
版权声明
作者:百度云资深工程师
本文为原创投稿。
随着移动互联网慢慢进入后半场,越来越多的公司将注意力转移到物联网,希望通过早期布局来起到占领这个行业的制高点,比如目前流行的摩拜单车,OFO 单车都是典型的物联网应用。物联网本身并不是什么新概念,随着大数据,AI 等技术的发展,大家意识到传统的物联网通过一定改造,借助大数据以及 AI 技术可以获得很多额外的价值。
这里主要介绍物联网的接入服务,物联网主流接入协议分为 MQTT,CoaP,Http,XMPP 等几种,本文主要是介绍 MQTT 协议的优缺点以及如何实现 MQTT 的分布式框架,至于各个协议之间的比较就不再这里详细介绍,大家可以百度相关资料去做详细了解。
MQTT 协议是为大量计算能力有限,且工作在低带宽、不可靠的网络的远程传感器和控制设备通讯而设计的协议,它具有以下主要的几项特性:
使用发布 / 订阅消息模式,提供一对多的消息发布,解除应用程序耦合;
对负载内容屏蔽的消息传输;
使用 TCP/IP 提供网络连接;
有三种消息发布服务质量:
“至多一次”,消息发布完全依赖底层 TCP/IP 网络。会发生消息丢失或重复。这一级别可用于如下情况,环境传感器数据,丢失一次记录无所谓,因为不久后还会有第二次发送。
“至少一次”,确保消息到达,但消息重复可能会发生。
“只有一次”,确保消息到达一次。这一级别可用于如下情况,在计费系统中,消息重复或丢失会导致不正确的结果。
小型传输,开销很小(固定长度的头部是 2 字节),协议交换最小化,以降低网络流量;
使用 Last Will 和 Testament 特性通知有关各方客户端异常中断的机制。
车联网
工业物联网
智能家居
视频直播弹幕
IM 实时聊天 (一对一聊天,群组聊天)
推送服务,比如推送实时新闻
金融交易数据订阅推送
单机版本的 MQTT 存在并发连接数上限以及处理能力的限制,主流的单机版本的 MQTT 服务包括 ActiveMQ, RabbitMQ,Apollo,Mosquitto,分布式的 MQTT 服务包括知名的 EMQ, VerneMQ 都是采用 Erlang 实现的。
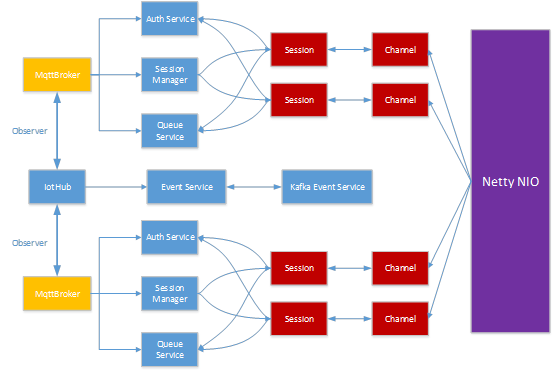
分布式版本的 MQTT 相对于单机版本最大的难点在于 Session 的管理,特别是持久化 session,MQTT 协议定义了两种 Session,其中一种是 transient Session,另外一种是 Persistent Session,用户可以通过在发送连接协议包的时候设置 clean session 这个状态位来决定采用哪种 session。另外一个难点就是集群的管理,这里设计的框架是每个 broker 都是对等,他们之间不存在什么主从关系,所以我们直接 AKKA Cluster 这个框架作为集群管理,每个 broker 都需要注册监听的时间包括 MemberUp,MemberDown,MemberUnreachable,ClusterMemberState 等事件,这样每个 broker 就很可以很好的感知其他节点的状态,对内部的 session 做相应的处理,broker 和 broker 之间的消息通知采用 Akka actor 来实现。

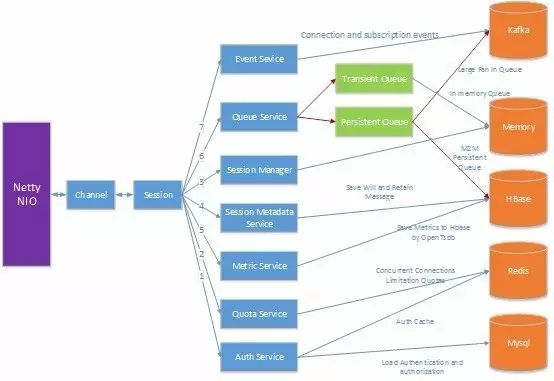
为了管理,以及设计方便,我们将内部服务抽象成为很多独立服务,这些服务包括:
Authentication and authorization service
a) 该服务负责用户名,密码等认证方式的鉴权,以及每个 client 对于那些主题有权限进行读和写,后台数据全部保存在 Mysql,通过 redis 做 cache 加速,当然也做 in memory 的 cache 加速,cache 回收机制采用 LRU 策略
Session Manager
