(点击上方蓝字,快速关注我们)
编译:伯乐在线 - 小米云豆粥
如有好文章投稿,请点击 → 这里了解详情
这篇博文是用Python分析股市数据系列两部中的第一部,内容基于我犹他大学 数学3900 (数据科学)的课程。在这些博文中,我会讨论一些基础知识。比如如何用pandas从雅虎财经获得数据, 可视化股市数据,平局数指标的定义,设计移动平均交汇点分析移动平均线的方法,回溯测试, 基准分析法。最后一篇博文会包含问题以供练习。第一篇博文会包含平局数指标以及之前的内容。
注意:本文仅代表作者本人的观点。文中的内容不应该被当做经济建议。我不对文中代码负责,取用者自己负责。
引言
金融业使用高等数学和统计已经有段时日。早在八十年代以前,银行业和金融业被认为是“枯燥”的;投资银行跟商业银行是分开的,业界主要的任务是处理“简单的”(跟当今相比)的金融职能,例如贷款。里根政府的减少调控和数学的应用,使该行业从枯燥的银行业变为今天的模样。在那之后,金融跻身科学,成为推动数学研究和发展的力量。例如数学上一个重大进展是布莱克-舒尔斯公式的推导。它被用来股票定价 (一份赋予股票持有者以一定的价格从股票发行者手中买入和卖出的合同)。但是, 不好的统计模型,包括布莱克-舒尔斯模型, 背负了部分导致2008金融危机的骂名。
近年来,计算机科学加入了高等数学的阵营,为金融和证券交易(为了盈利而进行的金融产品买入卖出行为)带来了革命性的变化。如今交易主要由计算机来完成:算法能以人类难以达到的速度做出交易决策(参看光速的限制已经成为系统设计中的瓶颈)。机器学习和数据挖掘也被越来越广泛的用到金融领域中,目测这个势头会保持下去。事实上很大一部分的算法交易都是高频交易(HFT)。虽然算法比人工快,但这些技术还是很新,而且被应用在一个以不稳定,高风险著称的领域。据一条被黑客曝光的白宫相关媒体推特表明HFT应该对2010 闪电式崩盘 and a 2013 闪电式崩盘 负责。
不过这节课不是关于如何利用不好的数学模型来摧毁证券市场。相反的,我将提供一些基本的Python工具来处理和分析股市数据。我会讲到移动平均值,如何利用移动平均值来制定交易策略,如何制定进入和撤出股市的决策,记忆如何利用回溯测试来评估一个决策。
免责申明:这不是投资建议。同时我私人完全没有交易经验(文中相关的知识大部分来自我在盐湖城社区大学参加的一个学期关于股市交易的课程)!这里仅仅是基本概念知识,不足以用于实际交易的股票。股票交易可以让你受到损失(已有太多案例),你要为自己的行为负责。
获取并可视化股市数据
从雅虎金融获取数据
在分析数据之前得先得到数据。股市数据可以从Yahoo! Finance、 Google Finance以及其他的地方拿到。同时,pandas包提供了轻松从以上网站获取数据的方法。这节课我们使用雅虎金融的数据。
下面的代码展示了如何直接创建一个含有股市数据的DataFrame。(更多关于远程获取数据的信息,点击这里(http://pandas.pydata.org/pandas-docs/stable/remote_data.html))
import pandas as pd
import pandas.io.data as web # Package and modules for importing data; this code may change depending on pandas version
import datetime
# We will look at stock prices over the past year, starting at January 1, 2016
start = datetime.datetime(2016,1,1)
end = datetime.date.today()
# Let's get Apple stock data; Apple's ticker symbol is AAPL
# First argument is the series we want, second is the source ("yahoo" for Yahoo! Finance), third is the start date, fourth is the end date
apple = web.DataReader("AAPL", "yahoo", start, end)
type(apple)
C:\Anaconda3\lib\site-packages\pandas\io\data.py:35: FutureWarning:
The pandas.io.data module is moved to a separate package (pandas-datareader) and will be removed from pandas in a future version.
After installing the pandas-datareader package (https://github.com/pydata/pandas-datareader), you can change the import ``from pandas.io import data, wb`` to ``from pandas_datareader import data, wb``.
