导读:在 3 月 4 日举办的高可用架构 PCC 性能挑战赛上(PCC 是 Performance Challenge Championship 的缩写),以 RocksDB 为存储的队伍获得了显著的优势。在另外一方面,RocksDB 被存储相关架构师在各种讨论中反复提及,高可用架构翻译了官方的 rocksdb 基础说明,让读者 5 分钟可以全面了解。PCC 大赛的获奖作品将会另文介绍。
1、介绍
RocksDB 项目最开始是在 Facebook 作为一个试验项目开发的高效的数据库软件,可以实现在服务器负载下快速存储(特别是闪存存储)的数据存储的全部潜力。它是一个 C++ 库,可以用于存储 KV,包括任意大小的字节流。它支持原子读写。
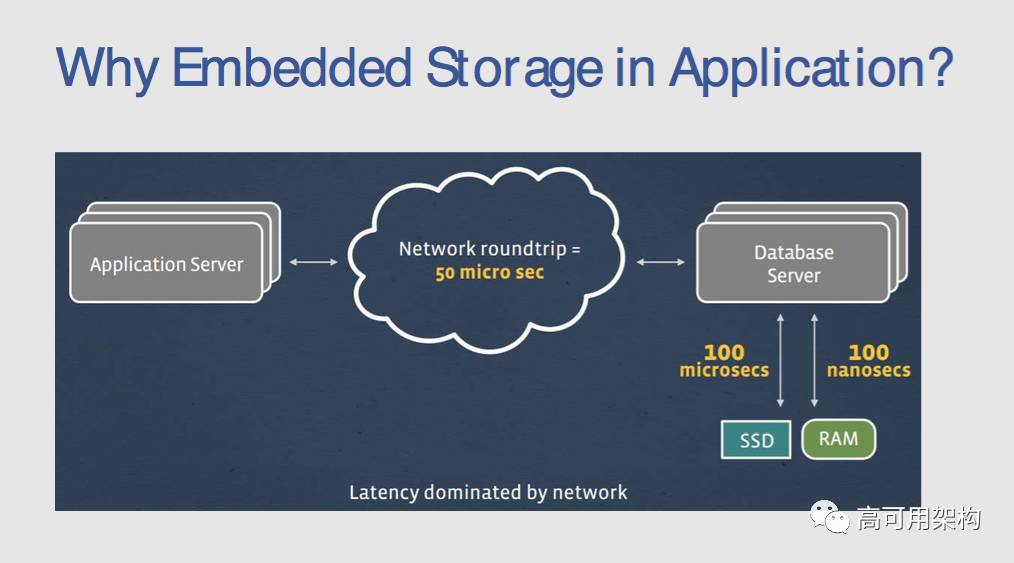
RocksDB 具有高度灵活的配置设置,可以调整为在各种生产环境(包括纯内存,闪存,硬盘或 HDFS)上运行。它支持各种压缩算法,并且有生产和调试环境的各种便利工具。
RocksDB 借用了来自开源 leveldb 项目的核心代码,以及来自 Apache HBase 的重要思想。初始代码是从开源 leveldb 1.5 fork 的。它还融入了 facebook 团队在开发 RocksDB 之前的若干代码及想法。
2、假设和目标
性能
RocksDB 的主要设计点是,它应该是快速存储和服务器工作负载的性能而设计。它应充分利用 Flash 或 RAM 提供的高速读/写速率的全部潜力。它应该支持高效的点查找以及范围扫描。它应该可配置为支持高随机读取工作负载,高更新工作负载或两者的组合。其架构应支持轻松调整参数,支持读取放大,写入放大和空间放大场景。
生产环境支持
RocksDB应该以这样一种方式设计,即它具有内置的工具支持,有助于在生产环境中部署和调试。大多数主要参数应该是完全可调的,以便它可以被不同硬件上被不同应用使用。
向后兼容性
软件的较新版本应向后兼容,以便在升级到较新版本的 RocksDB 时,现有应用程序不需要更改。
3、架构概述
RocksDB 是一个嵌入式 kv 存储,key 和 value 是任意字节流。RocksDB 按顺序组织所有数据,常用操作是 Get(key) ,Put(key) ,Delete(key) 和 Scan(key) 。
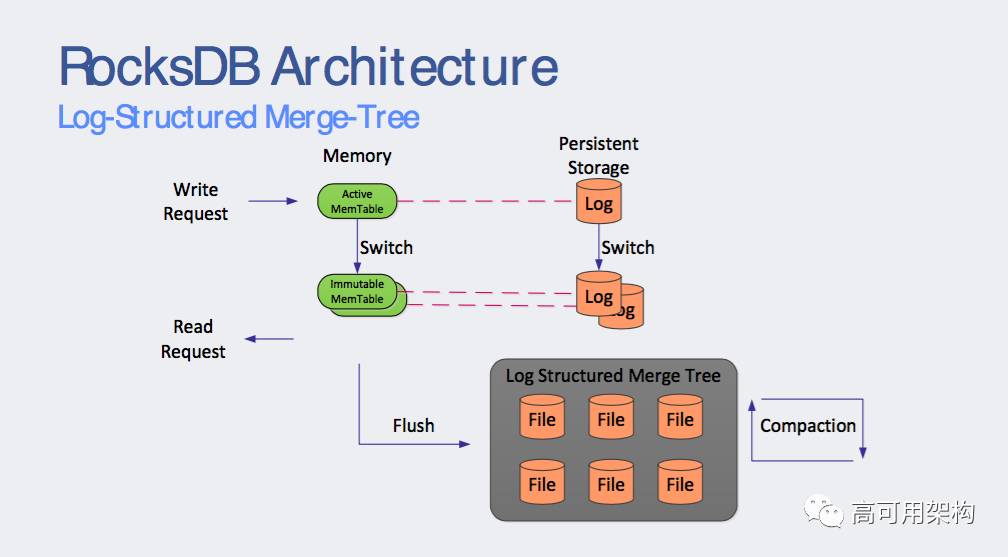
RocksDB 的三个基本结构是 memtable, sstfile 和 logfile。
memtable 是一个内存数据结构,新写入的数据被插入到 memtable 中,并可选地写入日志文件。
日志文件是存储上顺序写入的文件。当 memtable 填满时,它被 flush 到存储上的 sstfile ,然后可以被安全地删除。sstfile 中的数据顺序存放,以方便按 key 进行查找。
在此更详细地描述默认 sstfile 的格式 [2]。
4、特性
Get,Interator(迭代器)和快照
Key 和 value 被视为纯字节流。对 key 或 value 的大小没有限制。Get API 允许应用程序从数据库中提取单个 key。MultiGet API 允许应用程序从数据库中检索一堆 key。通过 MultiGet 调用返回的所有 key-value 彼此一致。
