 2 colors: Final State with Similarity Threshold 50%', 'schelling_2_50_final.png')
schelling_3.plot('Schelling Model with 2 colors: Final State with Similarity Threshold 80%', 'schelling_2_80_final.png')

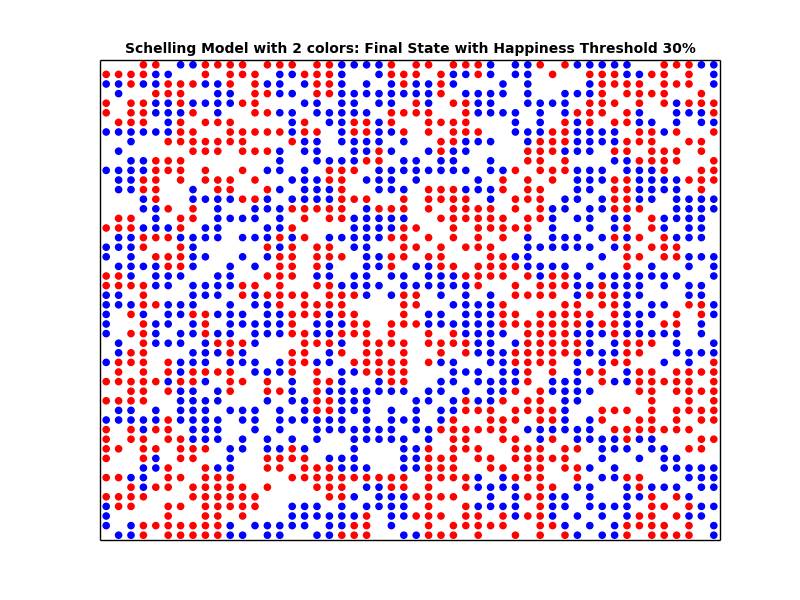


观察以上的绘图,我们可以发现相似性阈值越高,城市的隔离度就越高。此外,我们还会发现即便相似性阈值很小,城市依旧会产生隔离。换言之,即使居民非常包容(tolerant)(相当于相似性阈值很小),还是会以隔离告终。我们可以总结出:宏观所见并非微观所为。
5. 测量隔离
以上仿真,我们只通过可视化来确认隔离发生。然而,我们却没有对隔离的计算进行定量评估。本节我们会定义这个评估标准,我们也会模拟一些仿真来确定理想阈值和隔离程度的关系。
首先在 Schelling 类中添加 calculate_similarity 方法。这个方法会计算每个 Agent 的相似性并得出均值。我们会用平均相似比评估隔离程度。
def calculate_similarity(self):
similarity = []
for agent in self.agents:
count_similar = 0
count_different = 0
x = agent[0]
y = agent[1]
race = self.agents[(x,y)]
if x > 0 and y > 0 and (x-1, y-1) not in self.empty_houses:
if self.agents[(x-1, y-1)] == race:
count_similar += 1
else:
count_different += 1
if y > 0 and (x,y-1) not in self.empty_houses:
if self.agents[(x,y-1)] == race:
count_similar += 1
else:
count_different += 1
if x < (self.width-1) and y > 0 and (x+1,y-1) not in self.empty_houses:
if self.agents[(x+1,y-1)] == race:
count_similar += 1
else:
count_different += 1
if x > 0 and (x-1,y) not in self.empty_houses:
if self.agents[(x-1,y)] == race:
count_similar += 1
else:
count_different += 1
if x < (self.width-1) and (x+1,y) not in self.empty_houses:
if self.agents[(x+1,y)] == race:
count_similar += 1
else:
count_different += 1
if x > 0 and y < (self.height-1) and (x-1,y+1) not in self.empty_houses:
if self.agents[(x-1,y+1)] == race:
count_similar += 1
else:
count_different += 1
if x > 0 and y < (self.height-1) and (x,y+1) not in self.empty_houses:
if self.agents[(x,y+1)] == race:
count_similar += 1
else:
count_different += 1
if x < (self.width-1) and y < (self.height-1) and (x+1,y+1) not in self.empty_houses:
if self.agents[(x+1,y+1)] == race:
count_similar += 1
else:
count_different += 1
try:
similarity.append(float(count_similar)/(count_similar+count_different))
except:
similarity.append(1)
return sum(similarity)/len(similarity)
接下去,我们算出每个相似性阈值的平均相似比,并绘制出相似性阈值和相似比之间的关系。
similarity_threshold_ratio = {}
for i in [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7]:
schelling = Schelling(50, 50, 0.3, i, 500, 2)
schelling.populate()
schelling.update()
similarity_threshold_ratio[i] = schelling.calculate_similarity()
fig, ax = plt.subplots()
plt.plot(similarity_threshold_ratio.keys(), similarity_threshold_ratio.values(), 'ro')
ax.set_title('Similarity Threshold vs. Mean Similarity Ratio', fontsize=15, fontweight='bold')
ax.set_xlim([0, 1])
ax.set_ylim([0, 1.1])
ax.set_xlabel("Similarity Threshold")
ax.set_ylabel("Mean Similarity Ratio")
plt.savefig('schelling_segregation_measure.png')
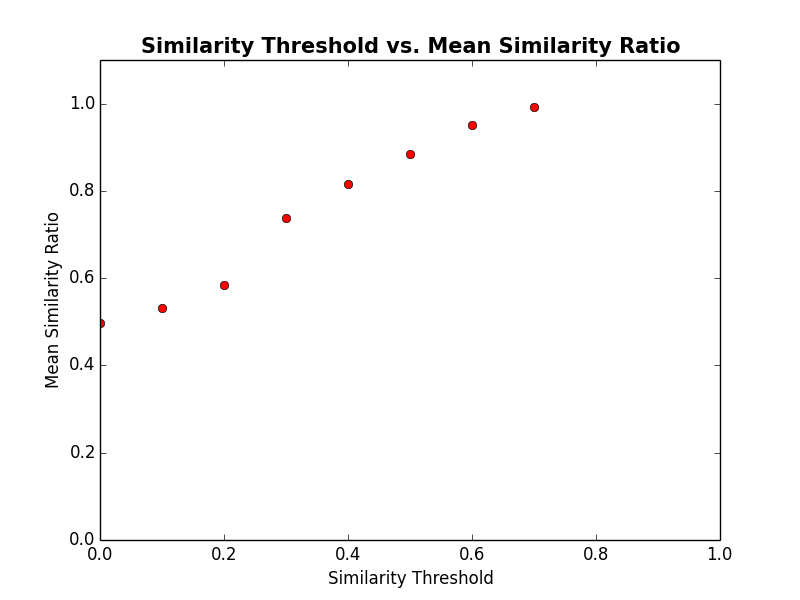
通过上图,可以发现即便相似性阈值非常小,依然会得到很高的隔离度(由平均相似性评估)。举个例子,相似阈值为 0.3,会得到 0.75 的平均相似性。我们可以通过量化再次确定宏观所见并非微观所为。
6. 总结
在本文中,我们介绍了一个基于 Agent 的模型——“Schelling 隔离模型”,并用 Python 实现。这个十分简单的模型帮助我们理解了非常复杂的现象:多民族城市中的种族隔离。我们可以发现城市种族的高度隔离不必解读成个体层面的偏隘。
参考
https://www.coursera.org/course/modelthinking
看完本文有收获?请转发分享给更多人
关注「Python开发者」,提升Python技能