FutureWarning)
pandas.core.frame.DataFrame
apple.head()
让我们简单说一下数据内容。Open是当天的开始价格(不是前一天闭市的价格);high是股票当天的最高价;low是股票当天的最低价;close是闭市时间的股票价格。Volume指交易数量。Adjust close是根据法人行为调整之后的闭市价格。虽然股票价格基本上是由交易者决定的,stock splits (拆股。指上市公司将现有股票一拆为二,新股价格为原股的一半的行为)以及dividends(分红。每一股的分红)同样也会影响股票价格,也应该在模型中被考虑到。
可视化股市数据
获得数据之后让我们考虑将其可视化。下面我会演示如何使用matplotlib包。值得注意的是appleDataFrame对象有一个plot()方法让画图变得更简单。
import matplotlib.pyplot as plt # Import matplotlib
# This line is necessary for the plot to appear in a Jupyter notebook
%matplotlib inline
# Control the default size of figures in this Jupyter notebook
%pylab inline
pylab.rcParams['figure.figsize'] = (15, 9) # Change the size of plots
apple["Adj Close"].plot(grid = True) # Plot the adjusted closing price of AAPL
Populating the interactive namespace from numpy and matplotlib
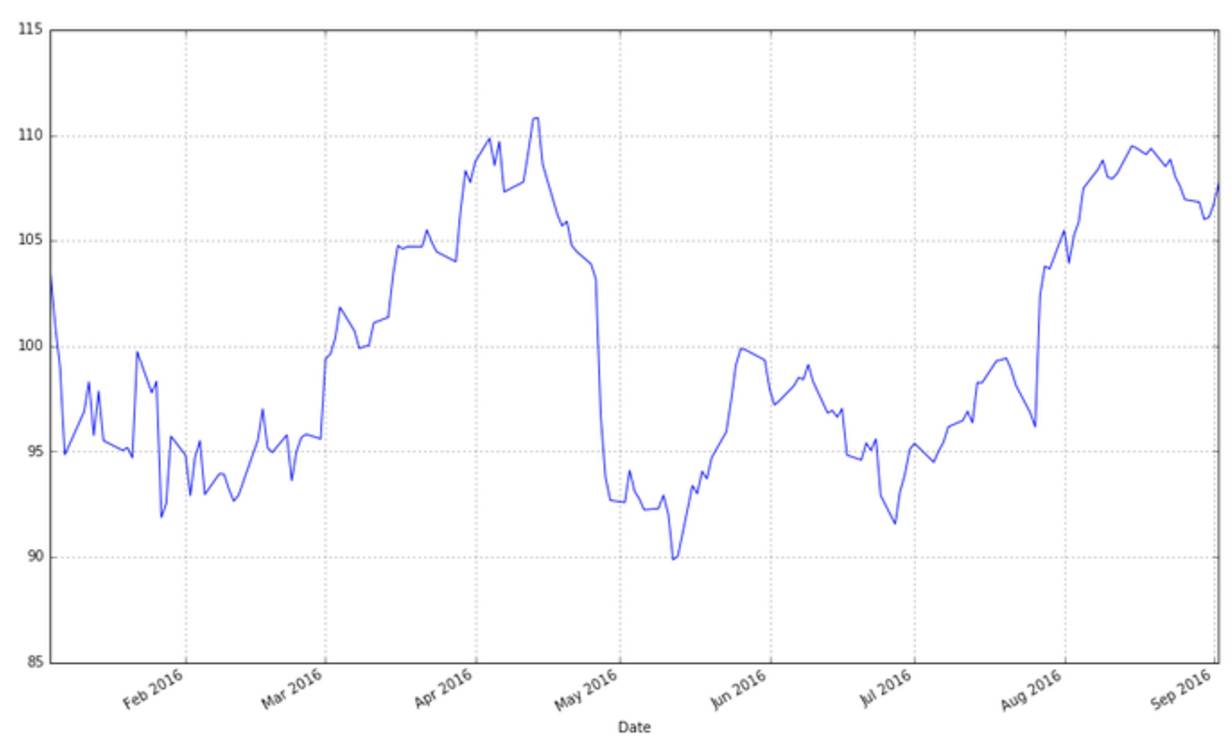
线段图是可行的,但是每一天的数据至少有四个变量(开市,股票最高价,股票最低价和闭市),我们希望找到一种不需要我们画四条不同的线就能看到这四个变量走势的可视化方法。一般来说我们使用烛柱图(也称为日本阴阳烛图表)来可视化金融数据,烛柱图最早在18世纪被日本的稻米商人所使用。可以用matplotlib来作图,但是需要费些功夫。
你们可以使用我实现的一个函数更容易地画烛柱图,它接受pandas的data frame作为数据来源。(程序基于这个例子, 你可以从这里找到相关函数的文档。)
from matplotlib.dates import DateFormatter, WeekdayLocator,\
DayLocator, MONDAY
from matplotlib.finance import candlestick_ohlc
def pandas_candlestick_ohlc(dat, stick = "day", otherseries = None):
"""
:param dat: pandas DataFrame object with datetime64 index, and float columns "Open", "High", "Low", and "Close", likely created via DataReader from "yahoo"
:param stick: A string or number indicating the period of time covered by a single candlestick. Valid string inputs include "day", "week", "month", and "year", ("day" default), and any numeric input indicates the number of trading days included in a period
:param otherseries: An iterable that will be coerced into a list, containing the columns of dat that hold other series to be plotted as lines
This will show a Japanese candlestick plot for stock data stored in dat, also plotting other series if passed.
