生命由一段又一段的旅程衔接而成,在每段旅程中,都能发现不一样的风景
在往期的推文中,我们介绍了很多爬虫的案例,做法是:通过copy命令得到网页源代码,然后将源代码读入stata,进行字符串处理,最终整合成我们需要的信息,这是基础爬虫的套路。然而copy命令爬虫是有其局限性的:如果对应的源代码中没有目标数据(例如去哪儿网
https://flight.qunar.com/
);如果要抓取的信息分页显示,但是点击下一页网址不变,这种情况下我们该怎么进行循环抓取呢(例如中国土地市场网
http://www.landchina.com/
);以及对于异步加载的网页,怎么才能得到目标数据的源代码呢?如果网站反爬,封了IP呢?
网络爬虫最难的不是字符串处理,而是如何得到目标数据的源代码。对于上述所列问题,copy命令是不能完全解决的。但是不要担心,今天小编给大家介绍一个新的爬虫神器,命令行工具:
curl
。我们将在之后的推文中对curl进行一系列基础介绍并展示相关的爬虫案例,请大家及时关注我们公众号推送。
简单来说,
curl
是一个在命令行下工作的文件传输工具。它支持文件的上传和下载,可以发送各种http请求给网站,然后抓取网站上内容,我们可以将HTTP/HTTPS/FTP相关的上传和下载等任务交给它,这样可以达到爬虫的目的。
curl
是一个和服务器交互信息(发送和获取信息)的命令行工具,支持DICT, FILE, FTP, FTPS, GOPHER, HTTP, HTTPS, IMAP, IMAPS, LDAP, LDAPS, POP3, POP3S, RTMP, RTSP, SCP, SFTP, SMTP, SMTPS, TELNET和TFTP等协议。
curl
支持代理、用户认证、FTP上传、HTTP POST请求、SSL连接、cookies、文件传输、Metalink等功能。
在基本了解
curl
后,我们就可以在电脑中安装和使用curl啦,具体操作如下:
首先,复制
curl
的官网网址到任何一个浏览器中:
https://curl.haxx.se/
,进入其官网,界面如下:

点击Download,界面如下:
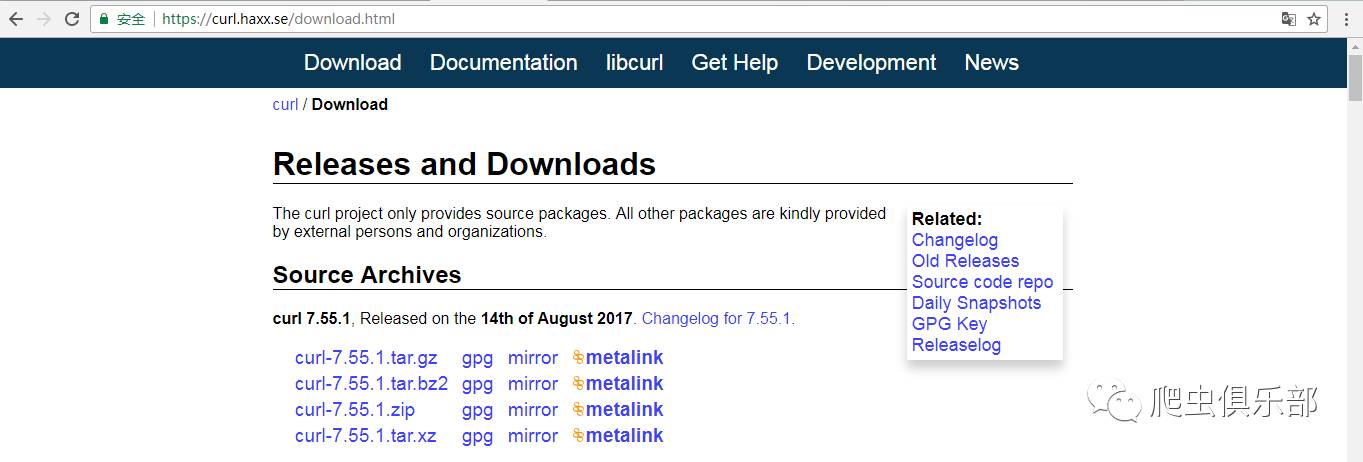
接下来就可以根据各自电脑的配置来选择安装的
curl
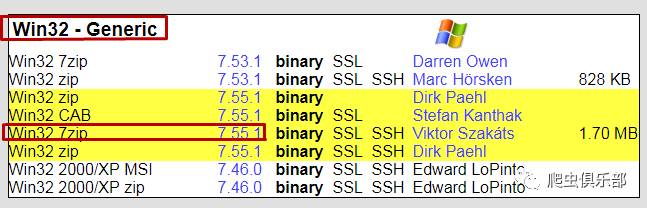
的版本啦,现在以小编电脑的window7 的32位操作系统为例展示一下安装过程:先将上述界面下拉,找到Win32-Generic,这里小编选择的是7.55.1版本,点击下载(如果你的电脑是64位操作系统,那就在Win64-Generic下选择要下载的版本吧),如下图:
