1. Ceph架构简介及使用场景介绍
1.1 Ceph简介
Ceph是一个统一的分布式存储系统,设计初衷是提供较好的性能、可靠性和可扩展性。
Ceph项目最早起源于Sage就读博士期间的工作(最早的成果于2004年发表),并随后贡献给开源社区。在经过了数年的发展之后,目前已得到众多云计算厂商的支持并被广泛应用。RedHat及OpenStack都可与Ceph整合以支持虚拟机镜像的后端存储。
1.2 Ceph特点
1.3 Ceph架构
支持三种接口:
1.4 Ceph核心组件及概念介绍
1.5 三种存储类型-块存储

rbd
典型设备
: 磁盘阵列,硬盘
主要是将裸磁盘空间映射给主机使用的。
优点
:
-
通过Raid与LVM等手段,对数据提供了保护。
-
多块廉价的硬盘组合起来,提高容量。
-
多块磁盘组合出来的逻辑盘,提升读写效率。
缺点
:
-
采用SAN架构组网时,光纤交换机,造价成本高。
-
主机之间无法共享数据。
使用场景
:
-
docker容器、虚拟机磁盘存储分配。
-
日志存储。
-
文件存储。
-
…
1.6 三种存储类型-文件存储

fs
典型设备
: FTP、NFS服务器
为了克服块存储文件无法共享的问题,所以有了文件存储。
在服务器上架设FTP与NFS服务,就是文件存储。
优点
:
缺点
:
使用场景
:
1.7 三种存储类型-对象存储
rgw
典型设备
: 内置大容量硬盘的分布式服务器(swift, s3)
多台服务器内置大容量硬盘,安装上对象存储管理软件,对外提供读写访问功能。
优点
:
-
具备块存储的读写高速。
-
具备文件存储的共享等特性。
使用场景
: (适合更新变动较少的数据)
2. Ceph IO流程及数据分布

rados_io_1
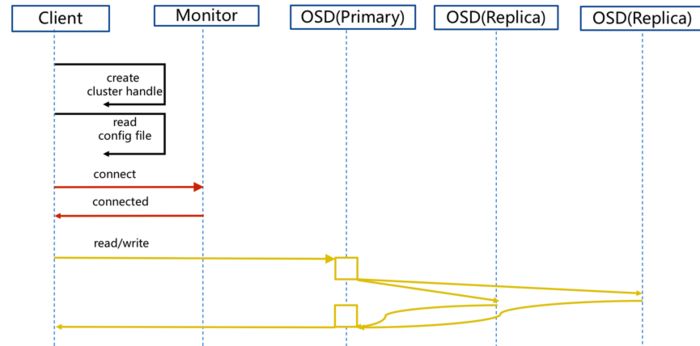
2.1 正常IO流程图
ceph_io_2
步骤
:
1. client 创建cluster handler。
2. client 读取配置文件。
3. client 连接上monitor,获取集群map信息。
4. client 读写io 根据crshmap 算法请求对应的主osd数据节点。
5. 主osd数据节点同时写入另外两个副本节点数据。
6. 等待主节点以及另外两个副本节点写完数据状态。
7. 主节点及副本节点写入状态都成功后,返回给client,io写入完成。
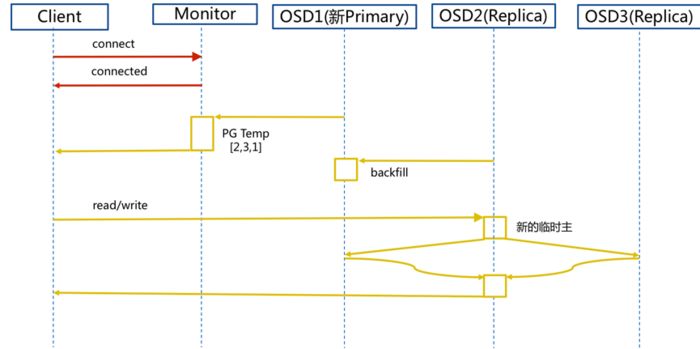
2.2 新主IO流程图
说明
:
如果新加入的OSD1取代了原有的 OSD4成为 Primary OSD, 由于 OSD1 上未创建 PG , 不存在数据,那么 PG 上的 I/O 无法进行,怎样工作的呢?