"""
mondays = WeekdayLocator(MONDAY) # major ticks on the mondays
alldays = DayLocator() # minor ticks on the days
dayFormatter = DateFormatter('%d') # e.g., 12
# Create a new DataFrame which includes OHLC data for each period specified by stick input
transdat = dat.loc[:,["Open", "High", "Low", "Close"]]
if (type(stick) == str):
if stick == "day":
plotdat = transdat
stick = 1 # Used for plotting
elif stick in ["week", "month", "year"]:
if stick == "week":
transdat["week"] = pd.to_datetime(transdat.index).map(lambda x: x.isocalendar()[1]) # Identify weeks
elif stick == "month":
transdat["month"] = pd.to_datetime(transdat.index).map(lambda x: x.month) # Identify months
transdat["year"] = pd.to_datetime(transdat.index).map(lambda x: x.isocalendar()[0]) # Identify years
grouped = transdat.groupby(list(set(["year",stick]))) # Group by year and other appropriate variable
plotdat = pd.DataFrame({"Open": [], "High": [], "Low": [], "Close": []}) # Create empty data frame containing what will be plotted
for name, group in grouped:
plotdat = plotdat.append(pd.DataFrame({"Open": group.iloc[0,0],
"High": max(group.High),
"Low": min(group.Low),
"Close": group.iloc[-1,3]},
index = [group.index[0]]))
if stick == "week": stick = 5
elif stick == "month": stick = 30
elif stick == "year": stick = 365
elif (type(stick) == int and stick >= 1):
transdat["stick"] = [np.floor(i / stick) for i in range(len(transdat.index))]
grouped = transdat.groupby("stick")
plotdat = pd.DataFrame({"Open": [], "High": [], "Low": [], "Close": []}) # Create empty data frame containing what will be plotted
for name, group in grouped:
plotdat = plotdat.append(pd.DataFrame({"Open": group.iloc[0,0],
"High": max(group.High),
"Low": min(group.Low),
"Close": group.iloc[-1,3]},
index = [group.index[0]]))
else:
raise ValueError('Valid inputs to argument "stick" include the strings "day", "week", "month", "year", or a positive integer')
# Set plot parameters, including the axis object ax used for plotting
fig, ax = plt.subplots()
fig.subplots_adjust(bottom=0.2)
if plotdat.index[-1] - plotdat.index[0] < pd.Timedelta('730 days'):
weekFormatter = DateFormatter('%b %d') # e.g., Jan 12
ax.xaxis.set_major_locator(mondays)
ax.xaxis.set_minor_locator(alldays)
else:
weekFormatter = DateFormatter('%b %d, %Y')
ax.xaxis.set_major_formatter(weekFormatter)
ax.grid(True)
# Create the candelstick chart
candlestick_ohlc(ax, list(zip(list(date2num(plotdat.index.tolist())), plotdat["Open"].tolist(), plotdat["High"].tolist(),
plotdat["Low"].tolist(), plotdat["Close"].tolist())),
colorup = "black", colordown = "red", width = stick * .4)
# Plot other series (such as moving averages) as lines
if otherseries != None:
if type(otherseries) != list:
otherseries = [otherseries]
dat.loc[:,otherseries].plot(ax = ax, lw = 1.3, grid = True)
ax.xaxis_date()
ax.autoscale_view()
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
plt.show()
pandas_candlestick_ohlc(apple)
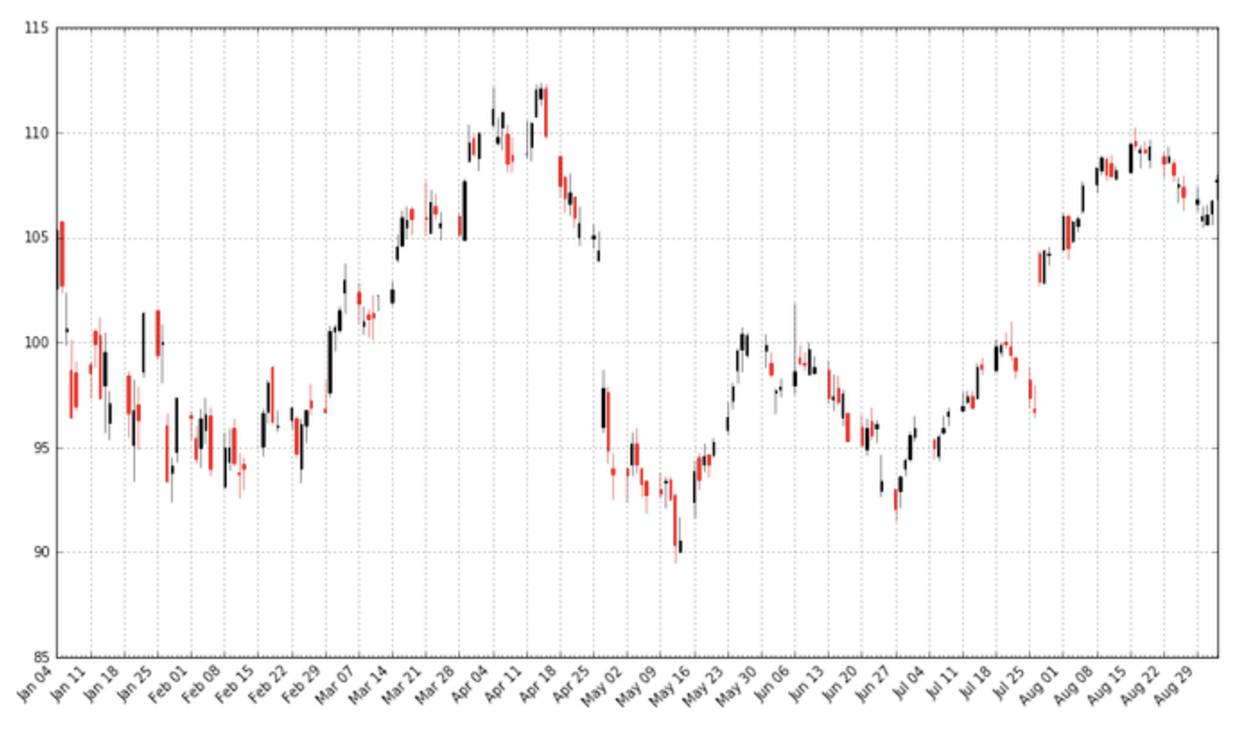
烛状图中黑色线条代表该交易日闭市价格高于开市价格(盈利),红色线条代表该交易日开市价格高于闭市价格(亏损)。刻度线代表当天交易的最高价和最低价(影线用来指明烛身的哪端是开市,哪端是闭市)。烛状图在金融和技术分析中被广泛使用在交易决策上,利用烛身的形状,颜色和位置。我今天不会涉及到策略。
我们也许想要把不同的金融商品呈现在一张图上:这样我们可以比较不同的股票,比较股票跟市场的关系,或者可以看其他证券,例如交易所交易基金(ETFs)。在后面的内容中,我们将会学到如何画金融证券跟一些指数(移动平均)的关系。届时你需要使用线段图而不是烛状图。(试想你如何重叠不同的烛状图而让图表保持整洁?)
