加入雷锋网,分享AI时代的信息红利,与智能未来同行。听说牛人都点了这里。
 雷锋网按:本文根据涂图CTO在七牛云架构师沙龙上的演讲整理,本篇主要谈谈人脸识别技术的原理与具体实践的一些问题,作者授权发布雷锋网。
雷锋网按:本文根据涂图CTO在七牛云架构师沙龙上的演讲整理,本篇主要谈谈人脸识别技术的原理与具体实践的一些问题,作者授权发布雷锋网。
在之前一篇文章中,我们提到了美颜2.0最关键的技术——人脸识别。这是项复杂但又非常热门的技术,我们将在这篇文章中聊一聊图像识别技术。
● ● ●
一、如何让机器看懂世界?
这里我们来简单聊聊机器学习与深度学习。
近段时间,机器学习、深度学习的概念非常火,尤其是今年 AlphaGo 击败了韩国棋手这件事,引起了世界的轰动。机器学习和深度学习这两个概念,比较容易混淆,以至于很多媒体在写报道时,经常把这两个词混着用。由于这两个概念目前最主要应用在图像领域上,所以我们仅就图像识别,尤其是人脸识别方面,区分一下这两个概念。
机器学习的概念提出的比较早,上世纪 90 年代初,人们开始意识到一种可以更有效地构建模式识别算法的方法,那就是用数据(可以通过廉价劳动力采集获得)去替换专家(具有很多图像方面知识的人)。而深度学习可以算是机器学习的一个分支,只在近十年内才得到广泛的关注与发展。
下面说说具体的区别。
首先,机器学习识别物体是基于像素特征的。我们会搜集大量的图像素材,再选择一个算法,使用这个算法来解析数据、从中学习,然后对真实世界中的事件做出决策和预测。
而深度学习可以算是机器学习的一个分支,只在近十年内才得到广泛的关注与发展。它与机器学习不同的是,它模拟我们人类自己去识别人脸的思路。
比如,神经学家发现了我们人类在认识一个东西、观察一个东西的时候,边缘检测类的神经元先反应比较大,也就是说我们看物体的时候永远都是先观察到边缘。就这样,经过科学家大量的观察与实验,总结出人眼识别的核心模式是基于特殊层级的抓取,从一个简单的层级到一个复杂的层级,这个层级的转变是有一个抽象迭代的过程的。深度学习就模拟了我们人类去观测物体这样一种方式,首先拿到互联网上海量的数据,拿到以后才有海量样本,把海量样本抓取过来做训练,抓取到核心的特征,建立一个网络,因为深度学习就是建立一个多层的神经网络,肯定有很多层。有些简单的算法可能只有四五层,但是有些复杂的,像刚才讲的谷歌的,里面有一百多层。当然这其中有的层会去做一些数学计算,有的层会做图象预算,一般随着层级往下,特征会越来越抽象。

举例来说,识别一张人脸,如果是在具体环境中的人脸,如果遇到云雾,或者被树遮挡一部分,人脸就变得模糊,那基于像素的像素特征的机器学习就无法辨认了。它太僵化,太容易受环境条件的干扰。而深度学习则将所有元素都打碎,然后用神经元进行“检查”:人脸的五官特征、人脸的典型尺寸等等。最后,神经网络会根据各种因素,以及各种元素的权重,给出一个经过深思熟虑的猜测,即这个图像有多大可能是张人脸。
所以,深度学习比机器学习不管在人脸识别还是各种各样的识别表现都要好,甚至已经超过人类的识别能力。比如 2015 年谷歌发布了一个 facenet 网络,做人脸检测的,号称用这个网络可以达到 98% 以上识别率。而我们人类自己去看样本所达到的正确率,一样不是百分之百,甚至还没有现在一些最先进的采用深度学习算法的技术准确率高。
在机器学习方面,目前国际上比较主流的基于人脸检测的计算,一是 HOG 算法,还有其他像 LBF 特征算法。 LBF 是 OpenCV 的,OpenCV 是个非常有名的开源库,里面有各种各样的图象处理相关功能,而且是开源的,但是它在移动平台上效果很差,没有办法达到我们要的效果。这里提到是因为它非常有名,里面包含了各种各样图象处理相关的功能,比如说做特殊处理,做人脸识别、物体识别等等。OpenCV 里面就包含了 LBF 算法的实现。
深度学习有不少开源框架,比如 Caffe、TensorFlow。这些框架提供的仅仅是构建深度学习网络的工具,但是深度神经网络才是最关键的东西。网络怎么构建?网络有多种构建方式,比如大家去关注这方面会发现经常看到一些名词,CNN、RNN,CNN 可能是比较火的,在人脸识别方面是表现非常优越的一个网络,现在也是比较主流的一个网络。当然也有很多网络,RNN 或者是更快的 CNN 网络等等,在解决某些具体问题的时候,有更加好的表现。
