
大家好,我是橙哥!今天,我们来看一下如何使用LSTM模型进行股票价格预测,并通过Alpaca API实现自动化交易。这段代码主要分为以下几个主要部分:导入必要的库、数据准备、模型构建、模型训练、模型加载和评估,以及通过API进行自动交易。每个部分都有其独特的功能,共同协作完成从数据处理到交易执行的全过程。首先,我们需要导入一些必要的库来支持我们的任务。这些库包括处理日期和时间的datetime,发送HTTP请求的requests,从Yahoo Finance下载股票数据的yfinance,以及数据处理和数值计算的numpy和pandas。此外,我们还需要sklearn.model_selection来划分数据集,以及keras来构建和训练神经网络模型。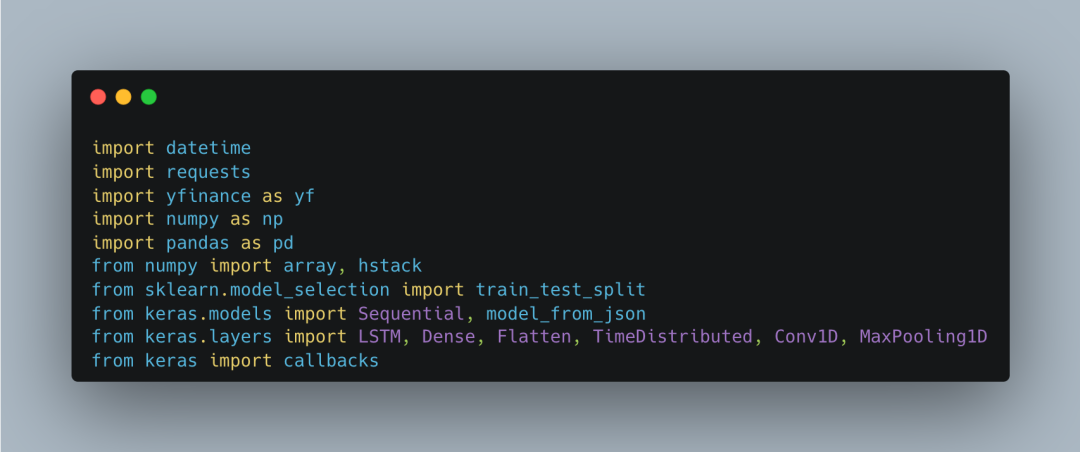
