这个端午节,对于绝大部分人来说,都非常平静。对买了英国航空机票的旅行者来说,却非常懊糟。他们在机场滞留时间有的超过72小时,从图中可以看出他们非常不开心。


原因是英国航空遭遇了重大的IT系统故障。
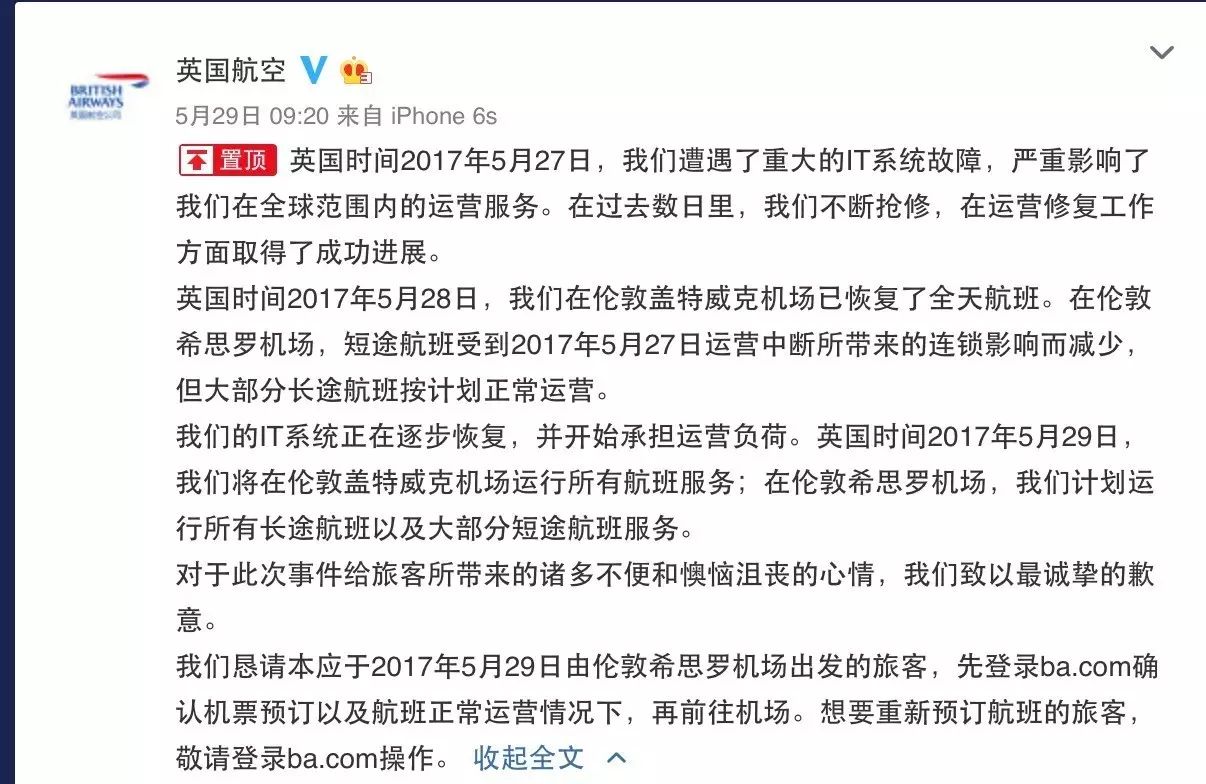
这得多么重大的IT系统故障,导致英国航空需要2天多时间都不能完全解决呢?
英国航空的首席执行官克鲁兹(Alex Cruz)在27日表示,初步调查认为事故原因跟电脑的电力系统有关。此次故障不仅影响到了英国航空在希斯罗和盖特威克机场出发来往的航班,还影响到了香港国际机场、北京首都国际机场、上海浦东机场、新加坡樟宜机场、东京成田国际机场和曼谷素万那普国际机场,所以这是一个全球性的故障,影响了7.5万旅客。按照英国航空的预计,周二从两个机场起飞的航班将会全面恢复。
来自BBC的信息表示:
航空专家布雷(Julian Bray)对BBC表示,英航的问题似乎瘫痪了负责处理航班升降、处理行李和乘客资料的系统。
对于这次故障,CEO最开始把锅扔给了电力系统,在29日又解释说,希思罗附近的数据中心供电短缺,最终导致瘫痪,并且备用系统也无济于事。不过,随后“电网公司新闻发言人在接受采访时表示,英国航空出现电力供应短缺应该是客户的问题,原因不在他们这边。希思罗机场新闻发言人也说,机场的私有电网周六没有出现任何问题。”
同时,克鲁兹还表示,没有受到网络攻击。
那么故障最终的真实原因是什么呢?