下面我展示了不同技术公司股票的数据,以及如何调整数据让数据线聚在一起。
microsoft = web.DataReader("MSFT", "yahoo", start, end)
google = web.DataReader("GOOG", "yahoo", start, end)
# Below I create a DataFrame consisting of the adjusted closing price of these stocks, first by making a list of these objects and using the join method
stocks = pd.DataFrame({"AAPL": apple["Adj Close"],
"MSFT": microsoft["Adj Close"],
"GOOG": google["Adj Close"]})
stocks.head()
stocks.plot(grid = True)
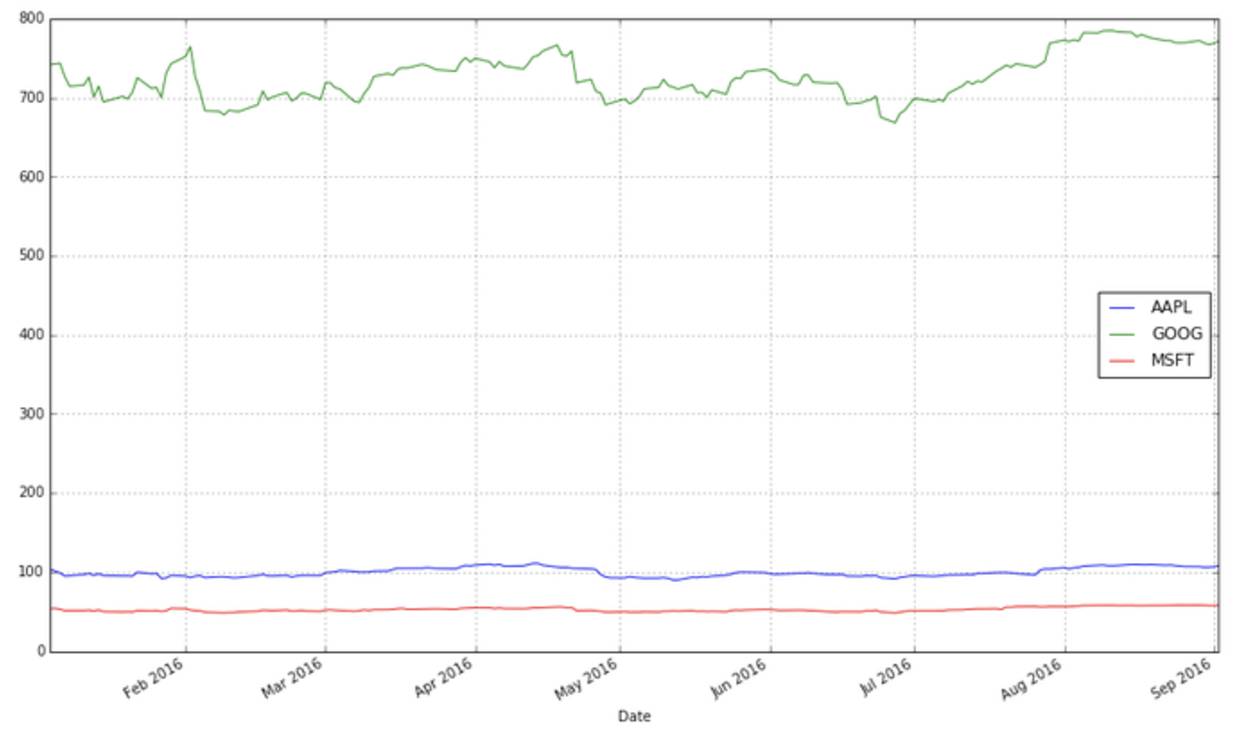
这张图表的问题在哪里呢?虽然价格的绝对值很重要(昂贵的股票很难购得,这不仅会影响它们的波动性,也会影响你交易它们的难易度),但是在交易中,我们更关注每支股票价格的变化而不是它的价格。Google的股票价格比苹果微软的都高,这个差别让苹果和微软的股票显得波动性很低,而事实并不是那样。
一个解决办法就是用两个不同的标度来作图。一个标度用于苹果和微软的数据;另一个标度用来表示Google的数据。
stocks.plot(secondary_y = ["AAPL", "MSFT"], grid = True)
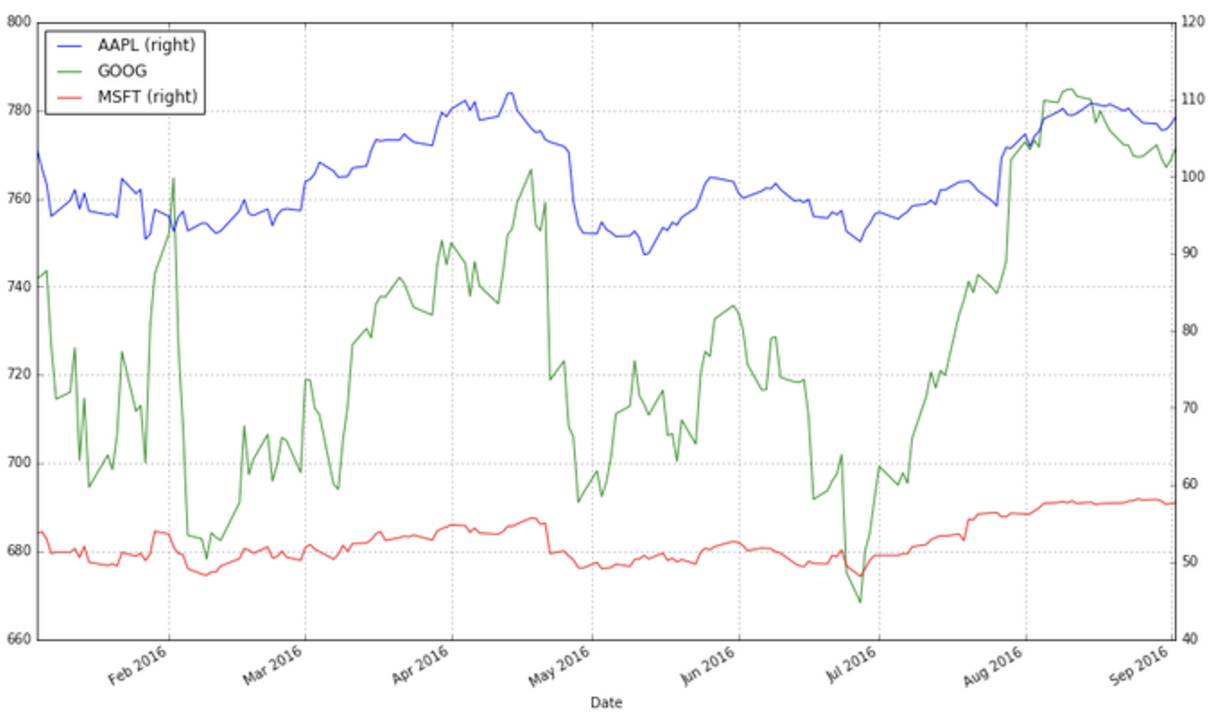
一个“更好”的解决方法是可视化我们实际关心的信息:股票的收益。这需要我们进行必要的数据转化。数据转化的方法很多。其中一个转化方法是将每个交易日的股票交个跟比较我们所关心的时间段开始的股票价格相比较。也就是:
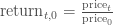
这需要转化stock对象中的数据,操作如下:
# df.apply(arg) will apply the function arg to each column in df, and return a DataFrame with the result
# Recall that lambda x is an anonymous function accepting parameter x; in this case, x will be a pandas Series object
stock_return = stocks.apply(lambda x: x / x[0])
stock_return.head()
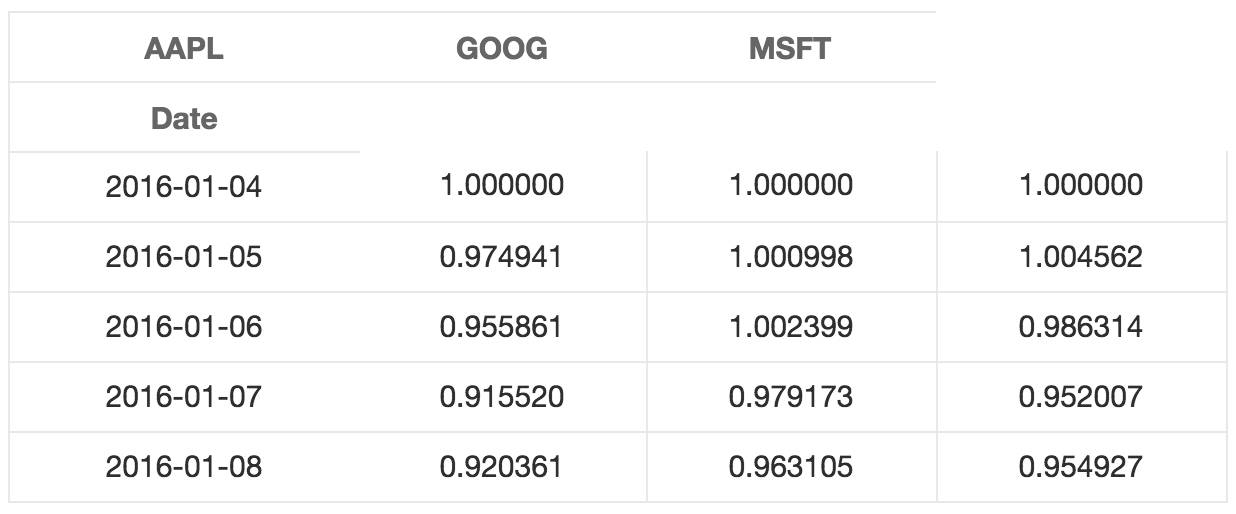
stock_return.plot(grid = True).axhline(y = 1, color = "black", lw = 2)

这个图就有用多了。现在我们可以看到从我们所关心的日期算起,每支股票的收益有多高。而且我们可以看到这些股票之间的相关性很高。它们基本上朝同一个方向移动,在其他类型的图表中很难观察到这一现象。
我们还可以用每天的股值变化作图。一个可行的方法是我们使用后一天$t + 1$和当天$t$的股值变化占当天股价的比例:
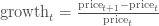
我们也可以比较当天跟前一天的价格:
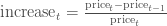
以上的公式并不相同,可能会让我们得到不同的结论,但是我们可以使用对数差异来表示股票价格变化:
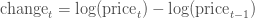
(这里的
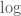
是自然对数,我们的定义不完全取决于使用
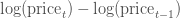
还是
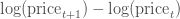
.) 使用对数差异的好处是该差异值可以被解释为股票的百分比差异,但是不受分母的影响。
下面的代码演示了如何计算和可视化股票的对数差异:
# Let's use NumPy's log function, though math's log function would work just as well
import numpy as np
stock_change = stocks.apply(lambda x: np.log(x) - np.log(x.shift(1))) # shift moves dates back by 1.
