公众号ID
|
计算机视觉研究院
学习群
|
扫码在主页获取加入方式

论文地址:
https://arxiv.org/pdf/2306.12156v1.pdf
Column of Computer Vision Institute
最近提出的
分割任意模型
(segment anything model,SAM)在许多计算机视觉任务中产生了重大影响。
SAM
它正在成为许多高级任务的基础步骤,如图像分割、图像字幕和图像编辑。然而,其巨大的计算成本使其无法在行业场景中得到更广泛的应用。计算主要来自高分辨率输入的Transformer架构。
在今天分享中,研究者为这项基本任务提出了一种性能相当的
加速替代方法
。通过将任务重新表述为片段生成和提示,我们发现具有实例分割分支的常规CNN检测器也可以很好地完成该任务。具体而言,我们将该任务转换为研究充分的实例分割任务,并仅使用SAM作者发布的SA-1B数据集的1/50直接训练现有的实例分割方法。使用我们的方法,我们在
50倍的运行时速度下
实现了与SAM方法相当的性能
。我们给出了足够的实验结果来证明它的有效性。


最近提出的SAM,它被视为一个里程碑式的愿景基础模型。它可以在各种可能的用户交互提示的引导下分割图像中的任何对象。SAM利用了在广泛的SA-1B数据集上训练的Transformer模型,这使其能够熟练地处理各种场景和对象。SAM为一项激动人心的新任务打开了大门,该任务被称为Segment Anything。这项任务,由于其可推广性和潜力,具有成为未来广泛愿景任务基石的所有条件。
然而,尽管SAM和后续模型在处理细分市场任何任务方面取得了这些进步和有希望的结果,但其实际应用仍然具有挑战性。突出的问题是与SAM架构的主要部分Transformer(ViT)模型相关的大量计算资源需求。与卷积技术相比,ViT因其繁重的计算资源需求而脱颖而出,这给其实际部署带来了障碍,尤其是在实时应用中。因此,这种限制阻碍了分段任何任务的进展和潜力。
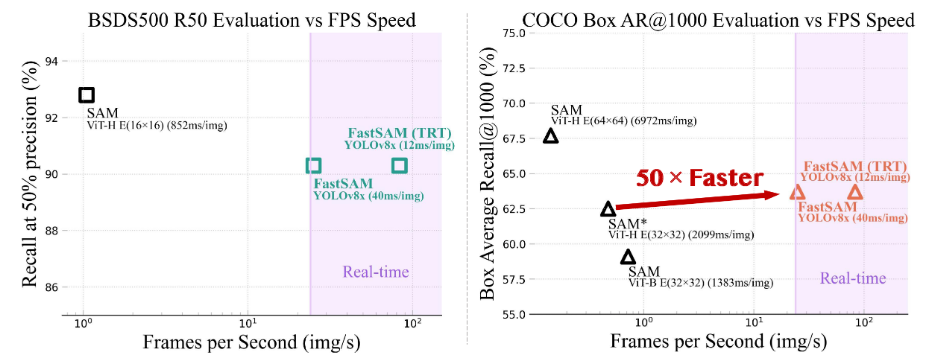
提出的FastSAM基于YOLOv8 seg,这是一种配备了实例分割分支的目标检测器,它利用了YOLACT方法。还采用了SAM发布的广泛的SA-1B数据集。通过仅在SA-1B数据集中的2%(1/50)上直接训练该CNN检测器,它实现了与SAM相当的性能,但大大减少了计算和资源需求,从而实现了实时应用。


