班主任之眼!——看穿彦正玛少女の薄纱
编辑:Gemini
简介
这是一篇正经的技术科普文章,尽量使用浅显易懂的语言介绍图像处理的知识以及图片选择类验证码识别的一种方法。
为了让更多人读懂,我调整了叙述的顺序和严谨性,并有意忽略了一些数学和实现上的细节,专业人士和对实现感兴趣的可以阅读论文或参考源代码(源代码只是验证模型用,中间反复修改,目标是能跑就行,有的地方可能写得很丑陋,见笑)。
序言
虽说公认的国民岳父是韩寒,可是毕竟小野只有一个。其实在我心中,真正的国民岳父乃我当朝重臣铁道部君。别不承认,君不见逢年过节有多少人抱着铁道部君的大腿哭喊道:“铁道部君,求你给我一张车票吧,给我上一张车票吧!”
新世纪以来,铁道部君抓住时代机遇,真抓猛干,麾下诞生了,,,,,,然而我最感兴趣的,却是其中最神秘的彦正玛小姐。

说到这彦正玛小姐,她几乎从不以全貌示人:她是如此的多变,以至于凡人只能看到她薄纱后万千面孔之一二,还埋怨她看上去全是马赛克。平庸的人自然无法欣赏这样的美丽,被下身支配的人们更只会在乎是否身轻体柔易推倒。可对于我来说,推导比推倒更有趣,更何况,验证码知识遮挡住了我们的视野,却放飞了我们的想象。这千千万万的面孔中,包含了日月星辰,火水土石,寒暑阴阳……我就是喜欢如此博学而又如此低调的姑娘。
若以常人的视角去看她,她的变化万千,阴阳不定,低像素的图片和扭曲的文字组合在一起,混沌杂乱,毫无规律,毫无美感。可纵然她有万般变化,古语有云:“道可道,非恒道;名可名,非恒名。”独特的少女需要从独特的角度去欣赏,两年以来,我一直默默端详她,试图撩开她的薄纱,触碰她最隐秘的本质。终于,领悟了班主任之眼的我,逐渐揭开了她的秘密……
班主任之眼
哎哟,作为三好学生这种文风我还是写不来,我还是回归我平时的说话方式吧。既然这是一篇科普文,就是面向大众的。
虽然验证码识别这个话题总是跟什么机器学习、人工智能等高深的概念在一起出现,看似不可企及。但实际上,一些看似复杂的问题,往往有简单而精妙的思路让人拍案叫绝,所谓“千里之堤溃于蚁穴”。这也正是研究系统安全的乐趣。今天就给大家介绍一下我毕业设计的项目——破解图像选择型验证码。
什么是验证码?
验证码的正式全称叫做“全自动区别人类与计算机的公开图灵测试”,通过向用户提问的方式区分人和计算机。验证码由卡内基梅隆大学的三位学生发明,被广泛用于安全领域,防范程序对系统进行的攻击破解。而我在本科期间就被这所学校的教科书震撼,之后申请到研究生,并以验证码作为我的毕业设计项目,不得不说是一种缘分。
最常见的验证码自然是扭曲的图形和数字验证码啦,不过今天我们要说的是另一种,也是中国人最熟悉的——图片选择型验证码。

上图大家看到的就是最开始使用图片选择型验证码的公司——Google的验证码。然而我的毕业设计并没有选择这种验证码来做实验,因为——它是在太简单了!
开个玩笑,其实除了它“简单”之外,更重要的原因是Google本身就是网络爬虫起家,它的反爬虫技术太厉害了,我采集不到足够的数据……想当年,我做美国数学建模比赛的时候,采取换IP+模拟IE浏览器动作的方法才勉强能够抓取足够做实验的数据,到如今,只怕难度还要翻番。
我清醒认识到了这一点的难度,于是我把魔爪伸向了……彦正玛小姐!
