
前言
在刚结束的深圳 GOPS 2017 全球运维大会上,来自 JFrog 的全球研发副总裁 Jagan Subramanian 发表了演讲。

Jagan 之前在甲骨文供职了16年,担任高级研发总监。由于之前甲骨文收购了很多公司,这些新的团队使用不同的语言开发,不同的仓库存储自研件,并且各种维护不同的上线流程,导致公司内部的软件交付流程非常混乱。同时随着软件微服务架构的落地,团队产生的包越来越多,团队之间很难协作。
为了解决这些痛点,在2013年,Jagan 开始负责开发甲骨文内部持续交付的 PaaS 平台,名叫 Carson,目的是为公司内部所有的开发团队提供统一的,自助式的持续交付平台。
在底层 DevOps 工具的选择上,为了满足团队开发语言多样化,需要统一,自助式软件交付流水线的管理,跨团队之间协同构建,发布等需求, Jagan 比较了很很多工具,最终选择了 Artifactory 和 Jenkins/Hudson 作为底层的工具,在上层开发了 Carson,实现了统一,自助式持续交付的平台。目前这个平台已经为甲骨文内部几万个开发者使用,为公司管理了1亿多个软件包。
Jagan 成功主导了甲骨文中间件,数据库等产品线的 DevOps 变革。如果您也想成为公司内部推动DevOps的领袖,就来参考下 Jagan 经验!
1、甲骨文的痛点
Stack Build 构建耗时很长。
Stack Build 是指的 A 构建时依赖 B,B 构建时依赖 C,导致在重复 Stack Build 时,需要花费大量的时间。
同一个依赖包有多个版本被引用。
举例:团队 A 开发了一个共用包,比如是解析 MQ 消息通用服务 common.jar V1.0。B 和 C 团队都引用了,一个月后 A 团队升级了,B 引用了common.jar V1.1,但 C 没有升级,在集成 A,B,C 的服务时,这个通用服务被引入了common.jar 的两个版本。
