
两年前,蒙特利尔大学 Ian Goodfellow 等学者提出“生成对抗网络”(Generative Adversarial Networks,GANs)的概念,并逐渐引起 AI 业内人士的注意。其实,直到 2015 年,生成对抗网络还称不上是炙手可热。但自今年(2016)以来,学界、业界对 GANs 的兴趣出现“井喷”:
-
多篇重磅论文陆续发表;
-
Facebook、Open AI 等 AI 业界巨头也加入对 GANs 的研究;
-
它成为今年 12 月 NIPS 大会当之无愧的明星——在会议大纲中被提到逾 170 次;“
-
GANs之父” Ian Goodfellow 被公推为人工智能的顶级专家;
-
业内另一位大牛 Yan Lecun 也对它交口称赞,
称其为“20 年来机器学习领域最酷的想法
”。
现在,雷锋网获得消息,就连苹果也跳上了 GANs 的彩车:苹果有史以来第一篇公开发表的 AI 论文,讲的是如何更好地利用 GANs,来训练 AI 图像识别能力。这是继苹果本月初在 NIPS 大会上宣布“将对外公布 AI 研究成果”之后,为兑现诺言做出的行动。
那么,GANs 是如何从一个原本“不温不火”的技术,成为今天人工智能的主要课题之一?
雷锋网对此进行了梳理,归纳了 GANs 从诞生到现在如何一步步走向技术成熟。以下是它发展路线中的大事件(主要研究进展):
●
●
●
1. GANs 诞生

Ian Goodfellow
2014 年 6 月,Ian Goodfellow 等学者发表了论文《Generative Adversarial Nets》,题目即“生成对抗网络”,这标志着 GANs 的诞生。文中,Ian Goodfellow 等作者详细介绍了 GANs 的原理,它的优点,以及在图像生成方面的应用。
那么,什么是 GANs?
用 Ian Goodfellow 自己的话来说:
“生成对抗网络是一种生成模型(Generative Model),其背后基本思想是从训练库里获取很多训练样本,从而学习这些训练案例生成的概率分布。
而实现的方法,是让两个网络相互竞争,‘玩一个游戏’。其中一个叫做生成器网络( Generator Network),它不断捕捉训练库里真实图片的概率分布,将输入的随机噪声(Random Noise)转变成新的样本(也就是假数据)。另一个叫做判别器网络(Discriminator Network),它可以同时观察真实和假造的数据,判断这个数据到底是不是真的。”
对不熟悉 GANs 的读者,这番解释或许有些晦涩。因此,雷锋网特地找来 AI 博主 Adit Deshpande 的解释,更加清楚直白:
“GANs 的基本原理是它有两个模型:一个生成器,一个判别器。判别器的任务是判断给定图像是否看起来‘自然’,换句话说,是否像是人为(机器)生成的。而生成器的任务是,顾名思义,生成看起来‘自然’的图像,要求与原始数据分布尽可能一致。
GANs 的运作方式可被看作是两名玩家之间的零和游戏。原论文的类比是,生成器就像一支造假币的团伙,试图用假币蒙混过关。而判别器就像是警察,目标是检查出假币。生成器想要骗过判别器,判别器想要不上当。当两组模型不断训练,生成器不断生成新的结果进行尝试,它们的能力互相提高,直到生成器生成的人造样本看起来与原始样本没有区别。”
更多“什么是 GANs ?”的详细解说,请参考雷锋网整理的 Ian Goodfellow NIPS 大会 ppt 演讲,Yan Lecun 演讲,以及香港理工大学博士生李嫣然的 “GANs 最新进展”特约稿。(点击
原文中的链接
查看)
早期的 GANs 模型有许多问题。Yan Lecun 指出,其中一项主要缺陷是:GANs 不稳定,有时候它永远不会开始学习,或者生成我们认为合格的输出。这需要之后的研究一步步解决。
●
●
●
2. 拉普拉斯金字塔(Laplacian Pyrami)的应用
GANs 最重要的应用之一,是生成看起来‘自然’的图像,这要求对生成器的充分训练。以下是 Ian Goodfellow 等人的 2014 年论文中,生成器输出的样本:

可以看出,生成器在生成数字和人脸图像方面做得不错。但是,使用 CIFAR-10 数据库生成的风景、动物图片十分模糊。这是 GANs 早期的主要局限之一。
2015 年 6 月 Emily Denton 等人发表的研究《Deep Generative Image Models using Lapalacian Pyramid of Adversarial Networks》(“深度图像生成模型:在对抗网络应用拉普拉斯金字塔”)改变了这一点。研究人员提出,用一系列的卷积神经网络(CNN)连续生成清晰度不断提高的图像,能最终得到高分辨率图像。该模型被称为 LAPGANs 。
其中的拉普拉斯金字塔,是指同一幅图像在不同分辨率下的一系列过滤图片。
与此前 GAN 架构的区别是:传统的 GAN 只有一个 生成器 CNN,负责生成整幅图像;而在拉普拉斯金字塔结构中,金字塔的每一层(某特定分辨率),都有一个关联的 CNN。
每一个 CNN 都会生成比上一层 CNN 更加清晰的图像输出,然后把该输出作为下一层的输入。这样连续对图片进行升采样,每一步图像的清晰度都有提升。
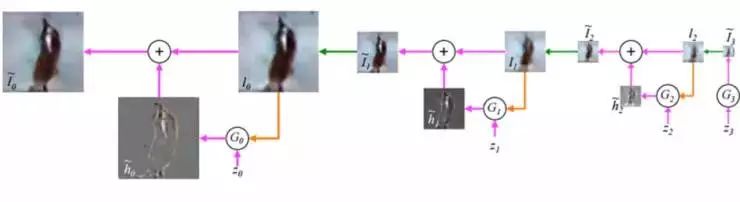
拉普拉斯金字塔结构图像生成示意
这产生了一个新概念:有条件生成对抗网络(conditional GAN,CGAN),指的是它有多个输入:低分辨率图片和噪音矢量。该研究生成的高质量图片,在 40% 的情况下被真人裁判当做真实图像。
对该研究的意义,李嫣然评论道:它将 GAN 的学习过程变成了“序列式” 的——不要让 GAN 一次学完全部的数据,而是让 GAN 一步步完成这个学习过程。
●
●
●
3. 利用 GANs 把文字转化为图像
把文字转化为图像,比起把图像转为文字(让 AI 用文字概括、描述图像)要难得多。一方面是近乎无限的像素排列方式;另一方面,目前没人知道如何把它分解,比如像(图像转为文字任务中)预测下一个词那样。
2016 年 6 月,论文《Generative Adversarial Text to Image Synthesis》(“GANs 文字到图像的合成”)问世。它介绍了如何通过 GANs 进行从文字到图像的转化。比方说,若神经网络的输入是“粉色花瓣的花”,输出就会是一个包含了这些要素的图像。该任务包含两个部分:1. 利用自然语言处理来理解输入中的描述。2. 生成网络输出一个准确、自然的图像,对文字进行表达。
为实现这些目标,生成器和判别器都使用了文字编码技术:通过循环文字编码器(recurrent text encoder)生成的文字属性,来作为条件对 GAN 进行训练(在雷锋网公众号回复“
GAN
”下载论文)。这使得 GAN 能够在输入的文字描述和输出图像之间建立相关性联系。

原理示意
该任务中,GAN 其实完成了两件任务:1.生成自然、说得过去的图像;2.图像必须与文字描述有相关性。

利用 GAN, GAN-CLS, GAN-INT,GAN-INT-CLS 生成的结果示意。GT 是真实图像,从左到右三组图像的任务分别是:1.全黑色的鸟,粗圆的鸟嘴;2.黄胸、棕冠、黑眉的小鸟;3. 蓝冠、蓝羽、黑颊的超小鸟,嘴小、踝骨小、爪小。