好了,啰啰嗦嗦说了这么多,下面进入正题:如何借助“班主任之眼”搞定这一类验证码。
可疑的巧合
我不知道各位中学的环境如何,反正在我的高中,早恋是条高压线,坚决不能碰,否则被教导处主任发现是要处分甚至劝退的。但是年轻的时候,谁能没有一颗悸动的心?有的班主任不忍心事情发展到无可挽回的地步,看到苗头就开始打预防针——他们都有独特的技巧,往往一抓一个准。
多年后聊起来,老师说,最有效的一条准则是——
在学校或街上,碰到两个男女学生单独在一起或者一前一后走,就可能有事情;碰到两次,就基本能够确定关系。
来源:某年级组长
这就是所谓的“可疑的巧合”,英文叫做suspicious coincidence. 在老师的假设中,男女同学之间是互不相关的,就像丢骰子一样,哪两个点数一起出现这个事件本身是随机的,而且概率应当想等。所以如果男女同学一起单独出现,那每一次应该出现不同的组合;如果某对组合一起出现多次,那就违反了老师的假设——这就说明男女同学有关系。
这跟验证码又有什么关系呢?
一个验证码可以看做两部分:文字和图片。验证码向用户提的问题是:找到和文字相关的图片。
文字可以看做是男同学,图片可以看做是女同学,他们之间的亲密程度不一——有的如胶似漆,比如“航母”和航母的图片;有的形同陌路,比如“肥皂”和毛巾的图片。现在,为了不让外人发现他们之间的关系,他们成批出现——一个文字标签同若干相关和不相关的图片混合在同一个验证码中。
想想验证码是怎么生成的?

假设有若干个类别,比如天鹅、海滩、航母、飞机等;每个类别下面有若干图片。那么最简单的【注1】生成验证码的步骤如下:
1、从所有类别的名称中抽取一个作为当前验证码的文字,比如“天鹅”
2、从该类别下的图片中随机抽取至少一张张作为相关图片,也就是用户要去选取的答案,比如上图中的第五(第二行第一个)和第七张图(第二行第三个)。
3、从剩下的图片中随便选取几张不相关的图片,凑够八张,就组成了如上图所示的验证码。
如果有10个图片的类别、每个类别有100张图片,总共就有1000张图片。那么对于每一个类别,只有10张图是相关的,剩下900张都是不相关的。那么在一张选取目标是“手电筒”的验证码里,相关图片的选择只有10种,而不相关图片的选择有900种!
反过来想呢?如果你手中有1000张验证码都是要选取“天鹅”的验证码,那么天鹅的图片至少需要出现1000次,也就是平均下来,天鹅这个类别的100张图片平均每张要出现10次。而不是“天鹅”这个种类的900张中,平均每张出现的次数是0.9次!
虽然这只是平均值,但确实是一个足以利用的巨大差距。
同样的,相关和不相关图片共同出现在一个验证码中概率差距也十分巨大,这里就留给学有余力的同学自己去计算了(需要做假设)。根据我们在部分样本上的采样结果,如果两张图片一起出现2次,那么他们有66%的可能是同一类的;如果两张图片一起出现三次或三次以上,那么他们有98%的可能性是属于同一个种类。
而班主任之眼,就是从这被刻意掩盖的关系中,寻找那些发生概率明显跟假设不一样的关系,从而确定文字和图片,以及图片和图片的“亲密程度”,也就是相关度。
利用文字和图片的相关度,我们可以做什么?
先反过来思考一个问题,我们在做这类验证码选择题的时候,真的需要理解它的含义吗?一般人在识别验证码的时候,思维流程图是这样的:
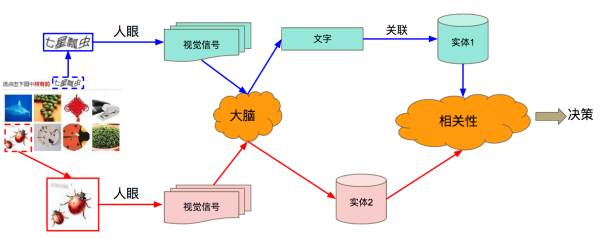
我们的大脑分别把文字和图像经过一系列复杂的转换对应到了某个抽象的实体,最后再经过比较决定他们是否相关。可是我们做决策一定要走完这个流程吗?
