来源: DeepMind & OpenAI
编译:刘小芹
【新智元导读】DeepMind 和 OpenAI 合作的新研究,让没有技术经验的人类给强化学习系统提供反馈,从而避免事先为系统指定目标的步骤。在某些情况下,这种方法只需要30分钟的反馈就足以训练系统,包括教会系统一个全新的、复杂的行为,例如使模拟机器人做后空翻。
下载论文:https://arxiv.org/abs/1706.03741

我们相信,人工智能将是最重要、最广泛有益的科学进步之一,人工智能帮助人类应对了一些最大的挑战,例如应对气候变化,提供先进医疗,等等。但是,为了让AI实现它的效用,我们知道技术必须建立在负责任的基础之上,我们也必须考虑所有潜在的挑战和风险。
这就是为什么 DeepMind 作为共同创立者发起了一些机构,例如AI联盟(Partnership on AI),旨在惠及人类和社会;以及为什么我们拥有一个致力于AI安全(AI Safety)的团队。这一领域的研究需要开放、协作,以确保尽可能广泛地采取最佳的实践,这也是我们为什么与OpenAI合作开展AI安全技术研究的原因。
这个领域的一个核心问题是:我们如何允许人类去告诉系统我们希望它做什么,以及更重要的是,我们不希望它做什么。随着我们利用机器学习处理的问题越来越复杂,以及这些技术在现实世界中得到应用,这个问题变得越来越重要。