数据准备函数
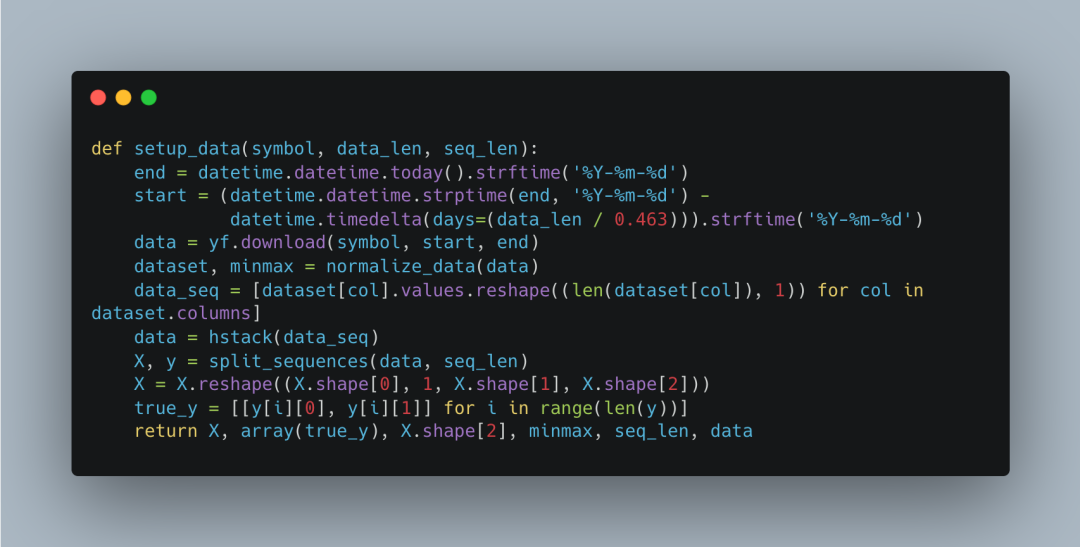
接下来,我们定义了一个数据准备函数setup_data。这个函数负责准备我们的数据。首先,它计算出数据的起始和结束日期。然后,使用yfinance下载指定股票代码的数据。接着,调用normalize_data函数对数据进行标准化处理。最后,将数据转换为适合LSTM模型的序列格式,并返回处理后的数据和相关参数。
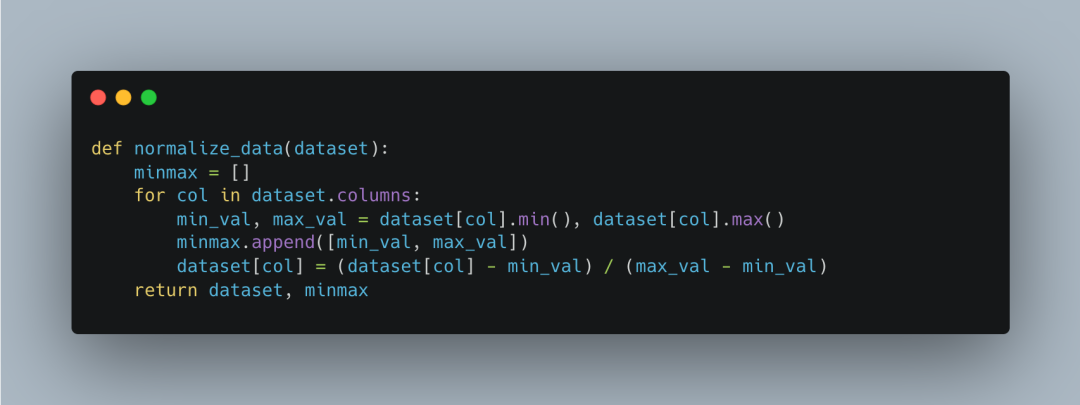
数据标准化函数
数据标准化函数normalize_data负责将数据标准化到[0, 1]范围内。它计算每列的最小值和最大值,并保存这些值。然后,对每列数据进行标准化处理,以确保数据的一致性和可比性。
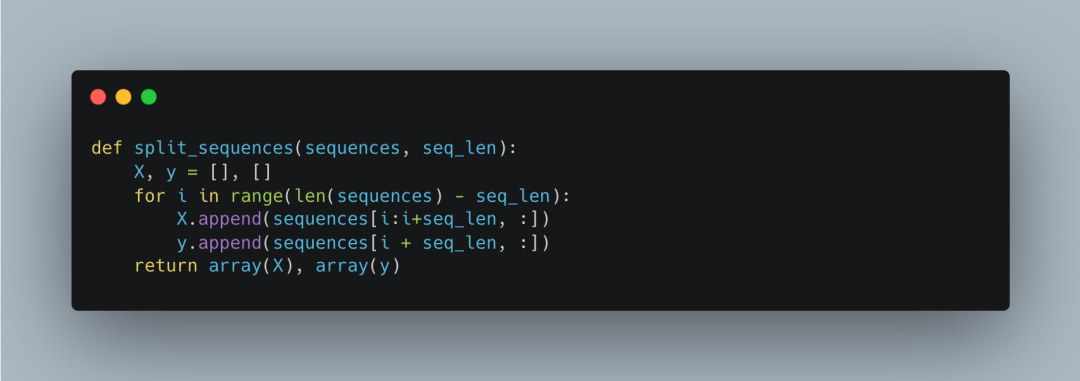
