大家早上中午晚上好,我是冯诺依0,我不得劲。
上一句话就是普普通通的打个招呼并且强化一下我的id,相比较来说,最近还是比较得劲的。
无非就是中午出去转了一圈发现周边基本上不能堂食所以只能点外卖,北京疫情越来越严重从而耽误了我去成都看live的计划,并且盼望已久的居家办公一直没有到来罢了。
接下来看一下今天这篇论文:

论文标题:MetaFormer Is Actually What You Need for Vision,很好,四舍五入也属于是*** is all you need系列。颜水成组做的一篇工作。发布于CVPR2022,目前引用量97.
颜水成也属于是深度学习这个方向的著名狠人了,代表作包括但不限于T2T和NIN。
那么这篇文章做了什么呢。
众所都周知啊,Dosovitskiy一声炮响,为CV送来了VIT。从那以后就有很多研究员努力尝试为VIT加入各种各样的空间位置先验,尝试在VIT中引入CNN中的先验。实验结果证明了,各种各样的先验引入方式基本上都能带来各种各样的涨点,所以这显然是一个很好的水论文的方向。
事实上这是很多学生发论文的方法之一。已经看过太多太多改进一下VIT的架构,做一点小改动就水一篇的工作了。
这些先验或者是加入到token的embedding方法中(最经典的比如带overlapping的token嵌入)或者加入到attention中(比如把全局attention更换成在局部空间内做attention)。
这些方法确实有效,但是它真的本质吗。如果说vit本身能work的主要原因其实并不在于attention或者embedding,那么在这些位置加入空间先验真的是一个好的科研方向吗。
本论文研究的问题就是,
VIT模型中,真正有效的设计是什么。
本论文通过大量的实验,验证了attention机制在VIT的模型架构中其实并不是非常重要,在极端的情况下,即使是将多头注意力机制更换成一个非常简单的按token做pooling的操作,也能取得非常有竞争力的表现。因此,vit模型真正有效的机制在于去掉attention以外的部分。作者去掉了多头注意力机制,而是替换成了一个抽象的token mixer操作。将替换后的架构命名为metaFormer,并且说明这样的架构才是VIT能work的基础。