DeepMind 和 OpenAI 合作的第一个结果证明了一种解决这个问题的方法:让没有技术经验的人类来教给强化学习(RL)系统一个复杂目标。强化学习是通过反复的试验和试错学习的系统。这就消除了让人类事先为算法指定一个目标的需要。这是一个重要的步骤,因为假如目标就算只出了一点点差错也可能导致不良、甚至危险的行为。在某些情况下,只需要30分钟的来自非专家的反馈就足以训练我们的系统,包括教会系统一个全新的、复杂的行为,例如使模拟机器人做后空翻。

大约用了900条来自人类的反馈来教这个算法做后空翻
我们在新论文《利用人类偏好的深度强化学习》(Deep Reinforcement Learning from Human Preferences)描述了这个系统,它与经典的RL系统不同,经典的RL系统使用被作为“激励预测器”(reward predictor)的神经网络训练智能体,而不是在智能体探索环境时收集的激励。

在这里下载论文:https://arxiv.org/pdf/1706.03741.pdf
它包括3个并行运行的进程:
一个强化学习智能体探索它所处的环境(例如在Atari游戏中)并进行交互;
定期地,该智能体所做行为的1~2秒的两个剪辑片段被发送给人类控制员,人类控制员需要在二者中选择一个最能实现预期目标的行为;
人类的选择被用于训练激励预测器,该预测器反过来又用于训练智能体。随着时间的推移,智能体学习最大限度地提高从预测器得到的奖励,并根据人类的偏好改进自己的行为。
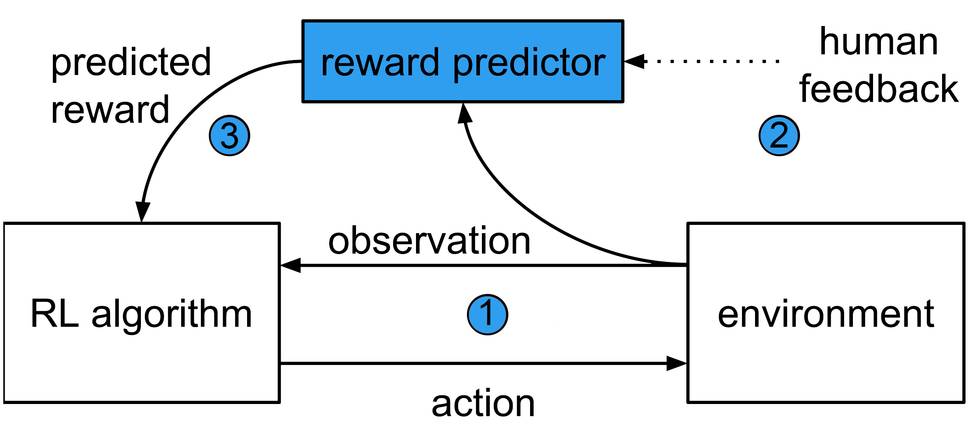
系统将学习目标与学习行为分开来实现
这种迭代学习的方法意味着人类可以发现和纠正智能体的任何不想要的行为,这是所有安全系统的关键部分。这样的设计也不会给人类控制员带来沉重的工作负担,他们只需要检查智能体的大约0.1%的行为,就能令其做他们希望的行为。但是,这仍然意味着要检查几百上千个剪辑片段,假如应用到现实世界的问题上,这个工作量是需要减少的。
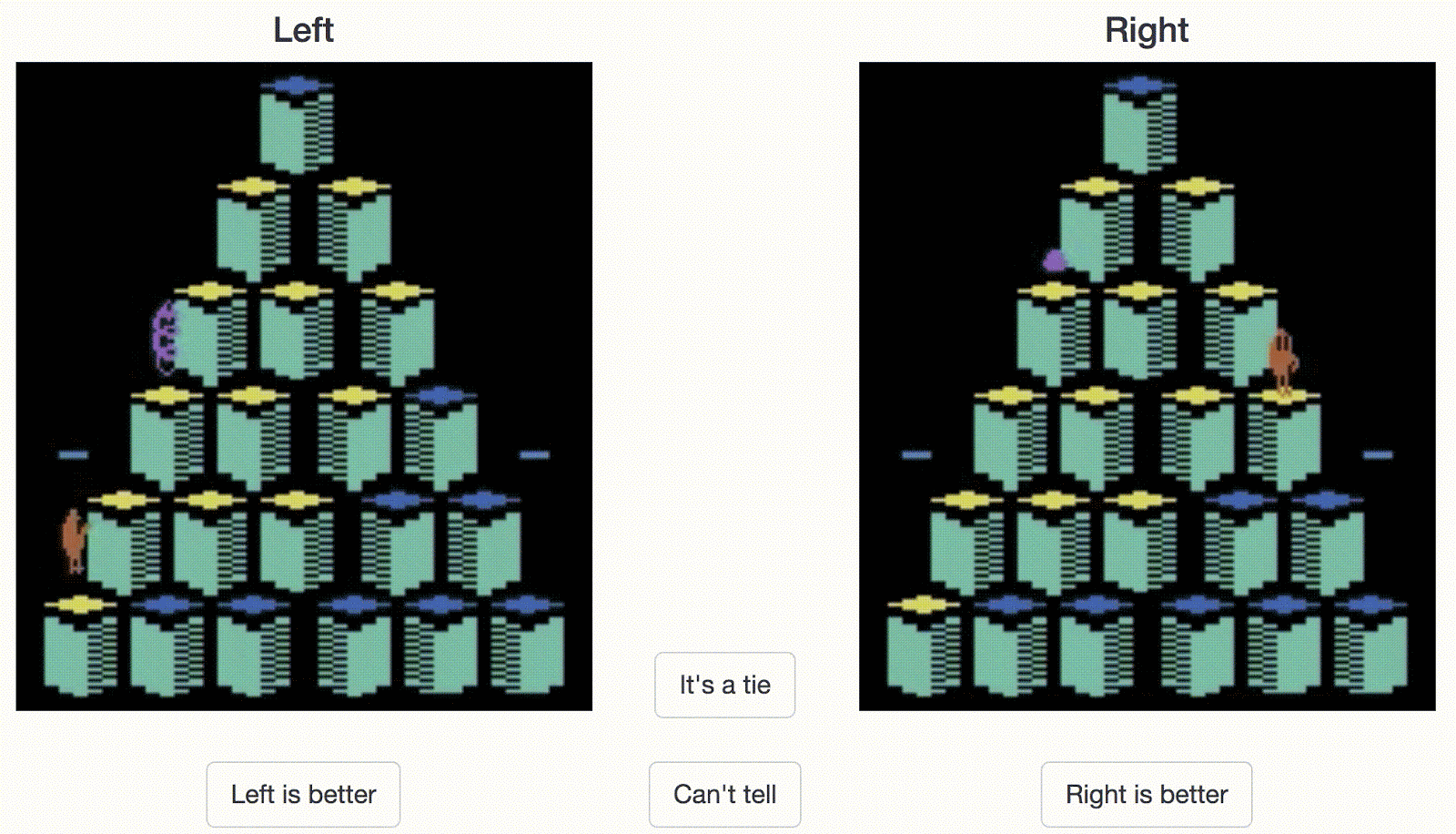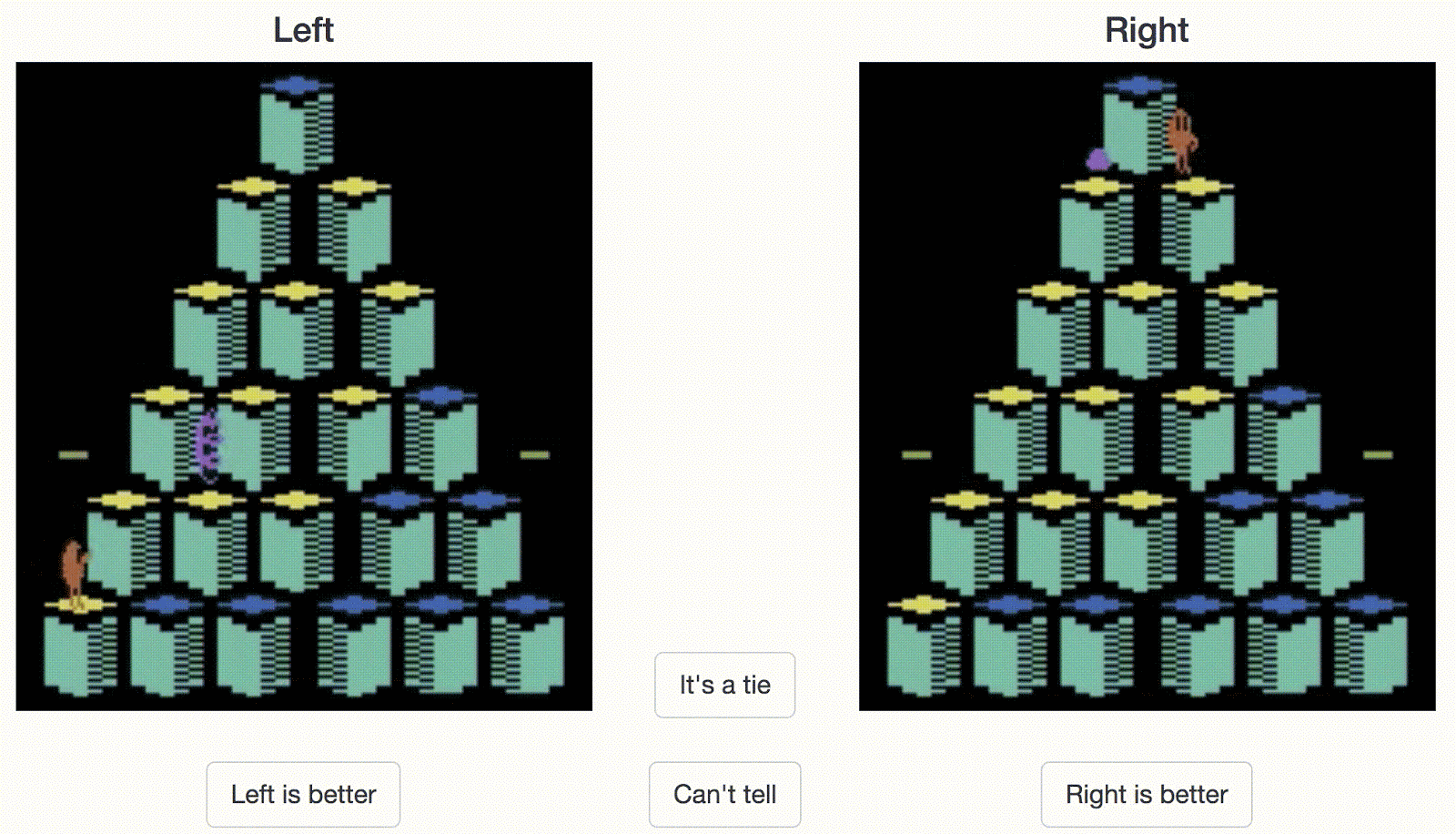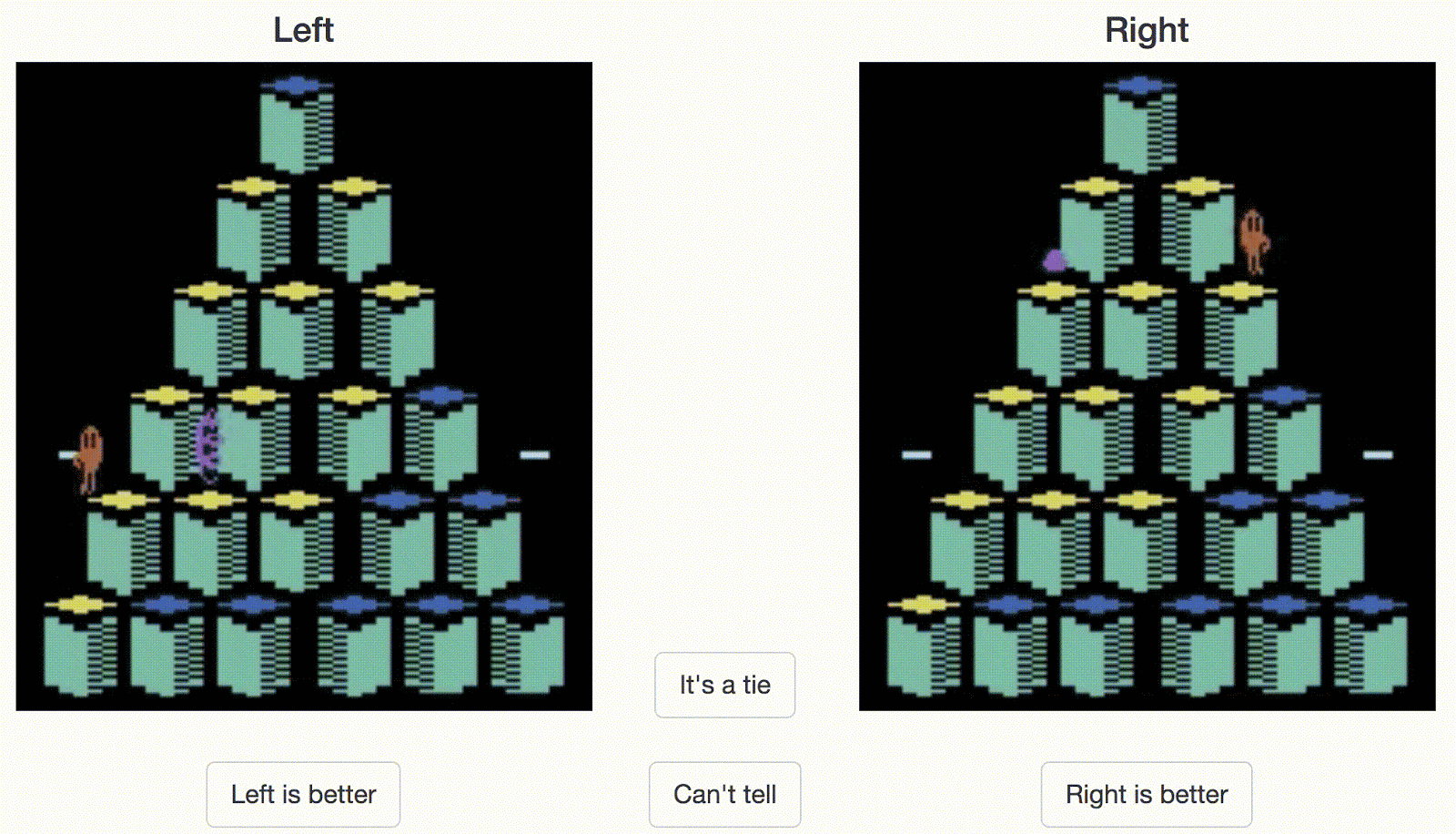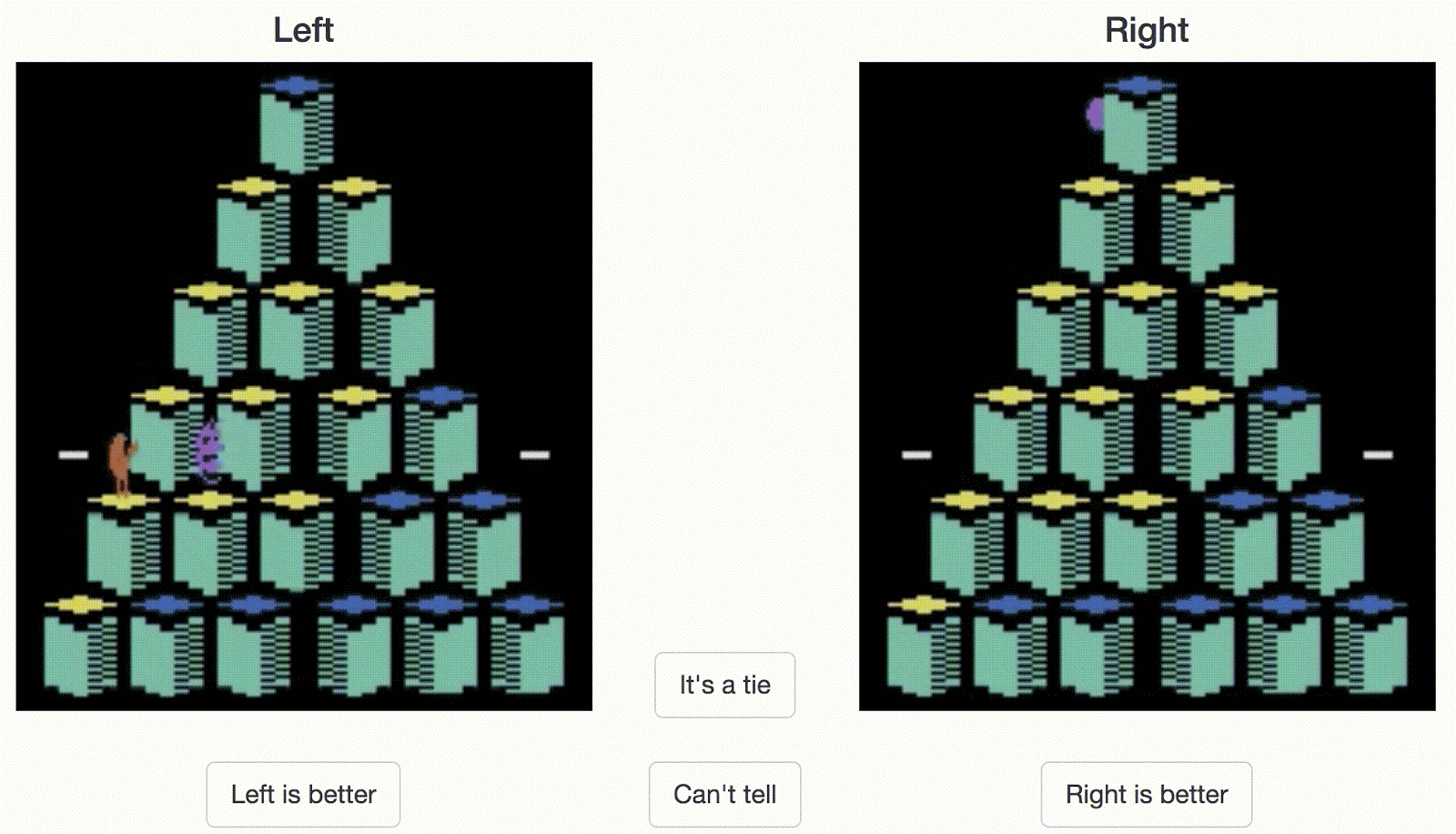
人类控制员必须在两个剪辑片段之间选一个。在这个例子中,对于Atari游戏Qbert而言,右边的剪辑看起来是更好的行为(得分更高)
