
PMCAFF(www.pmcaff.com)
:最大互联网产品社区,是百度,腾讯,阿里等产品经理的学习交流平台。定期出品深度产品观察,互联产品研究首选。
外包大师(www.waibaodashi.com)
:
要外包,找大师。PMCAFF旗下高质量互联网外包解决方案提供商。外包大师服务号:waibaodashi365
作者
:苏格兰折耳喵 某大数据公司数据分析师 擅长数据分析和可视化表达。个人微信号:g18818233178
现在互联网上关于“增长黑客”的概念很火,它那“四两拨千斤”、“小投入大收益”的神奇法力令无数互联网从业者为之着迷。
一般来说,“增长黑客”主要依赖于企业的内部数据(如企业自身拥有的销售数据、用户数据、页面浏览数据等),以此为依据进行数据分析和推广策略拟定。但是,如果遇到如下几种情况,“增长黑客”就捉襟见肘了:
-
假如一家初创公司,自己刚起步,自身并没有还积累数据,怎么破?
-
就算有数据,但自己拥有的数据无论在“质”和“量”上都很差,正所谓“garbage in ,garbage out”,这样的数据再怎么分析和挖掘,也难以得到可作为决策依据的数据洞察。
-
能看到数量上的变化趋势,却无法精准的获悉数值变动的真正原因,比如,近期APP上的活跃度下降不少,从内部数据上,你只能看到数量上的减少,但对于用户活跃度下降的真实动因却无法准确判定,只能拍脑袋或者利用过时的经验,无法让相关人信服。
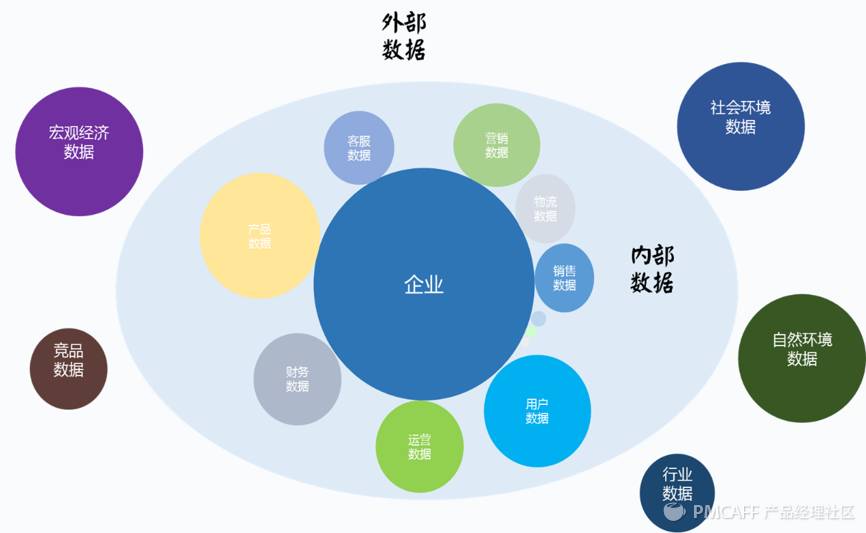
由此,笔者引出了“外部数据”这一概念,尤其是“Open Data”这片“数据蓝海”,“他山之石,可以攻玉”,从海量的外部数据中获取可以对自身业务起到指导作用和借鉴意义的insight,借助外部环境数据来优化自己。