数据序列化函数
数据序列化函数split_sequences将数据集划分为输入序列(X)和输出序列(y)。seq_len是每个序列的长度。
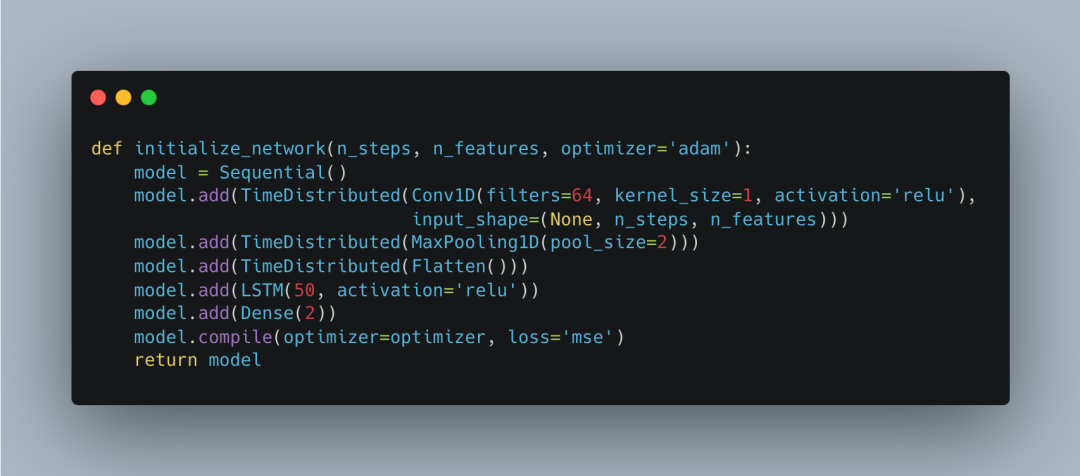
初始化和编译LSTM模型
接下来,我们定义了一个函数initialize_network,负责搭建我们的LSTM模型。模型结构包括一个卷积层、池化层、扁平化层、LSTM层和全连接层。使用adam优化器和均方误差(MSE)作为损失函数。
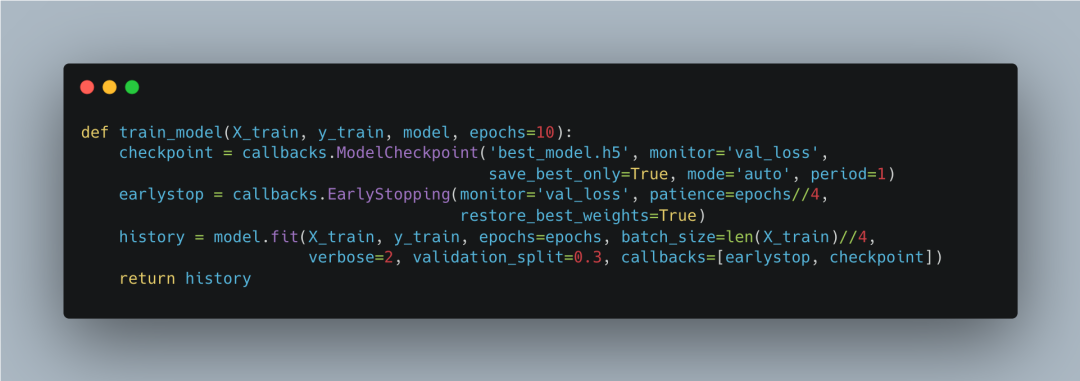
训练LSTM模型
训练LSTM模型的函数train_model负责训练我们的LSTM模型。使用ModelCheckpoint回调函数保存最佳模型,使用EarlyStopping回调函数在验证损失不再改善时提前停止训练。返回训练历史记录。