关于attention机制的效率这个问题,目前已经有非常多的工作在研究了。比如很多工作在探索如何对token做剪枝或者merge。实验研究表明,在一张图inference的过程中,实际上有效的token的数量是非常少的,因此这其实并不是一个很好的机制。
============耶耶耶我是分割线耶耶耶==========
接下来看一下文章的具体方法和分析。
首先介绍一下子把多头注意力机制MHA替换成抽象的token mixer架构得到的MetaFormer。
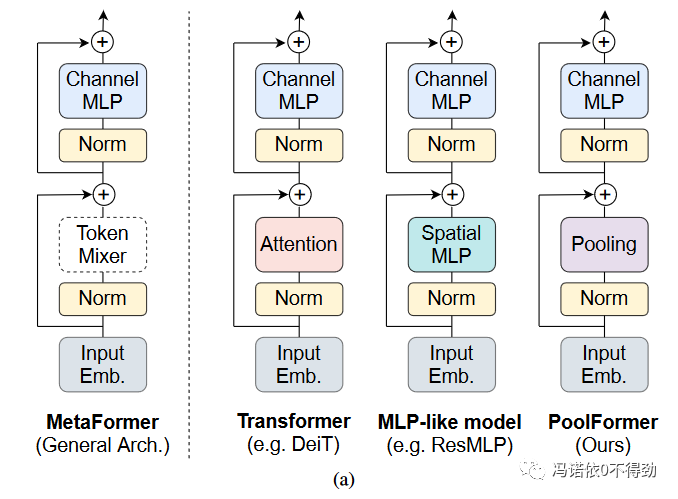
结构非常的一目了然,相比于VIT和ResMLP(一个使用纯MLP的架构,token之间的信息通过MLP进行交换),MetaFormer将他们的token信息交换模块抽象成一个通用的层。对于其他的设计,比如residual block、norm、输入embedding、通道MLP等都没有进行修改。整个网络依然可以用三个运算来表示:
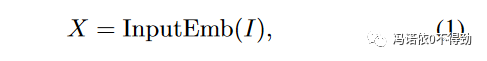
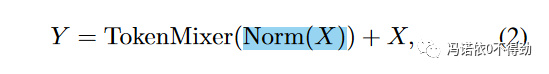
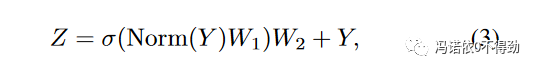
当然了,MetaFormer到目前为止是一个抽象的概念,本工作为了做实验,还是需要对它做具象。为了保证具象化的模型无限接近于MetaFormer,这里使用一个完全没有参数的池化操作作为token mixer,从而得到了本工作的实验模型
PoolFormer
:

这里看一看公式就能直接确认,这里就是一个非常经典的pooling操作。
读到这里我就开始怀疑,本工作能做work是不是因为这里引入的池化操作能够带来额外的局部空间先验。因此读到这里我会怀疑本工作是over claim的。但是后面的ablation部分消除了这个担忧。
注意,这里为了消除residual connection带来的输入空间的偏差,需要额外减去原本的token表示,以避免分布出现偏移。
这很好理解,因为正常状态下pooling是不能单独做short cut的。