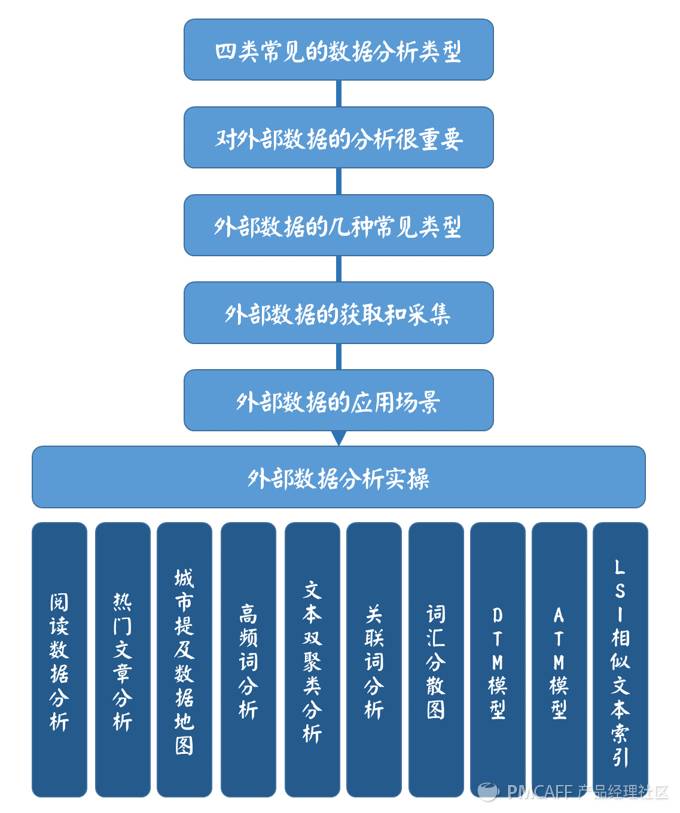
下图是本文的行文脉络:
在谈及外部数据的重要性之前,让我们先简单的看一看数据分析的四种类型。
四种常见的数据分析类型
按数据分析对于决策的价值高低和处理分析复杂程度,可将数据分析归为如下图所示的4种范式:
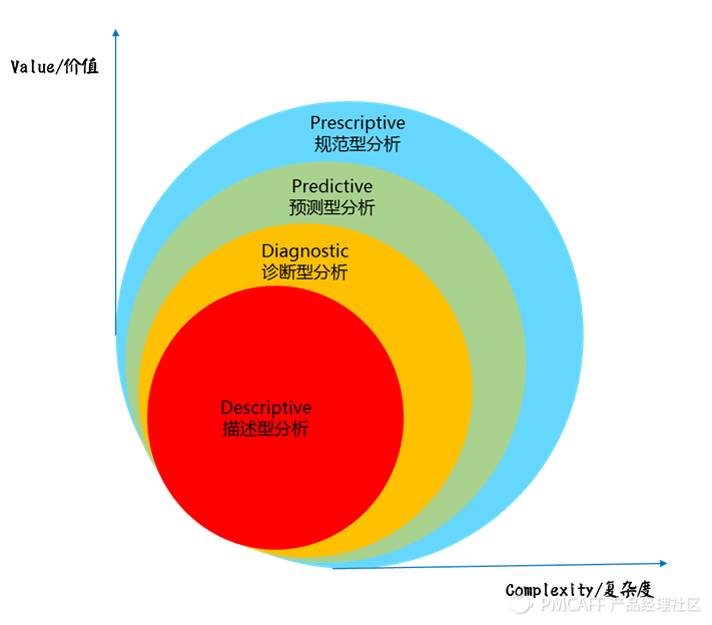
从上图可以看到,越远离坐标原点,沿坐标轴正向延伸,价值度就越高,分析处理的难度也就越大。
对于数据分析师而言,“描述型分析”、“诊断型分析”和“预测型分析”最为常见,而“规范型分析”涉及比较高深的数据挖掘和机器学习知识,不是我们接下来讨论的重点。
1.1 描述型数据分析
描述型分析是用来概括、表述事物整体状况以及事物间关联、类属关系的统计方法,是上述四类中最为常见的数据分析类型。
通过统计处理可以简洁地用几个统计值来表示一组数据地集中性(如平均值、中位数和众数等)和离散型(反映数据的波动性大小,如方差、标准差等)。
1.2 诊断型数据分析
在描述型分析的基础上,数据分析师需要进一步的钻取和深入,细分到特定的时间维度和空间维度,依据数据的浅层表现和自身的历史累积经验来判断现象/问题出现的原因。
1.3 预测型数据分析
预测型数据分析利用各种高级统计学技术,包括利用预测模型,机器学习,数据挖掘等技术来分析当前和历史的数据,从而对未来或其他不确定的事件进行预测。

1.4 规范型数据分析
最具价值和处理复杂度的当属规范型分析。
规范型分析通过 “已经发生什么”、“为什么发生”和“什么将发生”,也就是综合运用上述提及的描述型分析、诊断型分析和预测型分析,对潜在用户进行商品/服务推荐和决策支持。

