编者按:12月18日,腾讯大数据峰会暨KDD China技术峰会在深圳举行,华为诺亚方舟实验室主任李航博士在会上做了题为《自然语言处理中的深度学习:过去、现在和未来》的演讲,雷锋网根据现场演讲整理成本文。

深度学习在自然语言处理中的应用,大概可以分成两个阶段。
现在第一阶段已经基本结束,开始进入第二个阶段。所以,未来自然语言处理深度学习的发展趋势应该是一个神经处理和符号处理的结合的混合模式。
我在阐述这个观点的过程当中,也会介绍一下华为诺亚方舟实验室做的一些工作。华为诺亚方舟实验室,在整个华为的战略里,是肩负着人工智能、机器学习和数据挖掘方面的研究任务,既有偏长期的工作,也有偏短期的、产品化的工作,那么我今天主要是讲一讲,我们已经进行的基础性长期性的工作。主要包括自动问答、图片检索、机器翻译、自然语言对话领域里,我们做了哪些模型,取得了什么样的效果。
●
●
●
自动问答系统
如今的自动问答系统最简单的实现方式就是检索。
假设我们有一个问答库,问答库充满了FAQ(常见问题),我们可以把它索引起来构建一个检索系统。那么如果来了一个新问题,我们可以用检索的技术,针对问题找到一系列答案候选,把候选答案与问题做匹配并做一个排序(把最相关的答案排在前面),最后把最合适的答案反馈给用户。
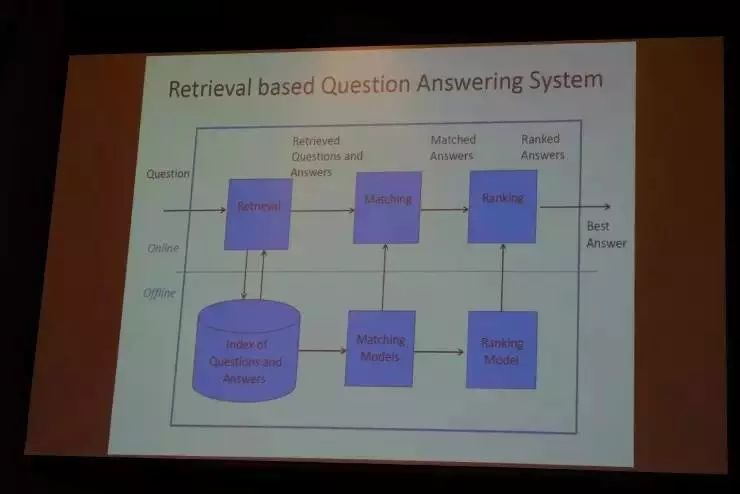
这里面有两个很重要的技术,一个是匹配(Matching),一个就是排序(Ranking)。匹配和排序,往往是通过离线学习来完成的,其中要构建很好的匹配模型和排序模型。
我们提出了这样的一个匹配模型“Deep Match Model CNN”,在业界一定程度上被广泛使用。其中最基本的想法就是,用卷积神经网络来去判断,一个问句和一个答句二者是否可以匹配得很好。

这是一个二维模型(一个问句和一个答句),我们把每一句话看做是词的序列,每个词用向量来表示,那么每句话是“向量序列”。我们这个模型可以通过卷积和最大池化从两个“向量序列”里抽取特征,从而根据特征来匹配。
●
●
●
图片检索
