(一)
Python
解析
PDF
简介
Python
提供了诸多开源的库来解析
PDF
,但我们首先要明确的是用于解析的
PDF
是文档型的,还是扫描型的。绝大部分库都只能解决文档型的
PDF
,而扫描型的
PDF
保存的实际上就是图片,要解析其中的信息复杂度更高,需要用到
OCR
(光学字符识别)技术。
OCR
技术是指将图片的字符形状转变成计算机能识别的文字,其过程包括图像处理、文字特征抽取、数据库对比等流程,技术难度较大,运用场景也更广。而用于解析文档型的
PDF
相对来说比较简单,可以依据
Python
的
open
函数返回的结果进行分析。
科创板招股说明书的
PDF
都是文档型的,一个简单的判别方式,就是看看能否选择到一段文字。
Python
中用于解析文档型的
PDF
主要有
PDFminer
、
PyPDF2
、
PDFrw
等,可以解析扫描型的
PDF
有
OCRmyPDF
等。从
github
上看
PDFminer
是最受欢迎的,
star
数最多。 并且相关的从
PDF
中提取表格数据的开源库,例如
camelot
、
PDFplumber
都是依赖于
PDFminer
的。由于我们需要的很多财务指标数据、财报数据都是以表格形式展示的,而只使用文本信息用规则或语义分析来提取表格数据,很难保证数据完全准确性,也较难验证。故本文使用
PDF
提取表格相关库来解析文档,出于代码的简洁与可扩展性,本文最终选用
PDFplumber
来解析相关数据。
(二)从
PDF
中抽取表格数据算法简介
无论是
camelot
还是
PDFplumber
库,其算法核心思想均来自于
Anssi Nurminen
的硕士论文《
Algorithmic Extraction of Data in Tables in PDF Documents
》。其主要步骤如下所示:
1.
依据文档字符的位置信息确定横向的边缘与竖向边缘。
2.
考虑边缘的合并与连接。
3.
依据边缘确定交点。
4.
依据交点确定最小的表格矩形,提取出表格的内容。
PDFplumber
依据
PDFminer
返回的边缘信息来进行后面几步的处理,我们用图片来简单的展示这个过程
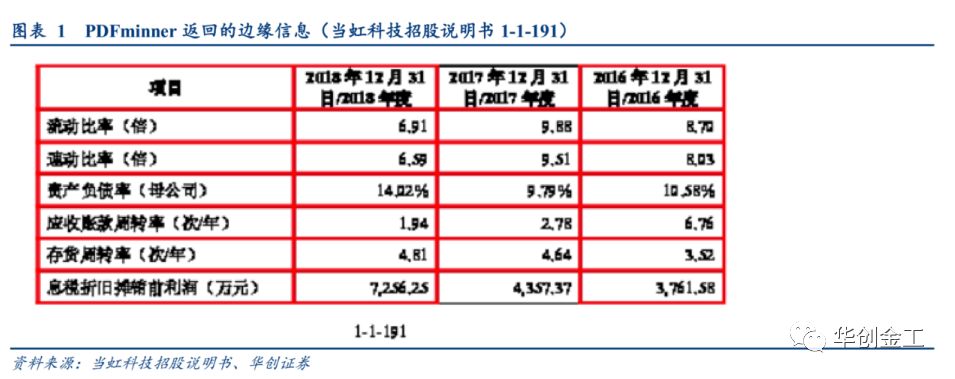
可以看出
PDFminner
返回的边缘信息比较准确,但第三列头尾的横向边缘并没有识别到。通过
PDFplumber
的算法,我们可以将处于同一水平的横向边缘连接上。
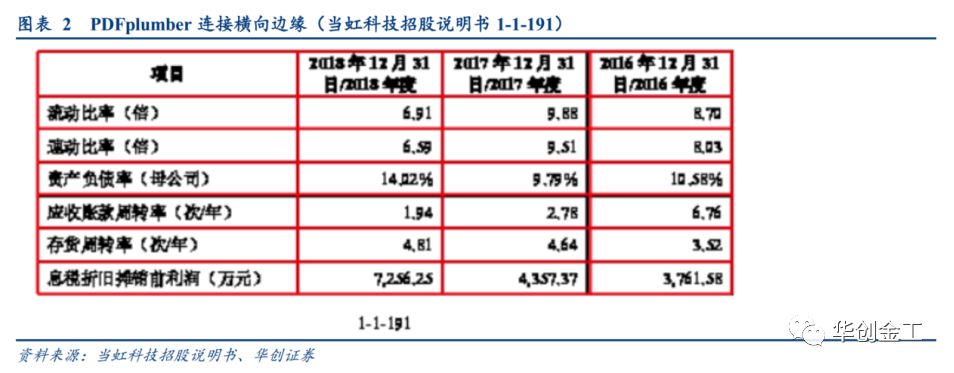
边缘正确了之后,我们可以很快来确定交点,在确定交点的时候,我们要注意做一些合并与去重。因为可能存在距离很近的两条边缘,这样会确定多个交点,我们要首先把距离很近的边缘做一个合并,这在一些表格的边框是一个双横边缘文本框来说很常见。准确的确认了交点之后,我们只需要依据交点的位置信息,找出它们确定的最小的闭合矩形,最后按行提取各个矩形中的信息即得到最后的表格数据。