数据库中的所有数据按照排序顺序进行逻辑排列。应用程序可以定义 key 的排序比较方法。Iterator API 允许应用程序对数据库执行 RangeScan。Iterator 可以寻找指定的 key,然后应用程序可以从该点开始一次扫描一个 key。Iterator API 也可以用于对数据库中的 key 进行反向迭代。创建 Iterator 时,将创建数据库的一致时间点视图。因此,通过 Iterator 返回的所有 key 都来自数据库的一致视图。
Snapshot API 允许应用程序创建数据库的时间点视图。Get 和 Iterator API 可用于从指定的快照读取数据。在某种意义上,Snapshot 和 Iterator 都提供了数据库的时间点视图,但它们的实现是不同的。短期扫描最好通过迭代器完成,而长时间运行的扫描最好通过快照完成。迭代器对与数据库的该时间点视图相对应的所有底层文件保持引用计数 - 这些文件在 Iterator 被释放之前不会被删除。另一方面,快照不会防止文件被删除; 但在压缩过程中,压缩程序能够判断快照的存在,它不会删除在任何现有快照中可见的 key。
快照不会在数据库重新启动后保持持久化,因此重新加载 RocksDB 库(通过服务器重新启动)会释放所有预先存在的快照。
前缀迭代器
大多数 LSM 引擎不能支持高效的 RangeScan API,因为它需要查看每个数据文件。但大多数应用程序不需要对数据库中的 key 范围进行纯随机扫描; 而应用程序通常通过 key 前缀进行扫描。
RocksDB 使用这个方法来体现了它的优势。应用程序可以配置 prefix_extractor 以指定 key 前缀。RocksDB 使用它来存储每个 key 前缀的 blooms。指定前缀(通过 ReadOptions)的迭代器将使用这些 bloom 位来避免查找不包含具有指定的 key 前缀的数据文件。
更新
Put API 将单个 key-value 插入数据库。如果 key 已经存在于数据库中,则以前的值将被覆盖。Write API 允许将多个 key-value 原子地插入到数据库中。数据库保证要么单个 Write 调用中的所有 key-value 将被插入数据库,要么它们都不会插入数据库。
持久化
RocksDB 有一个事务日志。所有 Put 都存储在称为 memtable 的内存中缓冲区中,并可选择插入到事务日志中。每个 Put 都有一组通过 WriteOptions 设置的标志,它们指定是否将 Put 插入到事务日志中。WriteOptions 还可以指定在 Put 被提交之前,是否向事务日志发出 sync 调用。
在内部,RocksDB 使用批量提交机制将多个事务写入到事务日志中,以便它可以使用单个 sync 调用提交多个事务。
容错
RocksDB 使用校验和来检测存储中的损坏。这些校验和针对每个块(通常在 4K 到 128K 之间)。块一旦写入存储,就不会被修改。RocksDB 动态检测硬件对校验和计算的支持,并在可用时自动提供该支持。
多线程压缩
需要压缩才能删除同一 key 的多个副本,如果调用者曾经多次覆盖同一 key 的值,则会出现同一 key 的多个副本。压缩还会处理 key 的删除。通过配置,压缩支持多线程进行。
LSM 数据库的总写入吞吐量直接取决于压缩可能发生的速度,特别是当数据存储在诸如 SSD 或 RAM 的快速存储器中时。