stock_change.head()
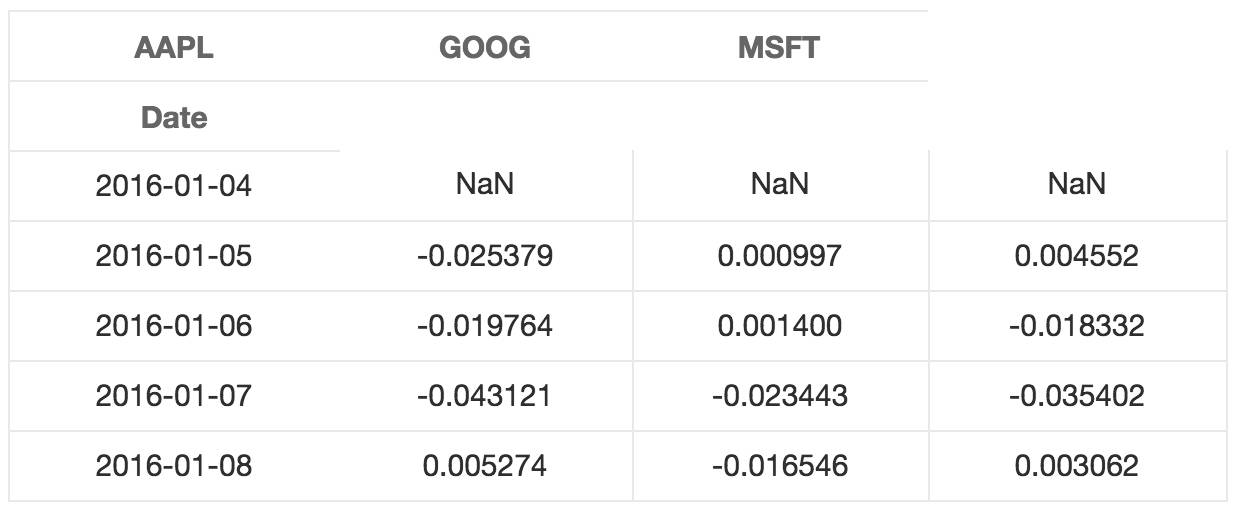
stock_change.plot(grid = True).axhline(y = 0, color = "black", lw = 2)
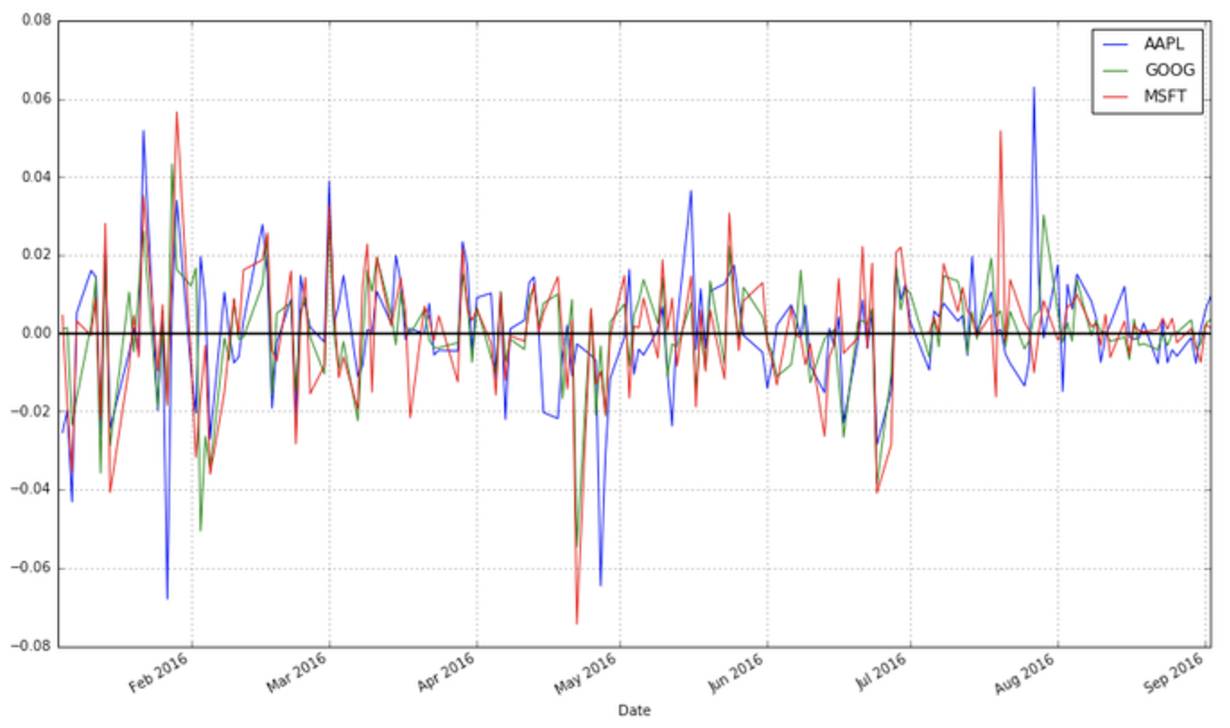
你更倾向于哪种转换方法呢?从相对时间段开始日的收益差距可以明显看出不同证券的总体走势。不同交易日之间的差距被用于更多预测股市行情的方法中,它们是不容被忽视的。
移动平均值
图表非常有用。在现实生活中,有些交易人在做决策的时候几乎完全基于图表(这些人是“技术人员”,从图表中找到规律并制定交易策略被称作技术分析,它是交易的基本教义之一。)下面让我们来看看如何找到股票价格的变化趋势。
一个q天的移动平均值(用
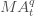
来表示)定义为:对于某一个时间点t,它之前q天的平均值。
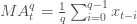
移动平均值可以让一个系列的数据变得更平滑,有助于我们找到趋势。q值越大,移动平均对短期的波动越不敏感。移动平均的基本目的就是从噪音中识别趋势。快速的移动平均有偏小的q,它们更接近股票价格;而慢速的移动平均有较大的q值,这使得它们对波动不敏感从而更加稳定。
pandas提供了计算移动平均的函数。下面我将演示使用这个函数来计算苹果公司股票价格的20天(一个月)移动平均值,并将它跟股票价格画在一起。
