

原作者 Walker Harrison
编译 CDA 编译团队
本文为 CDA 数据分析师原创作品,转载需授权
前言
国外习惯用 Google 进行搜索,可以毫不夸张的说
Google
已经彻底地融入了日常生活。如今人们一有什么问题都习惯谷歌一下,敲敲键盘,你就能找到想要的答案。
与此同时,你的 Google 搜索记录也反映了某段时间你的心态,好奇心,追求甚至是担忧。如果你已注册了 Google 帐户(通常是 Gmail ),根据你对隐私项的设置, Google 能够记录并提供你的搜索历史。下面我将告诉大家
如何获取和分析你的 Google 搜索记录,
以及进行数据可视化。

1. 下载数据
首先进入:https://takeout.google.com/settings/takeout,在这里你可以找到各种个人数据集,包括你的 GChat 对话和电子邮件。 取消全选(“全不选”),然后选择“搜索”并点击“下一步”。在下一页,选择文件类型(.tgz )和传递方式。 (我选择通过邮件发送的下载链接)。打开该电子邮件后,点击,下载存档并解压缩,你将得到文件夹“ Takeout ”和“ Searches ”中的一些文件。
2. 准备数据
数据是 JSON 格式,这种格式比较规整,可以通过通过 Python 变成向量:
import json
import os
import datetime
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from collections import Counter
files= os.listdir('Searches')
del files[0]
searches = []
dates = []
for file in files:
with open('Searches/%s'%(file)) as json_data:
d = json.load(json_data)
for i in range(len(d['event'])):
for j in range(len((d['event'][i][u'query'][u'id']))):
searches.append(d['event'][i][u'query'][u'query_text'])
dates.append(d['event'][i][u'query'][u'id'][j][u'timestamp_usec'])
dates = [datetime.datetime.fromtimestamp(int(i)/1000000).strftime('%Y-%m-%d %H:%M:%S')
for i in dates]
searches = [i.encode('utf-8') for i in searches]
3. 分析数据
我们可以看到截止到 2014 年秋季的 886 天内,我总共进行了近 64,000 次 Google 搜索,每天超过 70 次。 我每天在工作时都使用个人笔记本电脑,这能够解释这一巨大的搜索数量,同时也说明我并没有夸大 Google 搜索的普遍性!
数据中有很多值得挖掘的模式。比如每小时搜索数据:
hours = [datetime.datetime.strptime(i, '%Y-%m-%d %H:%M:%S').hour for i in dates]
n, bins, patches = plt.hist(hours, 24, facecolor='blue', alpha=0.75)
plt.xticks([0,6,12,18], ['12 AM','6 AM', '12 PM', '6 PM'], fontsize=18)
plt.xlabel('Hour', fontsize=24)
plt.ylabel('Frequency', fontsize=24)
plt.gcf().set_size_inches(18.5, 10.5, forward=True)
plt.show()