接下来就是我不很喜欢的部分了:作者对PoolFormer采用了类CNN结构。即分stage逐渐增大token的规模。按照作者的解释,pooling操作基本上是免费的,因此完全可以利用运算量随token线性增加的优势,对浅层使用更小的token。从而得到模型架构如下:
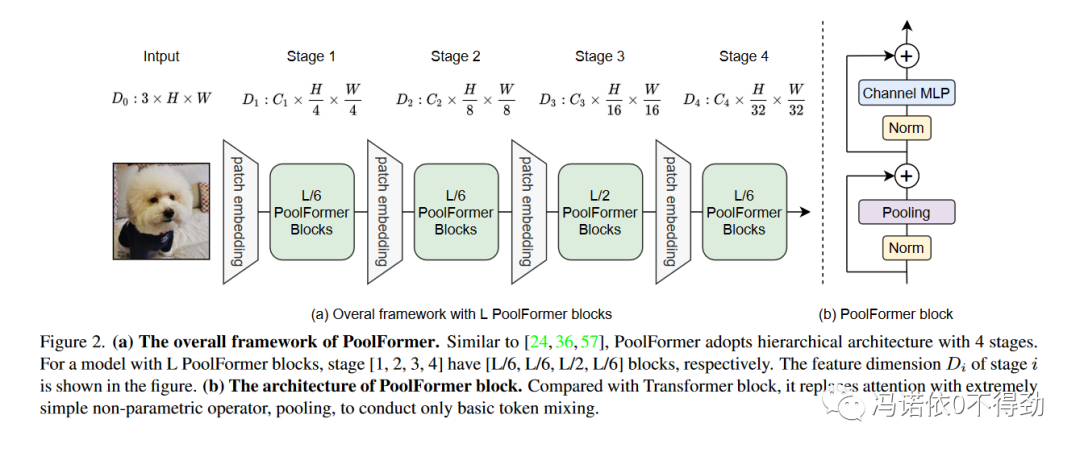
按照我的理解,这样的对比对于VIT来说其实是并不公平的。众所周知,VIT使用16*16的token,这样一个224*224的图像会被划分成196个token,由于MHA的运算复杂度是token数量的平方,因此更小的token是很难塞进卡里的。或许就是因为在浅层,信息分布在非常低级的相邻像素之中,而16*16的token对这样的信息提取本身就比较低效,因此才会依赖比较复杂的MHA操作来增强信息提取。而PoolFormer虽然去掉了MHA,但是在pooling中引入了空间局部性,并且还使用了更小的token来增强浅层对与低级信息的感知能力。所以我会觉得这个改动不是非常的公平。我会怀疑在标准VIT架构上将MHA替换为pooling是不是真的能work。
如果我是reviewer我真的会狠狠judge这一点。

最终文章给出模型架构如上表。
=====================================
接下来看实验结果。
首先是ImageNet1k分类结果。
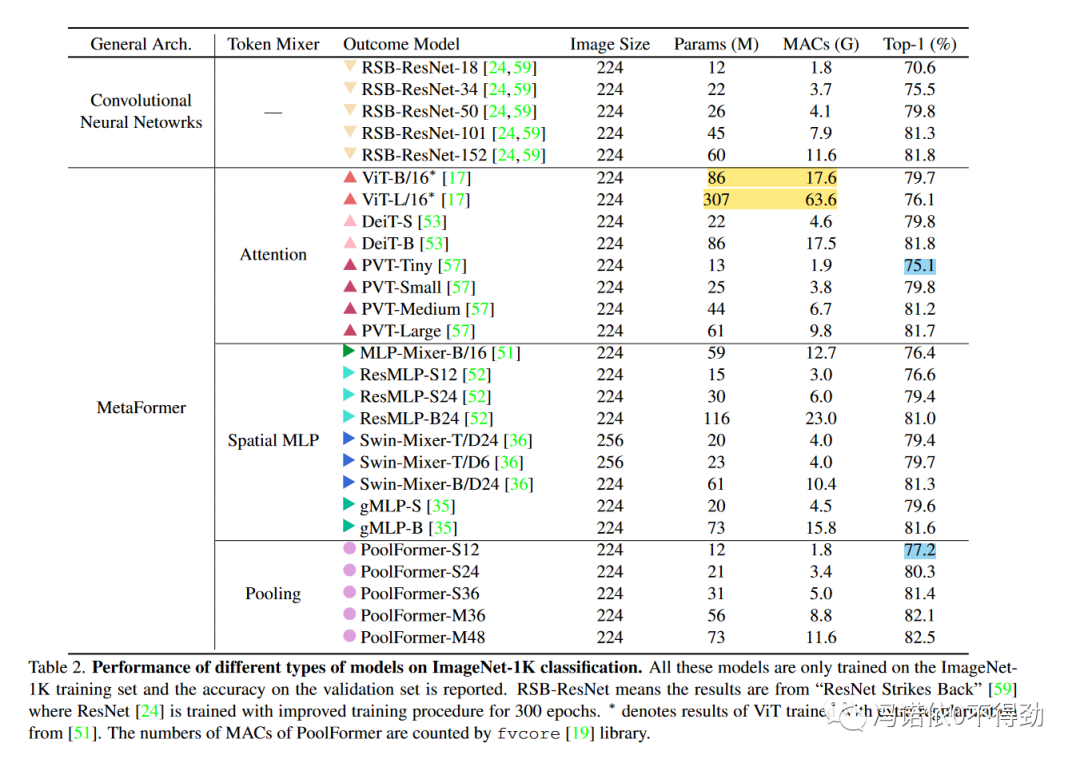
可以看到啊,因为vit的巨大运算量,点数基本上与poolFormer失去了可比性。但是能看出结论就是PoolFormer的效率是更高的。但其实本部分的结果很难看出PoolFormer的点数上涨是源于CNN-style的stage架构还是源于从attention替换成pooling。
在我的理解里面,对于架构完全相同的模型,如果吧MHA替换成pooling肯定是会掉点的。但是如果是为了支持本文的结论,如果点数下降不多,我是可以接受的。但是这一波架构的改变就会让我不是很能接受这篇文章的结论了。
论文中还给出了目标检测和语义分割的实验,这里就不放了。
重点看一下ablation。