apple["20d"] = np.round(apple["Close"].rolling(window = 20, center = False).mean(), 2)
pandas_candlestick_ohlc(apple.loc['2016-01-04':'2016-08-07',:], otherseries = "20d")
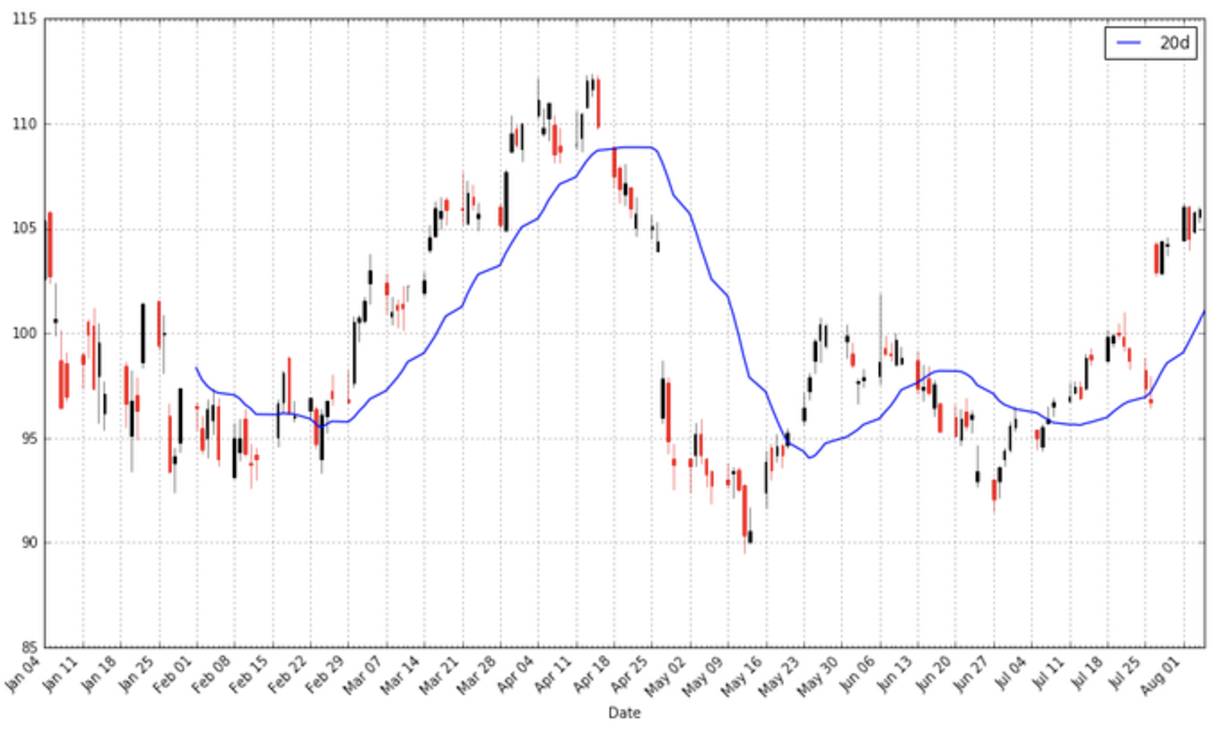
注意到平均值的起始点时间是很迟的。我们必须等到20天之后才能开始计算该值。这个问题对于更长时间段的移动平均来说是个更加严重的问题。因为我希望我可以计算200天的移动平均,我将扩展我们所得到的苹果公司股票的数据,但我们主要还是只关注2016。
start = datetime.datetime(2010,1,1)
apple = web.DataReader("AAPL", "yahoo", start, end)
apple["20d"] = np.round(apple["Close"].rolling(window = 20, center = False).mean(), 2)
pandas_candlestick_ohlc(apple.loc['2016-01-04':'2016-08-07',:], otherseries = "20d")
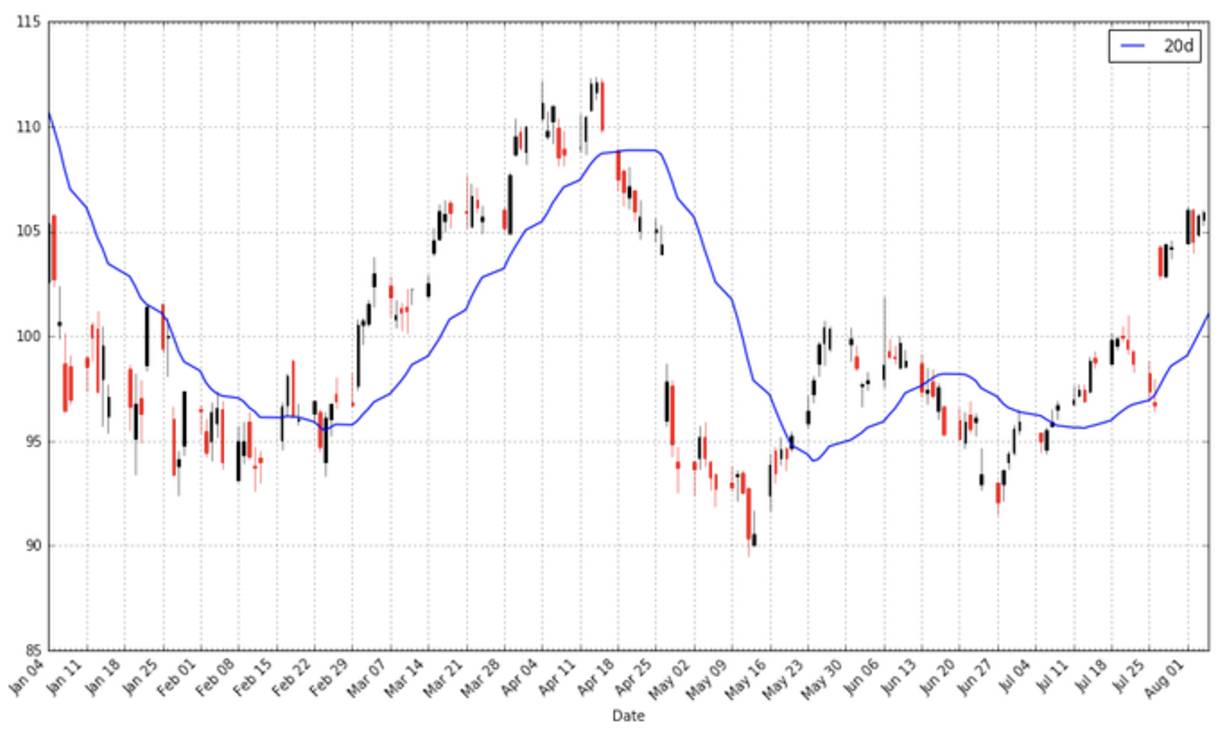