调用内部接口。
举例:当团队A,急需获得团队 B的数据, A 虽然知道不应该直接调用 B 的内部方法,但 A还是会要求 B 提供一个内部方法,等 B 定义好了外部接口,A 再来改代码调用外部接口。但实际情况是 A 完成了功能交付了代码之后,再也不会做重构。这样就导致了 A 和 B 模块直接的紧耦合。
依赖关系混乱。
当某个中间件需要重构,他并不知道公司内部哪些产品会被影响到,因为每个人看起来都会被影响。
开发者的环境通常和生产环境不一致。
举例:开发者在本地测试没问题,放到客户环境或者线上环境就出问题。
缺乏透明度,可视化。
团队中每个人都看不到当前的流程,没法评估当前流程有什么可以改进的地方。例如缺乏每次构建的时间,测试覆盖率,测试通过率,上线成功率,发布周期等指标的统计,导致。
传统的工具难以适配新的技术。
例如 C/C++ 的依赖管理就是个很大的痛点,由于 C/C++ 的编译依赖不能跨平台,它依赖与编译工具 cmake 或者 gcc,也依赖与芯片架构,所有缺少一个类似于 Maven 的依赖管理工具来管理所有的包。
实现云化。
在申请计算,存储,网络资源时,依赖于硬件,没有实现虚拟化,按需创建,消费资源。
2、Jagan在甲骨文推进DevOps的方法
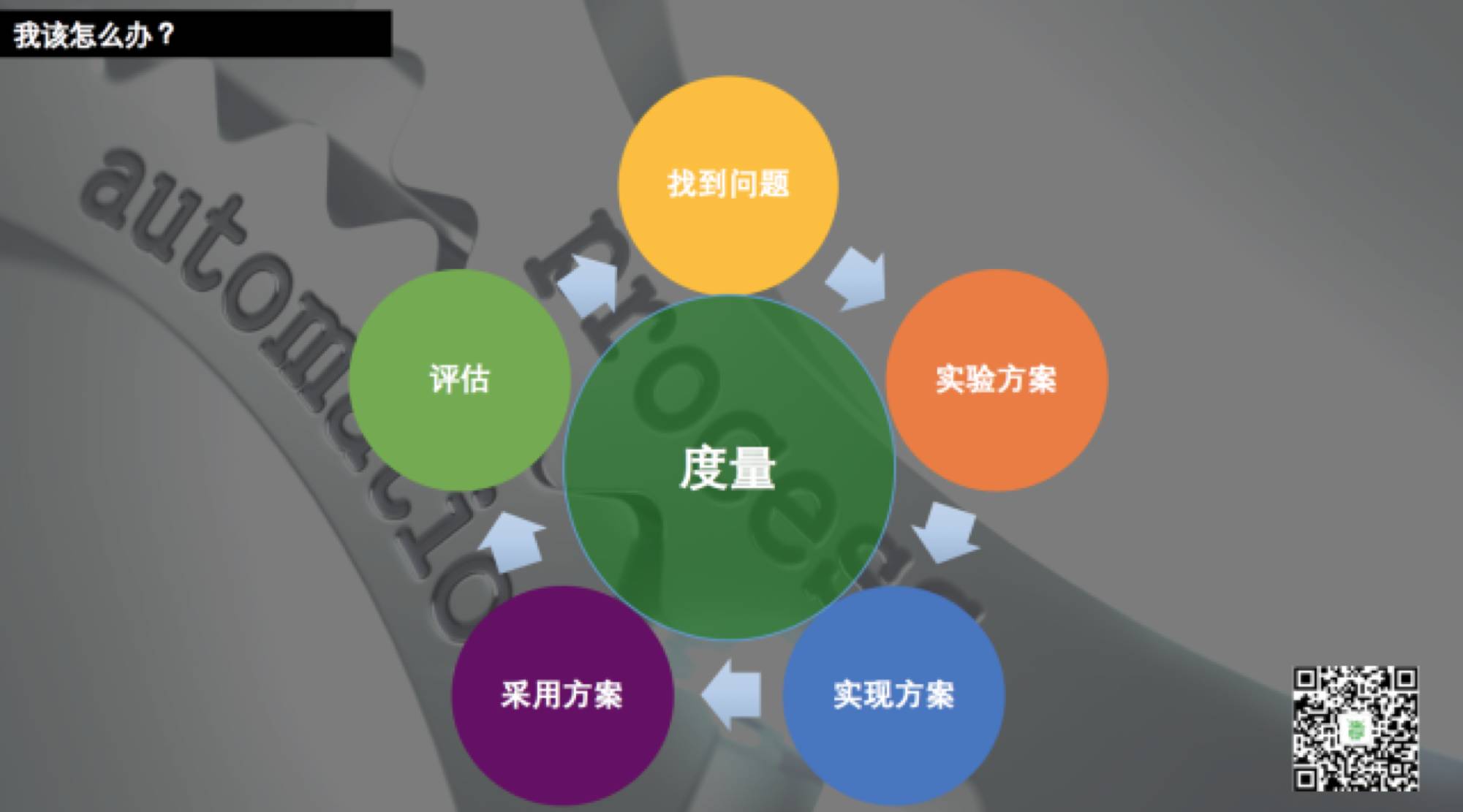
定位问题。
作为公司内部 DevOps 的领袖,你应该让开发,测试,运维的 Leader 坐在一起,从公司的角度来思考面临的问题,确保三个团队朝相同的方向努力。
实验方案。
让三个团队的 Leader 一起讨论如何改进公司的流程,讨论每个团队需要改变什么。在这个阶段,要尽量进行足够多的 POC,找个合适的方案解决公司问题。
实现方案。