有一个著名的思想实验叫做“中文房间”:
一个对汉语一窍不通,只说英语的人关在一间只有一个开口的封闭房间中。房间里有一本用英文写成的手册,指示该如何处理收到的汉语讯息及如何以汉语相应地回复。房外的人不断向房间内递进用中文写成的问题。房内的人便按照手册的说明,查找到合适的指示,将相应的中文字符组合成对问题的解答,并将答案递出房间。
来源:维基百科
https://zh.wikipedia.org/wiki/%E4%B8%AD%E6%96%87%E6%88%BF%E9%97%B4
也就是说,要学会翻译,并不需要真正“理解”图片或者文字所对应的抽象实体。那么类似地,在识别验证码的时候无需理解真正的实体是什么,只需要按照某种规则将文字和图像对应起来就可以了: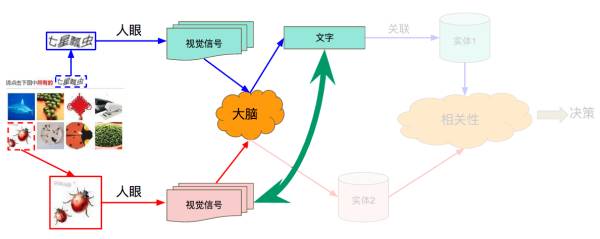
要做出正确选择,只需要通过某种标准确定文字和图片是否关联就好——这恰恰是我们可以通过之前所说图片和文字的“亲密程度”可以获取的信息。而这种标准,就是“中文房间”中的手册。
试想,如果积累足够多的验证码的统计数据,对于上图所示验证码,图片与“天鹅”文字标签一起出现的次数如下,那么做选哪几张是否就变得显而易见了?

至此,只要我们有足够多的数据,我们就可以根据统计的方法,在图片和文字之间建立关联,从而做出推测。这是不是太简单了?实际上,就是这么简单。下图是我们实验中统计的共同出现2次的几组图片,根据我们统计有大概20%~30%属于同一个类别,共同出现3次以上的图片一起出现的概率更是高达96%:

好了,说到这里,论文方法最核心、最基础的思想已经讲解完了。理论上,有足够的金钱或者资源,这个方法已经足够——像360、金山那样自己开发浏览器的公司,只要能够从用户那里采集点击数据,用这种方法破解验证码简直易如反掌。
榨干他们!
但是作为毕业设计,这样的方案是不行的,因为图库的实在是太大了,图片种类也太多了。根据估算,图库的数量应该在千万的级别,图片类别根据公开的报道来说应该有600左右——但实际上根据我们搜集的三百万张验证码来看,种类只有230种【注2】。
这意味着什么?这意味着,如果他有一百万张图片,而我们恰恰也只采集了一千万张图片的样本,那么每张图片平均只出现了十次——实际上,真实的情况是大部分图片只出现一次或者零次,少部分出现了多次——总体而言服从长尾分布,如下图所示:
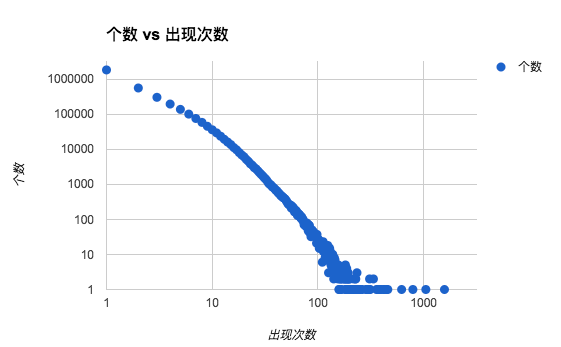
这是统计学中的一个现象,有数学证明,在这里就不做展开了。
这就导致两个问题:
成本过高。要穷尽他们所有的图库,需要数倍于他们图库的采样——因为你有可能反复得到已经出现过的图片。这其实是一个有趣的问题,跟氪金游戏中抽卡是一样的,比如阴阳师中期望要抽多少次卡才能够把所有的卡片集齐?(参考答案)。对于企业级用户来说或许尚可以承受,但对于我这种毕业设计还得自己掏腰包的人来说,每花一块钱都肉疼——何况又一次我的队友手一抖,把本地运行变成了在亚马逊服务器集群上运行,一个小时刷掉了一百多美元,我俩的研究支出就这么被迫翻倍。
