2013 年伦敦的一家小公司 DeepMind 发表了一篇论文 Playing Atari with Deep Reinforcement Learning
。论文描述了如何教会电脑玩 Atari 2600
游戏(仅仅让电脑观察游戏的每一帧图像和接受游戏分数的上升作为奖励信号)。结果很令人满意,因为电脑比大多数人类玩家玩的好,而且该模型在没有任何改变的情况下,学会了玩其他游戏,并且在三个游戏中表现比人类玩家好!自此通用人工智能的话题开始火热
-- 能够适应各种负责环境而不仅仅局限于玩棋类游戏,而 DeepMind 因此被谷歌看中而被收购。2015 年,DeepMind 又发表了一篇 Human-level control through deep reinforcement learning,在本篇论文中
DeepMind 用同样的模型,教会电脑玩49种游戏,而且过半游戏比专业玩家玩得更好。2016年3月,AlphaGo
与围棋世界冠军、职业九段选手李世石进行人机大战,并以4:1的总比分获胜;2016年末2017年初,该程序在中国棋类网站上以“大师”(Master)为注册帐号与中日韩数十位围棋高手进行快棋对决,连续60局无一败绩。
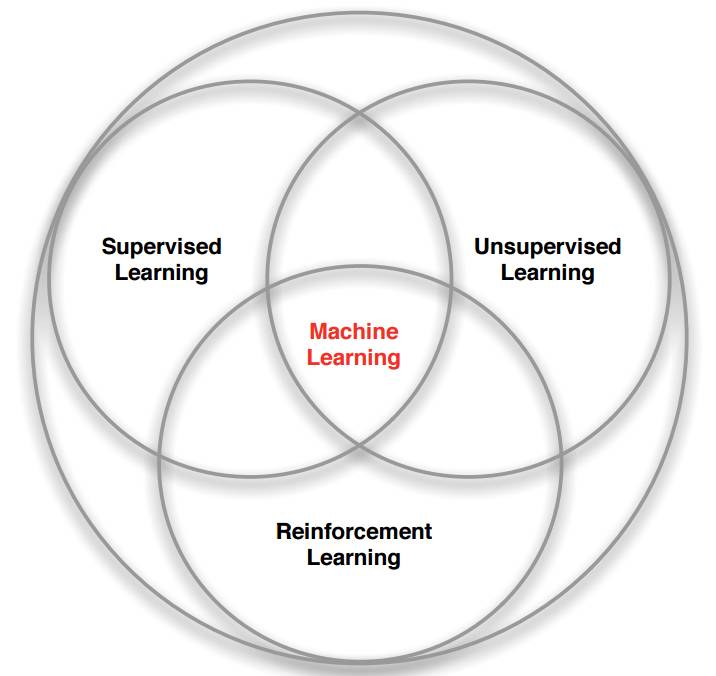
机器学习的分支
强化学习
以打砖块游戏为例,游戏中你控制底部的挡板来反弹小球,来清除屏幕上半部分的砖块。每次你打中砖块,分数增加,你也得到一个奖励,而没有接到小球则会受到惩罚。
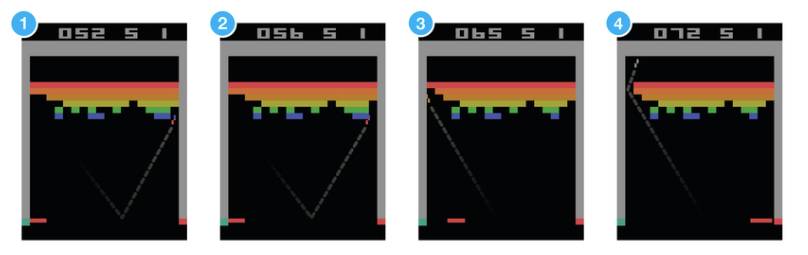
打砖块游戏假设让一个神经网络来玩这个游戏,
输入是屏幕图像,输出将是三个动作:左,右或发射球。很明显这是一个分类问题,对于每一帧图像,我们计算到到一个动作即可(为屏幕数据分类)。
但是听起来很简单,实际上有很多有挑战性的细节。因为我们当前的动作奖励有可能是在此之后一段时间获得的。不像监督学习,对于每一个样本,都有一个确定的标签与之对应,而强化学习没有标签,只有一个时间延迟的奖励,而且游戏中我们往往牺牲当前的奖励来获取将来更大的奖励。因为我们的小球在打到砖块,获得奖励时,事实上挡板并没有移动,该奖励是由于之前的一系列动作来获得的。这就是信用分配问题(Credit
Assignment Problem),即当前的动作要为将来获得更多的奖励负责。
而且在我们找到一个策略,让游戏获得不错的奖励时,我们是选择继续坚持当前的策略,还是探索新的策略以求更多的奖励?这就是探索与开发(Explore-exploit Dilemma)的问题。
强化学习就是一个重要的解决此类问题的模型,它是从我们的人类经验中总结出来的。在现实生活中,如果我们做某件事获得奖励,那么我们会更加偏向于做这件事。比如你的狗狗早上给你把鞋子叼过来,你对他说 Good dog 并奖励它,那么狗狗会更加偏向于叼鞋。而且人类每天在学校的成绩、在家来自父母的夸奖、还是工作上的薪水本质上都是在奖励。
马尔可夫决策过程 (Markov Decision Process)