你会发现移动平均比真实的股票价格数据平滑很多。而且这个指数是非常难改变的:一支股票的价格需要变到平局值之上或之下才能改变移动平均线的方向。因此平均线的交叉点代表了潜在的趋势变化,需要加以注意。
交易者往往对不同的移动平均感兴趣,例如20天,50天和200天。要同时生成多条移动平均线也不难:
apple["50d"] = np.round(apple["Close"].rolling(window = 50, center = False).mean(), 2)
apple["200d"] = np.round(apple["Close"].rolling(window = 200, center = False).mean(), 2)
pandas_candlestick_ohlc(apple.loc['2016-01-04':'2016-08-07',:], otherseries = ["20d", "50d", "200d"])

20天的移动平均线对小的变化非常敏感,而200天的移动平均线波动最小。这里的200天平均线显示出来总体的熊市趋势:股值总体来说一直在下降。20天移动平均线所代表的信息是熊市牛市交替,接下来有可能是牛市。这些平均线的交叉点就是交易信息点,它们代表股票价格的趋势会有所改变因而你需要作出能盈利的相应决策。
更新:该文章早期版本提到算法交易跟高频交易是一个意思。但是网友评论指出这并不一定:算法可以用来进行交易但不一定就是高频。高频交易是算法交易中间很大的一部分,但是两者不等价。
看完本文有收获?请转发分享给更多人
关注「Python开发者」,提升Python技能