理论水平太低。我可是要靠着它拿毕业证的,这么简单粗暴地搞有辱师门。
所以我们试图尽可能地压榨样本中包含的信息。在上述的内容中,我们只利用了文字与图片共同出现次数这一信息。但实际上,还有下列两个信息我们没有利用:
图片与图片共同出现的次数
图片本身所蕴含的特征(颜色、纹理等)
这两个信息都可以描述图片之间的相似度。
在之前我们已经提到过,同一类别的图片出现在一起的概率是大大超过不同类别的图片出现在一起的概率的。共同出现的频率越高,图片就越有可能属于同一类——但这也不是绝对,因为会有部分图片由于命运的安排一起出现多次的情况,但是毕竟是极少数。
这就如同见一见如故的爱情:最后在一起的叫一见钟情,没在一起的叫做一夜情——在相遇的第一天,你是很难知道到底是一见钟情还是一夜情的……
而就图片本身而言,相同种类的图片往往看上去是很相似的,比如下图所示的验证码中“荷叶”这一类的图片,往往有大面积的绿色,这就是一个显著的特征。
 当然了,这都是对人而言的相似。对计算机而言,这些图像都是一堆数字——更准确的说,是一个个向量,所以计算机可以有一个公式将这些向量转化为两个图片的相似度。关于图像、声音在计算机里的表示,改天可以另外再写一篇番外,里面也有不少有趣的话题。
当然了,这都是对人而言的相似。对计算机而言,这些图像都是一堆数字——更准确的说,是一个个向量,所以计算机可以有一个公式将这些向量转化为两个图片的相似度。关于图像、声音在计算机里的表示,改天可以另外再写一篇番外,里面也有不少有趣的话题。
有了这两个东西,我们就可以在我们第一步的基础上提高我们猜测的准确率了。怎么做呢?
首先,我之前讲了,如果他有100万张图片,你如果搜集了125万验证码,每个验证码有8张图片,这样总共你手上有1000万张图片。这1000万张图片并不是100万张每张出现10次,而是少部分出现的频率特别高,大部分出现的频率特别少。这样就分为两种情况:
对于出现次数特别多的图片,我们只需要看它跟哪个文字标签出现得最多,我们就可以认为它是属于哪一个类别的。
对于出现次数特别少的图片,因为数据太少我们没有办法确定——因为和它一起出现的文字标签可能只是偶然在一起。
出现次数多和出现次数少的图片,我们都可以用跟它一起出现次数最多的文字标签去做猜测他们的类别,但是二者对于我们的区别是——我们对猜测的信心不一样。第一种,一个图片出现了一百次,其中90次都是和文字标签“雨靴”一起出现,那么我们几乎可以肯定这个图片是雨靴。对于第二种,一个图片只出现了两次,文字标签分别是“航母”和“沙滩”,这时候我们就比较难分辨到底是航母还是沙滩了——也可能都不是。
能不能借助第一种情况我们拥有的信息来提升我们对第二种情况下猜测的准确率呢?万幸我在最后一个学期选了一门叫做Machine Learning on Large Dataset的课,刚好讲到了一个非常有用的方法:和谐领域!