a) 持久化 session 管理,包括 session 订阅什么主题,以及对应的 persistent queue,该 session 需要在每个 broker 都同步一份,这样可以有效解决高可用性的问题,比如 crash 之后,不会受到影响
b) 非持久化 session 管理,包括 session 订阅什么主题,以及对应的 transient queue,该 session 只需要在连接机器上保持,不需要同步到其他的 broker 上,如果对应的 client 和 broker 失去连接之后,对应 session 信息就会被清除掉
Event Service
a) 负责将连接,订阅等事件发送给每个 broker,对于每个连接事件,我们都需要将该消息推送给 event service,还有就是每个 client 的订阅主题,取消订阅主题的事件,目前 event service 的后端实现采用 Kafka 做的,当然也可以通过 Akka 本身提供的功能来做,考虑到需要持久化,所以采用了 Kafka,后期我们减少对 Kafka 的依赖
Session State metadata service
a) 负责持久化 session metadata 数据存储,该服务从 Event Service 订阅数据,然后决定哪些数据需要持久化到后端存储(采用 Hbase 做持久化存储),目前主要是存储持久化 session 相关的信息
Queue Service
a) 管理以及分配 queue,这里的 queue 分为两种,一种是 transient queue,一种是 persistent queue,transient queue 是采用 in memory 的方式实现,persistent queue 是采用 Hbase 实现。Transient queue 是为 transient session 创建的,persistent queue 是为 persistent session 创建。Persistent session 的特点就是即使该 session 对应的连接断开了,我们也需维护该 session,以及该 session 订阅的数据,以便下次这个 client 重新连接上来之后,自动恢复 session 的状态,还有下发没有处理完的订阅数据
Quota Service
a) 管理包括并发连接数,上行带宽,下行带宽的限制
Metric Service
a) 监控服务的并发连接数,并发消息数,当前流量,服务运行指标,包括 CPU,memory,网络等相关指标
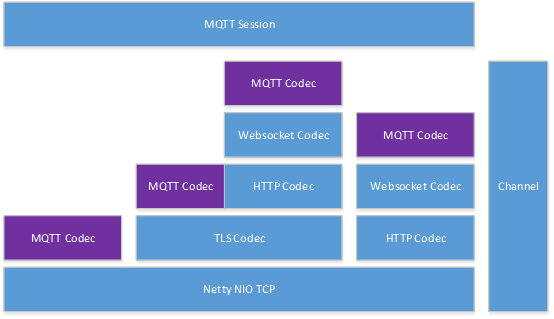
连接层采用 Netty NIO 框架,关于 Netty NIO 的详细设计,这里我们就不做介绍了。支持 4 种形式的接入方式,TCP,TLS,websocket over TLS,以及 websocket,各个接入方式的 codec 层级关系可以参考下图。
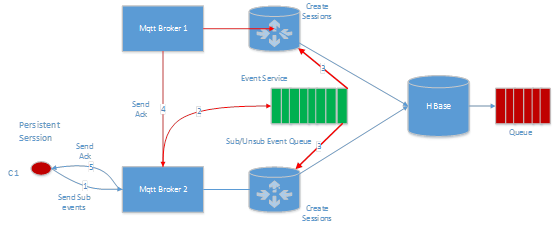
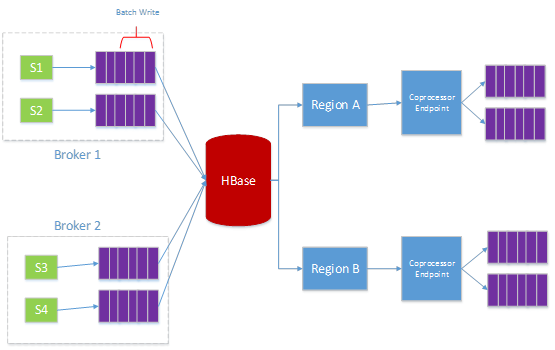
对于持久化 session,需要将该 session 信息同步到每台机器,每台机器都有所有持久化 session 信息的全集,这样做的好处就是当某台 broker 无法工作了,连接在这个异常 broker 上的 client 不会丢失消息,每条 publish 的消息都是直接写入 hbase 的,当 broker 恢复,或者 client 连接到其他 broker 之后,可以继续从 hbase 获取数据,然后发送给订阅的 client。
订阅消息会发往 event service,每个 broker 都会订阅来自 event service 的数据,对于持久化 session,每个 broker 都会创建对应 session 的订阅信息以及 virtual queue,这个 virtual queue 分为 client 和 server 两部分,client 端的 virtual queue 负责保证写入顺序,以及批量写入(提升效率),server 这边的 queue 保证来自不同 broker 的消息的有序性。