跟绝大部分故障一样,可能最终也不会公布出来。
但是,用电力供应不足来解释这样一个“全球性的故障”,显然是难以服众的。
“根据 BBC 的报道,2016 年英国航空裁撤了数百名 IT 员工,并将整个 IT 部门外包到了印度。
英国总工会负责航空国家官员 Mick Rix 表示“这些原本完全都能避免的”。2016 年 2 月他曾对英国航空的决定表示抗议。英国航空将 IT 部门外包的决策不仅造成约 800 名员工失业,根据 TechCrunch 的报道,随后出现的英国航空的新 IT 系统,在过去的一年里已经崩溃过五次,在 2016 年的 7 月和 9 月,英国航空也曾因为值机系统故障造成了严重的延误。”
那么,IT外包是罪魁祸首么?
朋友圈流传着一个笑话,说苹果APP越来越不好用了,因为开发主要是印度人。英国航空IT故障频发,因为维护的是印度人。
印度人显然也不会背锅。
作为一个在运维圈混迹了十多年的人来看,核心问题在于公司对IT投入的下降。作为一家老牌的航空公司,IT系统经历了几十年的建设和运营,很多系统的维护都得靠“人”,而不是靠“系统”或者所谓的平台能搞定的。那随着这些人的被裁,接着转包,故障的发生也就理所当然了。
在某次D+沙龙闭门会议上,来自国内顶尖云厂商的同学们也顺便谈到了这个问题。云计算时代,各种设备、软件都标准化、自动化、“智能化”,但你要真以为这样就万事大吉,那你就大错特错了。他们偶尔也会出现这样的问题,某台几年无人问知的系统,被关机了,自己小组的人都没反应,突然某个团队的人会叫起来,配置变更发不出去了。然后,重启,解决。当然,也会遇到重启也启动不了的情况,那当然还是要解决。相对而言,对用户可能是无感知的。因为大家都是一群傲娇的人,一遍遍之后,这类问题总会消灭殆尽的。
无独有偶,就在英国航空CEO克鲁兹表示”自己辞职也没有卵用“的时候(没错,也是5月27日),中国国家统计局发布了2016年的平均工资数据。
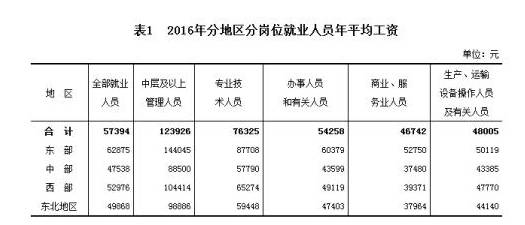
不出意外的,从各行各业各个层级来说,东部薪水要整体高于其他几个地区。
可能要稍微有点意外的是,IT行业的薪资超越金融行业在第一位,名义涨幅达到了9.3%。
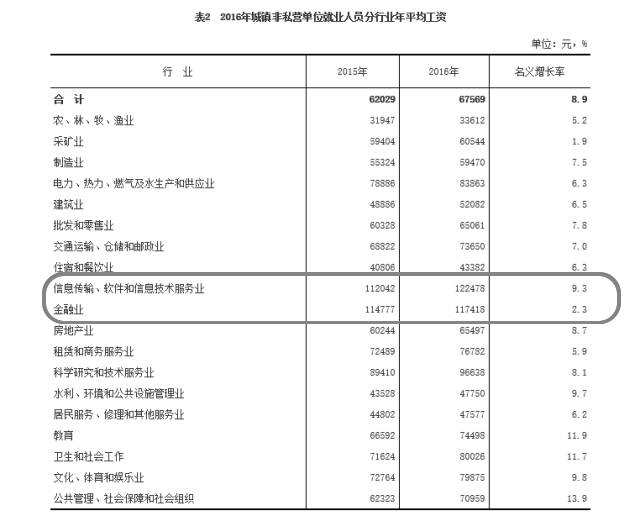
这跟国家提倡大众创业、万众创新有关系,国内的云计算、大数据各种IT创业企业层出不穷,IT人才得到重视,拉高了IT行业的薪水的同时,也激发了IT行业的创造和创新能力。当所有的传统企业都在谋求“互联网+”或“+互联网”,都在谋求数字化转型时,对IT资源和IT人才的需求势必是一个长期增长的趋势。
