本文由曾鋆、海智、亚辉、孟莹四位作者共同创作完成。
随着海量请求、节假日峰值流量和与日俱增的系统复杂度出现的,很有可能是各种故障。在分析以往案例时我们发现,如果预案充分,即使出现故障,也能及时应对。它能最大程度降低故障的平均恢复时间(MTTR),进而让系统可用程度(SLA)维持在相对较高的水平,将故障损失保持在可控范围内。但是,经过对2016全年酒店后台研发组所有面向C端系统的线上事故分析后发现,在许多情况下,由于事故处理预案的缺失或者预案本身的不可靠,以及开发人员故障处理经验的缺失,造成大家在各种报警之中自乱了阵脚,从而贻误了最佳战机。
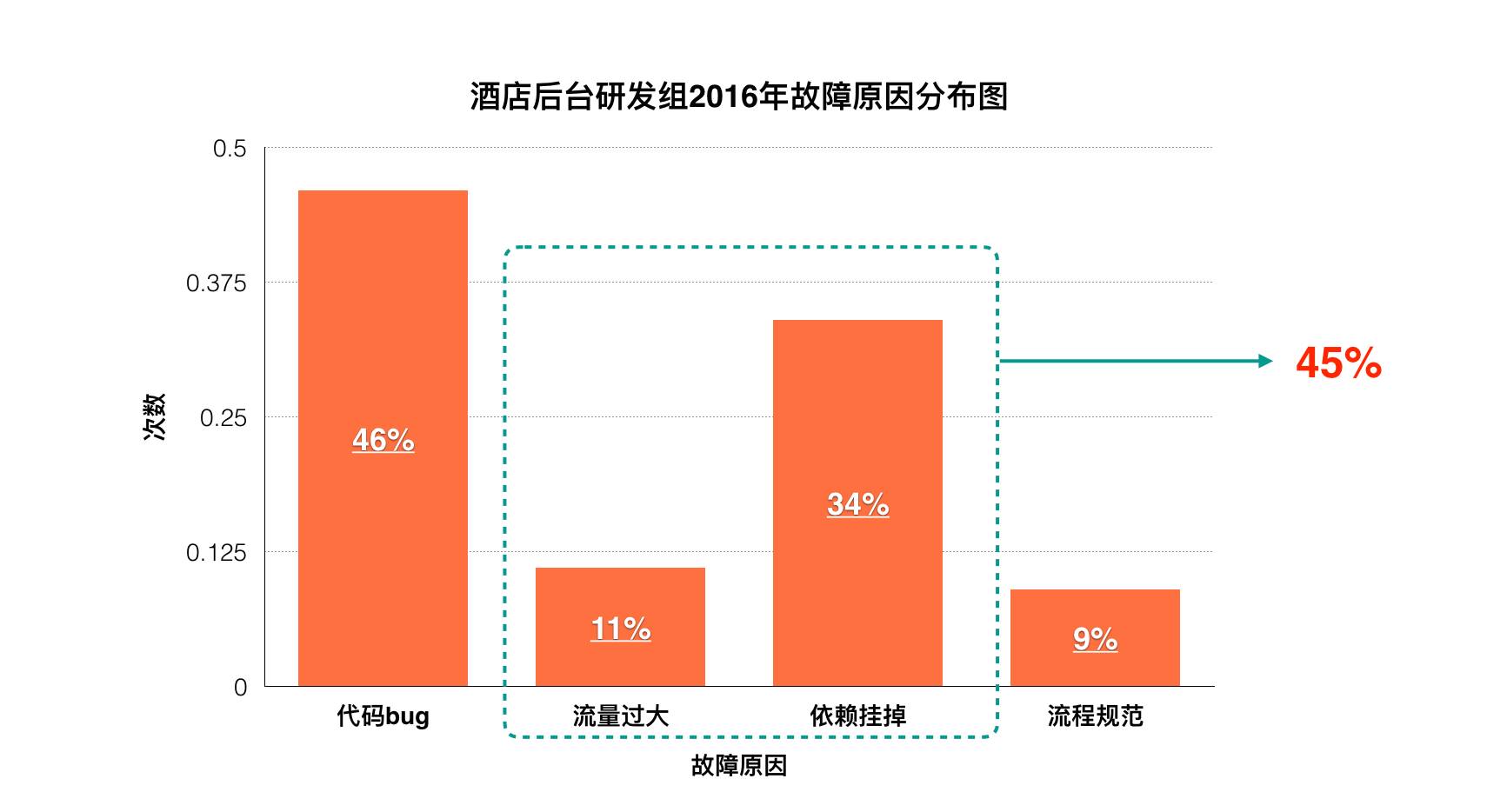
正如上面所讲,由“上游流量”和“依赖”导致的故障数量,占了全年故障的45%。
一个经典的case:
2016年3月10日,Tair集群因流量过大挂掉,导致酒店后台某组一个ID生成器的功能失效,无法获取ID,插入数据库失败。
值班同学找到相应的开发同学,执行之前的预案(切换到基于数据库的ID生成器),发现不能解决当前问题(有主键冲突)。
值班同学经过分析,临时修改数据库中的字段值,修复问题。
从上面的例子可以看出,业务方针对系统可能出现的异常情况,虽然一般设有预案,但是缺乏在大流量、有故障情况下的演练,所以往往在故障来临时,需要用一些临时手段来弥补预案的不足。
综上所述,我们要有一套常态化的“故障演练”机制与工具来反复验证,从而确保我们的服务能在正常情形下表现出正常的行为,在异常状况下,也要有正确、可控的表现。
这个服务或是工具能执行:
这样才能够做到在节假日与大促时心中有数,在提高系统服务能力的同时增加开发人员应对与处理故障的经验。
下面,以酒店后台switch研发组开发的“Faultdrill”系统为例,向大家介绍一下我们在这方面的经验。
