选自GitHub
作者:Adam Kosiorek
机器之心编译
参与:Panda
神经网络中的注意机制(attention mechanism),也被称为神经注意(neural attention)或注意(attention),最近也得到了人们越来越多的关注。在本文中,作者将尝试为不同机制和用例找到共同点,此外还将描述并实现两个软视觉注意(soft visual attention)机制范例。本文作者 Adam Kosiorek 为牛津大学在读博士。
注意机制是什么?
我们可以粗略地把神经注意机制类比成一个可以专注于输入内容的某一子集(或特征)的神经网络:它可以选择特定的输入。设 x∈R^d 为输入,z∈R^k 为特征向量,a∈{0,1}^k 是注意向量,g∈R^k 为 attention glimpse,fϕ(x) 为注意网络(attention network)。一般而言,注意实现为如下形式:

其中 ⊙ 是元素依次相乘。对于软注意(soft attention),其将特征与一个(软)掩模(mask)相乘,该掩模的值在 0 到 1 之间;对于硬注意(hard attention),这些值被限制为确定的 0 或 1,即 a∈{0,1}k。在后面的案例中,我们可以使用硬注意掩模来直接索引其特征向量 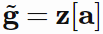 (用 Matlab 的表示方法),它会改变自己的维度,所以现在
(用 Matlab 的表示方法),它会改变自己的维度,所以现在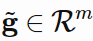 ,其中 m≤k。
,其中 m≤k。
为了理解注意机制的重要性,我们必须考虑到神经网络实际上就是一个函数近似器。它近似不同类型的函数的能力取决于它的架构。典型的神经网络的实现形式是矩阵乘法构成的链式运算和元素上的非线性,其中输入的元素或特征向量只会通过加法彼此交互。
注意机制会计算一个用于对特征进行乘法运算的掩模。这种看似无关痛痒的扩展会产生重大的影响:突然之间,可以使用神经网络近似的函数空间多了很多,让全新的用例成为了可能。为什么会这样?尽管我没有证据,但直观的想法是:有一种理论认为神经网络是一种通用的函数近似器,可以近似任意函数并达到任意精度,唯一的限制是隐藏单元的数量有限。在任何实际的设置中,情况却不是:我们受限于可以使用的隐藏单元的数量。考虑以下案例:我们要近似神经网络输入的乘积。前馈神经网络只能通过使用(许多)加法(以及非线性)来模拟乘法,因此它需要大量神经网络基础。如果我们引入乘法交互,那它就会变得简单且紧凑。
如果我们放松对注意掩模的值的限制,使 a∈R^k,那么上面将注意定义为乘法交互的做法能让我们考虑更大范围的模型。比如动态过滤器网络(DFN:Dynamic Filter Networks)使用了一个过滤器生成网络,它可以基于输入而计算过滤器(即任意幅度的权重),并将它们应用于特征,这在效果上就是一种乘法交互。使用软注意机制的唯一区别是注意权重并不局限于 0 到 1 之间。在这个方向上更进一步,了解哪些交互应该是相加的、哪些应该是相乘的是非常有意思的。
论文《A Differentiable Transition Between Additive and Multiplicative Neurons》对这一概念进行了探索,参阅:https://arxiv.org/abs/1604.03736。另外,《深度 | 深度学习能力的拓展,Google Brain 讲解注意力模型和增强 RNN》这篇文章也对软注意机制进行了很好的概述。
视觉注意
注意机制可应用于任意种类的输入,不管这些输入的形态如何。在输入为矩阵值的案例中(比如图像),我们可以考虑使用视觉注意(visual attention)。设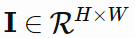 为图像,
为图像,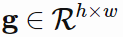 为 attention glimpse,即将注意机制应用于图像 I 所得到的结果。
为 attention glimpse,即将注意机制应用于图像 I 所得到的结果。
硬注意
对图像的硬注意已经存在了很长时间,即图像裁剪。在概念上这非常简单,因为仅需要索引。使用 Python(或 TensorFlow),硬注意可以实现为:
g = I[y:y+h, x:x+w]
上面代码的唯一问题是不可微分;为了学习得到模型的参数,比如借助分数函数估计器(score-function estimator)等方法,我之前的文章也曾简要提到过:https://goo.gl/nfPB6r
软注意
软注意最简单的形式在图像方面和向量值特征方面并无不同,还是和上面的(1)式一样。论文《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》是最早使用这种类型的注意的研究之一:https://arxiv.org/abs/1502.03044

