
据 DT 君从现场发来消息,就在刚刚,谷歌携手中国围棋协会和浙江省体育局在位于北京的中国棋院就“中国乌镇 · 围棋峰会”召开了新闻发布会。据发布会宣布,此次围棋峰会将于 5 月 22 到 27 日在中国桐乡乌镇举行,5月22日是活动报道日。而其中最为人关注的是,在开赛的前三天中 AlphaGo 与柯洁之间的三番棋对弈。

柯洁致辞:抱有必胜的心态和必死的信念
据发布会现场提供的材料,在比赛的后两天,峰会还将举办配对赛和团队赛两场形式各异的交流比赛。在配对赛中,两位棋手将分别与 AlphaGo 组队,挑战棋手如何理解AlphaGo独特风格并与之合作;在团体赛中,将由五位中国顶尖棋手合作,建立棋手“神经网络”,降低心里因素的影响,从而做出更加客观的判断。

谷歌大中华区总裁石博盟致辞
据悉,此次参战的 AlphaGo 2.0 可能采用了全新的算法模型,即未先学习人类棋谱再下棋的经验,而是直接通过对战来获得认知和能力。这与此前被“喂”了无数份人类棋谱的 AlphaGo 1.0 完全不同。

DeepMind 创始人戴密斯·哈萨比斯视频致辞
根据发布会提供的材料,AlphaGo的做法是使用了蒙特卡洛树搜索与评估网络(Value Network)和走棋网络(Policy Network)两个深度神经网络相结合的方法,其中一个是以估值网络来评估大量的选点,而以走棋网络来选择落子。在这种设计下,电脑可以结合树状图的长远推断,又可像人类的大脑一样自发学习进行直觉训练,以提高下棋实力。

DeepMind创始人哈萨比斯刚刚发推文表示对乌镇对决充满期待
但现在的 AlphaGo 2.0 到底进化成什么样,恐怕只有比赛开始后才能一探究竟了。
2016 年 3 月,AlphaGo 1.0 在围棋人机大战中“一战成名”,以 4:1 的成绩打败韩国名将李世石九段——这场胜利甚至可以说是开启了人工智能走向大众的新认知时代。

事后,李世石这样描述他与 AlphaGo 1.0 对战的感觉:“面对毫无感情的对手是非常难受的,这让我有种再也不想跟它比赛的感觉” 。
值得一提的是,李世石当时还不知道谷歌为这一胜利准备了一个秘密武器——一种专属的机器学习处理器“张量处理单元”(Tensor Processing Unit, TPU)。在当时的比赛中,TPU 帮助 AlphaGo 1.0 更快地 “思考”、更好地预判局势。
在 2016 年 5 月份,谷歌首次证实了“TPU”的存在,但并没有披露相关的技术细节,外界只知道在谷歌街景、AlphaGo 等应用中用到了TPU。谷歌自己就称,在 AlphaGo 战胜李世石的比赛中,AlphaGo 能够做出更快更准的判断,大部分功劳要归于TPU。
根据谷歌就在近日发布的论文显示,在功耗效率测试中,TPU目前的性能要优于常规的处理器 30 到 80 倍;而同传统的GPU / CPU的计算组合相比 ,TPU的处理速度也要快上15 到 30 倍。最为关键的是,由于TPU的运用,就连深度神经网络所需要的代码数量也大幅的减少,仅仅需要 100 到 1500 行代码就可以顺畅运行。
谷歌关于此次活动的宣传视频
DeepMind 创始人戴密斯·哈萨比斯今年 1 月 17 日出席 DLD(数字、生活、设计)创新大会上说:“AlphaGo 为谷歌公司节省了大量的电力消耗。谷歌数据中心每天的用电量惊人,我们就通过 AlphaGo 的算法合理配置冷却装置。结果用于冷却装置的能源消耗减少 40%,从而使整个数据中心的总电力消耗减少了 15%。”
可以想象,即便没有被“喂棋谱”,如此强大配置之下的 AlphaGo 2.0 有可能将是柯洁难以超越的对手。

实际上,就在 2017 年年初,AlphaGo 化名为 Master 横扫棋坛,以 60 比 0 大胜中日韩围棋高手,其中包括聂卫平、柯洁(是的,柯洁已经输过一次了)、朴廷桓、井山裕太等。对于 Master 的路数,有棋手表示 “看不懂”,几乎每一盘棋Master都有让职业高手找不到北的走法。
这在当时引起了不少人的困惑。AlphaGo1.0 的风格趋于保守,偏向于选择那些最终赢棋概率较大,但所赢目数较少的棋步,而 Master 的“棋风”大变,原因何在?