在压力测试(以下简称“压测”)和故障演练方面,业界已有很多种实践。
压测
压测有单模块压测和全链路压测两种模式。
阿里双11、京东618和美团外卖都有过线上全链路压测的分享(美团外卖的分享参见美团点评技术沙龙第6期回顾)。
全链路压测有几点明显的优势:
但与此同时,全链路压测也有较高的实践成本:
需要有明显的波谷期;
需要清理压测数据,或者申请资源构建影子存储;
真实流量难构造,需要准备虚拟商家和虚拟用户;
需要有完备的监控报警系统。
酒店业务模式和外卖/购物类的业务模式不太一样。首先,没有明显的波峰波谷(夜里也是订房高峰期,你懂的),因为没有明显的波峰波谷,所以清理数据/影子表也会带来额外的影响。真实流量的构造也是一个老大难问题,需要准备N多的虚拟商家和虚拟用户。
所以酒店最早推的是单业务模块级别的压力测试和故障演练,大家先自扫门前雪。
美团点评内部的通信协议以Thrift为主,业界的相关压力测试工具也有很多:
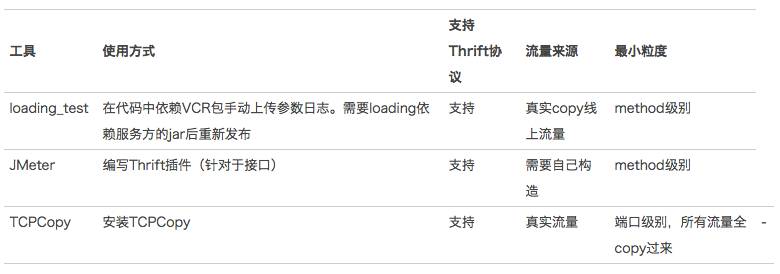
这几种方式都不满足我们的要求,我们的要求是:真实流量、method级别控制、操作简单。
所以我们准备自己造个轮子 :)
需求:业务方低成本接入,流量在集群级别(AppKey级别,AppKey相当于同样功能集群的唯一标识,比如订单搜索集群的AppKey为xx.xx.xx.order.search)以最低成本进行复制、分发,以及最重要的在这个过程中的安全可控等等都是对测试工具、框架的潜在要求。
基于以上,我们开发了流量复制分发服务。它的核心功能是对线上真实流量进行实时复制并按配置分发到指定的机器,来实现像异构数据迁移一样进行流量定制化的实时复制与迁移。
借助流量复制分发服务进行功能和系统级别的测试,以达到:
故障演练
如果要演练故障,首先要模拟故障(我们不可能真跑去机房把服务器炸了)。自动化的故障模拟系统业界已有实践,如Netflix的SimianAmy,阿里的MonkeyKing等。
美团点评内部也有类似的工具,casekiller等等。
SimianAmy和casekiller设计思路相仿,都是通过Linux的一些“tc”、“iptables”等工具,模拟制造网络延时、中断等故障。这些工具都是需要root权限才可以执行。美团点评的服务器都需要使用非root用户来启动进程,所以这种思路暂不可行。
这些工具都有一定要求,比如root权限,比如需要用Hystrix来包装一下外部依赖。比如我想制造一个表的慢查询、想制造Redis的某个操作网络异常,就有些麻烦。
所以我们准备自己造个轮子 :)
需求:业务方低成本接入,流量以最低成本进行故障的“制造”和“恢复”,无需发布、对代码无侵入就可以在后台界面上进行故障的场景配置、开启与停止。
基于以上,我们开发了故障演练系统。它是一个可以针对集群级别(AppKey级别)的所有机器,随意启停“故障”的故障演练平台。可以在无需root权限的前提下,构造任意method级别的延时或者异常类故障。
我们的设计思路是:
复制线上流量到影子集群。
通过对同样配置影子集群的压测,获得系统抗压极值。
制造针对外部接口/DB/Cache/MQ等方面的故障,在影子集群上测试降级方案、进行演练。
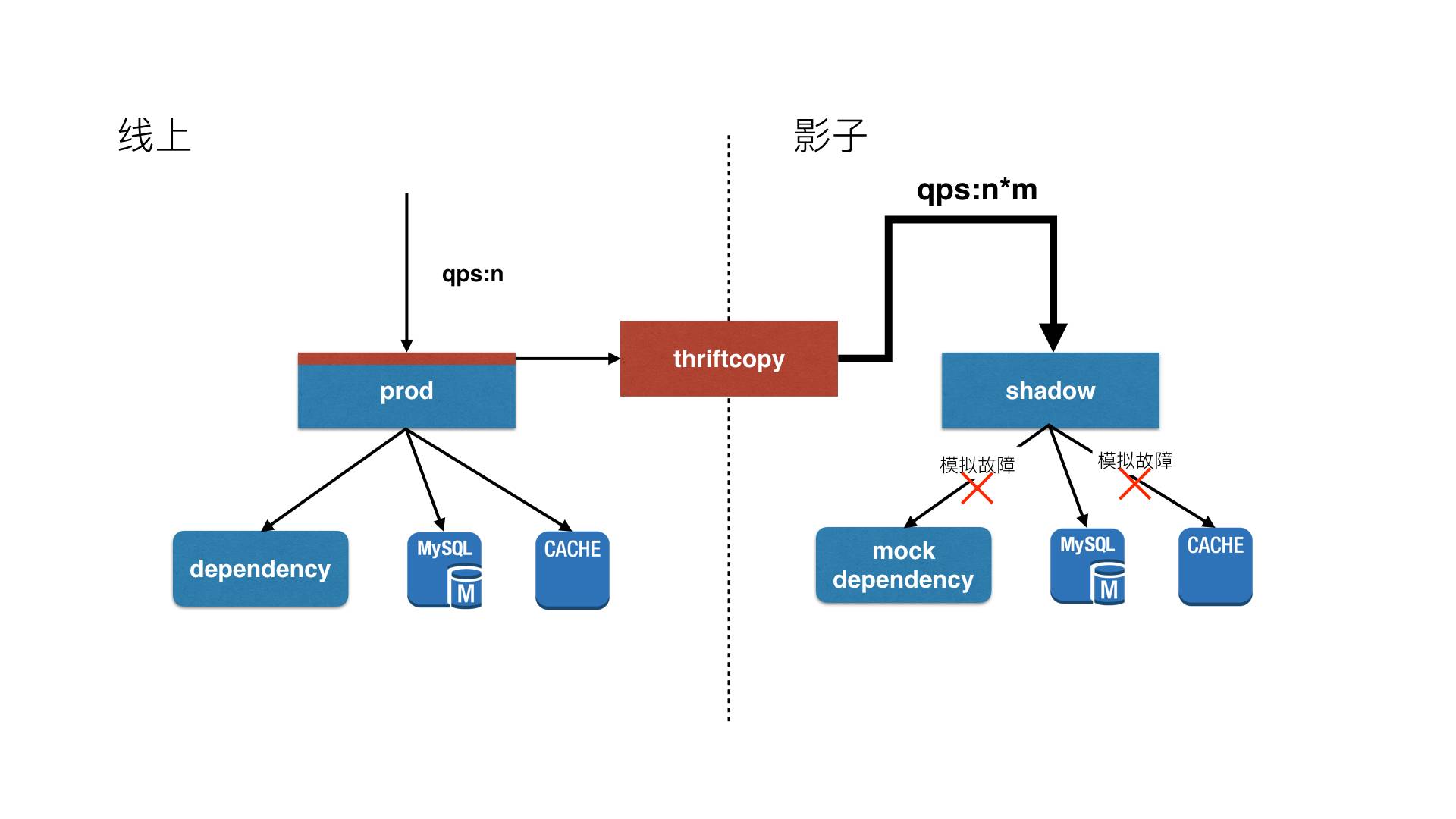
流量复制系统
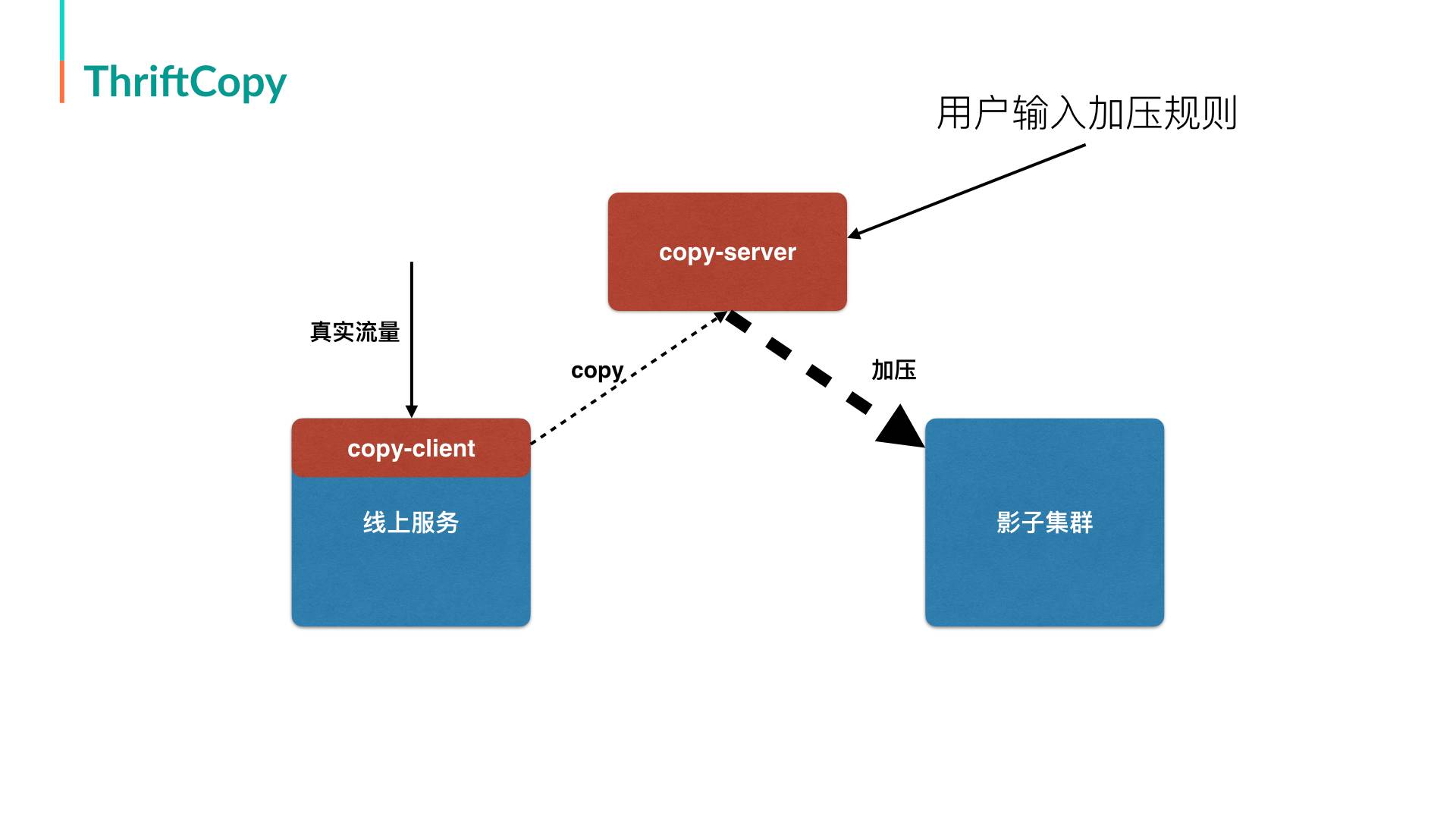
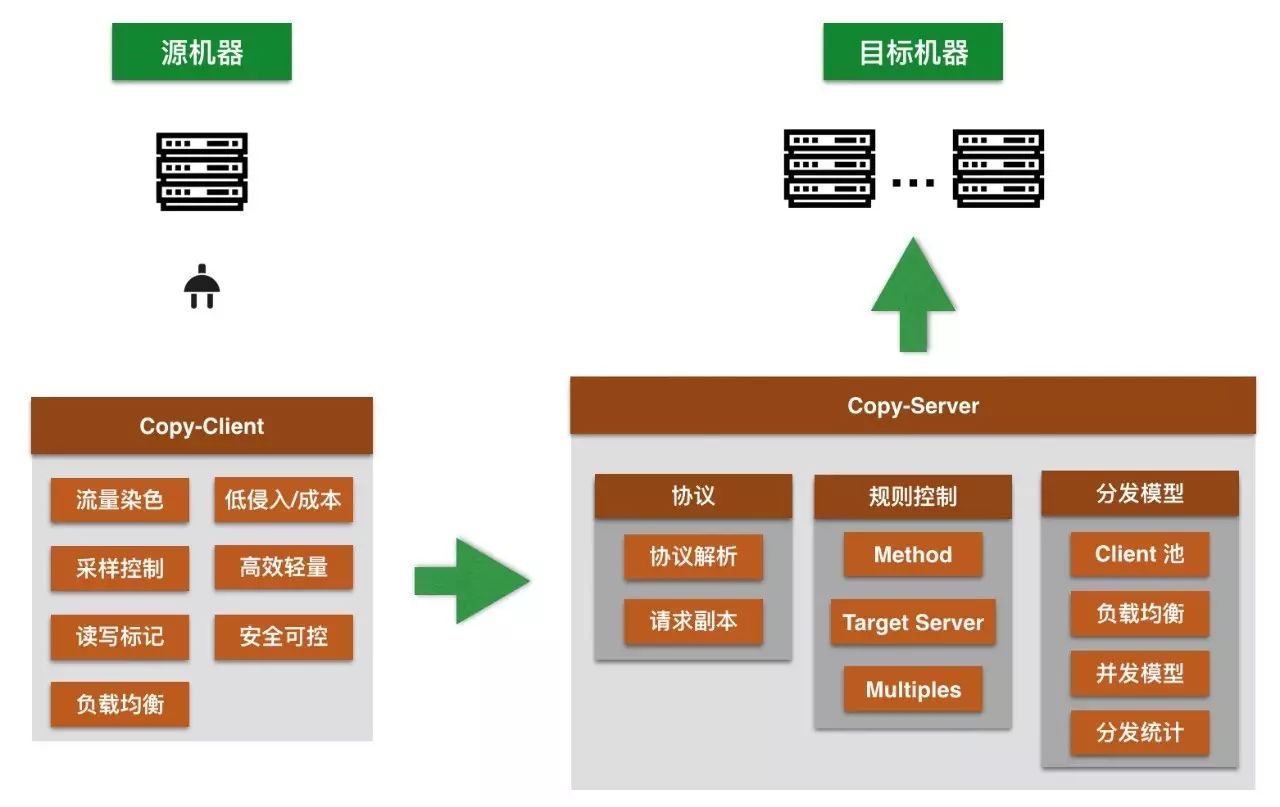
架构设计中参考了DubboCopy的系统设计,增加了一个SDK,解除了对TCPCopy的依赖。
