迁移学习(Transfer learning),顾名思义,就是把已知学到的知识应用于理解未知事物上,这很符合我们的认知过程。举个最简单的例子,假设我们给朋友介绍一种新产品,就叫“奇里古刹币”(乱编个名字也是很费脑细胞的),你很难讲解其中的逻辑。但你如果这么说:“类似于比特币,属于虚拟货币的一种,只不过仅限于购买牛奶”。你的朋友可能瞬间就理解了,“哦,原来如此”。
我们尝试分析一下你朋友大脑的运作:
第一步:把对比特币的认知直接转移(transfer)到了“奇里古刹币”
第二步:以此为基础,再加上限制条件“仅限于购买牛奶”
如此,便完成了迁移学习的过程。
事实上,迁移学习是每个数据分析师的必备技能,它不是一种算法模型,甚至称不上一种技术,只是一种方法论,或者说是一种模型设计思路。
迁移学习的基本概念
#定义#
对于两个相关场景A和B,A有大量的标签,B仅有少量标签或没有标签。迁移学习是指通过将对A学习的结果转移到B的建模中,以此提高B的建模效率。
#为什么要进行迁移学习#
建模人员都知道,有监督机器学习需要大量的标签数据,而为数据打标签十分耗时,而且通常需要大量人力参与,因此是一笔巨大的开销。对于一般有监督学习,我们通常会采用随机的方式初始化参数,再进行不断的迭代学习得到收敛的参数组合。我们可以这么理解,迁移学习实际上是特殊化的初始化流程,也就是,我们的初始化不是采用随机参数方式,而是将其他相关场景的训练结果拿来,作为这个模型的初始化。
迁移学习的主要优势
首先,迁移学习可以提高机器学习的效率。这显而易见,通过迁移学习,你可以不再通过随机的方式初始化参数,站在巨人的肩膀上learning,相比于从零开始的模型,必然已经赢在起跑线上了;
其次,迁移学习可以降低对训练数据的量级要求,尤其对于深度学习。试想,对于一个五层神经网络模型,功能是识别男女。那么,你拿一个识别人类的三层神经网络作为基础,进行迁移学习,那么,你只需要训练后两层即可,而无需从零开始。可想而知,这样的话,对于标签数据的数据量要求就少得多了;
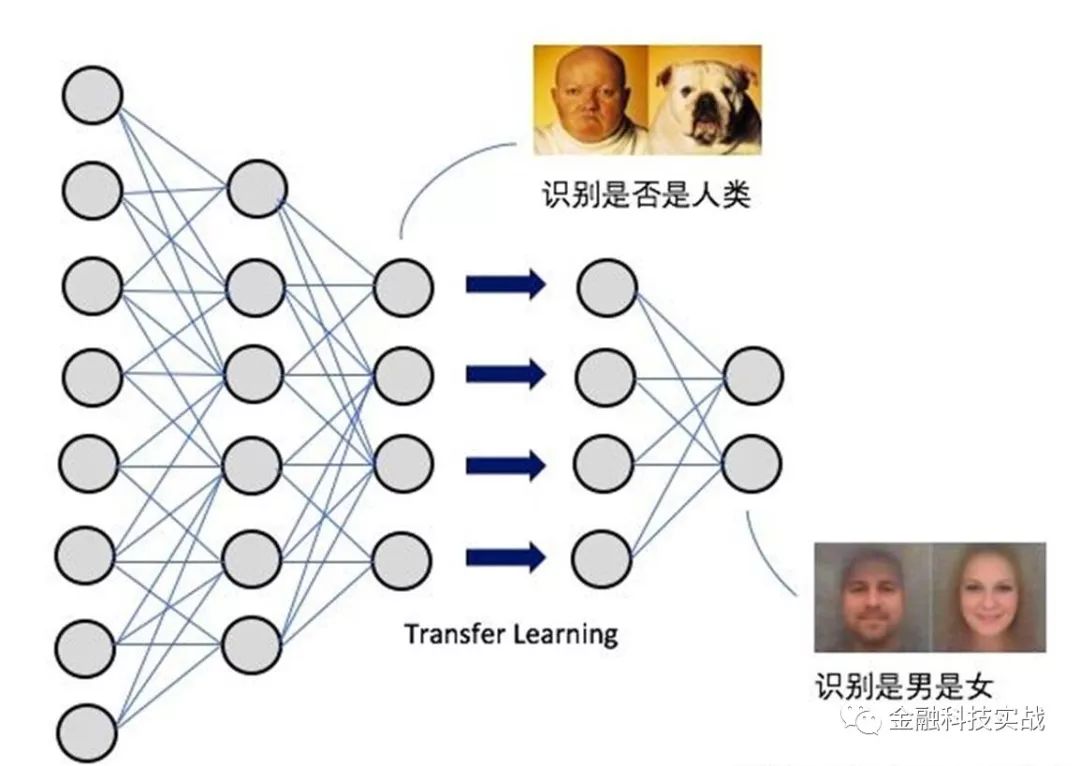
迁移学习示意图
最后,迁移学习的适用性较强。迁移学习虽然不能应用在任意场合,但只要两个场景具有一点相关性,即可以使用迁移学习。例如,国内某公司,其团队开始主要做精准营销,对客户进行分群,目的是识别出其需求和鉴别购买力。后采用迁移学习进行欺诈识别,虽然场景不尽相同,捕捉到人群特征也不尽相同,但其在精准营销上训练的模型参数可以作为反欺诈模型的初始化,以此节约训练时间。同样,对于反欺诈业界所提倡的联防联控,除了共享黑名单数据库外,其另一个比较重要的应用就是迁移学习。事实上,国内某知名电商日前发布的关于骗保反欺诈产品,就是以其商城购买行为分析模型为基础构建的,这也是一种迁移学习。
总之,迁移学习并非一种技术,而是一种方法论。其根本目的就是“站在巨人的肩膀上”建模,而至于能否采用“迁移学习”,就要看你有没有找对这个“巨人”了。跟“巨人”的场景关联性越高,迁移学习的适用性就越好。而如果你胡乱找错人,那么可能会一不小心掉进大坑,反倒费时了。
迁移学习的三种类型
迁移学习的关键,用四个字概括,就是“找对巨人”,也就是需要找到不同场景之间的关联和共性(特征),本文就系统性地介绍一下迁移学习的几种方法。
首先,来看几个定义。
1. Domain:
包含两个component,一是向量空间X,一个是X的分布P(X)
2. Task:
给定一个特定的domain和label空间Y,对于domain里每一个xi,都可以预测出相应的yi。通常,如果两个task不同,那么其通常有不同的label空间,或者不同的条件分布P(Y|X)
3. Source domain:
如果把一个task A上的knowledge迁移到taskB上,那么就说task A对应的domain就是Source domain, P(XS)
4. Target domain:
如果把一个task A上的knowledge迁移到taskB上,那么就说task B对应的domain就是Target domain, P(XT)
下面,根据标签的情况,将迁移学习分为三种类型:

Vontear在其blog里有一个形象的说明,在此引用下其说明:
Transductive Learning
:从彼个例到此个例,有点象英美法系,实际案例直接结合过往的判例进行判决。关注具体实践。
I
nductive Learning
:从多个个例归纳出普遍性,再演绎到个例,有点象大陆法系,先对过往的判例归纳总结出法律条文,再应用到实际案例进行判决。从有限的实际样本中,企图归纳出普遍真理,倾向形而上,往往会不由自主地成为教条。
而对于
unsupervised learning
,属于比较普遍的内容,在此不再赘述。
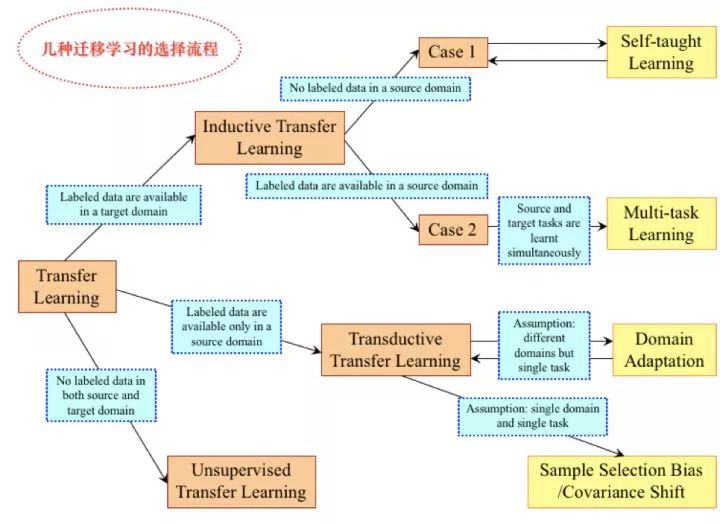
几种迁移学习的选择流程,如下图所示:
风控与反欺诈的应用场景
根据迁移的对象,可以将迁移学习分为四种类型,进一步展开就是风控与反欺诈的应用场景。以下,具体介绍一下几种常用的思路。
1、Inductive Transfer Learning + Instance-transfer
适用条件
:Source Domain和Target Domain数据的特征(feature)和标签(label)完全相同。
处理方式
:重新调整source domain的权重,应用于target domain。
举例
:信用卡申请的申请表和小额贷款的申请表的申请字段相同,其他埋点信息也相同,且最终的结论都是【通过】和【拒绝】。那么,在两者的申请场景下,可以采用此种方法。
2、Inductive Transfer Learning + Feature-representation-transfer
适用条件
:Task之间具有一定关联性,且包含共同的特征
处理方式
:把每一个task作为输入,用task之间共同的feature来建模。解释一下,首先你要通过一些方法将source domain里无标签的数据做一个更高level的提炼,称为representation;然后要将target domain的数据也做一个类似的转换,即representation;这样,我们就可以用可以利用representation来作为建模,且使用与representation相关的标签了。(很像求最小公倍数的思路)
举例:
这也是一种常用的思路。举一个最经典的例子,信用卡还款,有各种逾期行为,我们定义坏人的方式是认为M3&M3+;消费贷分期,也会有各种没有按时还款的行为,而这个定义是M2&M2+。看上去两个定义不同,但我们给这样一个新定义:坏人。此处,【坏人】就是一个共同的feature,也就是我们的定义representation。
3、Inductive Transfer Learning + Parameter-transfer
适用条件
:Task之间具有一定关联性,且在某个独立模型中共用一些参数。