ceph_io_3
步骤
:
1. client连接monitor获取集群map信息。
2. 同时新主osd1由于没有pg数据会主动上报monitor告知让osd2临时接替为主。
3. 临时主osd2会把数据全量同步给新主osd1。
4. client IO读写直接连接临时主osd2进行读写。
5. osd2收到读写io,同时写入另外两副本节点。
6. 等待osd2以及另外两副本写入成功。
7. osd2三份数据都写入成功返回给client, 此时client io读写完毕。
8. 如果osd1数据同步完毕,临时主osd2会交出主角色。
9. osd1成为主节点,osd2变成副本。
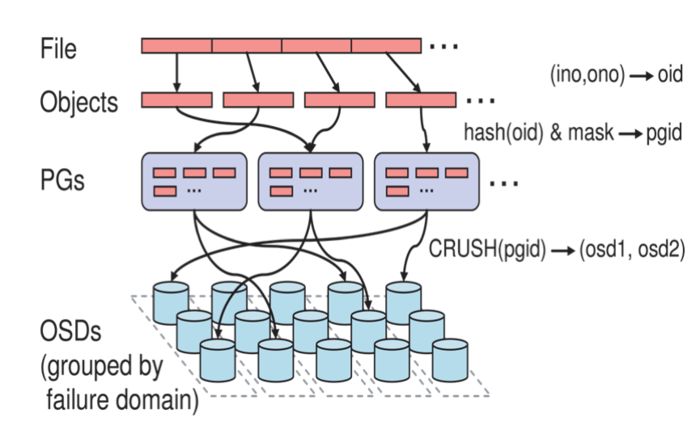
2.3 Ceph IO算法流程
ceph_io_4
1. File用户需要读写的文件。File->Object映射:
a. ino (File的元数据,File的唯一id)。
b. ono(File切分产生的某个object的序号,默认以4M切分一个块大小)。
c. oid(object id: ino + ono)。
2. Object是RADOS需要的对象。Ceph指定一个静态hash函数计算oid的值,将oid映射成一个近似均匀分布的伪随机值,然后和mask按位相与,得到pgid。Object->PG映射:
a. hash(oid) & mask-> pgid 。
b. mask = PG总数m(m为2的整数幂)-1 。
3. PG(Placement Group),用途是对object的存储进行组织和位置映射, (类似于redis cluster里面的slot的概念) 一个PG里面会有很多object。采用CRUSH算法,将pgid代入其中,然后得到一组OSD。PG->OSD映射:
a. CRUSH(pgid)->(osd1,osd2,osd3) 。
2.4 Ceph IO伪代码流程
locator = object_name
obj_hash = hash(locator)
pg = obj_hash % num_pg
osds_for_pg = crush(pg)
replicas = osds_for_pg[1:]
2.5 Ceph RBD IO流程