对外部数据中的分析很重要
经过上面对四种数据分析类型的描述,笔者认为现有的基于企业内部数据的数据分析实践存在如下几类特征:
-
大多数的数据分析仅停留在描述性数据分析上,未触及数据深层次的规律,没有最大限度的挖掘数据的潜在价值。
-
数据分析的对象以结构化的数值型数据为主,而对非结构化数据,尤其是文本类型的数据分析实践则较少。
-
对内部数据高度重视,如用户增长数据,销售数据,以及产品相关指标数据等,但没有和外部数据进行关联,导致分析的结果片面、孤立和失真,起不到问题诊断和决策支撑作用。
由此,我们必须对企业之外的外部数据引起重视,尤其是外部数据中的非结构化文本数据。
对于文本数据的重要性,笔者已在之前的文章中有过详细的论述,详情请参看
《数据运营 | 数据分析中,文本分析远比数值型分析重要!(上)》
。
与此同时,非结构化的文本数据广泛存在于社会化媒体之中,关于社会化媒体的相关介绍,请参看
《干货|如何利用Social Listening从社会化媒体中“提炼”有价值的信息?》
。
外部数据的几种常见类型
外部数据是互联网时代的产物,随着移动互联时代的兴起,外部数据的增长呈现井喷的趋势。
各个领域的外部数据从不同角度刻画了移动互联时代的商业社会,综合这些外部数据,才能俯瞰到一个“全息式”的互联网版图。
按互联网行业和领域的不同,外部数据包括且不限于:
-
阿里(淘宝和天猫):电商大数据
-
腾讯(微信和QQ):社交网络大数据
-
新浪(新浪微博和新浪博客):社交媒体大数据
-
脉脉:职场社交大数据
-
谷歌/百度:搜索大数据
-
优酷:影视播放大数据
-