图片检索,指的就是把图片和文本相匹配,即给定一张图片,对应找到一个自然语言描述;或者反过来,给定一个自然语言描述,找到一张相关图片。
在深度学习出来之前,类似“图片检索”这样的事往往是不能做的。现在我们可以用卷积神经网络来做图片和文本的匹配。我们这里有两个CNN,左边的CNN抽取图片的特征,右边的CNN抽取文本的特征,二者的特征做匹配。我们基于大量的这种“成对”的数据来训练模型。
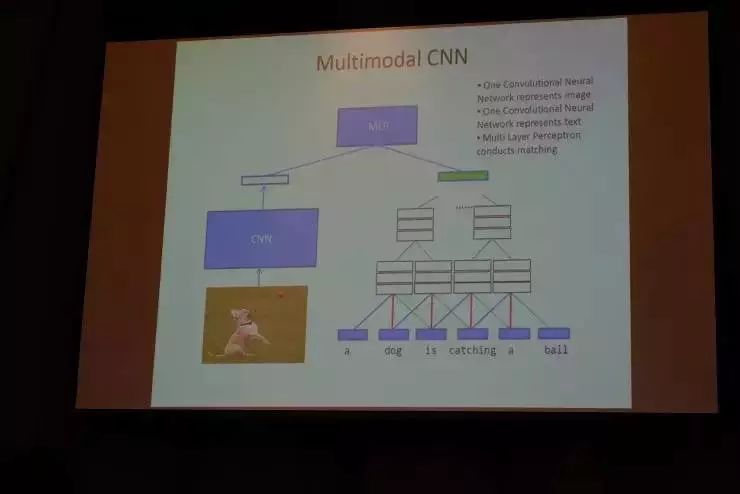
下面我给大家做一个演示,这是我们基于30万对的文本和图片,训练得到的一个匹配模型。比如,你输入一个自然语言描述“跟朋友公园玩耍的照片”,便得到如下图片检索结果。
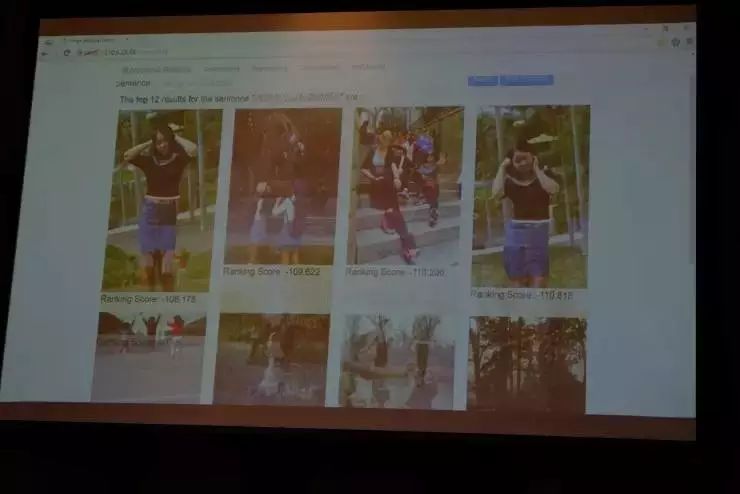
我们把从网上爬来的每张照片里,人为标注了两三句话的描述,有了这样的标注数据之后,我们构建了刚才所讲的匹配模型。除此之外,没有对图片和自然语言做任何其他的处理。我们在检索结果里可以看到,头10张图片里往往都有两三张非常相关的图片,准确率是相当高了。
●
●
●
机器翻译
现在用神经网络去做机器翻译的话,最典型的模型是基于循环神经网络RNN模型,也叫做“序列对序列学习”(Sequence to Sequence Learning)。如果现在我们把中文翻译为英文,那么中文就是“源语言”,英文就是“目标语言”。
前面我们提到,可以把自然语言描述转变成“向量序列”。机器翻译,实际上就是把中文(源语言)表示的“向量序列”转换成英文(目标语言)的"向量序列",然后进行这种翻译。
这个当中有一个重要的机制,叫做Attention,将源语言序列和目标语言序列动态对应在一起。比如现在要生成“Sitting”这个单词,那么我们就要通过Attention机制,反向从源语言中找到跟“Sitting”最相关的单词“坐”。
