1. 博通周五业绩会,AI业务大超预期,同时指引2027年3家客户(谷歌、Meta、字节)ASIC+网络产生的需求达到600-900亿美元。
2. 除此之外,OpenAI前首席科学家Ilya本周有个talk,强调基于公开数据预训练的ScalingLaw结束了。
➠这两件事,成为了近期科技圈的绝对热点。
云厂商合作伙伴+端侧落地,将成为25年AI产业的主要叙事:
1)参考Ilya的talk,目前免费的互联网数据已经用完了,基于公开数据的预训练Scaling Law已经走到头。
往后AI产业的发展,会向大型云厂商/电子品牌商倾斜。这些企业掌握更多基于海量用户的非公开数据,可以更有斜率的去推进Scaling Law。
2)云厂商是如何做的?谷歌+博通推进TPU;AWS+MRVL推进Tranium2;国内也是如此,字节+寒武纪;腾讯+燧原等。
其中海外市场,我更为重视AWS的合作伙伴,公司云的规模比谷歌还大,但ASIC起步慢了一些,现在正奋起直追,Tranium2的量明年肯定是超300万颗的。映射到A股生益电子,XYS可以多重视。
国内市场,寒武纪+燧原也是优秀的公司,寒武纪市场认可度非常高,那么燧原合作伙伴,诸如华勤技术(腾讯云服务器一供)也值得高看一眼。
3)推理侧,为跑通ROI,垂直模型2B2C场景会加速落地,下周字节的原动力大会;闪极联合科大讯飞的AI眼镜发布会。都是重要的催化剂。
博通CEO称预计到2027年,3大客户将会有600-900亿美金的AI芯片采购需求,这三大客户除了我们熟知的谷歌和Meta,另外一家中国公司字节跳动赫然在列。
其实之前字节跳动一直有跟博通在AI芯片上有合作,不过从产品形态上看并未涉及到高端的训练或者推理芯片。但从今年开始传出的一些消息看,未来几年字节将加大在自研芯片方面的投入,而这个自研芯片的消息就是跟博通进行合作开发。
字节选择博通其实也不难理解,谷歌的TPU产品是一个很好的成功案例。芯片开发是一个资金和技术密集型的行业,国内近两年频繁传出的芯片公司倒闭新闻也可以看出,想在这个行业成功并不容易,AI训练芯片这种大芯片的开发,难度更甚。在美国不断收紧AI芯片出口到中国的大背景下,国内其他几家CSP大厂都对自研芯片早有布局,留给字节跳动试错的时间不多,找一个可靠的合作伙伴,显然是更稳妥的选择。
对于字节自研芯片,目前最大的不确定性应该就是HBM禁令以及7nm及以下制成代工问题。但这两个问题不是字节独有的,目前国内所有的AI芯片公司都面临相同的问题。
字节跳动不断增涨的业务需求和不断扩张的业务版图需要庞大的算力支持,目前的字节可能是国内最包容的AI芯片采购商,据了解,NVIDIA、AMD、Intel的AI芯片都在字节的采购清单中,字节也在尝试使用国产芯片支撑它的业务需求。如此巨大的需求下,自研芯片显然是一个更有持续性,也是更加节约成本的方案。
可能到2026或者2027年,我们能更清晰的看到字节跳动在AI芯片领域的布局。万丈高楼平地起,一砖一瓦皆根基。我们从不把是否100%纯自研作为一家公司是否优秀的评价标准。每家公司都可以选择最适合自己的道路,务实才能长久。
阿里、百度、腾讯、字节这几家互联网大厂,选择了不同道路开发自己的AI芯片,未来谁的产品能实现持续迭代,能对自己的业务形成有效支撑,并得到市场认可,我们一起持续关注。
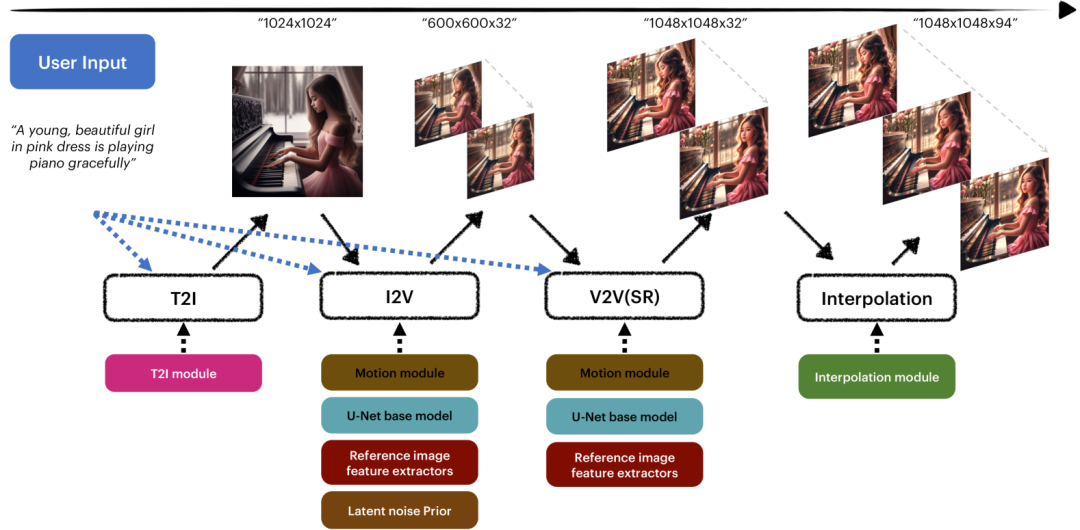
字节即梦AI的文生视频模型为MagicVideo-V2,原理如下(以1秒钟弹钢琴女孩视频为例):
1)首先文生图:生成1024*1024分辨率的一张图片,该模块自研;
2)其次图生视频:将上图生成32帧600*600分辨率的视频,该模块基于SD1.5;
3)之后视频增强:优化每一帧图像和提升分辨率,将上述视频增强变为1048*1048分辨率的32帧图像,该模块同样基于SD1.5;