开个玩笑,这种方法的英文名叫做Harmonic Field,正经的翻译应该是调谐场。大致的思想是这样的,如下图所示,
 假设图3出现了一百次,图6只出现了4次,但是图6与图3一起出现了2次,显著高于两张图一起出现的期望次数——几乎为0。这样,虽然我们不能确定图6是不是戒指,但是我对图3是戒指非常有信心,同时由于图3和图6一起出现过2次,而且视觉上特征高度相似,所以我可以认为图6也是戒指。
假设图3出现了一百次,图6只出现了4次,但是图6与图3一起出现了2次,显著高于两张图一起出现的期望次数——几乎为0。这样,虽然我们不能确定图6是不是戒指,但是我对图3是戒指非常有信心,同时由于图3和图6一起出现过2次,而且视觉上特征高度相似,所以我可以认为图6也是戒指。
仅仅靠这样的信息还不够,因为在我们手中,有大量的只共同出现一次的图片,而这些图片中的绝大部分真的是纯属偶然一起出现的——但是,也有小部分比例是真的属于同一种类并且一起出现的,这部分比例虽然不多,但是乘以基数(上千万)还是非常大的,所以我们得想办法尽可能把这部分有效信息也给榨出来。
共同出现的这个信息是用不上了,但是别忘了我们还有图片本身。比如上面的几个菠萝的图片,虽然是属于不同的图片,但是它们都有几个显著的视觉特征:圆形轮廓,粗糙的纹理,偏黄的颜色,顶上有绿叶……所以,这部分信息也可以利用起来。这些都有现成的模型可以直接拿来用,最著名的莫过于ImageNet,这个用巨大图库训练出来的模型用在这里提取特征是在是再合适不过了。下图中,左边是我们实验中所提取的视觉上高度相似的几组图片,右边是我们样本中图片相似度的分布情况,可以看出来大致是正态分布:

然后我用我想出来的一个美妙的公式(自大一下)将二者融合起来,得到一个图片之间的最终相似度,并用其作为图片之间边的权值,然后进行标签传递(Label Propagate)。
实际上,这样的方法非常奏效,将单个图片的分类成功率提高到了10%~15%
最后的堡垒
扭曲的文字是这类验证码最后的堡垒了,这也就是我说为什么Google验证码太简单的原因——它直接是网页文字呈现的,理论上可以直接复制粘贴,不需要识别,但是我们研究的这个却是扭曲的汉字图像——不能直接转换为文字。
大家在做汉字识别的思路都是想办法把文字切割开然后识别,效果不佳。其实,还有另外一种思路——把所有文字切放到一起做整体识别。毕竟根据官方说明种类最多只有600个——实际上我断断续续搜集了10个月的数据,我从中抽取并肉眼检查了一万张验证码,只有230个类别。当项目完成后我又采集了一些数据,发现了新的类别。所以我猜测可能有多组图片,会不定期更换显示图片和类别,但这只需要采集更多的数据即可解决。当然也有可能是某些类别实在是太难辨认,他们删除了。
把文字凑到一起识别有一个显而易见的好处,就是大大减少了需要分类的个数,而且不需要考虑分割的问题。
首先,文字分割就是一个难点,即便是英文字符的分割都很难,汉字本身就有偏旁部首,特别是左右结构的,常用的英文字符分割方法难以奏效,这条路是很难走通的——更何况汉字在扭曲之后往往有粘连,这更加提高了难度。
其次,在我搜集的230个类别里,类别名称有1~4个字,按平均每个类别名称有2.5个字来算,就需要有525个类别,足足增长了2.5倍。类别的增多意味着分类难度的增大和需要训练样本的增多。分类难度增加好理解,要教会宝宝10以内的加法和教会它九九乘法表,难度是不一样的。所需训练样本增多的意思是,你如果要教会宝宝分辨猫和狗,你可能只需要2张图就够了,但是你如果要教会他分辨波斯猫,加菲猫,牧羊犬和藏獒,就需要至少4张图片。