该模型可以学习注意图像的特定部分,同时生成描述这部分的词。
但是,这种类型的软注意非常浪费计算资源。输入中变暗的部分对结果没有贡献,但仍然还是需要处理。它也过度参数化了:实现这种注意的 sigmoid 激活函数是彼此独立的。它可以同时选择多个目标,但在实际中,我们往往希望进行选择并且仅关注场景中的单个元素。下面这两个机制解决了这个问题,它们分别是由 DRAW(https://arxiv.org/abs/1502.04623)和 Spatial Transformer Networks(https://arxiv.org/abs/1506.02025)这两项研究引入的。它们也可以重新调整输入的大小,从而进一步提升性能。
高斯注意(Gaussian Attention)
高斯注意是使用参数化的一维高斯过滤器来创造图像大小的注意图(attention map)。设

是注意向量,其分别通过 y 和 x 坐标指定了应该注意图像中的哪一部分。其注意掩模可以创建为
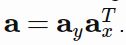

在上图中,上面一行表示 ax,右边一列表示 ay,中间的矩形表示得到的结果 a。这里为了可视化,向量中仅包含 0 和 1. 实际上,它们可以实现为一维的高斯向量。一般而言,高斯的数量就等于空间的维度,且每个向量都使用了 3 个参数进行参数化:第一个高斯的中心 μ、连续的高斯中心之间的距离 d 和这些高斯的标准差 σ。使用这种参数化,注意和 glimpse 在注意的参数方面都是可微分的,因此很容易学习。
上面形式的注意仍然很浪费,因为它只选择了图像的一部分,同时遮挡了图像的其它部分。我们可以不直接使用这些向量,而是将它们分别投射进

中。现在,每个矩阵的每一行都有一个高斯,参数 d 指定了连续行中的高斯中心之间的距离(以列为单位)。现在可以将 glimpse 实现为:
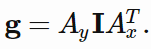
我最近一篇关于使用带有注意机制的 RNN 进行生物启发式目标跟踪的论文 HART 中就使用了这种机制,参阅:https://arxiv.org/abs/1706.09262。这里给出一个例子,下面左图是输入图像,右图是 attention glimpse;这个 glimpse 给出了主图中绿色标记出的框。