不管是航空公司也好,金融企业也罢,节流固然是一种守成的方法,当大家都大踏步的迈向开源的时代,吝啬IT投入,给自己带来的可能不只是一个周末的惊慌,而是给用户难以抹去的长久的阴影。
回到英国航空的故障,据英国《每日电讯报》的统计,这已是英航电脑系统自去年以来第六次出现故障。对于此次故障,有航空专家指出,英航应该及时启用备用系统,避免给乘客造成如此大的影响,而CEO克鲁兹表示,启用了备用系统,但是没有生效。
其实航空公司IT系统故障并非是个案,据不完全统计:
2016年3月22日,全日航空由于IT故障导致了100多个航班取消。原因据说是由于网络问题,UDP通讯异常(坏包增加),导致Oracle RAC集群异常。
2016年7月,美国西南航空耗时数天,才从一起因为路由器故障导致的系统崩溃事件中缓过气来。《达拉斯晨报》估算西南航空的IT系统问题造成的损失超过5400万美元。
2016年8月8日,达美航空IT系统因断电而瘫痪,达美被迫取消或推迟约2000个航班。达美航空对投资者称IT系统故障导致它损失了大约1.5亿美元。(今年1月发生的暴雪游戏《炉石传说》官方宣称也是由于断电所致)
2017年1月22日,美联航的IT系统也出现了故障,导致其航班运营中断了大概两个小时。
......
不难看出,IT系统故障时有发生,影响的范围有大有小。但像英国航空这样,一年之内连续发生几次影响极大的故障,还是极为罕见的。
端午节正好看了阿里王坚博士的《在线》,里面有个观点很有意思,所有的数据在线才有更意义,离线的价值就很小。对于IT系统更是这个道理,离线就非但没有价值,而且还造成了很大的问题。
那么英国航空这样的故障、这样的悲剧是可以避免的么?英国航空的说法是,无法避免,其它航空公司也会同样会遇到。对于一个有几百个系统、上万台设备的大型公司来说,故障确实天天可能都有,只看影响面的大小。
但这种影响极大的故障,是可以逐步减少,直至避免的。
而且,这种故障的减少和避免,通常是需要专业服务商的介入和帮助的,因为他们具有大量的类似案例,可以举一反三,避免类似故障在同一行业甚至是不同行业的反复出现。
比如说,由于网络原因导致数据库集群节点间的UDP坏包增大,最后会造成Oracle RAC节点hang甚至是重启的故障。不仅是在航空业,在电信行业也是屡屡发生。尽管故障造成的影响会很大,但故障预防却极其简单,通过vmstat检测 UDP failure增长数,每秒超过50发生预警即可。