和上一步 POC 的人一起进行方案的实现。此时你需要解决基础设施的问题,保证基础设施能够支持这些方案。
在测试要注意元数据的收集,例如每次构建的时间,测试覆盖率,测试通过率,上线成功率,发布周期。这些数据将来是执行持续度量的重要数据来源。
采用方案。
采用方案时,你需要为其他团队准备好文档,技术方面的支持,准备好工具。但并不意味着你准备好了文档,工具,公司团队就会配合你。公司可能有10-15%的团队坚定的支持你,并且他们会需要更先进的工具和方案。
另一部分人30%会相对保守,他们知道转型有什么用,并且会需要你来指导他们进行 DevOps 的转变。
还有一部分人会拒绝改变,你要让已经实施 DevOps 的团队作为示范项目,让所有人看到基于数据的可视化报表,看到他们的成果。
持续评估,持续度量。
此时做评估,度量,一定要用可视化的工具度量,不能凭感觉说话,必须依靠数据说话。
这就可以利用第三,四步中积累的元数据进行基于数据的度量,这个度量不仅仅是团队内部的,还可以是跨产品线的度量。当然评估之后会有发现新的问题,继续循环继续下去。
3、落地DevOps最佳实践
1. 协作。
团队之间很难做到真正的互相倾听,你需要作为那个中间人提供沟通的渠道。肯定会有人有质疑,但愿意沟通就是好事,因为最后你会和大家一起定出来团队之间协作的流程。
2. 透明化,可视化。
有人会问为什么在持续交付的流程里需要收集这么多元数据,这些元数据是评估交付流程好坏的唯一标准,这些元数据将来会给公司的转型代理巨大的价值。
你需要作为团队交付流程透明化,可视化的领导者。Jagan 在甲骨文内部搭建了 CI/CD 平台叫 Carson,这个平台为开发者提供可视化的构建流程,自定义构建流程编排,资源申请,数据统计等等很多功能。
可视化的 CI 流水线:

可视化的报表:
用这些可视化的数据,来度量 DevOps 获得的收益,包括测试通过率,构建成功率,构建速度,发布周期,资源分配情况,基于数据做成正确的决策,才是 DevOps 带来的价值。
3. 团队独立自主。
每个团队都应该有自己的 CICD 流水线。Oracle 的实践,他们为每个团队提供自助式的构建服务器的使用。从 QA 团队,每个团队也自助式的消费测试集群。
自助式CI服务编排:
4. 基础设施即代码。
运维的团队应该应该将所有的资源用代码来描述,因为运维团队的变更是没有记录的,也没有被测试过,导致环境容易产生不一致性。所以基础设施应该作为代码 checkin,然后进行测试。
5. 自动化。
为了提高效率,我们不应该容忍在软件发布流程里有任何人工审批的操作。通过大量的自动化测试的 Case 来保证软件的质量,并且将测试结果与发布的包关联,实现基于元数据的包发布。
6. 设置较高目标。
之前甲骨文的堆栈构建发布流程要经过2-3周的时间,最近已经能够达到每天多次的发布。
今天,整个产品发布周期从一年半,缩减到3个月。整个软件架构转变为微服务架构,每天多次发布服务。
Jagan 认为,为团队设置一个较高的目标,这会让团队兴奋,团队会全力全完成它,通常,最后的结果是团队证明了他们能够达到这个目标。
7. 持续度量。
流程以及产出物使用数据可视化工具可视化。

甲骨文中间件团队一个数据中心的存储量是80TB,每天的请求达到3千万次,下载的数据量达到 85TB,全球有6个数据中心。
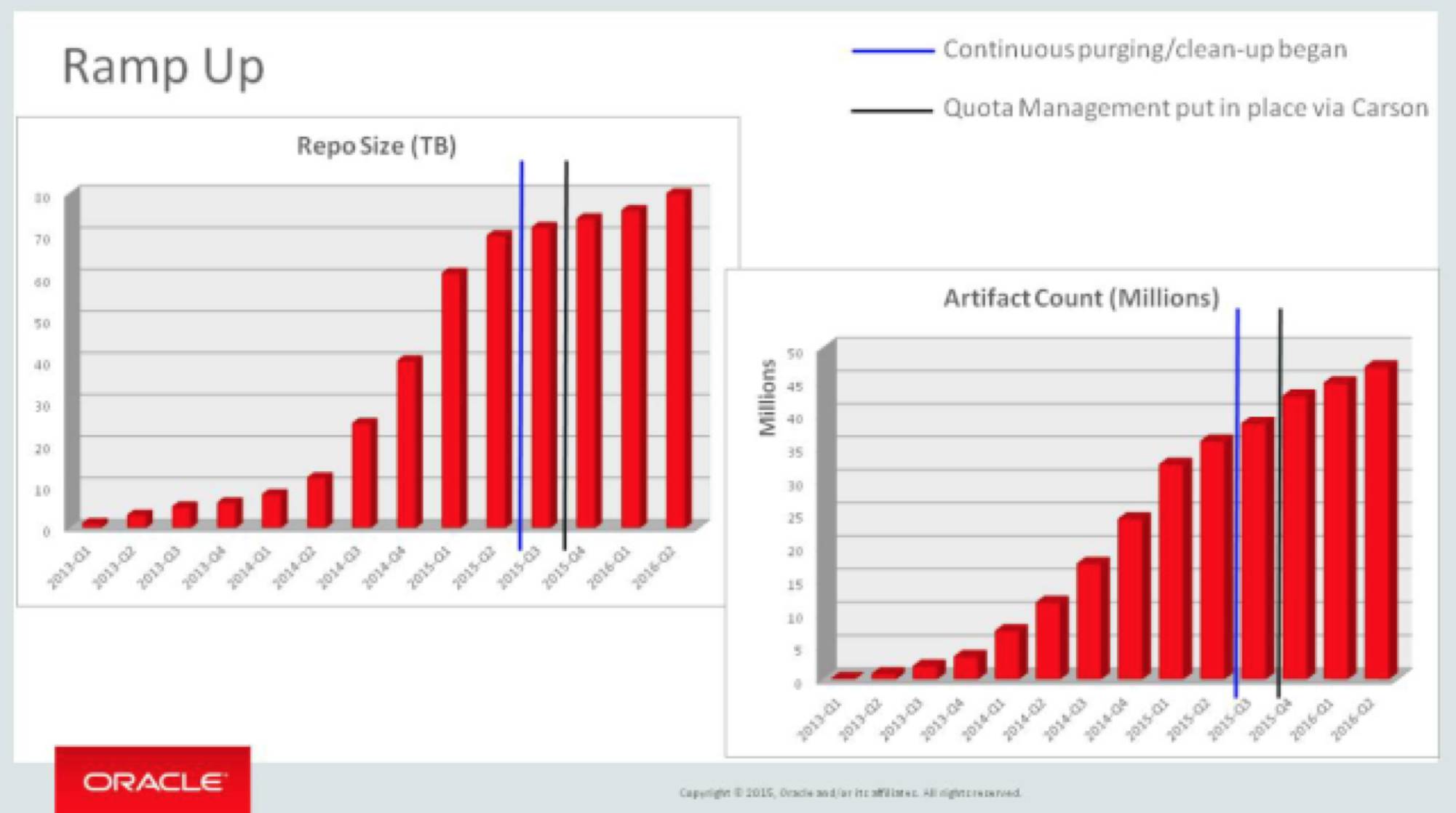
从 Artifactory 存储量的角度看甲骨文 DevOps 落地的速度。2013年 DevOps 开始落地,开始从中间件的某几个团队开始试点,到14年后,这些团队的成功案例影响到了其他团队,从 Artifactory 存储量可以看到,容量明显增长,其他的团队都来复制这个模式。15年开始,Artifactory 开始持续进行自动化的工件清理,节省了大量存储空间。