今日头条:阅读兴趣大数据
-
酷云EYE:收视大数据
-
高德地图:POI大数据
外部数据的获取和采集
随着互联网时代对于“Open Data(开放数据)”或“Data Sharing(共享数据)”的日益倡导,很多互联网巨头(部分)开放了它们所积累的外部数据。
再者一些可以抓取网络数据的第三方应用和编程工具不断出现,使得我们可以以免费或付费的方式获得大量外部数据(在获得对方允许和涉及商业目的的情况下),最终的形式包括未加工的原始数据、系统化的数据产品和定制化的数据服务。
以下是一些常见的外部数据分析和采集工具:
4.1 指数查询
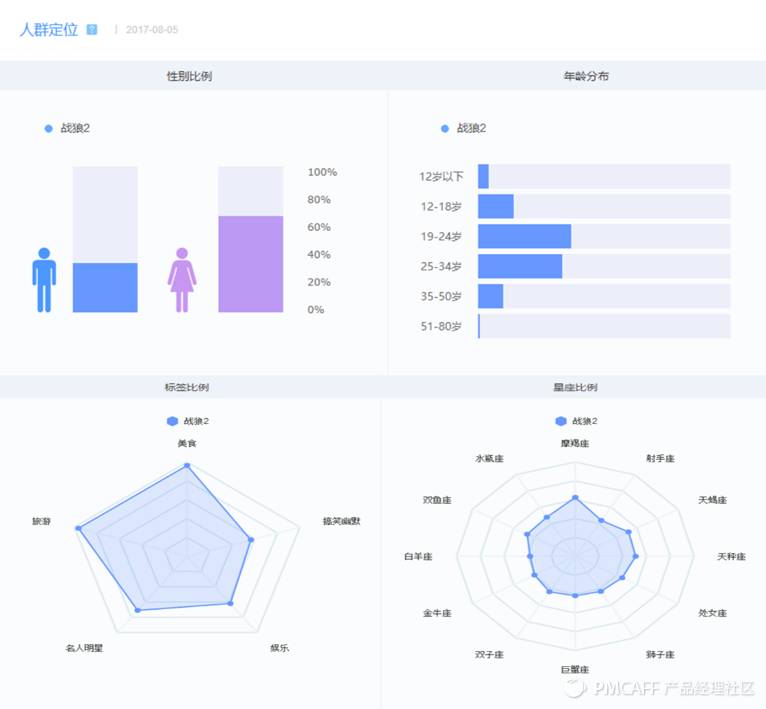
4.2 爬虫工具
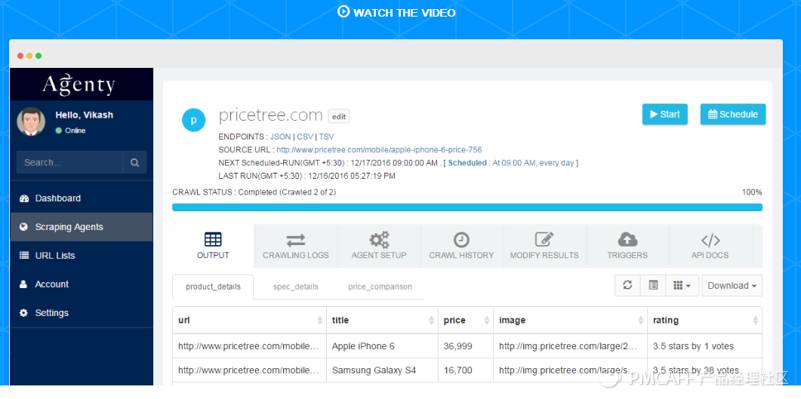
4.3 社会化媒体监测与分析平台
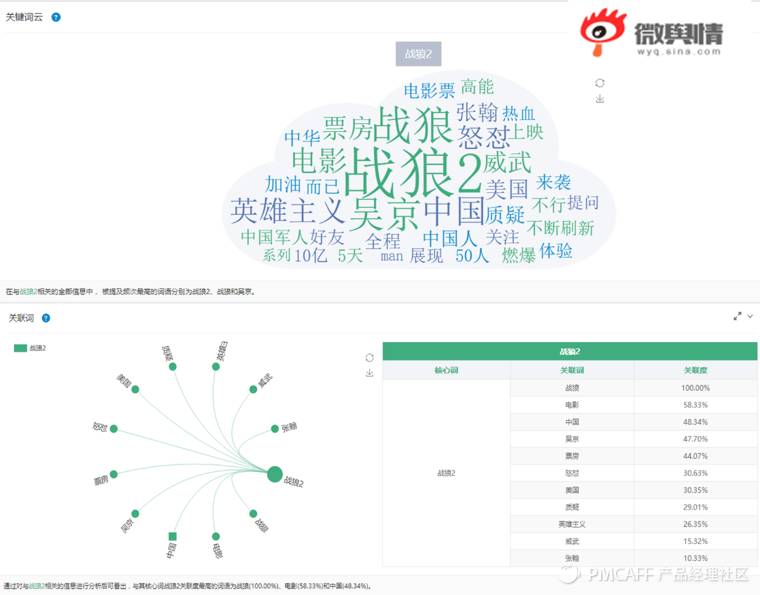
关于上述工具的使用介绍,请参考笔者之前的文章
《万字干货|10款数据分析“工具”,助你成为新媒体运营领域的“增长黑客》
、
《不懂数理和编程,如何运用免费的大数据工具获得行业洞察?》
。
外部数据分析的应用场景
最先对外部数据高度重视的先行者其实是政府机构,它们利用大数据舆情系统进行网络舆情的监测,但随着大数据时代的向前推进,外部数据的应用场景也越来越多,包括且不限如下方面:
-
舆情监测
-
企业口碑和客户满意度追踪
-
企业竞争情报分析
-
品牌宣传、广告投放及危机公关
-
市场机会挖掘、产品技术开发创意挖掘
-
行业趋势分析