比如说比特币勒索。
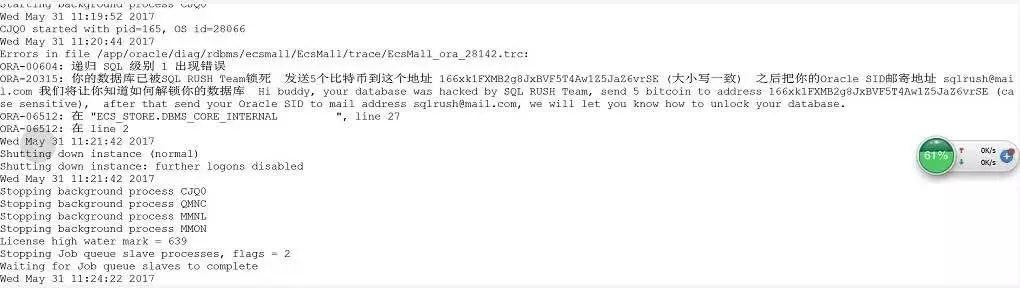
一方面通过管控,禁止未经审核的软件接入生产,一方面通过自动化运维平台,定期检查系统对象,在它还未发作之前就把它废除掉。
在各种航空公司IT故障中,大多数发言人都提到一个问题,就是收购和整合了很多公司后,系统整合出现极大的麻烦,也是导致故障的一个潜在因素。老的系统虽然老,但是稳定,新研发的系统往往才是故障爆发的源头。
这个说法基本跟我们的运维经验是吻合的。新系统不稳定的原因,除了业务逻辑导致的问题,就是上线前SQL未经过审核所致,招商银行最近的隐私泄露问题就属于此类。

这份银监会的文章是针对2016年11月、12月的手机号码泄露问题的答复书。不幸的是,招行在5月27日,发生了A用户查询自己信息时,会显示B用户的信息(而且还可以修改),刷新还会显示C用户的信息。
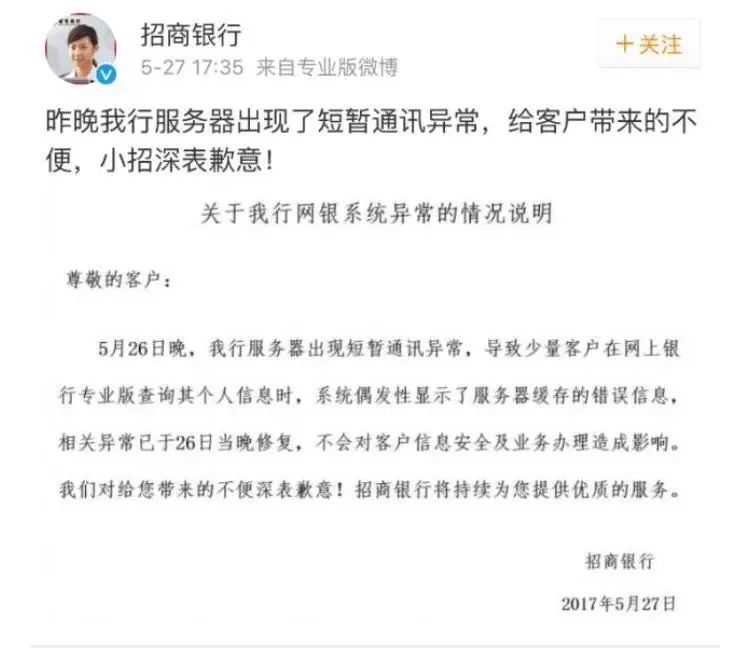
服务器缓存要背锅么?
我们可以看到,IT故障有其普适性,跟具体行业关系不大。不管是航空,还是运营商,或者是游戏公司或者是金融行业,我们都得遵循它的基本规律,解决它的基本问题。
它的基本问题,就有6个,简称六脉神剑,这是新炬团队2012年汇美论剑的产物。

每一剑都是为了保命,理解起来并不难。做起来,需要配合具体的实施步骤。
备份管理,有两层道理。首先是保全数据,另一层是作为高可用方案的最低级存在。更进一步要做到本地高可用,异地灾备。说一千道一万,要平时做演练,不然就跟CEO克鲁兹说的一样,启用了备用系统,但是没有用。
活着只是IT的基本要求,每一个IT人都想活得好。
活得好完全靠个人能力是不现实的。所以我们还逐步研发了一些工具/平台为人赋能:
为解决新系统性能低下问题,上线SQL审核平台
为解决人工检查效率低下问题,上线一键巡检工具
为解决人工倒数误操作频发的问题,上线了数据生命周期管理平台
为解决性能问题被动响应问题,上线了数据库性能管理平台
为解决架构复杂、机器众多、故障难查问题,上线了日志统一分析平台
为解决半夜加空间、删文件的问题,上线了自动化运维平台
.......
极为重要的是,这些工具接口统一,互联互通,不会造成额外的运维负担。
但是,这就一定能解决英国航空的悲剧了么?
未必!
DAMS峰会上海站的嘉宾们或许可以给出更多经验。

仅剩少量优惠票,快点击【阅读原文】报名抢座吧!门票优惠码“nbp”,深度课程优惠码“sql”。