所以,把所有文字当做整体做识别是一个不错的想法,事实上效果也相当好。我们的识别程序在7000个汉字标签的测试集上达到了80%的准确率,最后的集成测试中文字标签的识别率更是达到了96%——因为最后的验证码是12月份另外采集的,我猜测之前的验证码已经经过轮转,所以有部分训练集有的数据测试集没有再出现,导致测试变“简单”了。
论文中,我们为了方便,使用了标注数据训练神经网络,也就是所谓的有监督学习。举个简单的例子,你在教宝宝把猫和狗图片分开的时候,指着猫的图片说这是猫,指着狗的图片说这是狗——这是有监督的学习;给一堆猫和狗的图片,混起来,不告诉他这些图片是啥,让宝宝自己去悟出两个不一样的种类——这是无监督的学习。
有监督学习需要大量的标记数据——标注了其真实类别的标签图片。那么数据哪里来呢?我也不知道从哪儿就发现了若快网这个神奇的网站,先来看看网站描述:
 敢情这号称世界上最先进的图片处理算法和神经网络训练系统——是人眼识别啊。而且费用特别特别便宜,我充了300人民币,加上它识别错误给的补偿,轻松搜集了几万条标注的数据。不过说实话,这个网站的识别成功率的确有97%
敢情这号称世界上最先进的图片处理算法和神经网络训练系统——是人眼识别啊。而且费用特别特别便宜,我充了300人民币,加上它识别错误给的补偿,轻松搜集了几万条标注的数据。不过说实话,这个网站的识别成功率的确有97%
至于我怎么知道错误的呢?我的做法是维护一个词表(我肉眼看10000张看出来的),不在这里面的直接报错。当然,有更好的实现方式:如果出现新词,再提交几次,如果是相同的结果,那么将其加入词表。但是我自己实现的时候发现若快对图片有缓存,如果是相同的直接返回结果,我就懒得做变化提交了——因为效果已经足够好了。
我们采用的是有监督学习(数据是标记了类别的),实际上可以采用无监督学习,做是做了,没有去认真调(没怎么调的情况下识别准确率也到了40%),否则纯无监督学习的模型会更漂亮。考虑到读者的接受水平,我把这部分讨论放到理论部分。
这样,我们成功地使用简单的神经网络结构和相对比较低的成本就搞定了汉字识别。
图片选择
通过以上步骤,在得到一个验证码的时候,我们已经可以知道其中文的标签和8张图片。然后我们就可以搜集大量的验证码,并使用之前提到的方法得到每张图属于各个类别的概率。结果大概是这样:
 那么怎么在这其中选择呢?我们目前使用的方法是固定阈(yù)值法,设定当概率高于某个阈值的时候,就选择这个图片,在一个小规模的数据集上实验并选择合适的阈值:
那么怎么在这其中选择呢?我们目前使用的方法是固定阈(yù)值法,设定当概率高于某个阈值的时候,就选择这个图片,在一个小规模的数据集上实验并选择合适的阈值:
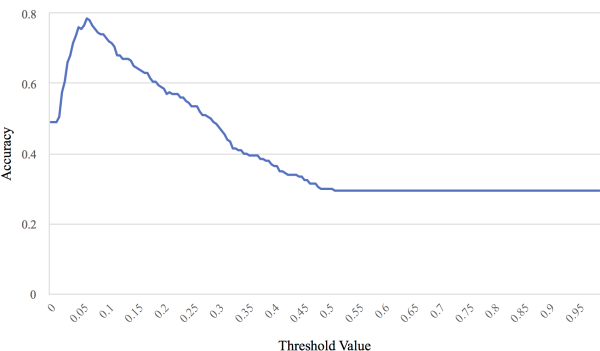 经过实验,我们的阈值取到0.065这个值的时候识别效果最好,大概78%. 当然这里其实可以用动态阈值、权值区间等,但是时间太紧,我们也就没有再去仔细调整了。
经过实验,我们的阈值取到0.065这个值的时候识别效果最好,大概78%. 当然这里其实可以用动态阈值、权值区间等,但是时间太紧,我们也就没有再去仔细调整了。
总结
彦正玛小姐这次是被实实在在看个透了。
其实,这种验证码的问题在于,以为“随机”加上足够大的数据量就万事大吉了,却没有考虑到“随机”本身也是在提供某种信息。这其实是一个很有趣的问题,如果从香农的信息论的角度来看,均匀分布的随机性是为了掩盖某种信息——这时候不确定性(熵)最大,从统计学的意义上更难攻破。然而,验证码本质上是隐含地传递某种期望只能够被人读懂信息,并让人把这种信息识别出来并且以另一种方式反馈回去,而信息的本质是能够将不确定性降低的事物,它在传递的时候是没办法抹除的——否则人肯定也识别不了。所以,即便使用了均匀分布的随机性,也必然会导致图文、图图关联等分布的非均匀随机性,从而露出破绽,这是这类验证码固有的理论缺陷。