形成以下的流程:
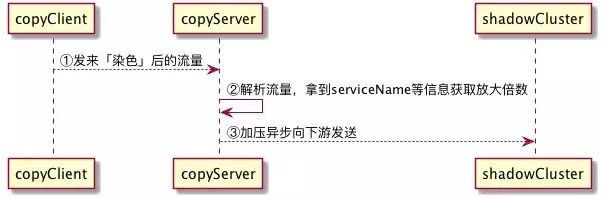
① 需要压测方先依赖我们的SDK包,在需要压测的具体实现方法上打上注解@Copy,并注明采样率simplingRate(默认采样率为100%)。
@Copy(attribute = CopyMethodAttribute.READ_METHOD, simplingRate = 1.0f)
public Result toCopiedMethod() {
}
② 正式流量来时,异步将流量发往copy-server。
③ copy-server根据流量中的信息(interface、method、serverAppKey)来获取压测配置(影子集群的AppKey,需要放大几倍)。
④ 根据压测配置,对影子集群按照放大倍数开始发包。
协议分析
Thrift原生协议情况下,如果你没有IDL(或者注解式的定义),你根本无法知道这条消息的长度是多少,自然做不到在没有IDL的情况下,对报文进行解析转发。感谢基础组件同学做的统一协议方面的努力,让ThriftCopy这个事情有了可行性 :)
除了公网RPC接口使用HTTP协议以外,美团点评内部RPC协议都统一为一种兼容原生Thrift协议的“统一协议”。
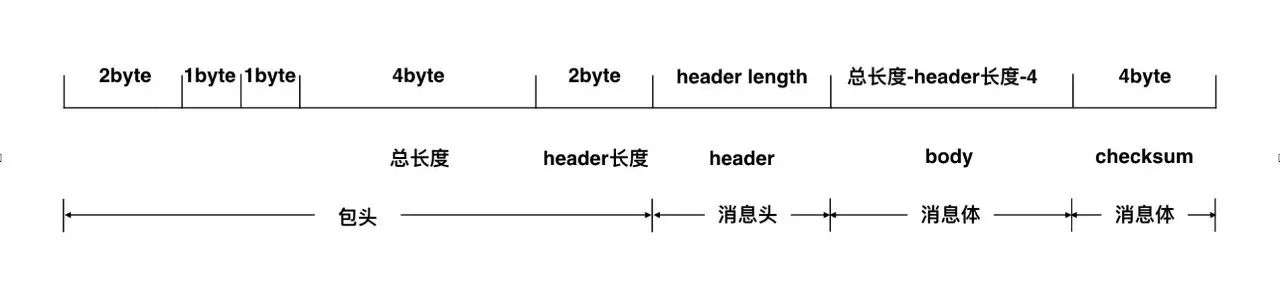
total length指定其后消息的总长度,包含2B的header length+消息头的长度+消息体的长度+可能的4B的校验码的长度。header length指定其后消息头的长度。
header里的内容有TraceInfo和RequestInfo等信息,里面有clientAppKey、interfaceName、methodName等我们需要的信息。