我们在已有的模型基础上做了一个比较大的改进,在其中加入了一个覆盖向量机制(Coverage Vetor)。为什么要引入这个机制呢?传统的神经翻译机器模型,会产生过翻译(重复翻译)或少翻译的现象,那么Coverage Vetor机制,就用来记忆到目前为止,我们到底翻译了多少内容,并据此动态地去调整Attention机制。
比如在英文里面我们要产生"The"这样虚词的时候,它受到源语言的影响比较少,因为这是英文自己的语言特性决定要用“The”这样的词,所以这时就需要我们的Attention弱一些。所以我们需要动态地去调整Attention机制,从而大幅度提高机器翻译的准确率。
下面看一看我们的模型运行的效果。比如,我们到互联网上随便找一句话:
“据韩国媒体报道,因为大量中国游客取消预约,正在韩国大邱居心搞得‘炸鸡啤酒节’一项核心活动告吹。”
以下分别是诺亚方舟的神经模型和网上某个在线翻译系统给出的结果,大家可以对比来看。
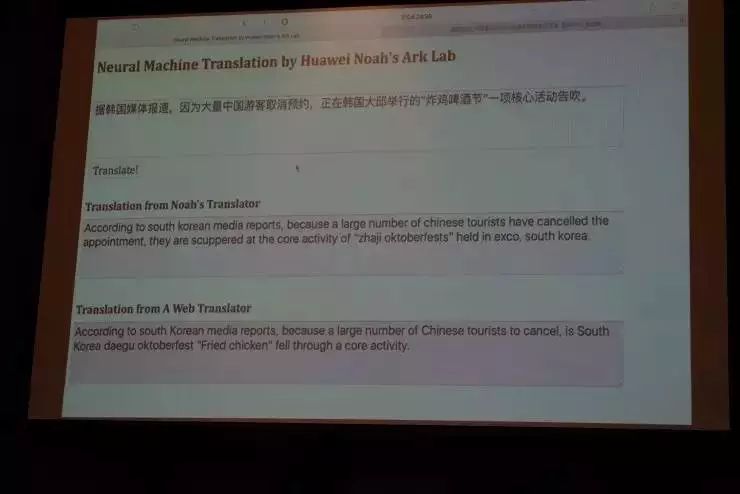
需要提到的一点是,我们的这个模型是最基本的状态,并没有做其它工程上的事情。粗略来看的话,我们用这个深度学习做出的翻译结果更加流畅,当然也有一些问题,就是有些词它还没有翻译出来。
那么我们这个系统跟其他业界相比,是个什么水平呢?
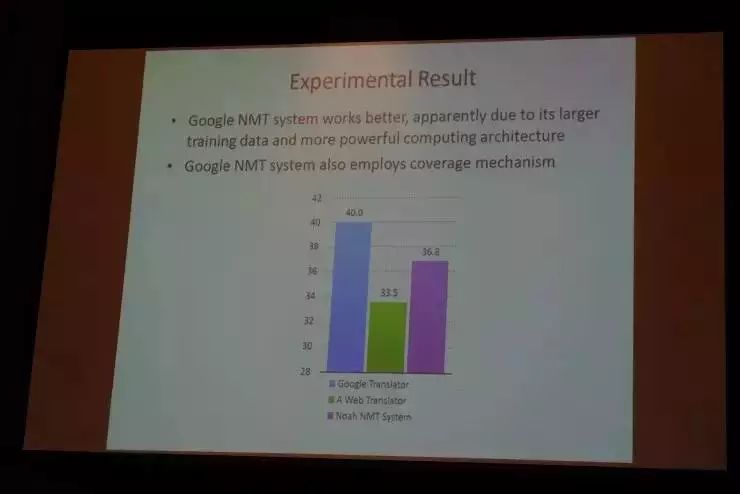
在同一个测试题上,我们跟谷歌的NMT神经系统相比,还是有点差距(大约差3-4个百分点),因为他们有更大的训练库和更强的计算架构。但我们这个非常初级的模型,相比于互联网的一般的搜索引擎里面提供的机器翻译功能,效果已经好很多了。
●
●
●
自然语言对话
在自然语言对话这块,我们提出了一个叫做“Neural Responding Machine”的模型,这是业界第一个完全基于深度学习的模型去做的单轮对话系统。
刚才我们谈到的几点,包括自动问答、机器翻译,都是基于“检索”的,那么对话系统的特点,就是基于“生成”的。
当你输入一句话到这个系统里,这个系统会自动产生一个回复,这个模型是通过大量的数据训练出来的,也是一个“序列对序列学习”的模型。那么下面,我们可以看一下演示。