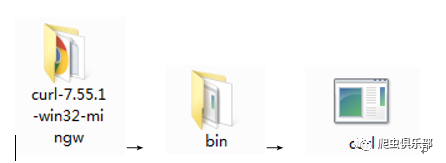
下载完成后,将安装包进行解压,值得注意的是在解压后的文件夹中找到
curl
的应用程序后,在笔者的电脑中需要将它放到路径
C:\Windows\System32
下,这是因为该路径是在环境变量的path下面,所以放在这里可以直接通过命令行调用
curl
,又或者将解压后的路径添加到环境变量的path中也可,步骤如下图:
安装好
curl
后,我们赶紧趁着热乎劲儿一起来试试如何使用
curl
。我们需要借助命令行窗口,这里有一个快捷方法打开命令行窗口,只需要按windows键+R键,在弹出的窗口中输入cmd后点击确定,即可打开命令行窗口,如下图:
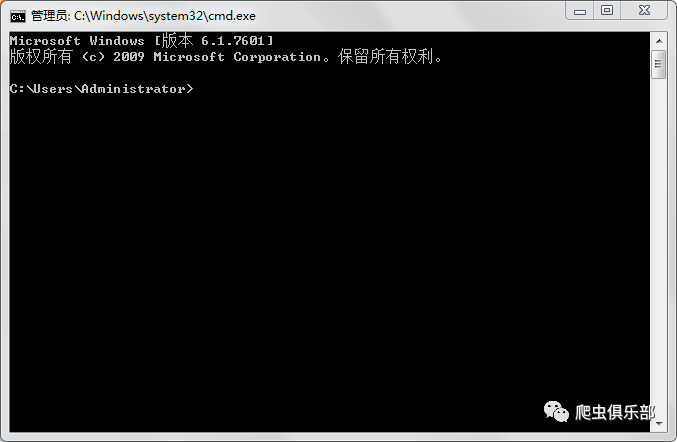
现在我们就可以在这个窗口中使用
curl
,比如说我们访问新浪财经:
curl
http://finance.sina.com.cn/
,这时候返回来的信息就是新浪财经(
http://finance.sina.com.cn/
)的源代码,如下图所示:
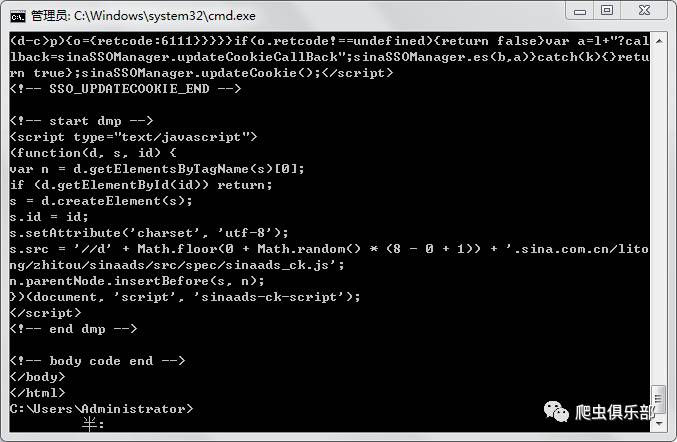 这样新浪财
经首页的网页源代码就可以get到啦。
最后我们
在Stata中调用
curl
,输入如下命令:
这样新浪财
经首页的网页源代码就可以get到啦。
最后我们
在Stata中调用
curl
,输入如下命令:
clear
!curl -o sina.txt http://finance.sina.com.cn/
//将新浪财经的网页源代码下载并保存到名为sina的txt文件中,保存的路径为默认路径
这里的
curl
后面加了一个 -o ,作用是将新浪财经的网页源代码下载并保存到名为sina的txt文件中,保存的路径为stata默认保存路径。
下一篇推文中,我们将深入介绍
curl
的其他几种常见用法,例如可以通过
--data/-d
方式指定使用POST方式传递数据,还可以利用
curl
来可以发送保存cookie,等等,敬请期待啦~
注:此推文中的图片及封面(除操作部分的)均来源于网络!如有雷同纯属巧合!
以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。
另外,我们开通了苹果手机打赏通道,只要扫描下方的二维码,就可以打赏啦!

应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~