client功能
应用启动时
客户端启动时,首先获取copyServer的IP list(异步起定时任务不断刷新这些IP列表)。
建立相应的连接池。
初始化对@Copy做切面的AOP类。
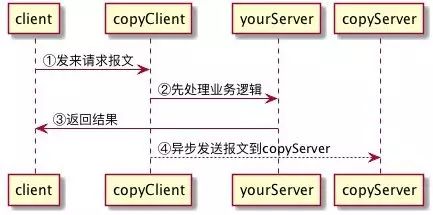
RPC请求到来时
命中切面,先同步处理业务逻辑。
异步处理下面的逻辑:
以上,便可进行流量的复制与分发,在服务设计上,Client端尽量做到轻量高效,对接入方的影响最小,接入成本低,并且在整个流量复制的过程中安全可控。另外,在Client,当前针对美团点评使用的Thrift协议,进行:
流量染色。对原请求在协议层重写染色其中的clientAppKey和requestMethodName,分别重写为""和"${rawMethodName}_copy"在请求接收方可以调用特定方法即可判断请求是否是由“流量复制分发服务”的转发请求。
读写标记。通过在注解上attribute属性标记转发接口为读还是写接口,为后续的流量分发做好准备。
负载均衡。支持服务端的横向扩展。
采样控制。对流量复制/采样进行控制,最大限度的定制复制行为。
server功能
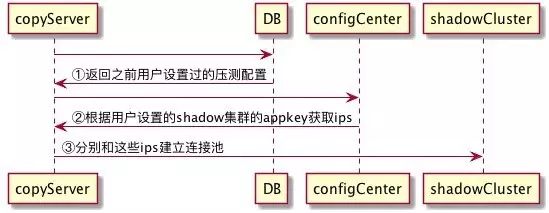
应用启动时
读取数据中存住的压测配置(fromAppKey、targetAppKey、放大倍数)。
根据targetAppKeys去分别获取IP list(异步起定时任务不断刷新这些IP列表)。
建立相应的连接池。
流量到来时
根据“统一通信协议”解包,获取fromAppKey、interfaceName、methodName等我们要的信息。
异步处理下面的逻辑:
故障演练系统
我们的需求是,可以集群级别(AppKey级别)而不是单机级别轻松的模拟故障。