这个系统是我们根据微博400万份数据训练而成的,比如当你输入“我想买一部三星手机”,系统会自动生成回答“还是支持一下国产吧”。
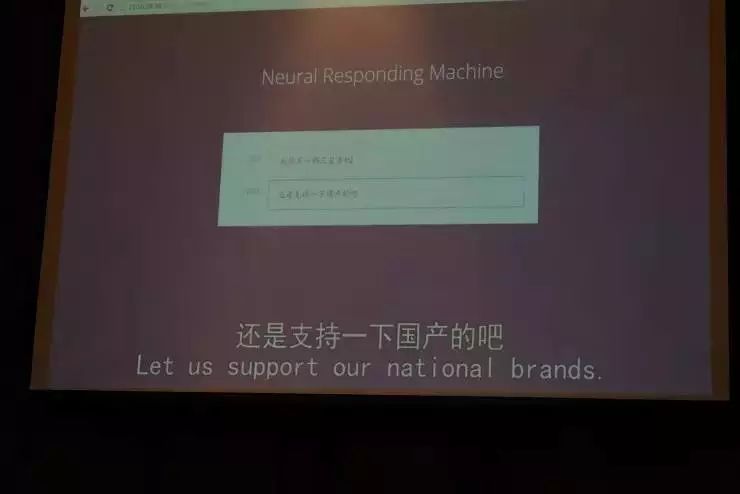
这句生成的话,不是我们教它说的,而是它自己产生出来。我们来看第二个例子。
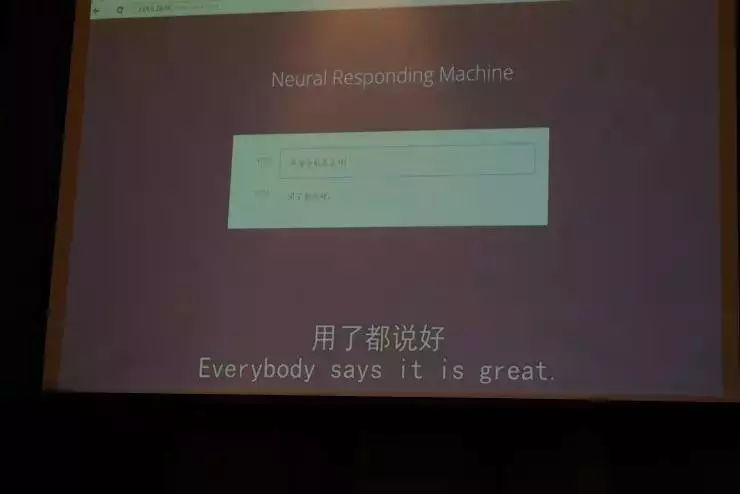
(台下爆发一阵笑声)第二个例子实际上是开玩笑的,如果多次让系统看到这样的对话,它就会这样去说了。
所以这个模型是有记忆功能的,但却不是死记。在经过大量数据训练之后,它能够在96%的情况下产生自然的回复,这个是非常令人吃惊的。并且在76%的情况下,可以形成一个单轮的对话。其实自然语言对话还是非常难的,刚才看到这样的简单机制还是很难帮我们真正地去实现自然语言对话系统,这是需要大概上亿参数、几百万的神经元,把对话的模式(Pattern)记忆下来,从而产生回复。
●
●
●
神经处理与符号处理结合
刚刚的几个例子里,用大数据、深度模型完成一些端到端的任务,而且准确率还不错。特别是图片搜索和机器翻译方面,有的甚至可以接近和达到实用水平。同时,我们也明显看到深度学习在自然语言处理方面的一些局限,它针对长尾现象比较弱,很难结合人类的知识。在实际应用中,我们希望将类似人类的一般知识放到机器系统里,让这个系统能够跟我们人一样,使用这些知识。如果纯粹使用神经网络模型往往是比较困难的,所以未来的自然语言处理的发展方向,应该是深度学习(神经处理)与符号处理的结合。
所以我们面临很多挑战性的任务,但我们已经开始在这方面做一些尝试。
下面介绍几个例子,一个是在自动问答领域,我们提出一个名为“Neural Enquirer”的模型,当然我们现在还在不断改进这个模型。这个模型最基本的想法就是结合符号处理和神经处理。比如,我们有一个包含大量“奥林匹克运动会”问答关系的数据库。来了一个问询语句,比如:
Which city hosted the longest Olympic game before the game in Beijing?