(三)
PDFplumber
的参数扩展以及如何保证数据的准确性
上述展示了一个相对比较顺利的抽取表格数据的过程,但当批量地从
PDF
抽取数据,总会遇到各种各样没考虑到的问题。尽管
PDFplumber
提供了大量的自定义参数,但对于合并和连接并没有区分横边缘与纵边缘,实际上对于实践来说,横向地连接的距离容
忍可以设置的很大,因为基本不存在横向的列两个结构完全不同的表的可能。而对于纵向连接需要考虑,一个页面纵向的列多个表格的影响,容忍设置的过大很容易,使得不相关的两个表连接起来。
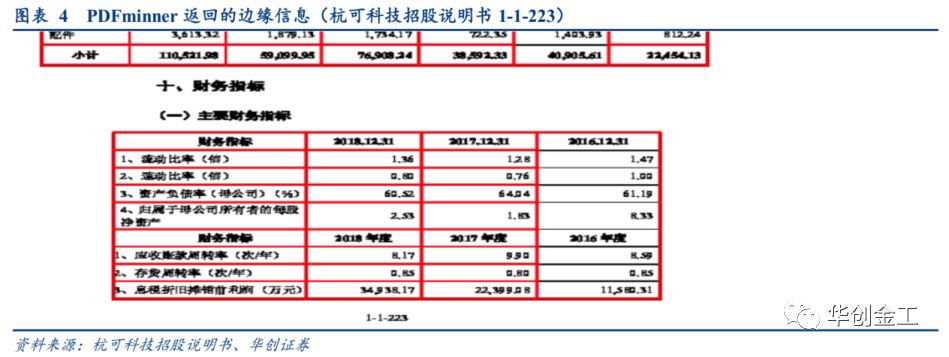
如上图所示,我们要的财务指标数据在第
4
列又出现了横向边缘有所缺失的情况,我们设置连接距离容忍,但会发现,除了横向的连接,纵向的连接不小心连接到上面的表。
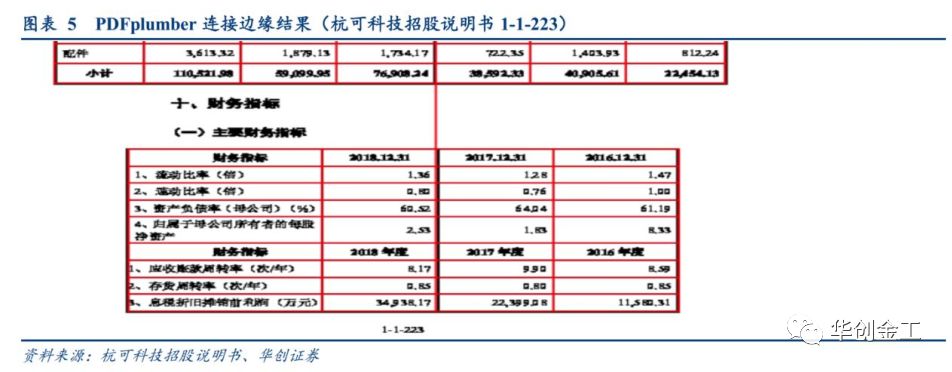
如上图所示,出现这种情况后,会对我们确定的表格产生很大的错误。故本文针对这些情况,在
PDFplumber
的基础上进一步分开横边缘与纵边缘的参数设置,并对纵向边缘的横向合并时设置纵向距离,防止距离很远的纵向边缘在横向合并时还互相受影响。即可以解决如下图所示的问题,合并纵向边缘时,受到上面的纵向边缘的影响,从而影响到了最后确定的表格矩形,对最后提取到的内容可能会缺失重要信息。
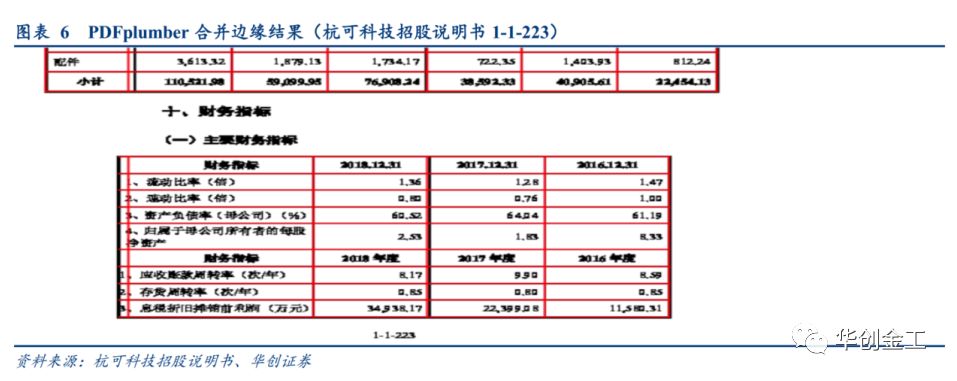
如上所示,我们通过参数的进一步扩展,并且在某些参数上放开,在某一些参数上面缩紧,对金融数据表格提取有很好的适用性。
并且对于每一个页面,
PDFplumber
借助可视化工具来帮助大家进行调试,只要出现如图
3
的结果,边缘正确、交点正确,那么得到的表格数据必然是正确的,这对我们数据质量是一个很好的把握。我们不必再人工地去验证具体的数据结果,只要验证图片的正确与否。对于我们要提取的表格数据,我们都会把对应的页面图片保存下来,观察我们要提取的数据是否正确,不正确我们要进一步调整参数进行调试。
(四)
Python
解析科创板招股说明书数据整体方案简介
对于科创板招股说明书,除了财报数据我们还有诸如可比公司、股权结构、经营分析等等其他的信息。由于
PDF
通常都比较大,招股说明书至少都在
200
页以上。我们给出如下整体的解决方案:
1.
解析各个
PDF
的目录,可以从第二页开始搜索,定位目录的位置,解析目录。因为目录的页面特点非常明显,基本上可以用同一个的正则表达式提取出数据。
2.
依据目录模糊寻找定位财报、财务指标的位置,进行表格提取,并进行验证调试。
3.
依据目录模糊寻找定位其他信息的位置,正则提取句子中的数据或其他数据,进行一些剔除与必要的验证。