模拟什么样的故障呢?

我们调研了很多种实现方式:

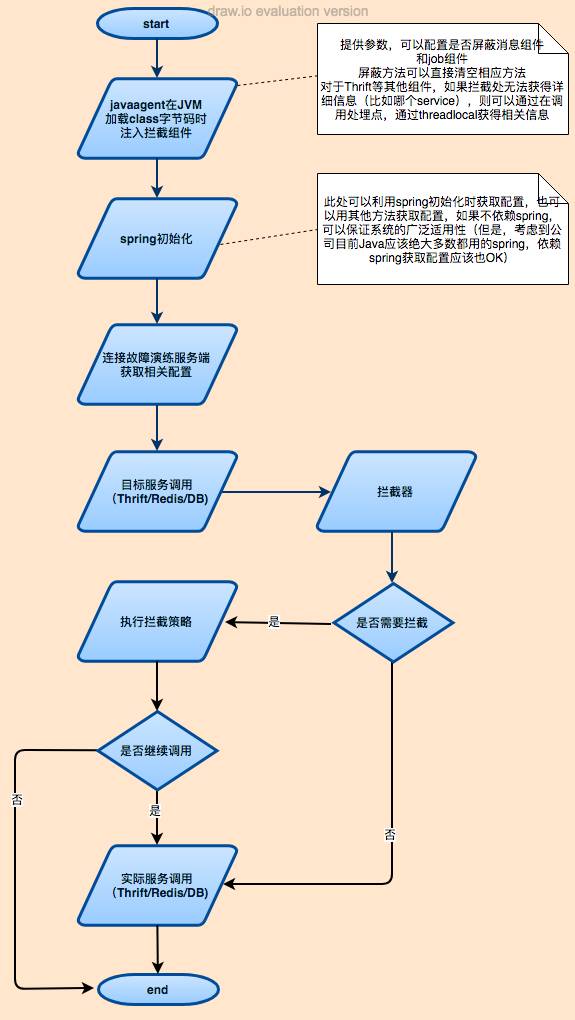
经过调研对比,选定了基于javaagent进行字节码注入,来实现对个目标对象的拦截并注入演练逻辑。
client功能
应用启动时
需要修改启动时的JVM参数-javaagent:WEB-INF/lib/hotel-switch-faultdrill-agent-1.0.2.jar

加载client包,对RedisDefaultClient、MapperRegistry、DefaultConsumerProcessor、DefaultProducerProcessor、MTThriftMethodInterceptor、ThriftClientProxy等类进行改造。
从远程获取设定好的相应的script,比如“java.lang.Thread.sleep(2000L);”比如“throw new org.apache.thrift.TException("rpc error");”(会有异步任务定时更新script列表)。
根据script的AppKey和faultType,生成一个md值,做为key。
根据script的文本内容,动态生成一个类,再动态生成一个method(固定名称为invoke),把script的内容insertBefore进来。然后实例化一个对象,做为value。
将上面的key和value放入一个Map。
目标类(比如RedisDefaultClient)的特定method执行之前,先执行map里对应的object中的invoke方法。
方法执行时
执行之前查找当前的策略(map中的对应object),如果没有就跳过。