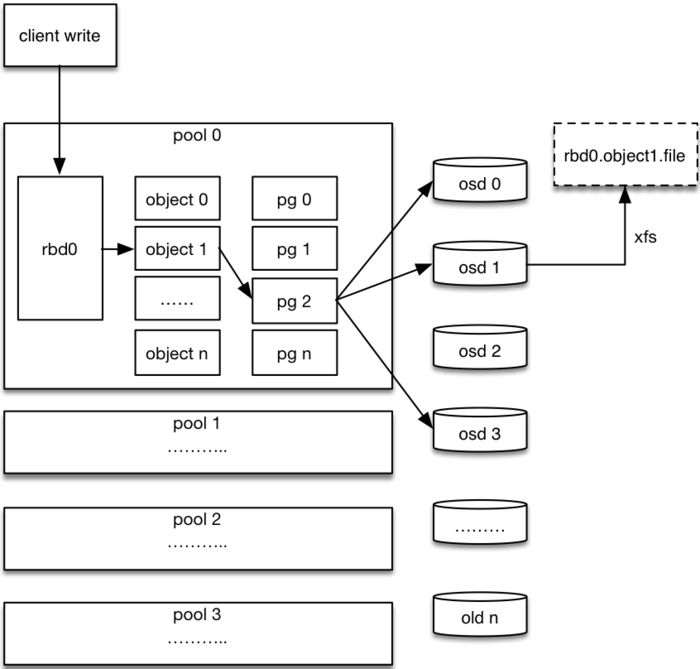
ceph_rbd_io
步骤
:
1. 客户端创建一个pool,需要为这个pool指定pg的数量。
2. 创建pool/image rbd设备进行挂载。
3. 用户写入的数据进行切块,每个块的大小默认为4M,并且每个块都有一个名字,名字就是object+序号。
4. 将每个object通过pg进行副本位置的分配。
5. pg根据cursh算法会寻找3个osd,把这个object分别保存在这三个osd上。
6. osd上实际是把底层的disk进行了格式化操作,一般部署工具会将它格式化为xfs文件系统。
7. object的存储就变成了存储一个文rbd0.object1.file。
2.6 Ceph RBD IO框架图
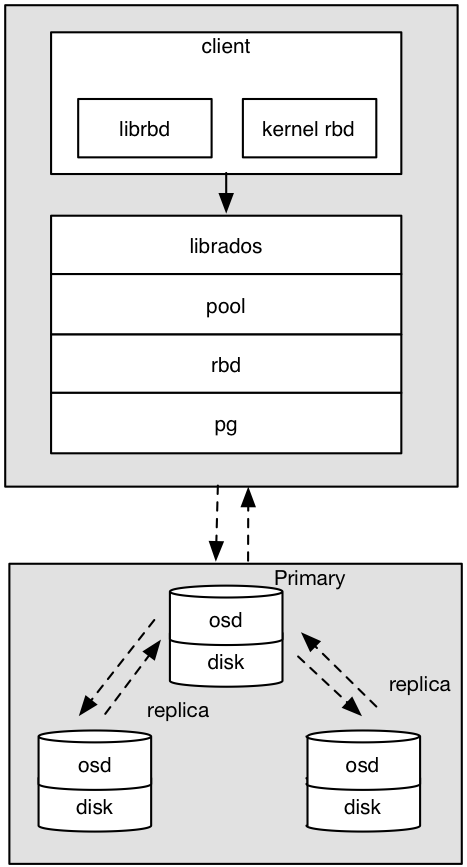
ceph_rbd_io1
客户端写数据osd过程
:
1. 采用的是librbd的形式,使用librbd创建一个块设备,向这个块设备中写入数据。
2. 在客户端本地同过调用librados接口,然后经过pool,rbd,object、pg进行层层映射,在PG这一层中,可以知道数据保存在哪3个OSD上,这3个OSD分为主从的关系。
3. 客户端与primay OSD建立SOCKET 通信,将要写入的数据传给primary OSD,由primary OSD再将数据发送给其他replica OSD数据节点。
2.7 Ceph Pool和PG分布情况
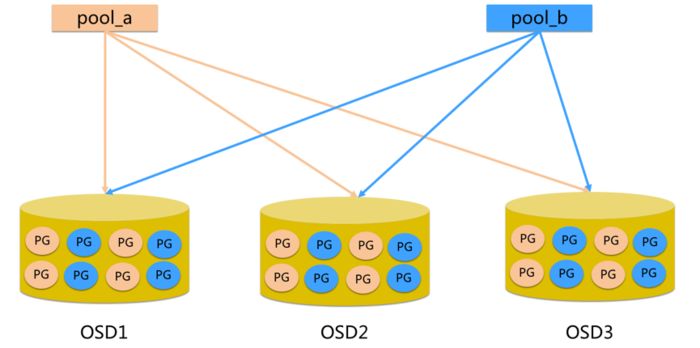
ceph_pool_pg
说明
:
2.8 Ceph 数据扩容PG分布
场景数据迁移流程
:
-
现状3个OSD, 4个PG
-
扩容到4个OSD, 4个PG
现状
:

ceph_recory_1
扩容后
:

ceph_io_recry2
说明
每个OSD上分布很多PG, 并且每个PG会自动散落在不同的OSD上。如果扩容那么相应的PG会进行迁移到新的OSD上,保证PG数量的均衡。
3. Ceph心跳机制
3.1 心跳介绍
心跳是用于节点间检测对方是否故障的,以便及时发现故障节点进入相应的故障处理流程。
问题
:
故障检测策略应该能够做到
:
3.2 Ceph 心跳检测
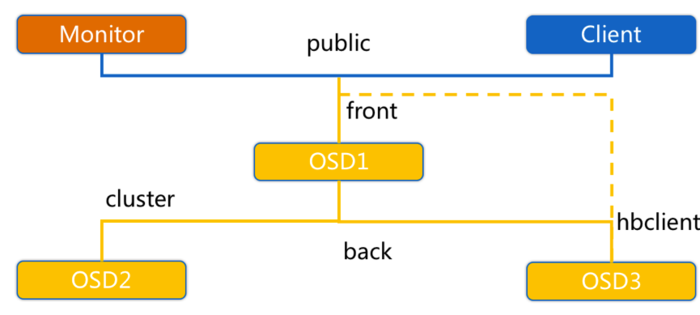
ceph_heartbeat_1
OSD节点会监听public、cluster、front和back四个端口
-
public端口:监听来自Monitor和Client的连接。
-
cluster端口:监听来自OSD Peer的连接。
-
front端口:供客户端连接集群使用的网卡, 这里临时给集群内部之间进行心跳。
-
back端口:供客集群内部使用的网卡。集群内部之间进行心跳。
-
hbclient:发送ping心跳的messenger。
3.3 Ceph OSD之间相互心跳检测
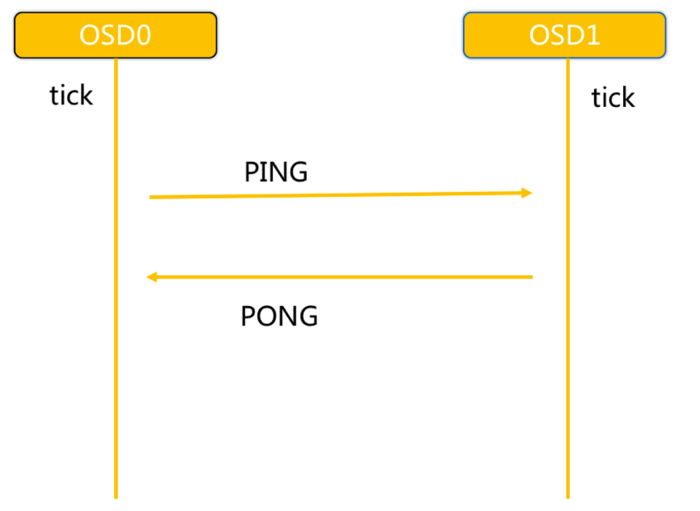
ceph_heartbeat_osd
步骤
:
-
同一个PG内OSD互相心跳,他们互相发送PING/PONG信息。
-
每隔6s检测一次(实际会在这个基础上加一个随机时间来避免峰值)。
-
20s没有检测到心跳回复,加入failure队列。
3.4 Ceph OSD与Mon心跳检测
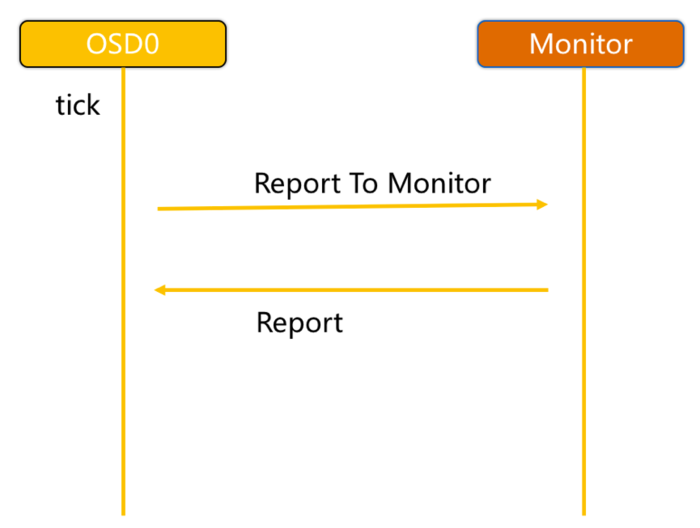
ceph_heartbeat_mon
OSD报告给Monitor:
-
OSD有事件发生时(比如故障、PG变更)。
-
自身启动5秒内。
-
OSD周期性的上报给Monito
-
OSD检查failure_queue中的伙伴OSD失败信息。
-
向Monitor发送失效报告,并将失败信息加入failure_pending队列,然后将其从failure_queue移除。
-
收到来自failure_queue或者failure_pending中的OSD的心跳时,将其从两个队列中移除,并告知Monitor取消之前的失效报告。
-
当发生与Monitor网络重连时,会将failure_pending中的错误报告加回到failure_queue中,并再次发送给Monitor。
-
Monitor统计下线OSD
3.5 Ceph心跳检测总结
Ceph通过伙伴OSD汇报失效节点和Monitor统计来自OSD的心跳两种方式判定OSD节点失效。
4. Ceph通信框架