还将其应用于多个下游分割任务,以显示其泛化性能。在MS COCO上的面向对象任务上,在AR1000上实现了63.7,这比32×32点提示输入的SAM高1.2点,但在单个NVIDIA RTX 3090上运行速度快50倍。实时SAM对工业应用很有价值。它可以应用于许多场景。所提出的方法不仅为大量视觉任务提供了一种新的、实用的解决方案,而且速度非常快,比当前方法快几十倍或数百倍。
下图给出了所提出的Fast-SAM方法的概述。该方法由两个阶段组成,即所有实例分割和提示引导选择。前一阶段是基础,第二阶段本质上是面向任务的后处理。与端到端变换器不同,整体方法引入了许多与视觉分割任务相匹配的人类先验,如卷积的局部连接和感受野相关的对象分配策略。这使得它能够针对视觉分割任务进行定制,并且可以在较小数量的参数上更快地收敛。
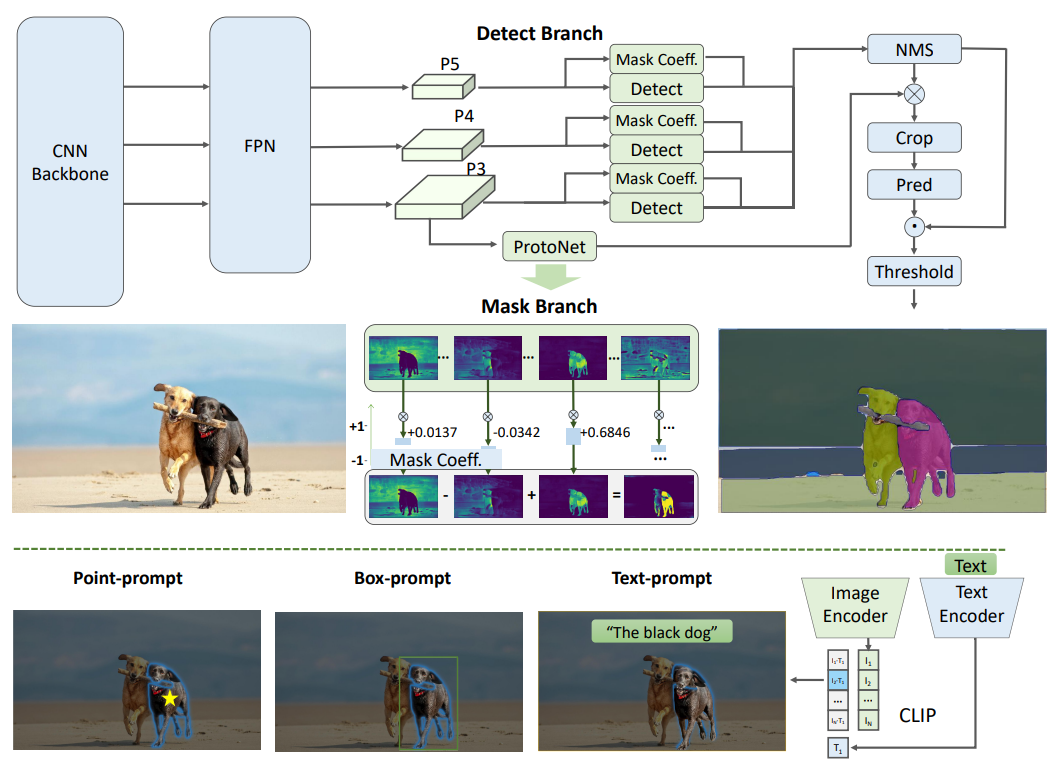
检测分支输出类别和边界框,而分割分支输出k个原型(在FastSAM中默认为32)以及k个掩码系数。分割和检测任务是并行计算的。分割分支输入高分辨率特征图,保留空间细节,还包含语义信息。该映射通过卷积层进行处理,放大,然后通过另外两个卷积层输出掩码。掩码系数,类似于探测头的分类分支,范围在-1和1之间。实例分割结果是通过将掩模系数与原型相乘,然后将其相加而获得的。
Prompt-guided Selection
在使用YOLOv8成功分割图像中的所有对象或区域之后,分割任何对象任务的第二阶段是使用各种提示来识别感兴趣的特定对象。它主要涉及点提示、框提示和文本提示的使用。
Point prompt
包括将选定的点与从第一阶段获得的各种遮罩进行匹配。目标是确定点所在的遮罩。与SAM类似,我们在方法中使用前地面/背景点作为提示。在前景点位于多个遮罩中的情况下,可以利用背景点来过滤出与手头任务无关的遮罩。通过使用一组前景/背景点,我们能够在感兴趣的区域内选择多个遮罩。这些遮罩将合并为一个遮罩,以完全标记感兴趣的对象。此外,我们还利用形态学运算来提高掩模合并的性能。
Box prompt
长方体提示涉及在选定长方体和与第一阶段中的各种遮罩相对应的边界框之间执行并集交集(IoU)匹配。其目的是用所选框识别具有最高IoU分数的掩码,从而选择感兴趣的对象。
Text prompt
在文本提示的情况下,使用CLIP模型提取文本的相应文本嵌入。然后确定相应的图像嵌入,并使用相似性度量将其与每个掩模的内在特征相匹配。然后选择与文本提示的图像嵌入具有最高相似性得分的掩码。
通过仔细实施这些提示引导选择技术,FastSAM可以从分割图像中可靠地选择感兴趣的特定对象。上述方法提供了一种实时完成任何分割任务的有效方法,从而大大提高了YOLOv8模型在复杂图像分割任务中的实用性。一种更有效的即时引导选择技术留给了未来的探索。

Segmentation Results of FastSAM
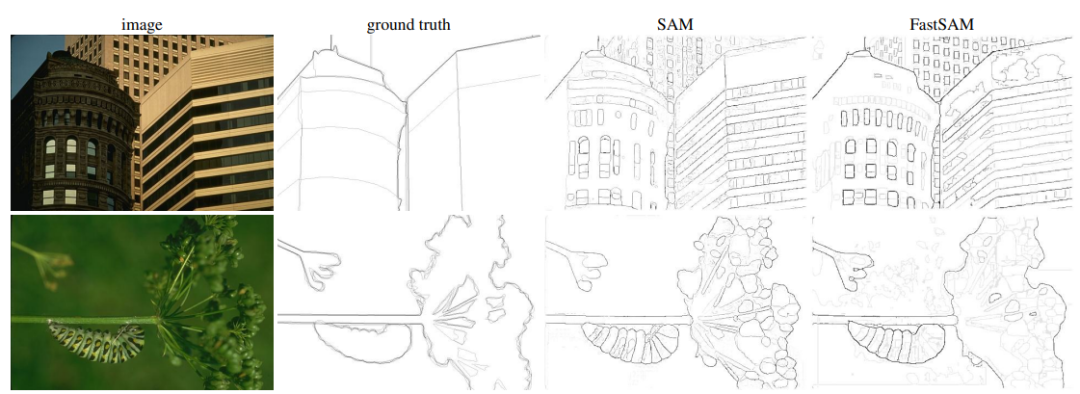
SAM和Fast-SAM比较

在上图中显示了定性结果。FastSAM可以
根据文本提示很好地分割对象
。然而,文本到掩模分割的运行速度并不令人满意,因为每个掩模区域都需要被馈送到CLIP特征提取器中。如何将CLIP嵌入提取器组合到FastSAM的骨干网络中,仍然是关于模型压缩的一个有趣的问题。

基于提供的代码,自己进行了搭建。搭建流程见【计算机视觉研究院】知识星球。






转载请联系本公众号获得授权










