转自订阅号「AIOps智能运维」,已授权运维帮转发
作者简介:运小贝,百度高级研发工程师
负责百度内网质量监测平台(NetRadar)的业务端设计及开发工作。在系统和网络监控、时序指标异常检测、智能客服机器人等方向有广泛实践经验。
百度内网连接着数十万台服务器,承载着全公司业务的网络通信,其通信质量的重要性不言而喻。而百度内网的质量监测平台NetRadar(网络雷达),通过对整个内网“服务器端到端”传输质量进行监测,实现了快速、准确地发现、通告、定位内网问题,为百度业务的正常通信提供了有力保障。
《百度网络监控实战:NetRadar横空出世》系列文章将分上、下两篇介绍NetRadar平台,本文主要介绍内网质量监测的意义、相关需求以及百度原有的内网监测技术,而下篇将从核心功能、设计框架、异常检测策略以及可视化视图等方面对NetRadar平台进行系统介绍。
百度拥有数十万台服务器,分布于全国各地的几十个数据中心(又称IDC、机房)。这些海量的服务器通过网络分层级互联,构成了统一的“资源池”,对外提供可靠、强大的存储、计算和通信服务。
在软件架构上,百度的大型服务一般都是模块化设计,一次服务需要上下游大量模块共同协作完成。为了提高并发服务能力和容灾能力,这些模块会分布式地部署在不同机房的不同服务器上。为保证服务的正常运行,内网必须保证各模块具有良好的“端到端”网络通信能力,一旦出现网络故障并影响了模块间的通信,往往会对服务造成影响,甚至导致服务整体不可用。
为了提供高可靠、高性能的端到端通信能力,网络结构在设计上预留了大量冗余,既有设备的冗余,也有线路的冗余。这样一来,两台服务器间的通信可以同时存在许多条不同的路径,能够在一定程度上抵御网络故障。尽管如此,实际环境中端到端的通信问题依然常见,其原因主要包括:路由收敛延迟、ToR交换机单点故障、网络拥塞等等。另一方面,即便单个设备、网线、服务器发生故障的概率很低,乘上巨大的数量,故障必然是“常态”现象。
在这种“与故障为伴”的环境下,既然无法避免故障,就需要能够及时、准确地监测内网质量,这对于保证服务正常运行来说是至关重要的。
在运维实践中,工程师对内网质量监测系统都有什么样的需求呢?我们对各业务线的运维工程师,以及来自网络组的同学进行了调研。为了更好地说明用户需求,图1给出了一个典型的运维场景:
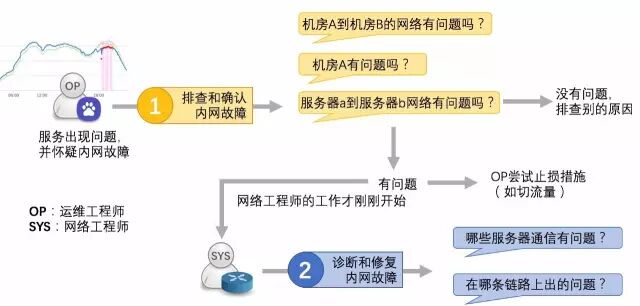
图1 内网问题相关的运维场景
当运维工程师发现服务关键指标异常后,如果怀疑是内网故障导致的,则需要通过回答如下一些问题进行排查:
1)“机房A到机房B的网络有问题吗?”
2)“服务器a到服务器b网络有问题吗?”
如果经过检查确认内网没有问题,就要继续排查其他可能的原因,诸如上线、操作、程序 bug 等原因,以帮助进行有效的止损和恢复决策。而如果确定是内网故障导致服务受损,那么网络工程师为了诊断和修复网络故障,会排查一系列的通信问题来帮助缩小故障范围,比如:“哪些服务器通信有问题?”,“哪条链路有问题?”等。为了回答这些问题,最直接有效地方式就是“进行服务器端到端检测”,比如:
1) 排查“机房A到机房B网络有问题吗?”
可以测试: 机房A大部分机器到机房B大部分机器间的网络质量
2) 排查“机房A内部网络有问题吗?”
可以测试: 机房A大部分机器互相访问的网络质量
3) 排查“服务器a到服务器b网络有问题吗?”
只需测试: 服务器a访问服务器b的网络质量
4) 排查“哪些服务器通信有问题?”
需要挨个ping或ssh疑似有问题的服务器
5) 排查“在哪条链路上出的问题?”