如果有就先执行object中的invoke方法。起到“java.lang.Thread.sleep(2000L);”比如“throw new org.apache.thrift.TException("rpc error");”等作用。
server的功能
server的功能就比较简单了,主要是存储用户的设置,以及提供给用户操作故障启停的界面。

举个例子

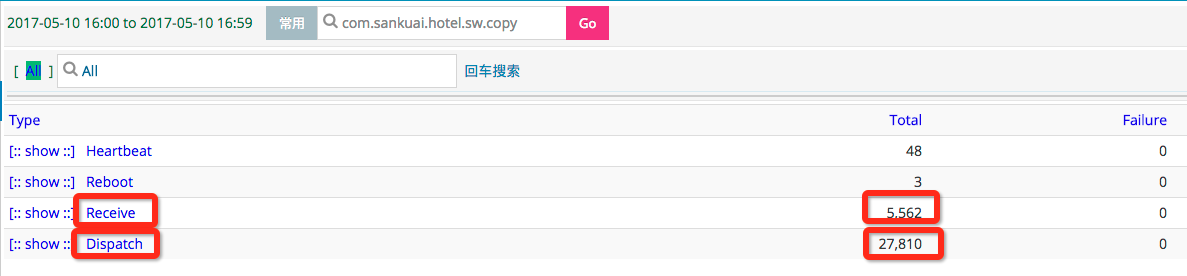
本机单测调用beta03集群上的服务接口distributeGoodsService.queryPrepayList 5000次。

在目标集群beta04上收到此接口的25000次转发过来的请求。

多次请求,观察CAT(美团点评开发的开源监控系统,参考之前的博客)报表,其中Receive为接收到的需要转发的次数,Dispatch为实际转发数量。
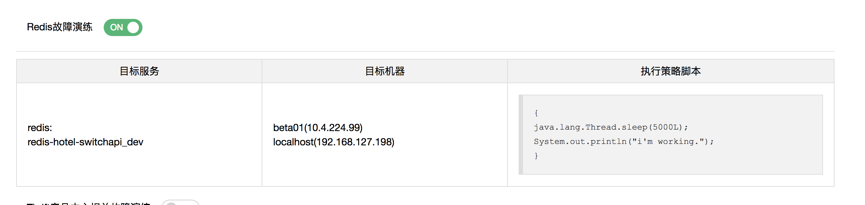
开始模拟故障:Redis故障、MTThrift故障。
请求接口:控货的filter接口(访问缓存),故障前、后响应时间对比图:
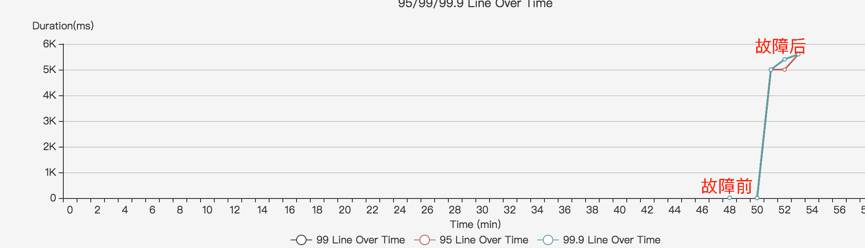
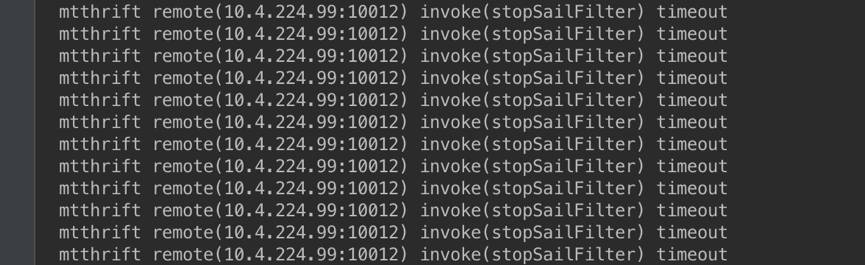
客户端设置超时1s,接收到请求都超。
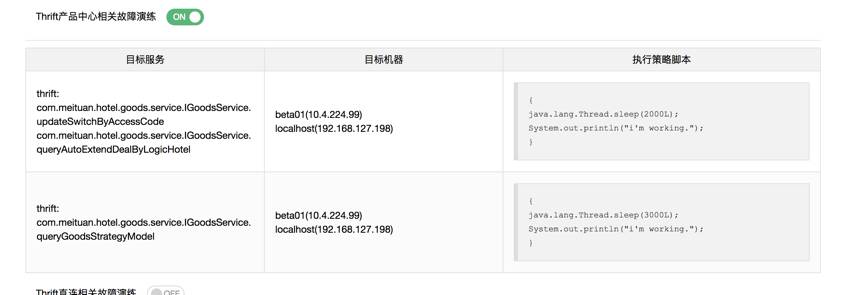
开启Thrift接口故障演练,接口:com.meituan.hotel.goods.service.IGoodsService.queryGoodsStrategyModel,延时3s,设置接口超时6s。
故障前后响应时间对比:
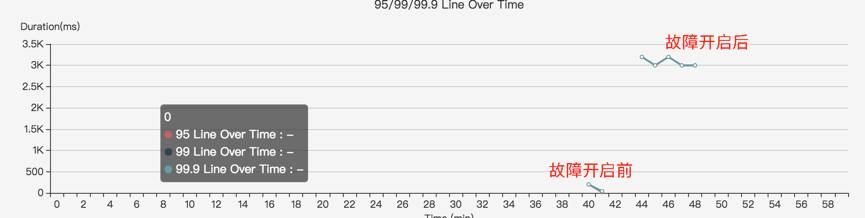