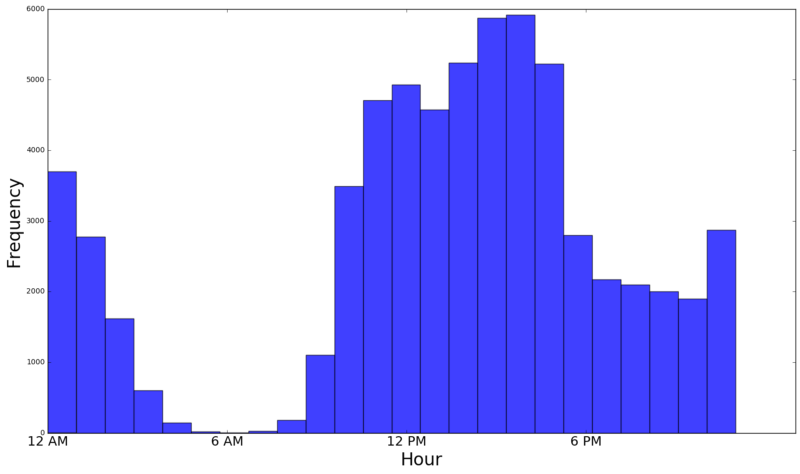
每小时图反映了我的作息规律:当我没有使用 Google 时,很可能我在睡觉。在到达工作地点之后,我开始各种搜索,在下午 3 点左右达到高峰值。晚餐后经过简短的休息,我再次开始搜索,在 10 点左右达到又一个高峰,一直持续到过了凌晨才结束。(我是一只夜猫子)。
我都在 Google 搜索些什么呢?可以对词频进行分析排序:
combo = ' '.join(searches)
freqs = Counter(combo.split())
top = freqs.most_common(40)
words = []
counts = []
for i in range(40):
words.append(top[i][0])
counts.append(top[i][1])
words.reverse()
counts.reverse()
plt.barh(range(40), counts, align='center', color='b', alpha=0.75)
plt.yticks(range(40), words, fontsize=16)
plt.gcf().set_size_inches(18.5, 10.5, forward=True)
plt.show()
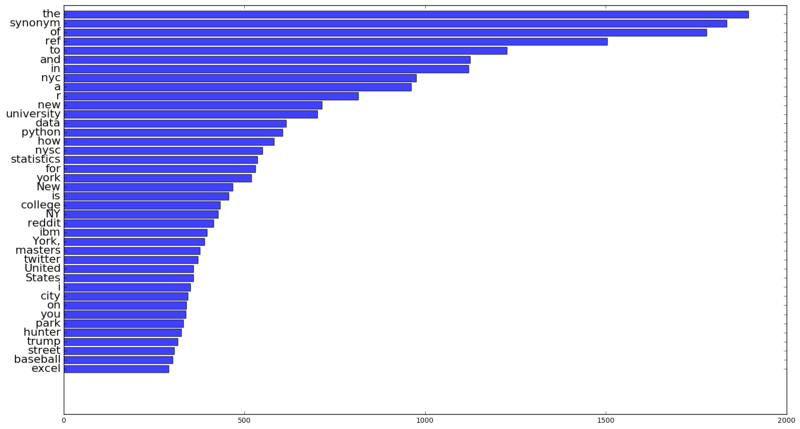
英文中常常使用的
“
the”
“
of
”
可以忽略不计,在列表中仍然可以看到过去几年中我的心路历程。我经常写博客,而且会避免过度使用同一个词,因此会常常搜索同义词。 我住在纽约(“nyc”),常常去健身房(“nysc”)。 我是一个有追求的数据科学家(“data”,“python”,“r”)。 我是典型的美国人(“baseball”,“States”),同时也很关心时事(“trump”)。
当然,时间段对搜索词有很大的影响。人们不会因为相同的原因每天都搜索同一件事,同时也不会每天想同样的事。因此,分析随着时间推移一些特定的词的变化很有意义。这能够让我们了解兴趣和关注点是如何随着时间的推移而变化的:
d = {"search": searches,
"time": dates}
googled = pd.DataFrame(d)
dt = datetime.datetime(2014, 10, 1)
end = datetime.datetime(2017, 3, 5)
step = datetime.timedelta(days=7)
weekly = []
while dt weekly[i]) &
(googled['time']
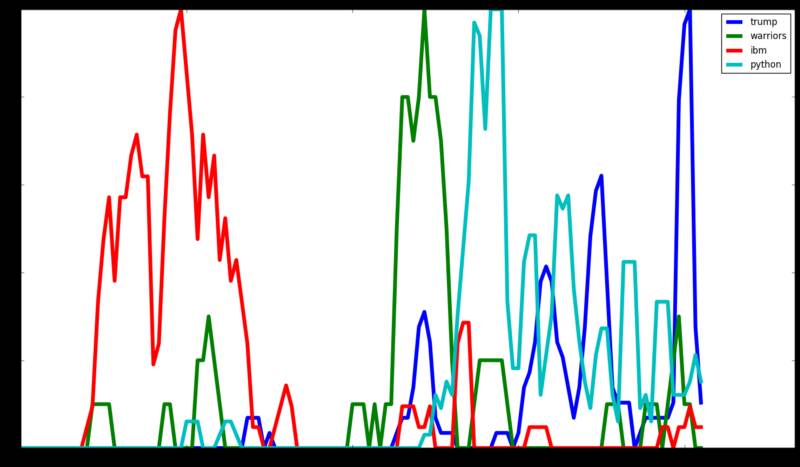
虽然你我素未谋面,但是你完全可以通过这个图来了解我是谁,以及在某段时间内我在想些什么。 毕业后,直到 2015 年夏天我都在 IBM (红色)工作。有好几个月,我一直特别关注金州勇士队创纪录的赛季(绿色)。 在 2016 年春天,我决定学习 Python (浅蓝色)。接近总统选举时,我非常关注特朗普(深蓝色),其中中断了一段时间,直到他的就职典礼又开设重新关注。
结语
读完从这篇文章,会让你感受到 Google 无所不知的强大性。这些反映在从地图到 GChat 对话以及个人日历等数据。个人的电子足迹涵盖了多少讯息,以及谁有权获得这些数据,这都值得我们深思。
但可以肯定的是,你有权查看你的搜索记录,并且了解当中的意义。我们都渐渐失去了在睡前回顾一天做了些什么的习惯,在某种程度上 Google 充当了类似日记的功能,而且反映的内容更真实。
在这里鼓励你试着下载自己的数据,尝试分析。完整的代码链接如下。如果你习惯用的是某度搜索的话,那怪我咯~
https://github.com/WalkerHarrison/Google_searches

推荐阅读
初级数据科学家求职时的 3 大必备能力
不可错过的优质深度学习课程
职场 | 数据库面试常问的一些基本概念
听说你最擅长“拖”,你“拖”得过Excel吗?