4.1 Ceph通信框架种类介绍
网络通信框架三种不同的实现方式:
-
Simple线程模式
特点:每一个网络链接,都会创建两个线程,一个用于接收,一个用于发送。
缺点:大量的链接会产生大量的线程,会消耗CPU资源,影响性能。
-
Async事件的I/O多路复用模式
特点:这种是目前网络通信中广泛采用的方式。k版默认已经使用Asnyc了。
-
XIO方式使用了开源的网络通信库accelio来实现
特点:这种方式需要依赖第三方的库accelio稳定性,目前处于试验阶段。
4.2 Ceph通信框架设计模式
设计模式(Subscribe/Publish
):
订阅发布模式又名观察者模式,它意图是“定义对象间的一种一对多的依赖关系,
当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新”。
4.3 Ceph通信框架流程图
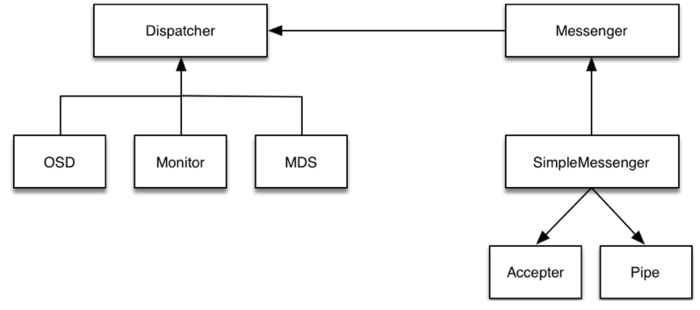
ceph_message
步骤
:
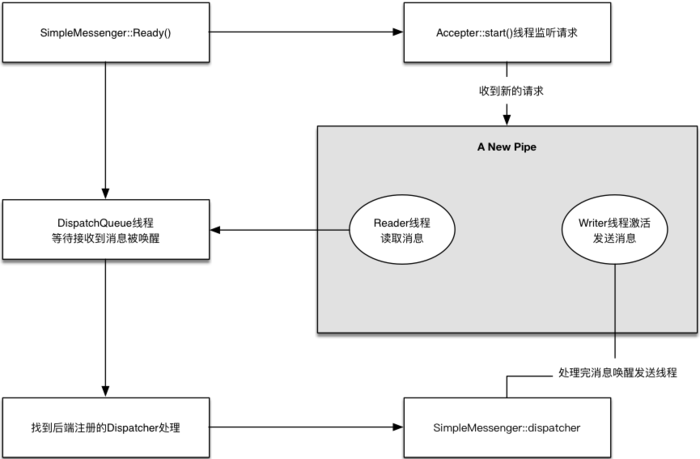
ceph_message_2
4.4 Ceph通信框架类图
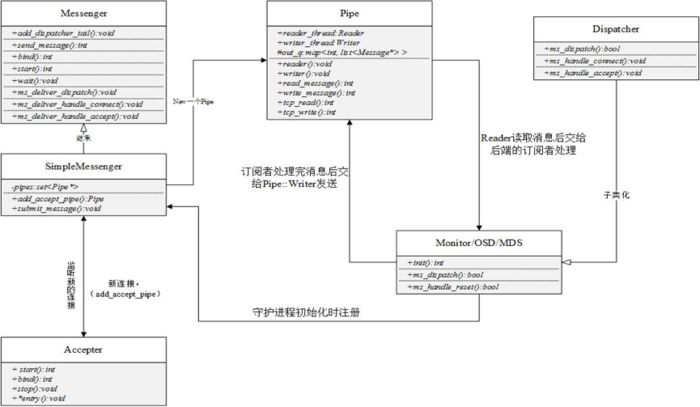
ceph_message_3
4.5 Ceph通信数据格式
通信协议格式需要双方约定数据格式。
消息的内容主要分为三部分:
-
header //消息头,类型消息的信封
-
user data //需要发送的实际数据
-
payload //操作保存元数据
-
middle //预留字段
-
data //读写数据
-
footer //消息的结束标记
class Message : public RefCountedObject {
protected:
ceph_msg_header header;
ceph_msg_footer footer;
bufferlist payload;
bufferlist middle;
bufferlist data;
utime_t recv_stamp;
utime_t dispatch_stamp;
utime_t throttle_stamp;
