在自然场景文本检测技术中,基于锚点的回归方法是其中的一种主流方法[1,2,3,4]。然而,由于场景文本的多方向分布及尺寸角度变化的多样性,这类方法常常需要设计复杂多样的锚点来匹配各式各样的文本;场景文本检测中的锚点机制需要深入的探索,并进行有效的改进与创新。本文主要介绍两篇对于文本检测中锚点机制进行改进创新的论文:隐式锚点机制 HAM(IEEE TIP2020: HAM: Hidden Anchor Mechanism for Scene Text Detection)和注意力锚点机制 AAM(IEEE T-ITS 2020: Detecting Text in Scene and Traffic Guide Panels With Attention Anchor Mechanism)。
这两篇论文首先将锚点进行长度、高度、角度的解耦合
[5]
,然后采用不同的改进方法将锚点重构为最终的文本检测结果,能够克服锚点设计的复杂性,自适应的检测不同方向、不同尺度的场景文本。其中,隐式锚点机制
HAM
将所有锚点的预测值当做一个隐藏层,然后将所有的预测结果融合,使得网络的输出类似于直接回归方法。注意力锚点机制
AAM
使用注意力机制预测宽度、高度和角度锚点,然后根据预测出来的锚点来进行最终检测文本的回归。
目前基于锚点的文本方法都会设计很多复杂的锚点来使其符合多变的文本。这使得算法的复杂度变高,不利于不同场景下的文本检测,遇到没有对应的设计锚点,此时的文本检测往往表现不好。本文介绍的两篇论文则是,针对锚点设计复杂性问题,分别设计了机制隐式锚点机制和注意力锚点,来提升基于锚点的算法对于多方向复杂文本检测的性能。

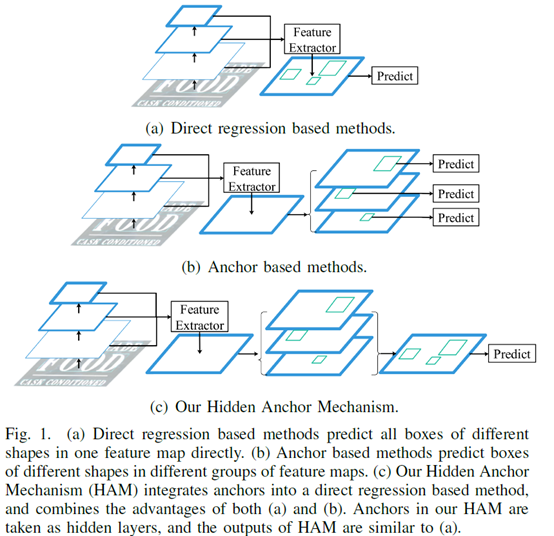
隐式锚点机制将锚点的输出层作为一个网络的隐层,并将每个锚点的预测结果加权求和,从而得出最终的预测结果。如图
1
所示,论文提出的隐式锚点机制将直接回归方法(例如
EAST [6]
)和基于锚点回归的方法相结合,将锚点的输出结果作为网络的中间隐层,将其重新组合成为最终的输出预测结果,使得网络的输出结果和直接回归方法一样简洁,能够方便的进行计算与训练。
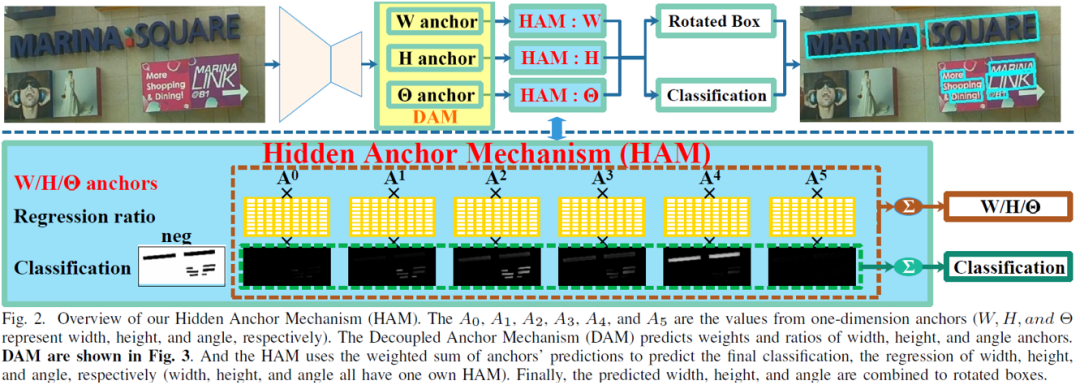
隐式锚点机制原理如图
2
所示,在解耦合锚点机制基础上,在特征图的每一个像素点,隐式锚点机制为每一个锚点值预测一个回归值与锚点值的比例,以及一个分类的置信度,即每个锚点均预测回归值。其中同一维度(宽度
/
高度
/
角度)锚点的分类置信度之和(包括背景类置信度)为
1
,使用
Softmax
来进行分类监督。最后,同一维度(宽度
/
高度
/