通过可视化的度量,可以清楚知道产品的构建速度,发布成功率,发布周期等等,这些度量指标将作为下一个开发周期目标的参考基准,为团队指定合理的目标。
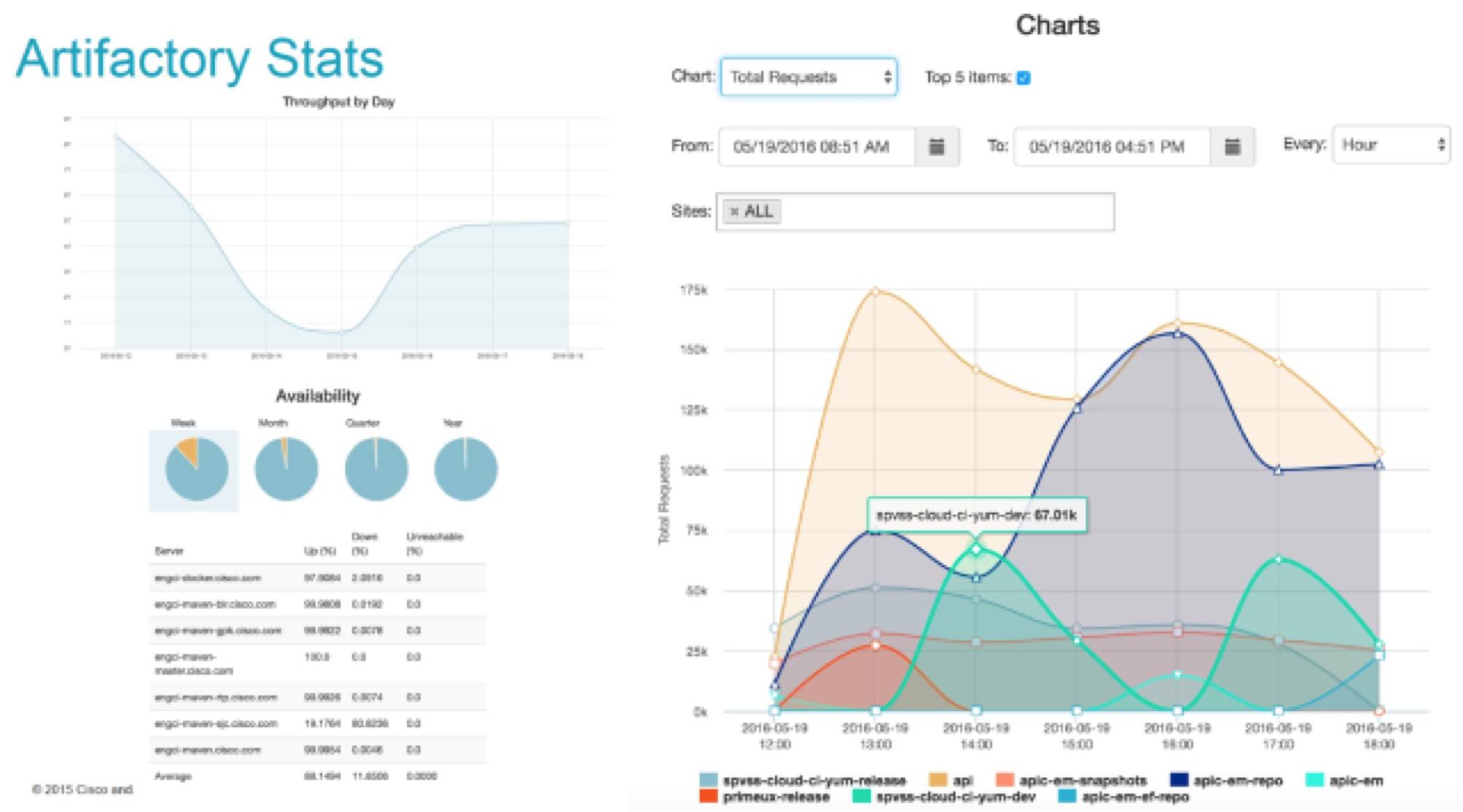
元数据也可以用来评估某个产品线占用的资源,投入产出比,做跨团队直接的绩效考评。
8. 快速失败。
上游构建的测试用例里要包含下游构建的测试用例,这样让测试在上游测试阶段失败,而不是要等到下游测试,才发现测试失败。
9. 保持质疑。
在每一环境都保持质疑,问问自己,团队能否做得更好,更快,更加自动化?
10. 这并不是工具的问题。
你是否真的相信 DevOps 能够提高生产效率?如何更有快速,更自动化的交付软件,这而不是仅仅工具的事情,而是公司文化的转变。
4、总结
你要作为公司内部主推 DevOps 的领袖,解决各种困难。
建立跨团队的沟通机制,实现 CI/CD 流程的可视化。
收集元数据做自动化发布,并且基于元数据做持续的评估,目的是缩减构建时间,缩减上线时间,用自动化测试工具提供软件质量,提高发布频率。
利用评估的体系,将最好的资源投入到最好的产品。
关于JFrog
世界领先 DevOps 平台
公司成立于2008年,在美国、以色列、法国、西班牙,以及中国北京市拥有超过200名员工。
JFrog 拥有3000多个付费客户,其中知名公司包括如腾讯、谷歌、思科、Netflix、亚马逊、苹果等。连续两年,JFrog 被德勤评选为50家发展最快的技术公司之一,并被评为硅谷增长最快的私营企业之一。

请扫二维码
关注“JFrog”
感受原汁原味的硅谷技术
点击“阅读原文”,前往 JFrog官网