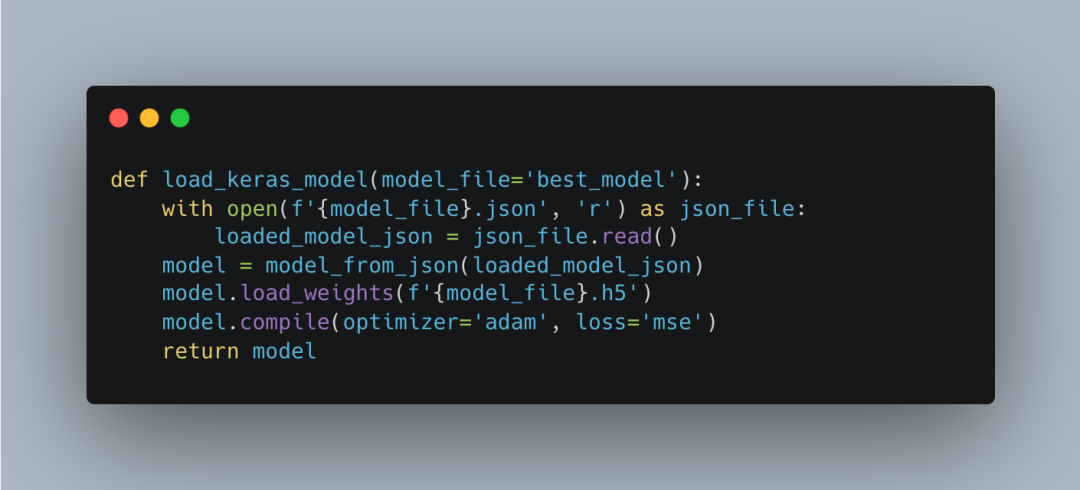
加载训练好的LSTM模型
加载训练好的LSTM模型的函数load_keras_model负责加载已经训练好的LSTM模型。从JSON文件中加载模型的结构,并从HDF5文件中加载模型的权重。
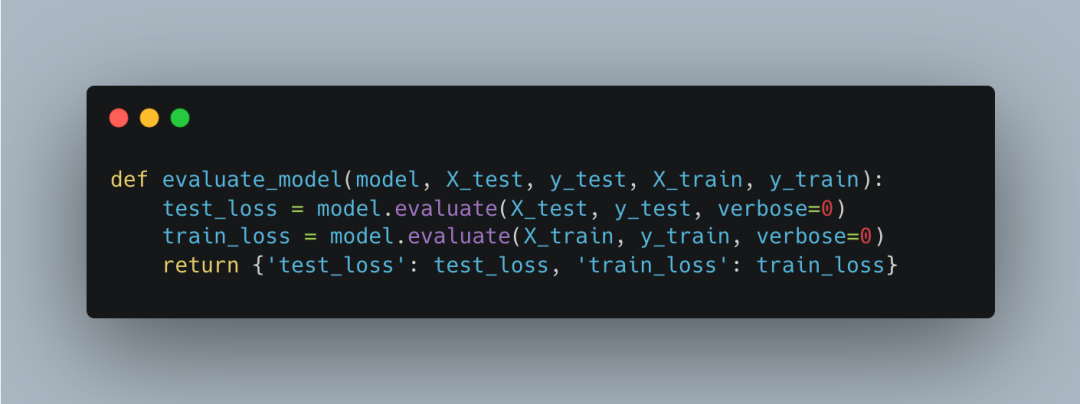
评估模型性能
评估模型性能的函数evaluate_model负责评估模型的性能。计算训练集和测试集上的损失值,并返回结果。
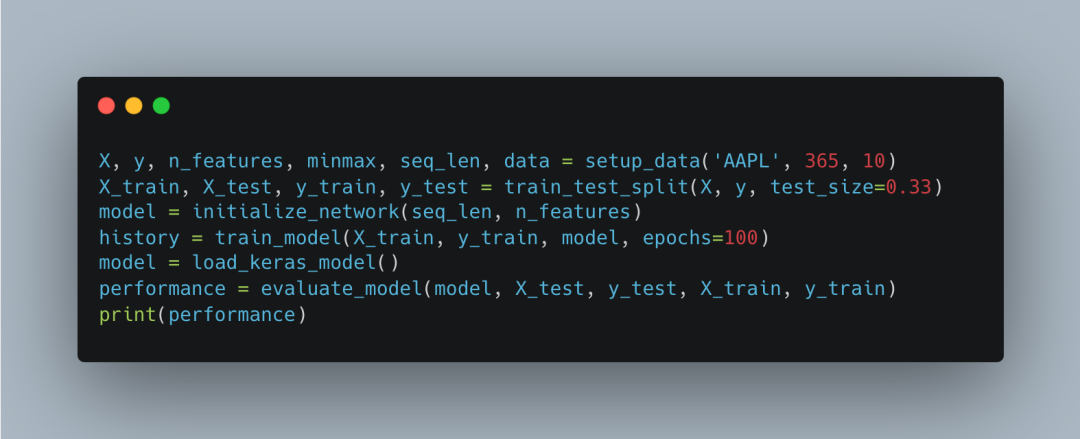
主执行部分
这部分代码是我们的主程序。调用setup_data函数准备数据,使用train_test_split将数据划分为训练集和测试集,初始化并训练LSTM模型,加载训练好的模型并评估其性能。