角度)锚点的预测值将分类置信度作为权重,进行加权求和,得到最终预测的宽度、高度和角度。

如图
6
所示,论文还提出了一种迭代回归框的机制(
IRB
)来作为后处理,进一步提升方法的性能。
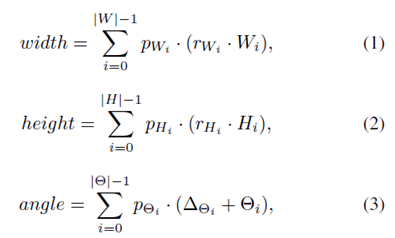
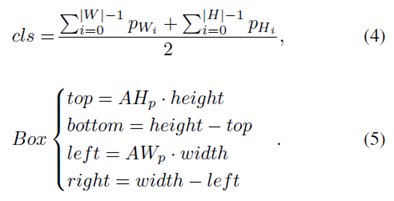
其中,预测的宽高角度如公式
1
、
2
和
3
所示,最终的分类结果和预测框如公式
4
和
5
所示,整个网络的最终输出结果与直接回归类方法
EAST
类型。
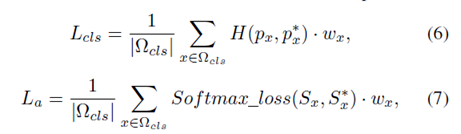
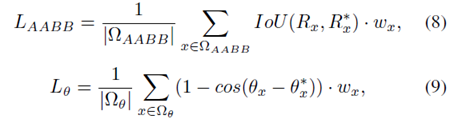
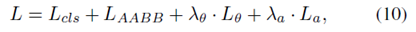
这里,损失函数参考了
FOTS [7]
,额外增加了
La
来对每个锚点进行分配。损失函数如公式
6
到
10
所示,
Lcls
,
La
,
LAABB
,
L
θ分别为分类损失,锚点分配损失,回归框损失和角度的损失函数。
L
为最终的损失函数,其中
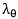 设置为
10
,
设置为
10
,
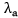 在前