那么如何用数学的方法来解决此类问题呢?最常用的方法就是那此类问题看作一个马尔可夫决策过程 (Markov Decision Process)。
MDP 中有两个对象:Agent 和 Environment。
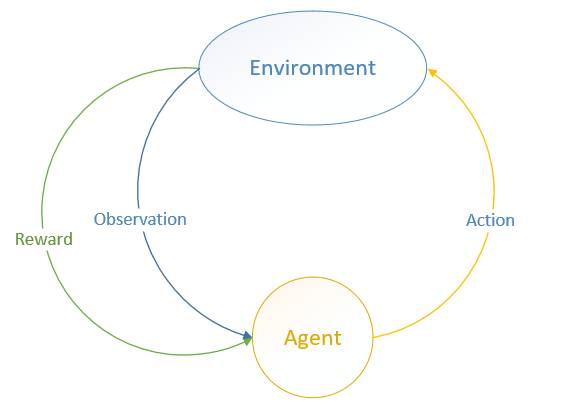
Environment 处于一个特定的状态(State)(如打砖块游戏中挡板的位置、各个砖块的状态等),Agent 可以通过执行特定的动作( Actions )(如向左向右移动挡板)来改变 Environment 的状态, Environment 状态改变之后会返回一个观察(Observation)给Agent,同时还会得到一个奖励(Reward)(可以为负,就是惩罚),这样 Agent 根据返回的信息采取新的动作,如此反复下去。Agent 如何选择动作叫做策略(Policy)。MDP 的任务就是找到一个策略,来最大化奖励。
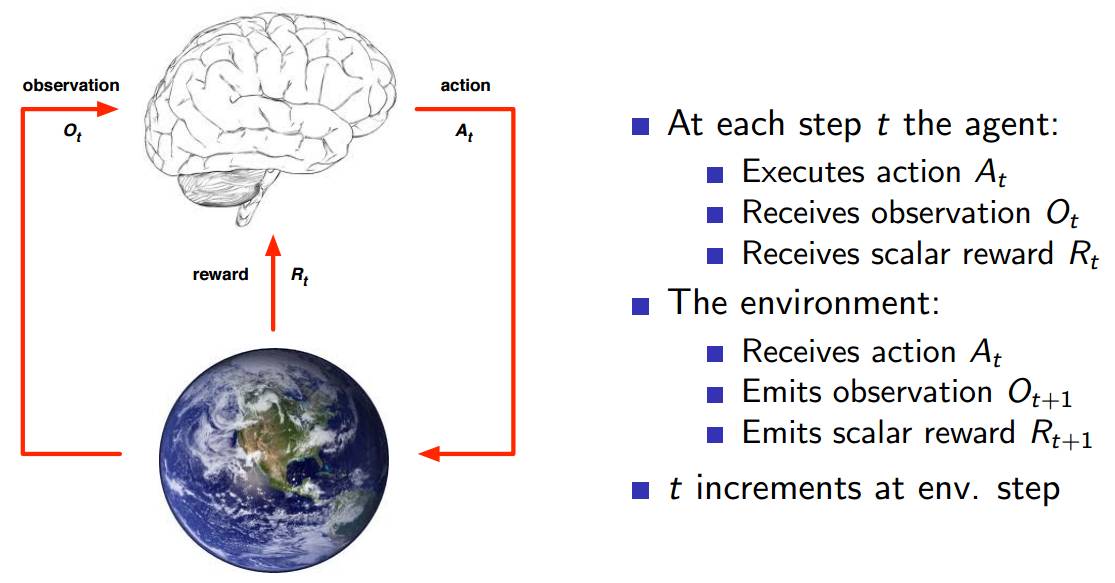
具体的执行步骤如上图图所示。注意 State 和 Observation 区别:State 是 Environment 的私有表达,我们往往不知道不会直接到的。在 MDP 中,当前状态State (Markov state)包含了所有历史信息,即将来只和现在有关,与过去无关,因为现在状态包含了所有历史信息。举个例子,在一个遵循牛顿第二定律的世界里,我们随意抛出一个小球,某一时刻 t 知道了小球的速度和加速度,那么 t
之后的小球的位置都可以由当前状态,根据牛顿第二定律计算出来。再举一个夸张的例子,如果宇宙大爆炸时奇点的状态已知,那么以后的所有状态就已经确定,包括人类进化、我写这篇文章和你在阅读这篇文章都是可以根据那一状态推断出来的。当然这只是理想状况,现实往往不会那么简单(因为这只是马尔科夫的一个假设)。只有满足这样条件的状态才叫做马尔科夫状态。即:
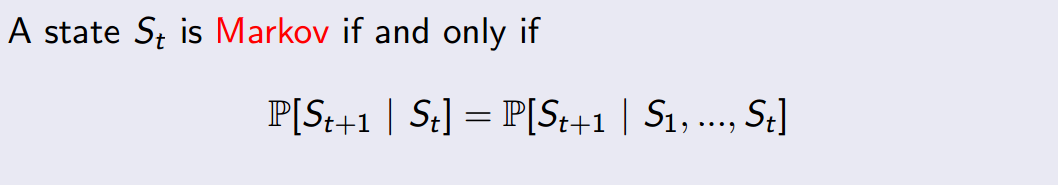
正是因为 State 太过于复杂,我们往往可以需要一个对 Environment 的观察来间接获得信息,因此就有了 Observation。不过 Observation 是可以等于 State 的,在游戏中,一帧游戏画面完全可以代表当前状态,因此 Observation = State,此时叫做 Full Observability。
状态、动作、状态转移概率组成了 MDP,一个 MDP 周期(episode )由一个有限的状态、动作、奖励队列组成:
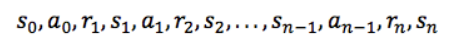
这里 si 代表状态,ai 代表行动,ri + 1(下标 i+1)是执行动作后的奖励。 最终状态为sn(例如“游戏结束”)。
原文链接:
https://lufficc.com/blog/reinforcement-learning-and-implementation