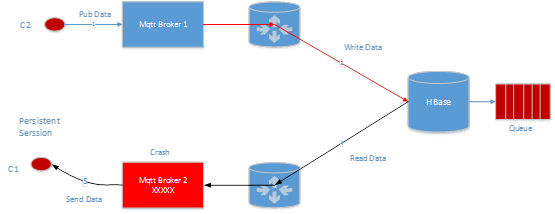
C2 往 C1 订阅的主题发送一条数据,router 会直接将数据写入 C1 对应的 hbase queue,然后通知 C1,告诉他有新的数据可以消费了,这个时候 broker 直接从 hbase 读取数据,然后发往 C1。
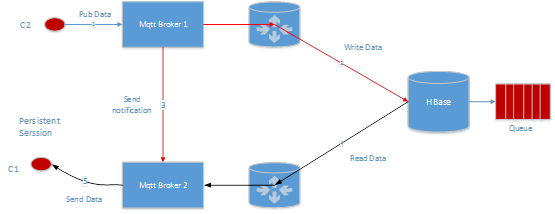
如果 Mqtt Broker 2 出现 crash 了,比如这个进程挂了,或者 Mqtt Broker 2 所在的机器断电了,或者网络出现故障了,C1 本来应该收到的数据并不会减少,由于 Mqtt Broker 1 会继续往 Hbase 写入数据,等 C1 重新连接之后,可以继续从 Hbase 消费数据。
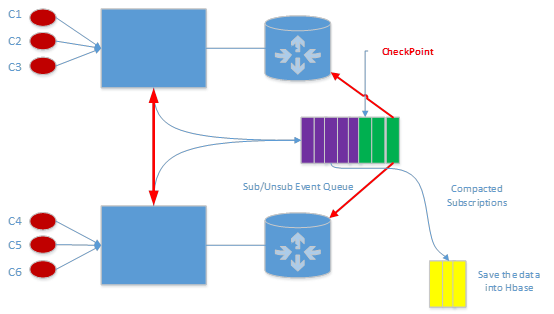
Event service 数据的 Compaction
考虑持久化 session 相关的数据都是写入到 kafka 的,如果一个新的 broker 加入集群,首先就需要将持久化 session 的信息全部加载,如果加载都是从 kafka 主题的头部开始消费数据的话,可能会花费很久,为此我们需要将 kafka 的数据做 compaction,这些 compaction 的数据写入到 hbase,如何加载全量信息了,全量信息就是 hbase 数据的集合和备份 checkpoint 之后 kafka 数据集合 merge 结果就是最终的全量信息。
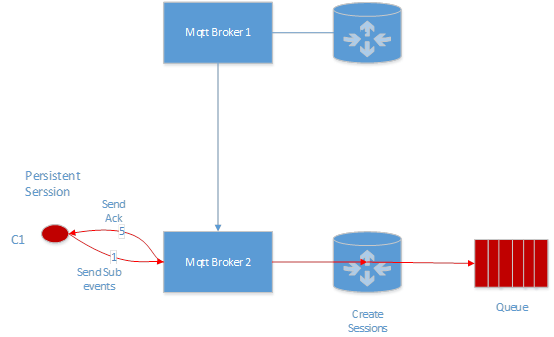
当非持久化 session 的 client 连接上来的时候,如果订阅主题,我们会直接在改 client 所在机器创建 session 以及 session 对应的 queue。
订阅消息流程:
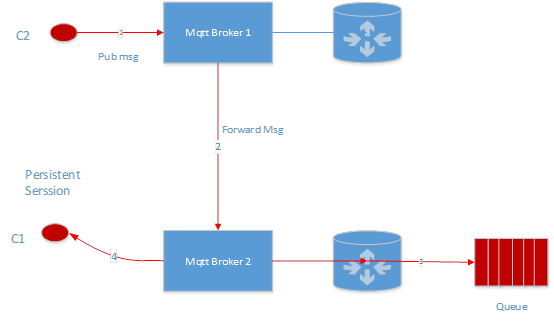
发送消息流程:
当 C2 发送一条消息的时候,broker 1 会把消息转发给 broker 2, broker 2 会先把消息写入到 C1 对应的 in memory queue,然后发送一个有数据的 event 给 C1,这个时候 broker 2 会从 queue 读取数据,然后发往给 C1。
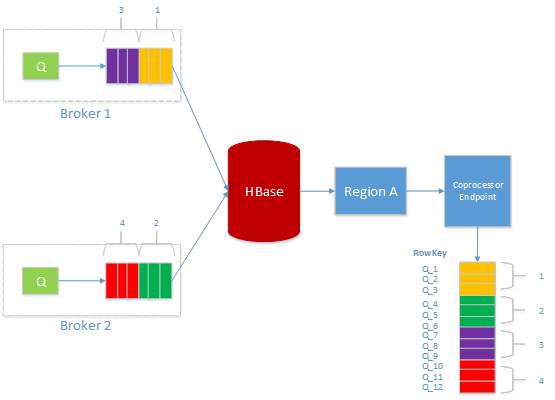
Hbase 本身不提供 queue 这个功能,但是我们可以利用 hbase 特性来实现 virtual queue 的概念,通过设计好 rowkey 来保证消息的有序性,然后将数据的读取转化为 scan 操作,下图有 4 个 client,我们为每个 client 分配一个 unique 的 queue ID,然后每个 queue 的数据通过 queue ID 和单调递增的 ID 来组合成为一个 unique 的 rowkey,为了保证写入的均匀性,我们需要合理设计 unique ID 的 prefix 来保证将这些 rowkey 均匀的分布到不同的 region。
为了实现 queue 的功能,我们在 Hbase 上定义了一个新的 coprocessor,这个 coprocessor 用来创建 queue,管理 queue 的数据,以及删除 queue,同时还可以修改 queue 的配额等等。下图是我们的一个事例,我们有 4 个 client,每个 client 都有自己的 queue,通过算法把这些 queue 均匀的分布到不同的 region 上使用定制 region split 算法。