10
万轮为
0.1
,之后为
0
。
在前
10
万轮为
0.1
,之后为
0
。
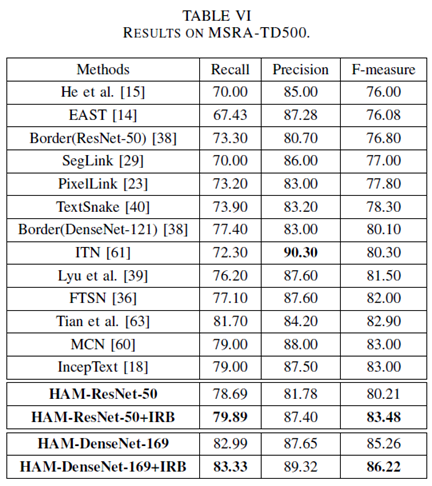
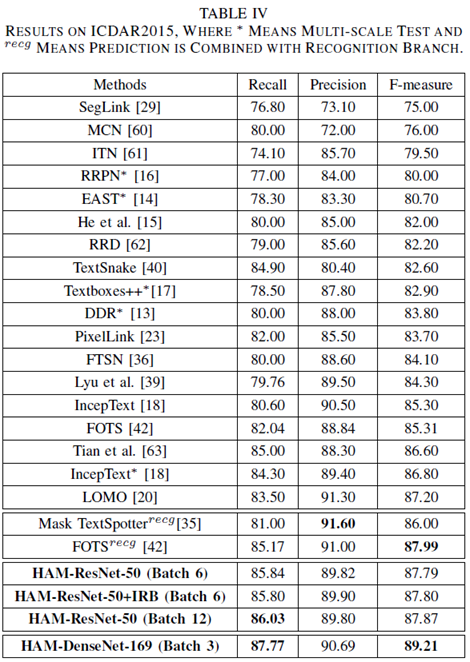
从表
VI
和
IV
可以看出,该方法在
MSRA-TD500
和
ICDAR 2015
上都取得了
State-of-the-art
的检测效果。其中
+IRB
代表使用了本文提出的迭代回归框的后处理方法,



上图
展示了一些可视化的场景文本数据集
MSRA-TD500
,
ICDAR 2015
和
ICDAR 2017 MLT
的
检测结果图。

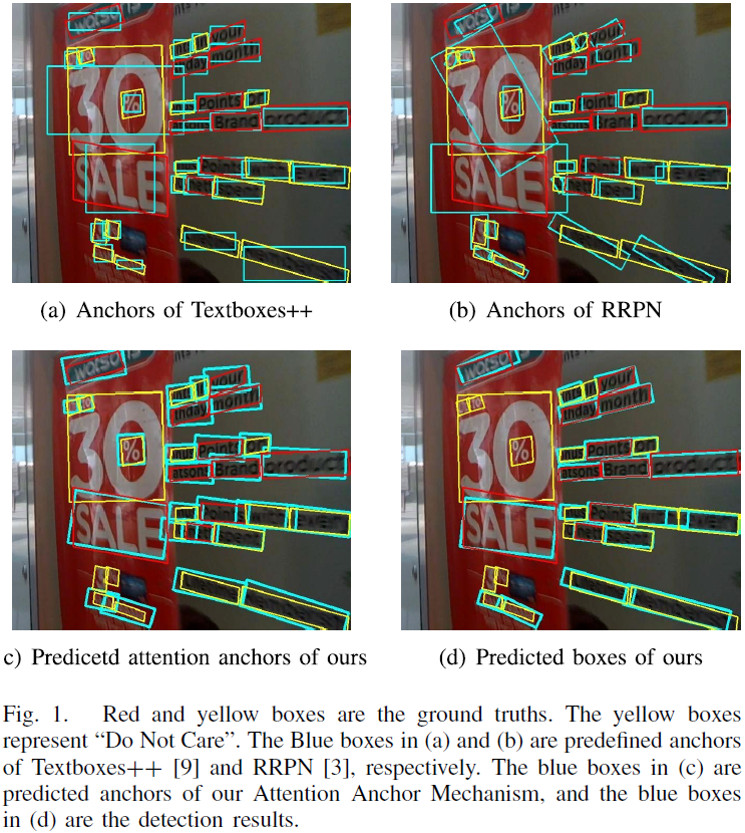
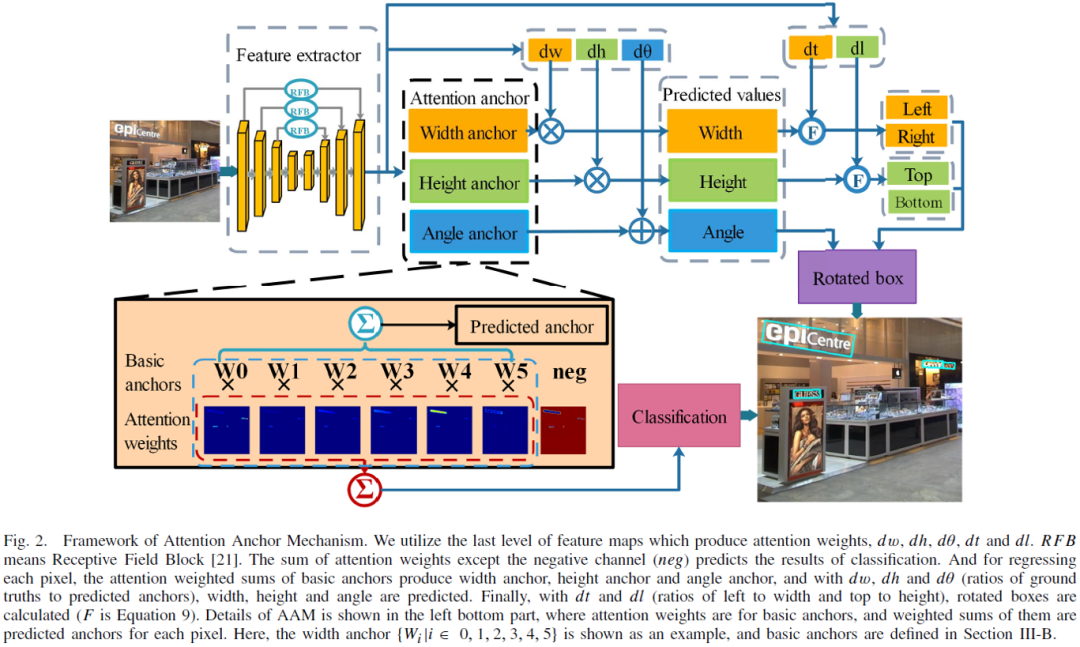
注意力锚点机制的原理如图
2
所示,主干网络类似于
FPN
,其中添加了
RFB
模块来增强网络的感受野。论文对于解耦合之后的锚点使用了注意力机制,将注意力机制预测的权重作为每个锚点的权重,并将每个维度的锚点进行加权求和,从而预测出一个适合当前文本的锚点,即为注意力锚点。在注意力锚点的基础上,本文的方法预测了文本的真值和锚点的比例,从而预测出文本的宽度,高度以及角度。