RocksDB 可以配置为多线程压缩。可以看出,与单线程压缩相比,当数据库在 SSD 上时,多线程压缩持续写入速率可以增加多达 10 倍。
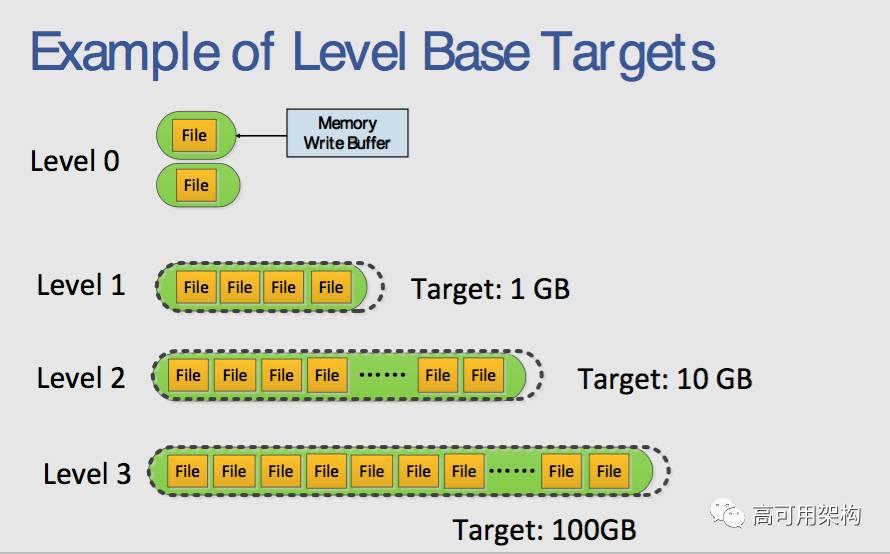
整个数据库存储在一组 sstfile 中。当 memtable 已满时,其内容写入 Level-0(L0)中的文件。当它被刷新到 L0 中文件时,RocksDB 删除 memtable 中的重复和覆盖的 key。一些文件会定期读入并合并形成较大的文件,这称为压缩。
RocksDB 支持两种不同的压缩方式。
通用压缩(
Universal Style Compaction
)存储 L0 中的所有文件,所有文件按时间顺序排列。压缩拾取一些在时间上彼此相邻的文件,并将它们合并回新的文件存回 L0。所有文件可以具有重叠的 key。
级别样式压缩(
Level Style Compaction
)在数据库中以多个级别存储数据。较新的数据存储在 L0 中,最旧的数据存储在 Lmax 中。L0 中的文件可能具有重叠的键,但其他图层中的文件不能。压缩过程选择 Ln 中的一个文件及其在 Ln + 1 中的所有重叠文件,并用 Ln + 1 中的新文件替换它们。
通用样式压缩通常导致较低的写入放大,但比水平样式压缩更高的空间放大。
数据库中的 MANIFEST 文件记录数据库状态。压缩过程会添加新文件并从数据库中删除旧文件,并通过将它们记录在 MANIFEST 文件中使这些操作持久化。要记录在 MANIFEST 文件中的事务使用批量提交算法,来将重复 sync 的请求合并到 MANIFEST 文件。
避免停顿
后台压缩线程也负责将 memtable 内容刷新到存储上的文件。如果所有后台压缩线程都忙于执行长时间运行的压缩,那么突然的写入操作可以快速填满memtable ,从而新的写入操作将会卡顿。这种情况可以通过配置 RocksDB 保留一小段线程来避免,这些线程显式保留用于将 memtable 刷新到存储器的唯一目的。
压缩过滤器
一些应用程序可能希望在压缩时对数据做一些处理。例如,具有对生存时间(TTL)的固有支持的数据库,可以移除过期的 key。这可以通过应用程序定义的压缩过滤器来完成。如果应用程序想要连续删除超过特定时间的数据,它可以使用压缩过滤器删除已过期的记录。RocksDB 压缩过滤器让应用程序修改 key 的值或完全删除 key 作为压缩过程的一部分。例如,应用程序可以作为压缩的一部分连续运行数据清理程序。
ReadOnly 模式
数据库可以以只读模式打开,其中数据库保证应用程序不会修改数据库中的任何内容。这导致高得多的读取性能,因为被横穿的代码路径完全避免了锁的开销。
数据库调试日志
RocksDB 将详细日志写入名为 LOG* 的文件。这些主要用于调试和分析正在运行的系统。该日志可以被配置为以指定的周期滚动。
数据压缩
RocksDB 支持 snappy,zlib,bzip2,lz4 和 lz4_hc 压缩。RocksDB 可以配置为在不同级别的数据上支持不同的压缩算法。通常 90% 的数据在 Lmax 级别。
典型的安装可能配置无压缩级别 L0-L2,snappy 压缩中级和 zlib 压缩 Lmax。
事务日志