需要执行traceroute命令查看路由细节
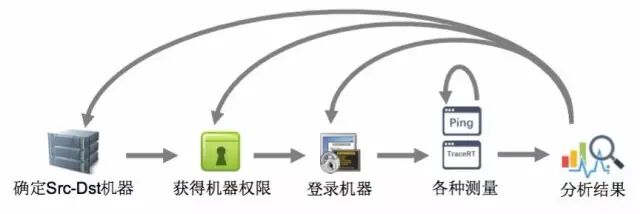
图2 人工测量网络质量步骤
但是,人工执行上述测试任务费时又费力。如图2所示,为了进行一次端到端的网络质量检测,首先要确定“源-目的”服务器,然后获得服务器的登录权限,之后才能登录到机器上执行各种测试操作,最终分析数据得到测量结果。显然,这种人工测量的方式可扩展性很差,无法应对大规模测量的需求。因此,需要一个平台能够实时地、自动地执行测量任务,给出分析结果。
那么,这个平台需要满足什么要求呢? 通过对业务线运维工程师和网络工程师进行调研,整理的需求如下:
1)“端到端”的持续监测
由于百度业务线的程序或模块均部署在服务器上,其网络通信也都是从服务器发起和接收,所以服务器“端到端”的网络质量更能反应内网状况对业务通信的实际影响。所以从业务角度出发,平台应当能够对端到端网络质量进行持续监测。
2)全覆盖的监测
实际中,运维工程师通常知道业务部署在哪些机房,但不清楚具体哪些机器间有网络通信,所以会关注 “这些机房网络是否正常”这种全局性的问题。此外,网络工程师的责任是保证整个内网质量可靠,需要系统地监测整个内网性能,尽可能地发现和修复网络故障,减少隐患。
3)按需下发监测任务
实际工作中常常需要根据现场情况执行特定的监测任务,这导致需要进行额外的、有针对性的测量。所以,监测平台还需支持按需监测。
4)检测结果主动报警
由于网络工程师直接对内网质量负责,因此希望监测平台在测量”端到端”通信性能后,对相关数据进行分析,判断网络是否正常,并在检测到网络异常后及时发送报警,以保证各业务线服务正常。
5)针对产品业务的定制化展示
由于一个产品业务通常只部署在部分机房,依赖部分网络,所以运维工程师往往不关注非其负责的。因此,监测系统需要支持定制化展示,使运维工程师能迅速获取其需要关注的网络状态信息。
那么,百度现有的内网监测技术能否满足以上需求呢?
其实,百度内部已经应用了一些内网质量监测技术,这些技术利用不同的测量手段获取内网质量数据,并加以分析,进而判断网络是否正常。表1给出了三种现有监测技术的相关信息。
表1 现有监测技术原理及不足
编号 | 监控原理 | 不足
|
技术1 | 利用交换机的Syslog监测交换机级别故障 | 交换机级别故障无法准确反映业务所感知的网络性能 |
Syslog无法记录所有交换机故障 |
无法检测非交换机故障类网络异常 |
技术2 | 部署专用的服务器探针来连接各IDC核心交换机,服务器通过互相发包对IDC间网络性能进行主动探测 | IDC内部网络通信监控缺失 |
探测到的IDC间网络性能和业务感受到的网络性能有所差别 |
资源开销大,不能直接扩展 |
技术3 | 在所有线上服务器部署探针,并在各IDC分别设置一个靶标服务器,让所有线上服务器测量到各靶标服务器的网络状态 | 单个靶标服务器存在单点故障问题,不能很好代表机房的网络情况 |
机房内部的拓扑覆盖不全 |
不支持按需探测功能 |
上述几种技术在内网质量监测和运维中发挥了一定作用,但在使用过程中也发现了一些不足,不能很好满足上述需求。因此,基于以上技术的实战经验,我们开发了新平台NetRadar(网络雷达)。与以上监测技术相比,NetRadar具有以下优点:
覆盖广:探测agent在全网linux服务器完成部署,覆盖了百度全部内网机房;
多层级:7*24小时持续监测整个内网的网络质量,包括机房间、机房内集群间、集群内ToR交换机间的网络质量;
指标全:评价网络质量的方式多样,区分QOS队列、协议、统计值,共计27种网络质量监控指标,每个探测周期会产生近百万的监控指标;
检测准:通过自适应异常检测算法对监控指标进行检测,并进一步生成机房、区域级别的网络事件;
除此之外,NetRadar还支持按需探测,并提供全内网“端到端”探测接口以及故障事件接口,以帮助工程师快速诊断网络问题。
相信通过本文的介绍,您已经对百度内网质量监测有了一些了解。接下来,我们将推出本系列文章的下篇:《百度网络监控实战:NetRadar横空出世(下)》,系统性地介绍NetRadar平台,请持续关注AIOps智能运维!