这样一个长句对应着一个非常复杂的命令,我们用神经网络将其转换成向量表示,与数据库里的向量表示做匹配,经过多次匹配来真正找到复杂的逻辑关系,最后找到答案。
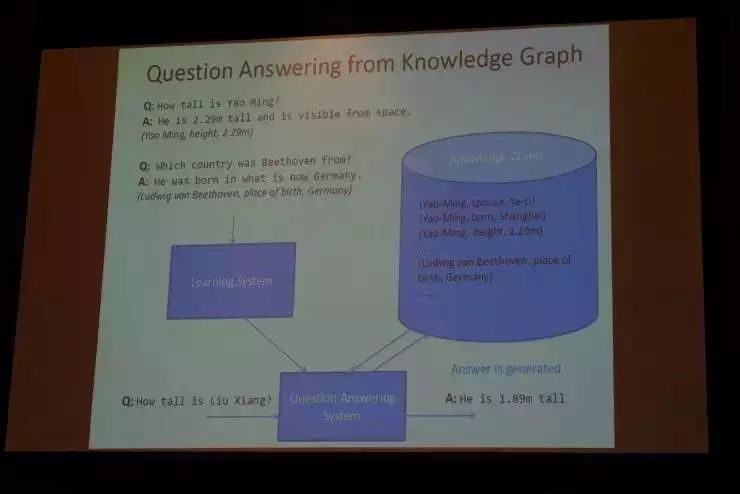
我们另外在做的一个事情,也是问答系统,跟刚才所讲到的相似但不完全一样。我们用到了一个包含知识图谱的知识库,包括“三元组”(图中所示为 Learning System、Knowledge Graph和Question Answering System),据此提出了一个名为“GenQA”的模型,它可以结合符号处理和神经处理,既用符号又用分布式表达做检索,通过神经网络产生答案。因为时间关系,这个模型的具体细节我不详细介绍了。
●
●
●
神经机器翻译与统计机器翻译结合
我们还在做的一件事情,就是将神经机器翻译(NMT)和统计机器翻译(SMT)结合起来。其基本想法就是,传统的统计机器翻译有很多优势,那么当我们在使用神经机器翻译的时候,用统计机器翻译来辅助。因为NMT严重依赖于大数据,如果数据不足,往往还不如你用传统的SMT方法来的好。这种结合,能够提升解决实际问题的能力,比如翻译不当或对于未登入词的翻译问题。

我们刚才谈到“序列对序列学习”可以帮助我们去做机器翻译,也就是说NMT靠自己来决定产生哪些词,那么在新模型里,SMT也会对词的产生造成影响,这两者结合起来,判断最终应该产生什么样的词。这样可以在一定程度上,提升翻译的准确度。
●
●
●
CopyNet模型
刚刚我们提到单轮对话做到了76%的准确率,我们希望能够把准确率再进一步提升。不知大家有没有观察到这么一个现象,那就是我们在跟别人聊天的时候,往往会去重复一些对方已经说过的词组。比如说会发生这样的对话:
-My Name is Harry Potter.
-Hi, Harry Potter.

这样的一个对话是蛮自然的。所以一个可能重要的机制就是,把问句里的一部分复制到我们答句里,使得单轮对话的效果更好、更顺畅。我们可以考虑这样的一个叫做“CopyNet”的模型,其效果是非常好的。前面我们提到,单轮对话也是“序列对序列学习”,那么当我们产生组成答句的各个词汇时,就需要决定在某个位置产生特定的词,所以每个位置都面临一个动态的选择:是生成新的词,还是从输入语句里复制一些词过来。

以上就是我们华为诺亚方舟实验室大致进行的工作,总的来说就是:深度学习确实给自然语言处理带来了一些突破性进展,主要体现在能够端到端地训练模型以完成不同的任务,包括自动问答、机器翻译和图片检索等,但是它仍然有一定的局限性。当自然语言处理牵涉到更高层次的推理、知识等方面内容时,这种局限性就很容易凸显出来。所以我们现在采取的方法就是将深度学习和符号处理结合起来,这也就是自然语言处理未来的发展方向。