下面的代码可以让你在 TensorFlow 中为某个 minibatch 样本创建一个上述的带有矩阵值的掩模。如果你想创造 Ay,你可以这样调用:Ay = gaussian_mask(u, s, d, h, H),其中 u、s、d 即为 μ、σ、d,以这样的顺序并在像素中指定。
def gaussian_mask(u, s, d, R, C):
"""
:param u: tf.Tensor, centre of the first Gaussian.
:param s: tf.Tensor, standard deviation of Gaussians.
:param d: tf.Tensor, shift between Gaussian centres.
:param R: int, number of rows in the mask, there is one Gaussian per row.
:param C: int, number of columns in the mask.
"""
# indices to create centres
R = tf.to_float(tf.reshape(tf.range(R), (1, 1, R)))
C = tf.to_float(tf.reshape(tf.range(C), (1, C, 1)))
centres = u[np.newaxis, :, np.newaxis] + R * d
column_centres = C - centres
mask = tf.exp(-.5 * tf.square(column_centres / s))
# we add eps for numerical stability
normalised_mask = mask / (tf.reduce_sum(mask, 1, keep_dims=True) + 1e-8)
return normalised_mask
我们也可以写一个函数来直接从图像中提取 glimpse:
def gaussian_glimpse(img_tensor, transform_params, crop_size):
"""
:param img_tensor: tf.Tensor of size (batch_size, Height, Width, channels)
:param transform_params: tf.Tensor of size (batch_size, 6), where params are (mean_y, std_y, d_y, mean_x, std_x, d_x) specified in pixels.
:param crop_size): tuple of 2 ints, size of the resulting crop
"""
# parse arguments
h, w = crop_size
H, W = img_tensor.shape.as_list()[1:3]
split_ax = transform_params.shape.ndims -1
uy, sy, dy, ux, sx, dx = tf.split(transform_params, 6, split_ax)
# create Gaussian masks, one for each axis
Ay = gaussian_mask(uy, sy, dy, h, H)
Ax = gaussian_mask(ux, sx, dx, w, W)
# extract glimpse
glimpse = tf.matmul(tf.matmul(Ay, img_tensor, adjoint_a=True), Ax)
return glimpse
空间变换器(Spatial Transformer)
空间变换器(STN)可以实现更加一般化的变换,而不仅仅是可微分的图像裁剪,但图像裁剪也是其可能的用例之一。它由两个组件构成:一个网格生成器和一个采样器。这个网格生成器会指定一个点构成的网格以用于采样,而采样器的工作当然就是采样。使用 DeepMind 最近发布的一个神经网络库 Sonnet,可以很轻松地在 TensorFlow 中实现它。Sonnet 地址:https://github.com/deepmind/sonnet
def spatial_transformer(img_tensor, transform_params, crop_size):
"""
:param img_tensor: tf.Tensor of size (batch_size, Height, Width, channels)
:param transform_params: tf.Tensor of size (batch_size, 4), where params are (scale_y, shift_y, scale_x, shift_x)
:param crop_size): tuple of 2 ints, size of the resulting crop
"""
constraints = snt.AffineWarpConstraints.no_shear_2d()
img_size = img_tensor.shape.as_list()[1:]
warper = snt.AffineGridWarper(img_size, crop_size, constraints)
grid_coords = warper(transform_params)
glimpse = snt.resampler(img_tensor[..., tf.newaxis], grid_coords)
return glimpse
高斯注意 vs. 空间变换器
高斯注意和空间变换器可以实现非常相似的行为。我们该选择使用哪一个呢?这两者之间有一些细微的差别:
高斯注意是一种过度参数化的裁剪机制:需要 6 个参数,但却只有 4 个自由度(y、x、高度、宽度)。STN 只需要 4 个参数。
我还没运行过任何测试,但 STN 应该更快。它依赖于在采样点上的线性插值法,而高斯注意则必须执行两个巨大的矩阵乘法运算。STN 应该可以快上一个数量级(在输入图像中的像素方面)。
高斯注意应该更容易训练(没有测试运行)。这是因为结果得到的 glimpse 中的每个像素都可以是源图像的相对大批量的像素的凸组合,这使得我们能更容易找到任何错误的原因。而 STN 依赖于线性插值法,这意味着每个采样点的梯度仅相对其最近的两个像素是非 0 的。
你可以在这里查看代码示例:https://github.com/akosiorek/akosiorek.github.io/tree/master/notebooks/attention_glimpse.ipynb
一个简单的范例
让我们来创建一个简单的高斯注意和 STN 范例。首先,我们需要载入一些库,定义尺寸,创建并裁剪输入图片。
import tensorflow as tf
import sonnet as snt
import numpy as np
import matplotlib.pyplot as plt
img_size = 10, 10
glimpse_size = 5, 5
# Create a random image with a square
x = abs(np.random.randn(1, *img_size)) * .3
x[0, 3:6, 3:6] = 1
crop = x[0, 2:7, 2:7] # contains the square
随后,我们需要 TensorFlow 变量的占位符。
tf.reset_default_graph()
# placeholders
tx = tf.placeholder(tf.float32, x.shape, 'image')
tu = tf.placeholder(tf.float32, [1], 'u')
ts = tf.placeholder(tf.float32, [1], 's')
td = tf.placeholder(tf.float32, [1], 'd')
stn_params = tf.placeholder(tf.float32, [1, 4], 'stn_params')
我们现在可以定义高斯注意和 STN 在 Tensorflow 上的简单表达式。
# Gaussian Attention
gaussian_att_params = tf.concat([tu, ts, td, tu, ts, td], -1)
gaussian_glimpse_expr = gaussian_glimpse(tx, gaussian_att_params, glimpse_size)
# Spatial Transformer
stn_glimpse_expr = spatial_transformer(tx, stn_params, glimpse_size)
运行这些表达式并绘制它们:
sess = tf.Session()
# extract a Gaussian glimpse
u = 2
s = .5
d = 1
u, s, d = (np.asarray([i]) for i in (u, s, d))
gaussian_crop = sess.run(gaussian_glimpse_expr, feed_dict={tx: x, tu: u, ts: s, td: d})
# extract STN glimpse
transform = [.4, -.1, .4, -.1]
transform = np.asarray(transform).reshape((1, 4))
stn_crop = sess.run(stn_glimpse_expr, {tx: x, stn_params: transform})
# plots
fig, axes = plt.subplots(1, 4, figsize=(12, 3))
titles = ['Input Image', 'Crop', 'Gaussian Att', 'STN']
imgs = [x, crop, gaussian_crop, stn_crop]
for ax, title, img in zip(axes, titles, imgs):
ax.imshow(img.squeeze(), cmap='gray', vmin=0., vmax=1.)
ax.set_title(title)
ax.xaxis.set_visible(False)
ax.yaxis.set_visible(False)

以上代码也在 Jupyter Notebook 上:https://github.com/akosiorek/akosiorek.github.io/blob/master/notebooks/attention_glimpse.ipynb
结语
注意机制能够扩展神经网络的能力:它们允许近似更加复杂的函数,用更直观的话说就是能关注输入的特定部分。它们已经帮助提升了自然语言处理的基准表现,也带来了图像描述、记忆网络寻址和神经编程器等全新能力。
我相信注意机制最重要的用例还尚未被发现。比如,我们知道视频中的目标是连续连贯的,它们不会在帧切换时凭空消失。注意机制可以用于表达这种连贯性的先验知识。具体怎么做?请拭目以待。 
原文链接:http://akosiorek.github.io/ml/2017/10/14/visual-attention.html
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]