● ● ●
二、图像识别的一些具体实现:比如,智能鉴黄
当们我们具备了相关的深度学习技术后,就可以在服务端上构建应用了。
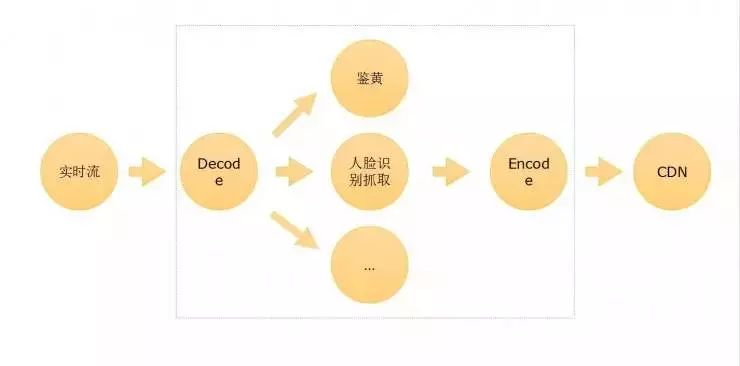
比如做智能鉴黄,一路视频流输入,解码以后拿到每一帧,识别出有问题的部分,对它进行处理。比如打上马赛克,或者把内容保存下来,然后发送通知给后台,告诉后台这里有一张疑似有不可描述的东西出现了等等,之后再编码,输出到其它地方,比如再分发到 CDN 等等。这些过程如果用人工识别成本非常高,要发展肯定要通过技术手段去解决。
最后说下手机端上的经验:涂图的产品在人脸检测性能方面的测试指标。
比如 iOS 和安卓平台上面我们做的测试,在 iPhone 6 上,40 特征点抓取需要 40 毫秒,相当于一秒内可以处理 25 帧。当然实际上并不需要这么多的次数,人眼观察事物,因为有视觉暂留效应,一般来说 12 帧是个分界线,小于 12 帧就能感觉到画面卡顿,但是只要大于 12 帧,看起来就是连续的。所以我们一般限制在十七八次的检测,在 iOS 上够用了。安卓方面,相对于 iOS 平台的表现确实要差一些,不论是 API 的封装,还是整个硬件的搭配,可能同样一个 GPU 型号,用在安卓的设备上就没法达到跟 iOS 同样的表现,iOS 平台确实在各方面上要做得比安卓好一点。小米5是比较新的设备了,40 特征点抓取需要大概 60毫秒。
● ● ●
三、技术的发展瓶颈:最后还是拼硬件
虽然在手机端上,比如 iOS 9,已经推出了深度学习 API,iOS 10 又对其进行了升级,提供了更多的功能,但是一般来说我们是在 PC 上面开发、训练的,直到把代码都做好,再放在手机设备上运行。因为就像刚才提到的,机器学习、深度学习的开发中非常关键的环节是训练。
训练是什么意思?
比如我取 1 万张图片把人脸都标识出来,把 1 万张样本处理之后得到经验,到底人脸有什么特征?比如涉及 150 个参数,得出一个函数,调整后得到一个函数模型,这样的模型再去训练、测试,最后得到一个比较好的模型。接下来再找很多测试数据,比如 1 万张测试数据,来检测这个模型,如果表现很好,那这个数据模型网络是可靠的,最后用在实际中。
但是这个训练的过程非常耗时间。我们运行一个训练,CPU 可能需要二三十个小时。
这还是简单的模型,一些复杂的模型,比如谷歌开放的 125 层神经网络,如果用 CPU 来跑可能要三四天,相当于这么久以后才能得到一个模型,你才知道这个模型是好是坏。如果你发现不行,又改了一个小参数,结果还要继续三四天时间。所以解决的办法只有一条,就是升级硬件。比如 GPU 取代 CPU 完成运算。这里列了一个细的指标,比如有些算法需要在 RGB 空间里做检测,有没有不可描述的内容在里面。如果我们用 GTX 980 Ti 来运行,可以小于 20 毫秒一帧,用 i7 的 CPU 运行,检测出来则是 800 秒,跟 GPU 跑完全不可比。但问题是,专门做训练的 GPU 设备非常贵,七八千块钱的 GPU 在机器训练里面都不算好的,而且为了在复杂的场景中不耽误时间,比如像 AlphaGo 做训练一样,只能用海量的设备来弥补,这个成本可想而知。所以才说只有有一定实力的公司才能担负的起做深度学习。
现在国际上一些主流的大公司,比如微软,很多服务包括云服务等等,用的是 FPGA 方案。百度也在做基于运算单元的芯片,中科院也在做相关的研究。
所以深度学习一路发展下来,实际上一直都卡在计算上,计算能力远远跟不上我们软件的要求,最后就又变成了比拼硬件的时代。但其实这个问题并不是近期才有的:早在人工智能出现的早期,神经网络的概念就已经存在了,但神经网络对于“智能”的贡献微乎其微,主要问题就出在运算能力不足上。所以现在大家可以预见,量子计算一旦成为可能,人工智能的时代才算真正要到来了。