定义 queue name 为 reverse{clientId}_tenantId,这里的 clientID 是系统生成的,是 64bit 的 long,我们为每个 client 生成一个 ID,这个 ID 是单调递增的,加入我们预期 region 的数目为 128 个的话,那么我们就取 reverse{clientId}的头 8bit 作为 region 分割的条件,这样我们就可以把不同的 queue 均匀分布到不同的 region 上了,然后对 region 做 balance。
对于持久化消息队列,需要在每个 broker 上都建立一个 virtual queue,该 virtual queue 对应 hbase 的真实 queue,每次 virtual queue 的数据都是 batch 写入 hbase,假设这个 queue 的名字为 Q 的话,我们会为每个写到 hbase 的消息分配一个 unique 的 ID,该 ID 是 Q_(ID),ID 是一个单调递增的数字,采用 64bit 的 long 表示,每个 batch 写入到 hbase 的 coprocessor 之后,需要先获取该 queue 的 lock,然后分配 ID,然后将数据写入 hbase,最后释放 lock,这样下一个 request 就可以继续写入,这里 lock 的粒度是 queue 级别,就是每个 queue 都会有自己的一个 lock,这样可以保证并发性。
我们会为每个 queue 保存该 queue 在 Hbase 的最小 ID,以及最大 ID,如果该 queue 的最小 ID 和最大 ID 由于 cache 失效,导致内存不存在的话,我们就通过 hbase 的 scan 操作,来获取最小的 ID,以及最大 ID,然后将数据保留到 cache 里面,这样可以加速下次查找,每次读取特定长度的数据,下次计算便于继续读取,读数据的时候并不需要获取锁,由于读数据只会来自一台机器的一个 client,就是任何时刻只有一个 client 在读数据。
这里的删除已经读取的数据,由于我们的数据都是有序的,所以删除的时候,只需要告诉 queue 需要删除多长的数据即可,然后我们根据最小 ID,以及 offset 可以算出需要删除 rowkey 的 ID,然后执行一个 batch delete 操作,这样就可以将数据删除了,删除数据也不会需要获取锁,由于删除请求只会来自一台机器的一个 client,就是任何时刻只有一个 client 在删除数据。
同时由于 Hbase 目前并不存在官方的 async 的 library 来往 hbase 写入数据,或者读取数据,目前只有 opentsdb 提供一个版本,考虑我们是利用 coprocessor 增加了一个新的 endpoint,但是 opentsdb 的 async library 并不支持 coprocessor,为了我们需要扩展 async 的 library,这样就可以 async library 的 coprocessor 库来处理数据。
如何利用 in memory compaction 来优化 hbase queue 的性能指标,由于 mqtt 的消息写入 hbase 之后,基本马上就会被读取出来,然后发送给 client,所以说 mqtt 的消息都是属于 short lived 的数据,如果这些数据都在 in memory 做 compaction 的话,那就意味我们不需要将这些数据写入 HFile,只需要写 WAL 日志,这样可以极大的降低 HDFS 文件系统的 IO,对于我们这种场景的话,Hbase 的瓶颈就出在 HDFS 文件系统的读写上,目前 in memory compaction 已经在 hbase 2.0 上实现,不过没有正式 release。
更多 in memory compaction 的资料可以参考:
Accordion: HBase Breathes with In-Memory Compaction