utime_t recv_complete_stamp;
ConnectionRef connection;
uint32_t magic = 0;
bi::list_member_hook<> dispatch_q;
};
struct ceph_msg_header {
__le64 seq;
__le64 tid;
__le16 type;
__le16 priority;
__le16 version;
__le32 front_len;
__le32 middle_len;
__le32 data_len;
__le16 data_off;
struct ceph_entity_name src;
__le16 compat_version;
__le16 reserved;
__le32 crc;
} __attribute__ ((packed));
struct ceph_msg_footer {
__le32 front_crc, middle_crc, data_crc;
__le64 sig;
__u8 flags;
} __attribute__ ((packed));
5. Ceph CRUSH算法
5.1 数据分布算法挑战
5.2 Ceph CRUSH算法说明
5.3 Ceph CRUSH算法原理
CRUSH算法因子:
5.3.1 层级化的Cluster Map
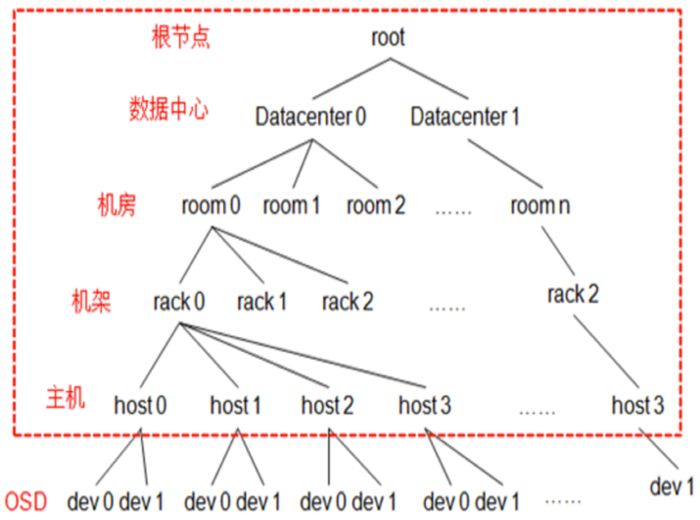
ceph_crush
CRUSH Map是一个树形结构,OSDMap更多记录的是OSDMap的属性(epoch/fsid/pool信息以及osd的ip等等)。
叶子节点是device(也就是osd),其他的节点称为bucket节点,这些bucket都是虚构的节点,可以根据物理结构进行抽象,当然树形结构只有一个最终的根节点称之为root节点,中间虚拟的bucket节点可以是数据中心抽象、机房抽象、机架抽象、主机抽象等。
5.3.2 数据分布策略Placement Rules
数据分布策略Placement Rules主要有特点
:
a. 从CRUSH Map中的哪个节点开始查找
b. 使用那个节点作为故障隔离域
c. 定位副本的搜索模式(广度优先 or 深度优先)