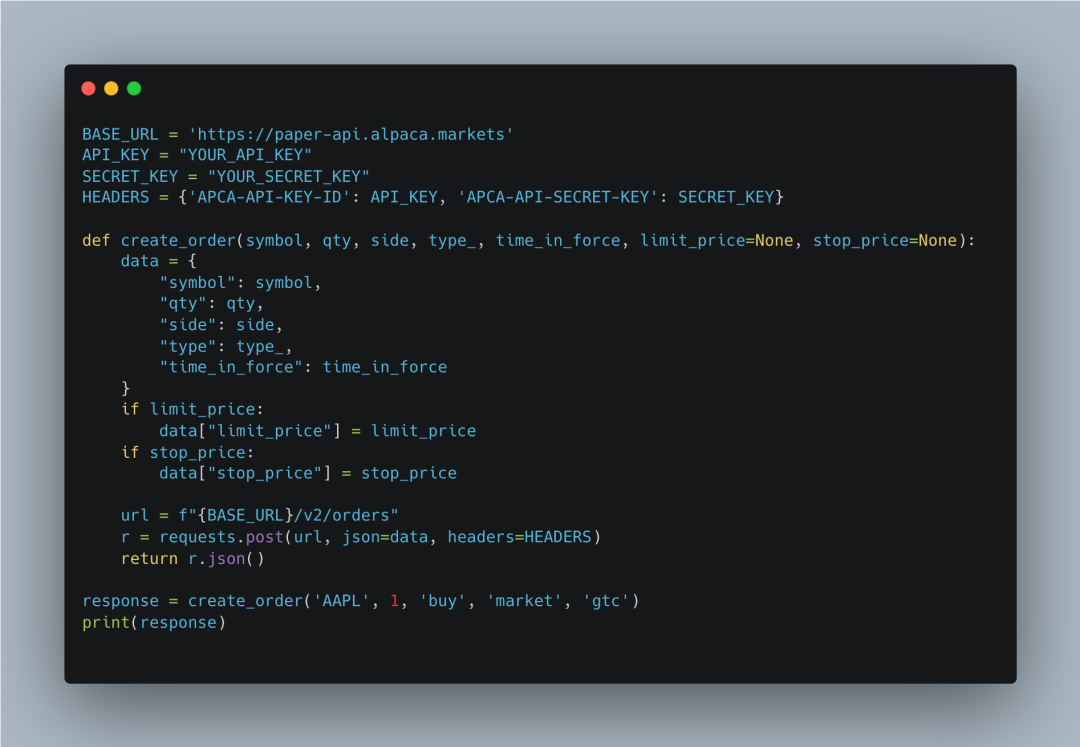
Alpaca API设置和订单创建函数
最后,我们通过Alpaca API进行自动交易。create_order函数接受订单参数,并发送POST请求到Alpaca API创建订单。示例中创建了一个买入1股苹果公司股票的市场订单。
总结
这段代码展示了如何使用LSTM模型进行股票价格预测,并通过Alpaca API实现自动化交易。代码的主要步骤包括数据准备、模型训练、模型评估和订单创建。希望这段代码能帮助你更好地理解量化交易的流程和技术细节。长按下方扫码加入宽客邦量化俱乐部,获取「本文完整源码」。

阿里云服务器双11活动专属特惠
错过今天,再等一年!
点击阅读原文可享「8.5折」首购优惠