https://blogs.apache.org/hbase/entry/accordion-hbase-breathes-with-in
Internal design:
https://blogs.apache.org/hbase/entry/accordion-developer-view-of-in
每种 queue 都有自己的优缺点,为此我们提供了多种 queue 可以供用户选择,额外提供 redis 以及 kafka 的 queue,kafka 的 queue 是一种很 popular 的方式,主要是用在大规模扇入场景,比如说 100w 个 client 都往同一个主题发送消息,如果采用 in memory 的 queue 或者 hbase 的 queue,那么瓶颈就会出在订阅端(只有一个 TCP 连接来处理数据),如果采用 kafka queue,可以将数据发往 kafka 的主题,然后调用 kafka 的 client 来消费数据,这样就可以完美解决大扇入的场景。
目前 MQTT 服务是一个分布式多租户的服务,一个 IotHub 上面会有很多租户的 MQTT Broker,每个 MQTT broker 对应一个 tenant,每个 broker 有自己的 authentication service, session manager, Queue service,以及很多其他服务,包括 unique Id generator,backend storage service,以及 router 服务,当一个 client 的通过 TCP 和我们的服务建立连接之后,首先我们会为该 client 创建一个 session,这个 session 会检查该 client 是否合法,包括 tenant 名字,用户名,密码,如果所有的都合法的话,我们会把这个 client 的 session 添加到 session manager,如果不是合法的,我们会直接把这个 client 的连接给断开。
MQTT 采用 TCP 的方式和云端建立连接,我们通过用户名来区分这个 client 对应的是那个 tenant,所以我们对用户名有严格的规定,用户名必须是{tenant Name}/{clientName},拿到用户名和密码之后,我们先算出该 client 对应的 tenant name,然后获取该 tenant 对应 broker 实例,后去该 broker 的 auth 服务来认证用户名和密码组合。
Baidu IoT Hub vs EMQTT
MPS: message per seconds
消息 payload 大小: 1024 bytes
场景:一半 pub 和一半 sub,每一个 pub 对应一个 sub,也就是说通过唯一主题关联起来,这种场景是对 MQTT 协议最严格的考验,其他场景相对来说 CPU 消耗会少一些
测试 Queue 类型:In memory queue
Notes:
由于 Pub 和 Sub 是一一对应的,所这里的 MPS 是指 PUB 的 QPS,所以实际 QPS 是这个数字的两倍。


可用 MPS(无丢包,latency 小于 0.5s):

结论:同等连接数下,IoT Hub 的可用最大吞吐量在 EMQTT 的 1~2 倍之间。
部署 broker 机器配置信息:
vendor_id: GenuineIntel
cpu family: 6
model: 45
model name: Intel(R) Xeon(R) CPU E5-2620 0 @ 2.00GHz
core: 12
Memory:
MemTotal: 132137288 kB
更多关于百度 IoT Hub 使用信息可以访问官网:https://cloud.baidu.com/product/iot.html
今日荐文
点击下方图片即可阅读

百度无人车和天工物联网都使用了时序数据库,但是你有多了解时序数据库?