谷歌 DeepMind 公司创始人戴密斯·哈萨比斯(如上图)曾在一次采访中透露,他们正在尝试训练一个没有学习过人类棋谱的人工智能。或许 Master 正是 AlphaGo1.0 和 2.0 之间的过渡产品,也或许 Master 正是 AlphaGo2.0 本身。
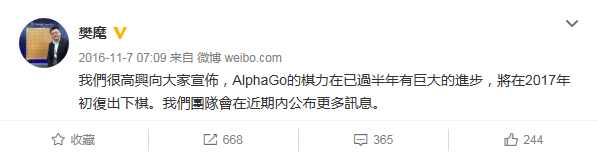
2016 年 11 月的时候,AlphaGo 团队的发言人樊麾通过微博宣布:“我们很高兴向大家宣布,AlphaGo 的棋力在已过半年有巨大的进步,将在2017年初复出下棋,我们团队会在近期内公布更多讯息” ——这个“巨大进步”耐人寻味。
据 DeepMind 介绍, AlphaGo 1.0 是“深度学习”人类棋谱得出围棋手数的估值,但 1.0 版本的 AlphaGo 所走招法其实并没有超出人类理解范围,而且也是人类棋手用过的方法。
但是,如果 AlphaGo 1.0 完善了,就意味着得出了接近完美的围棋手数估值函数,而 AlphaGo 2.0 则是利用这个估值函数进行自我对局和“深度学习”,不再受人类棋谱的局限,下出真正属于“人工智能”的围棋。

那么这次与柯洁之间的新战役,是否意味着 AlphaGo1.0 就这么退出历史舞台了呢?
2016 年,AlphaGo1.0 战胜李世石之后,谷歌在《Nature》上公布了其详细的研究结果。2017 年 4 月 2 日,马化腾在中国 IT 领袖峰会上公开表示他对谷歌此举的感激之情,因为腾讯的围棋AI“绝艺”不久前在日本 UEC 比赛中获得冠军。
“如果没有 Google 的 paper(论文),我们也做不出来”,马化腾表示。
据报道,除了绝艺之外,日本的 DeepZenGo、比利时的“丽拉”等围棋 AI 新秀,都受到了 2016 年谷歌在《自然》杂志上发表的关于 AlphaGo 论文启发。可以说,当年公布的 AlphaGo 1.0 研究结果还在“哺育”着整个围棋人工智能领域。
去年年底,Google 宣布将 DeepMind 源代码进行开源,上传到 Github 上。Google 希望,以此增加 AI 能力的开放性,让更多开发者参与 AI 研究,观察其他开发者是否能够挑战并打破 DeepMind 现在的纪录。
而就在近日,DeepMind 宣布已经开源了最新的深度学习框架 Sonnet,将被用于与 TensorFlow 进行协同工作,开发者从此能够更方便、直接地构建复杂神经网络模型。

不久前,DeepMind 创始人戴密斯·哈萨比斯曾表示:“2017年将是 AlphaGo 与棋界兴奋的一年”。这一次,他们又会带来什么样的惊喜?
凑巧的是,马云在 4 月 2 日的中国IT领袖峰会上对AlphaGo “隔空喊话”:“AlphaGo 赢了李世石,so what?下围棋本来的乐趣就是对方下一把臭棋,结果机器不会下臭棋,那还有什么事情呢?”
或许,我们也可以期待 AlphaGo 在这次 PK 中能下一把令人称绝的臭棋。但如果你希望能去围观,可以着手准备去乌镇了,据说当地客房已经很紧张了。

MIT Technology Review 中国唯一版权合作方,任何机构及个人未经许可,不得擅自转载及翻译。
分享至朋友圈才是义举

一个魔性的科幻号,据说他们都关注了