4)最后视频插帧:将1048*1048*32帧的视频通过插帧成为1048*1048*94帧,该模块基于VFI(VQGAN)。
在不考虑集群损失、算法创新优化等未知因素影响下,我们对即梦AI创造的算力需求进行测算:
假设1:图生视频与视频增强环节生成图像所需算力与SD1.5一致,SD1.5在RTX4070S(FP16 35.46TFLOPS)生成512*512分辨率图片所需随时间2秒钟;
假设2:插帧环节使用GAN,参考高通测算使用插帧最高节约78%视频算力,此处用50%压缩率代替;
得到每分钟文生视频约需要23581Tflops,约为0.007H100GPU(FP16 989TFLOPS)工作时。

进一步,竖轴为即梦AI的月活用户数量(亿),横轴为每天每个用户生成视频时长(分钟)测算
在1亿/2亿月活,每天生成10分钟的假设下,所需H100数量约为28w/55w个

若进一步考虑豆包1亿月活的目标,或还能够进一步带来客观的算力需求

1、NV的下跌是因为市场担心ASIC芯片在推理时代会抢走GPU的市场,对应的是博通的上涨。但实际上这不会动摇NV的地位,且NV也在布局ASIC,ASIC本质上是一种定制芯片牺牲了通用性,而NV只需要在GPU上增加一些小模块就可以达到ASIC的作用。
2、CSP给ASIC下单本质上或许不是技术路线的原因,更多是对NV垄断地位的一种反击商业策略而已,因为从成本上来看ASIC几乎没有任何优势:“哪怕芯片免费送,也要比GB200贵”这是老黄的原话。你可以理解成当年整车厂要自研电池来反击宁德时代一样,但这并不能动摇宁德的实际地位。
3、铜在上面这个叙事逻辑下底层估值体系发生了微妙的变化,这也是很多人没有意识到的一点。之前大家把铜和NV的GB200系列高度绑定,所以估值体系一直很难超过光模块(中美、周期)被牢牢锁死在NV链估值的天花板。但现在各家要自研自采ASIC芯片,铜在推理时代突然下游一下子变得全面开花,尤其期待字节,看看能不能直接给wr和sy下单。
4、铜缆也有细分,有机构对于AEC这个细分非常看好甚至激进,比如最近AWS找xys给了AEC单子、Google自己的TPU(也可以理解成一种ASIC)也用的AEC。是的,你没猜错,他们最终都要找ltk。
(Active Electrical Cable,有源铜缆)适合在数据中心【短距】且【高速】场景下使用,是大型数据中心降本方案之一。短距与铜作为传输介质的物理特性有关。高速场景下,AEC相比DAC(无源铜缆)由于有retimer约束信号,传输距离更长,铜缆更细,易于部署。
海外CSP纷纷部署,国内大厂紧随其后。目前AWS/微软/xAI需求较大,Google开始部署,随着自研ASIC比例提升,AEC需求快速起量。国内阿里腾讯开启测试,预计25年采购;字节25年短距场景以单模LPO光模块为主,26年逐步引入AEC。除云厂商加速部署以外,我们认为,AEC和Optical I/O、DAC一道,是Nvidia下一代Rubin的机柜内链接的备选方案之一。
目前存量市场稍小但增速较快。25年随北美云厂商需求提升,市场空间有望到达20亿美金。26年国内市场接力,海外市场继续随GPU自研而渗透率提升,市场空间仍有望继续高速提升。
海外供应商暂时领先,国内供应商紧跟。海外安费诺/Credo/molex出货较多,国内#新易盛/ 立讯精密陆续开始起量。预计25年进入AEC市场,有望凭借合作方的渠道优势快速抢占北美市场。AEC由retimer芯片、铜缆、连接组件构成。Retimer主要由Marvell/Credo/博通出货,国内可关注澜起科技产品;铜缆关注Credo供应商。