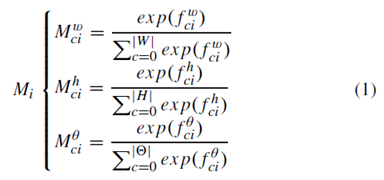
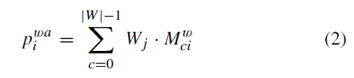
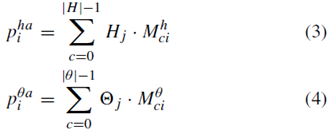

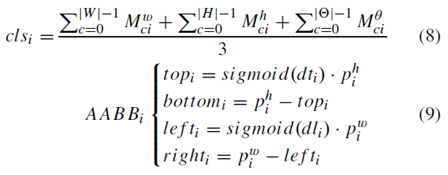
预测的注意力机制权重如公式
1
所示;注意力机制之后预测出来的锚点值为公式
2
、
3
、
4
;预测的宽、高、角度值为公式
5
、
6
、
7
;最终的预测分类结果为公式
8
,回归框为公式
9
。
注意力锚点机制的损失函数与
FOTS
类似,与隐式锚点机制相比没有
La
来对锚点进行显式地分配,而是用注意力机制自动分配。
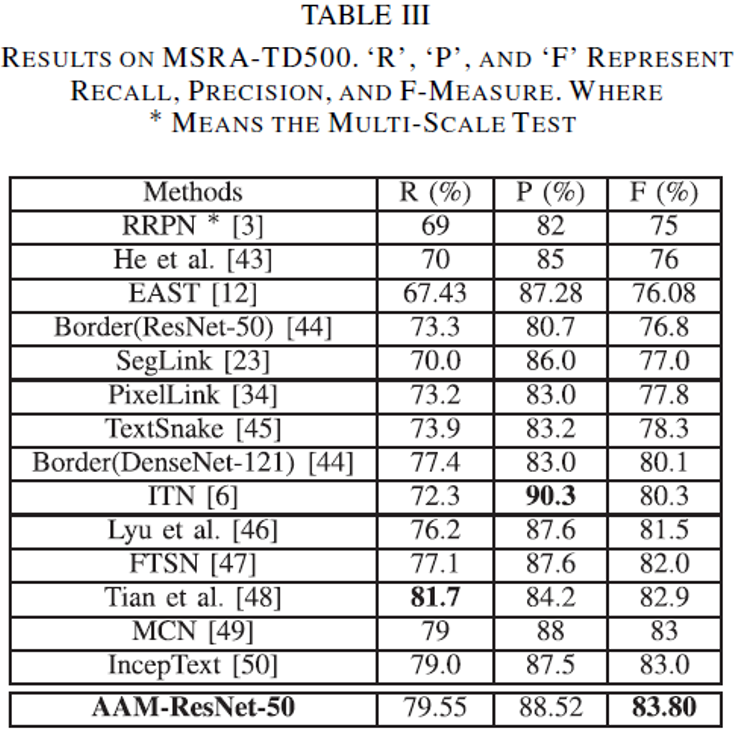
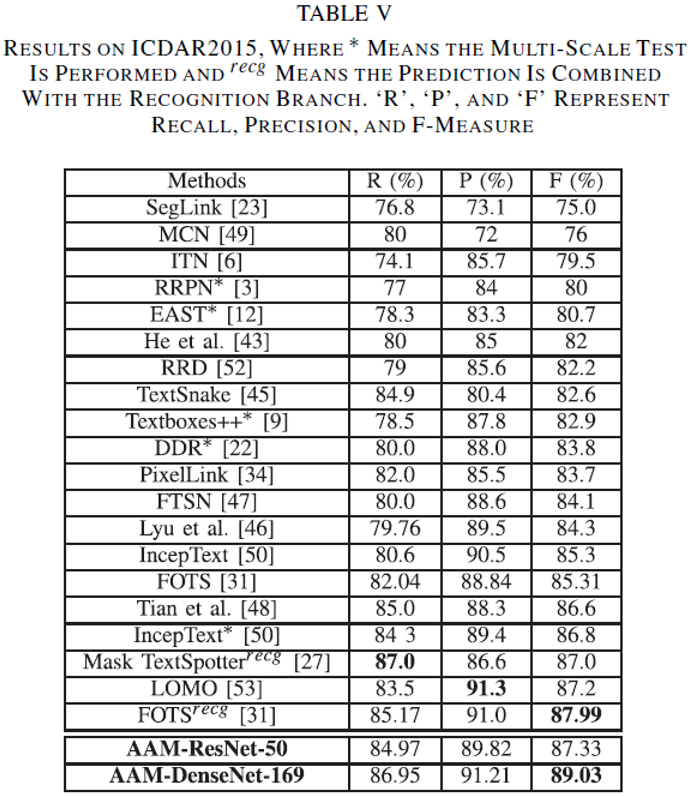
从表
III
和
V
可以看出,该方法在
MSRA-TD500
和
ICDAR 2015
上都取得了
State-of-the-art
的检测效果。
本文介绍了两篇对锚点机制进行改进的自然场景文本检测方法,对基于锚点机制的场景文本检测方法进行了较深入的探索及相应性的改进创新。在多个文本检测数据集上的实验表明这两种方法均取得了良好的性能。