在Atari的Enduro游戏,要驾驶一辆汽车并超其他车,这很难通过传统的RL网络的试验和试错方法学习,加入人类反馈的方法最终使我们的系统实现了超过人类的结果。在其他游戏和模拟机器人的任务中,我们的方法与标准的RL设置表现相当,但在Qbert和Breakout等几个游戏中,我们的方法根本不工作。
但是,这样一个系统的最终目标是即使智能体不在环境中的情况下,也能允许人类来为智能体指定一个目标。为了测试,我们教智能体各种各样的新行为,例如令它进行后空翻,单腿走路或在Enduro游戏中学习与另一辆车并排行驶,而不是为了得分去超车。

Enduro的正常目标是尽可能多地超车。但是在我们的系统中,我们可以训练智能体实现不同的目标,比如与其他车辆并行。
虽然这些测试得到了一些积极的结果,但其他测试显示出其局限性。尤其是,如果在训练初期停止人类的反馈,我们的设置很容易被奖励黑掉。在这种情况下,智能体继续探索所处环境,这意味着激励预测器被迫在没有反馈的情况继续预测奖励。 这可能会导致过高的奖励,从而令智能体学习了错误的行为——往往是奇怪的行为。下面的视频是一个例子,智能体发现,来回击球是相比应分或失分更好的策略。

智能体的奖励功能黑了,它决定来回击球优于赢分或失分
了解这些缺陷对于确保我们避免故障,并构建按照预期行为的AI系统至关重要。
为了测试和增强这个系统,我们还有更多的工作要做。但是这个系统已经显示了在创建可以由非专家用户使用的系统的许多关键的第一步,它们所需的反馈量十分少,而且可以扩展到各种各样的问题。
其他的探索领域可以是减少所需人类反馈的量,或使人类能够通过自然语言界面提供反馈。这将标志着创建一个可以轻松学习人类行为复杂性的系统的显著进步,也是创造与人类全面合作的AI的关键一步。
这项研究是 DeepMind 的 Jan Leike,Miljan Martic,Shane Legg 和 OpenAI 的 Paul Christiano,Dario Amodei 以及 Tom Brown 持续合作的一部分。
在 OpenAI 的 gym 复制后空翻实验,使用如下奖励函数:

DeepMind博客介绍:https://deepmind.com/blog/learning-through-human-feedback/
OpenAI博客介绍:https://blog.openai.com/deep-reinforcement-learning-from-human-preferences/