这样就完成了一次加压情况下的故障演练过程,随后就可以让团队成员按照既定预案,针对故障进行降级、切换等操作,观察效果。定期演练,缩短操作时间,降低系统不可用时间。
“故障演练系统”目前具备了流量复制和故障演练两方面的功能。希望能通过这个系统,对酒店后台的几个关节模块进行压测和演练,提高整体的可用性,为消费者、商家做好服务。
后续“故障演练系统”还会继续迭代,比如把忙时流量存起来,等闲时再回放;还有如何收集response流量,进而把抽样的request和response和每天的daily build结合起来;如何在故障演练系统中,模拟更多更复杂的故障等等。还会有更多的课题等待我们去攻克,希望感兴趣的同学可以一起参与进来,和我们共同把系统做得更好。
分布式会话跟踪系统架构设计与实践,美团点评技术博客.
基于TCPCopy的Dubbo服务引流工具-DubboCopy.
从0到1构建美团压测工具,美团点评技术博客.
javassit.
曾鋆,2013年加入美团点评,就职于美团点评酒旅事业群技术研发部酒店后台研发组,之前曾在人人网、爱立信、摩托罗拉工作过。
海智,2015年校招加入美团点评,就职于美团点评酒旅事业群技术研发部酒店后台研发组。
亚辉,2015年加入美团点评,就职于美团点评酒旅事业群技术研发部酒店后台研发组。
孟莹,2014年校招加入美团点评,就职于美团点评酒旅事业群技术研发部酒店后台研发组。
最后发个广告,美团点评酒旅事业群技术研发部酒店后台研发组长期招聘Java后台、架构方面的人才,有兴趣的同学可以发送简历到[email protected]。
查看文章原网址可点击“阅读原文”。
更多技术博客:美团点评技术博客。
PS:正文中标绿的名词均为参考链接,可点击查询。