RocksDB 将事务存储到日志文件中以防止系统崩溃。在重新启动时,它会重新处理日志文件中记录的所有事务。日志文件可以配置为存储在与 _sstfile_s 不同的目录中,比如某些场景,你可能会将所有数据文件存储在非持久性快速存储器中,同时,您可以通过将所有事务日志放在较慢但持久的存储上确保不会有数据丢失。
完全备份,增量备份和复制
RocksDB 支持完全备份和增量备份。RocksDB 是一个 LSM 数据库引擎,因此,一旦创建,数据文件就不会被覆盖,这使得很容易提取与数据库内容的时间点快照相对应的文件名列表。API DisableFileDeletions 指示 RocksDB 不要删除数据文件。压缩将继续发生,但数据库不需要的文件将不会被删除。然后,备份应用程序可以调用 API GetLiveFiles / GetSortedWalFiles 以检索数据库中的活动文件列表,并将它们复制到备份位置。备份完成后,应用程序可以调用 EnableFileDeletions ; 数据库现在可以自由回收所有不再需要的文件。
增量备份和复制需要能够找到并 tail 数据库的所有最近更改。API GetUpdatesSince 允许应用程序在 RocksDB 事务日志上执行 tail 操作。它可以从RocksDB 事务日志中连续获取事务,并将它们应用到远程复制副本或远程备份。
复制系统通常希望用一些元数据注释每个 Put。该元数据可以用于检测复制管道中的循环。它也可以用于时间戳和顺序事务。为此,RocksDB 支持一个称为 PutLogData 的 API,应用程序可以使用该 API 来为每个 Put 添加元数据。此元数据仅存储在事务日志中,不存储在数据文件中。通过 PutLogData 插入的元数据可以通过 GetUpdatesSince API 来获取。
RocksDB 事务日志在数据库目录中创建。当不再需要日志文件时,将其移动到归档目录。留在归档目录的原因是落后的复制流可能需要从日志文件中检索过去的事务。API GetSortedWalFiles 返回所有事务日志文件的列表。
在同一个进程中支持多个嵌入式数据库
RocksDB 的一个常见用例是应用程序固有地将其数据集分区为逻辑分区或分片。这种技术有利于应用程序负载平衡和从故障快速恢复。
这意味着单个服务器进程需要能够同时操作多个 RocksDB 数据库。这通过名为 Env 对象完成。除此之外,线程池也与 Env 关联。如果应用程序想要在多个数据库实例之间共享公共线程池(用于后台压缩),那么它应该使用相同的 Env 对象来打开这些数据库。
类似地,多个数据库实例可以共享相同的块高速缓存。
块缓存 - 压缩和未压缩数据
RocksDB 使用 LRU 缓存来提供读取。块高速缓存被分割成两个单独的高速缓存:第一高速缓存是未压缩块,第二高速缓存是压缩块,它们都存在 RAM 中。如果配置了压缩块高速缓存,则数据库智能地避免在 OS buffer 中缓存数据。
表缓存
表缓存是一种用于缓存打开的文件描述符的结构。这些文件描述符用于 sstfile。应用程序可以指定表缓存的最大大小。
外部压缩算法
LSM 数据库的性能在很大程度上取决于压缩算法及其实现
。RocksDB 有两个支持的压缩算法:LevelStyle 和 UniversalStyle。我们还希望使大型开发人员能够开发和实验其他压缩策略。因此,RocksDB 有适当的钩子关闭内置的压缩算法,并提供 API 允许应用程序操作自己的压缩算法。