讨论
(专业内容,可跳过)
文中提到,由于时间关系,在汉字验证码那一块我们使用了有监督学习的方法。其实,在最开始我们没有知道“若快”这个网站之前,采用的方法是模拟产生文字的方式:
 红框内是原始图片,右边都是我们生成的(干扰字符+随机横纵向正弦变换),看着是不是有一点像?这样我们就可以获取近乎无限的标记数据。在只采用我们自己生成的数据的情况下,在独立生成的测试集合上能够得到99%的准确率(见思考题3),在真实数据集上的准确率也有30%~40%
红框内是原始图片,右边都是我们生成的(干扰字符+随机横纵向正弦变换),看着是不是有一点像?这样我们就可以获取近乎无限的标记数据。在只采用我们自己生成的数据的情况下,在独立生成的测试集合上能够得到99%的准确率(见思考题3),在真实数据集上的准确率也有30%~40%
实际上,最近出来了一个比较火的对抗网络(Generative Adversarial Nets)和受限玻尔兹曼机(Restricted Boltzmann Machine),生成数据的方法比我们的要高级不少,如果用这种方法来生成训练数据我相信训练效果要更好。只是一个我理论水平不够,二个时间也不够了,有兴趣的朋友可以做一做,探讨一下。
增强措施
放弃这种验证码——经过岁月洗礼的才是最好的,扭曲的英文字母流行那么多年不是没有道理。
像Google那样增强工程难度(但要防住自研浏览器、浏览器插件好像有点难),比如最近直播网站流行的拼图型验证码就是属于这一类。
在随机的概率分布上做手脚(这并非无法破解,只不过增加了破解成本,但是破解成本一般来说比加密成本要高)
为图片增加变形、变色、旋转等技术手段(虽然能够防止我们论文中使用的感知哈希的方法,但是换一个更范化的哈希函数还是防不住,而且还增加了用户的识别难度)
花絮
注释
【1】这只是一种假设,真正的生成过程可能并不是如此。实际上,根据我们的观察,他们的生成算法甚至比均匀随机分布提供了更多的相关性信息——即便是与文字无关的图片,如果属于同一类,那么出现在同一验证码中的概率也大大高于随机的理论值。
【2】根据我们的观察,他们可能把所有图库分成了若干组,不定期轮换显示。
阅读理解
给“学有余力的同学”一些思考题:
在前面文章所举的例子中,假设每张图片被抽取的概率都是相等的,如果有10个图片的类别、每个类别有100张图片,如果有1000张验证码的文字都是“天鹅”,那么,天鹅这个类别的100张图片的出现次数应该服从什么分布,为什么?
如何通过图片总数与其中不同的图片数估算图库总数?
为什么在独立的测试集合上能够达到99%的准确率,而真实数据集上只有30%~40%?
图片中有随机噪点,如何把相同图片噪点不同的图片合并?
如何使用ImageNet的输出进行相似度的比较?如何减少这个比较的计算量?

往期经典文章回顾:
第一个被认为“科学家”的人:泰勒斯
数学思维比数学运算更重要
二十世纪的十大科学骗局
瞎扯现代数学的基础
x背后的轶闻趣事
主宰这个世界的10大算法
16个让你烧脑让你晕的悖论
机器学习中距离和相似性度量方法
传说中的快排是怎样的
玻璃秘史:一个人 改变了全世界
程序人生的四个象限和两条主线
比特币的原理及运作机制
概率论公式,你值得拥有
分类算法之朴素贝叶斯算法
采样定理:有限个点构建出整个函数