1、格局:现在明确有需求量的是MSFT(400G、800G)和AWS(800G),谷歌测试进行量的forecast仍需展望,xAI、Oracle也有类似项目推进;credo这边基本测试都通过,比较早;Marvell、Asteralab、博通等芯片进度会相对慢些,但也都配合安费诺、旭创、新易盛等厂商在积极导入
2、价格的话:800G AEC(其实是两个铁头+线缆)大概400-500美金,客制化约300美金;400G AEC可能是150美金。
3、理论测算:
1)谷歌方向:明年谷歌150w颗,但里面TPUv5 V4推理和训练都有,我们只针对训练卡算,比例是1:1.25条AEC(假设3D Torus部分铜缆连接全部用AEC,参考TPUv4架构测算);可能TPUv5p有个大几十万颗,那就是大几十万条-百万条 800G AEC,
2)AWS方向:参考SA,市场预期明年AWS可能120-170w Trainium2,32卡一机柜版本TR2 与400G DAC/AEC比例有1:2(32卡),64卡机柜主要用上3D Torus架构,加上网卡端与400G比例大致是1:1.5,平均可能1:1.75 400G AEC/DAC;仅考虑测算下可能AWS接近300w AEC/DAC;
3)NV方向:由于铜缆PCC/ACC/AEC大概率只是在第一层(网卡到TOR),所以条数跟GPU比例大概是1:1,2025年假设B卡全部用CX8网卡,接入层可以用800G AEC的话,那就是理论最大是300多万条 800G AEC(不考虑有光模块的掺杂);H100/H200如果还有100w出货,可能还有100多万条 400G AEC/DAC。
4、综上:将ASIC芯片+GPU芯片算,因为DAC到400G/800G时代传输距离将极大缩短,所以我们假设考虑400G开始转为AEC,2025年有可能得到400w 条 400G ,300多万条 800G AEC的理论市场规模,假设全部为AEC,则价值量为18-20亿美金左右的市场。
1、以太网交换机芯片
市场格局:博通在以太网业务及芯片方面,占据市场接近70%,Marvell占20%,英伟达等其他公司占剩余部分。
国内情况:国内数据中心交换机芯片,400G及800G以国外芯片为主,国内有少量400G芯片出货,但比例不超过10%到15%,国外芯片占80%以上。
技术难度:SerDes,涉及高速时钟,运行速度快,时钟在传输过程中会发生漂移和位移,会带来数据错位,影响传输速度,因此纠错和测试检测在高速交换机芯片中至关重要,博通、英伟达等有自己的SerDes技术IP,国内在SerDes这块的IP开发不够,多采用第三方通用IP,在进入25.6T甚至51.2T时会遇到很多挑战,国内交换机芯片在技术性能方面与国外有一定差距。
2、财政部采购政策对博通影响
在中低端芯片市场影响较大,高端芯片市场影响较小。在中低端市场国产化会进一步扩大,而高端市场如400G、800G等,国内厂商目前无法替代,交换机厂商只能选择国外芯片
政策鼓励国内芯片厂商,华为、中兴等有自己芯片的厂商在能做的市场中会有优势,若他们能力提升,推出更高端产品,可能会拉开与其他厂商的差距。
3、博通产品
产品定位:Tomahawk面向数据中心,是高端甚至更偏向高端的产品系列;Trident中低端甚至偏低端,面向电信客户;Jericho介于两者之间,偏向终端,面向企业型用户
4、光模块与CPO
光互联发展阶段:光互联分为三个阶段,第一阶段到800G甚至1.6T是传统可插拔光模块,1.6T到3.2T可插拔光模块面临功耗和成本挑战,进入CPO阶段,26年CPO会成为主流应用;再往上到6.4T到12.8T,GPU会碰到瓶颈,进入全硅光互联阶段。
硅光与CPO的区别:CPO是为解决DSP功耗问题的中间态,将光芯片、电芯片的部分功能做到光引擎里;硅光细分有源器件和无源器件,若这些器件能在VCSEL模式工艺上实现集成,硅光集成将成为主流。