接下来,笔者将以某互联网社区上近6年的文章数据作为实例,进行“360度无侧漏式”的数据分析,来“示范”下如何对外部数据进行挖掘,从中最大限度的“榨取”关于互联网产品、运营方面的insight。
外部数据分析实操案例
以某互联网社区的文章数据分析为例
在笔者下面的“数据发现之旅”中,会带着3个目的,主要是:
以下是笔者抓取的数据的原始形态,抓取了“标题”、“时间”、“正文”、“阅读量”、“评论量”、“收藏量”和“作者”这7个维度的数据,抓取时间区间是2012.05.17~2017.07.31,文章数据共计33,412条。
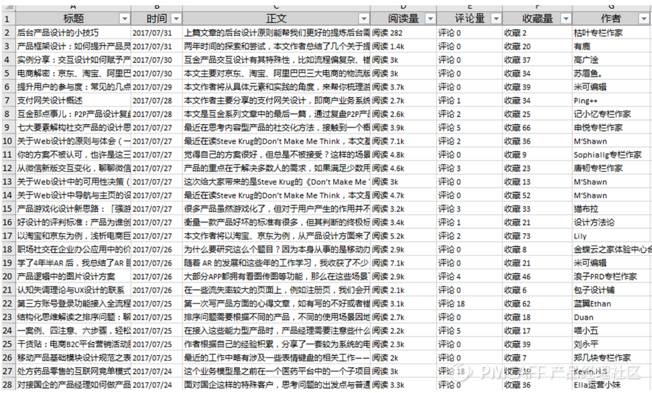
然后,笔者对数据进行了清洗,主要是“阅读量”,将“k(1000)“、“万(10000)”、“m(1000000)”变成了相应的数字,便于后续的数值计算和排序。同时,新增3个维度,即文章所属的栏目“类别”、“正文字数”和“标题字数”。
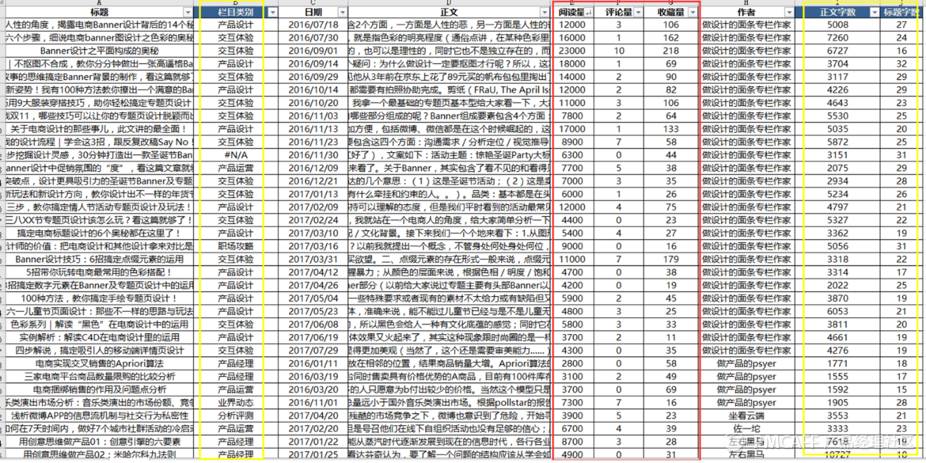
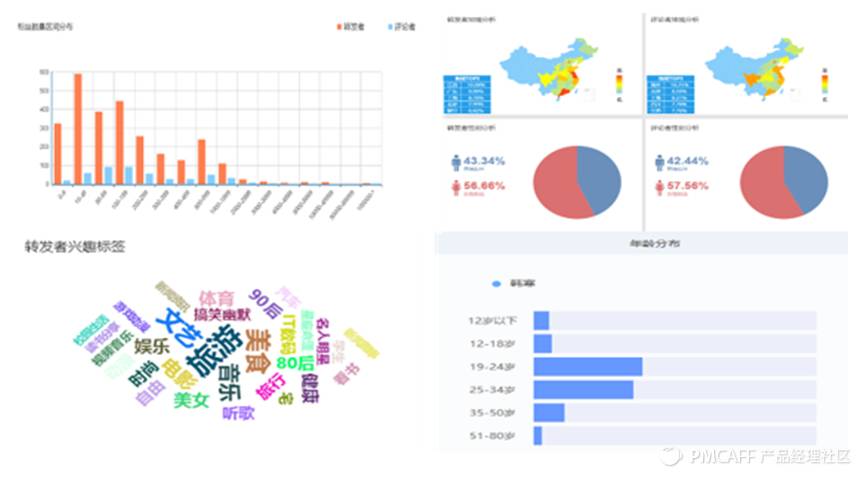
6.1全局纵览
6.1.1 各栏目下的文章数量分布情况
首先,先对各个栏目下的文章数量进行基础性的描述性分析,看看10个栏目类别下的文章数量分布。
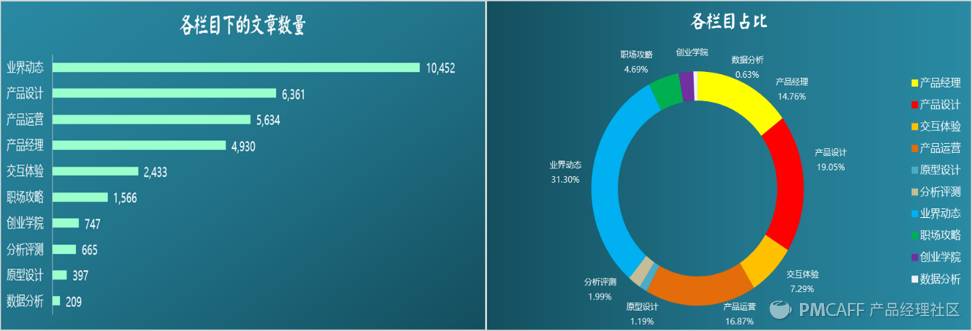
从上面的条状图和环形图可以看出,“业界动态”这一栏目下的文章数量最多,为10,,452篇,占到了文章篇数总量的31.3%,其次是产品设计和产品运营,分别占到了总数的19.5%和16.87%,反倒是“产品经理”下的文章数量不多。
接下来,笔者统计了这10各栏目在过去的6年中的数量变化情况,如下面的热力图所示:
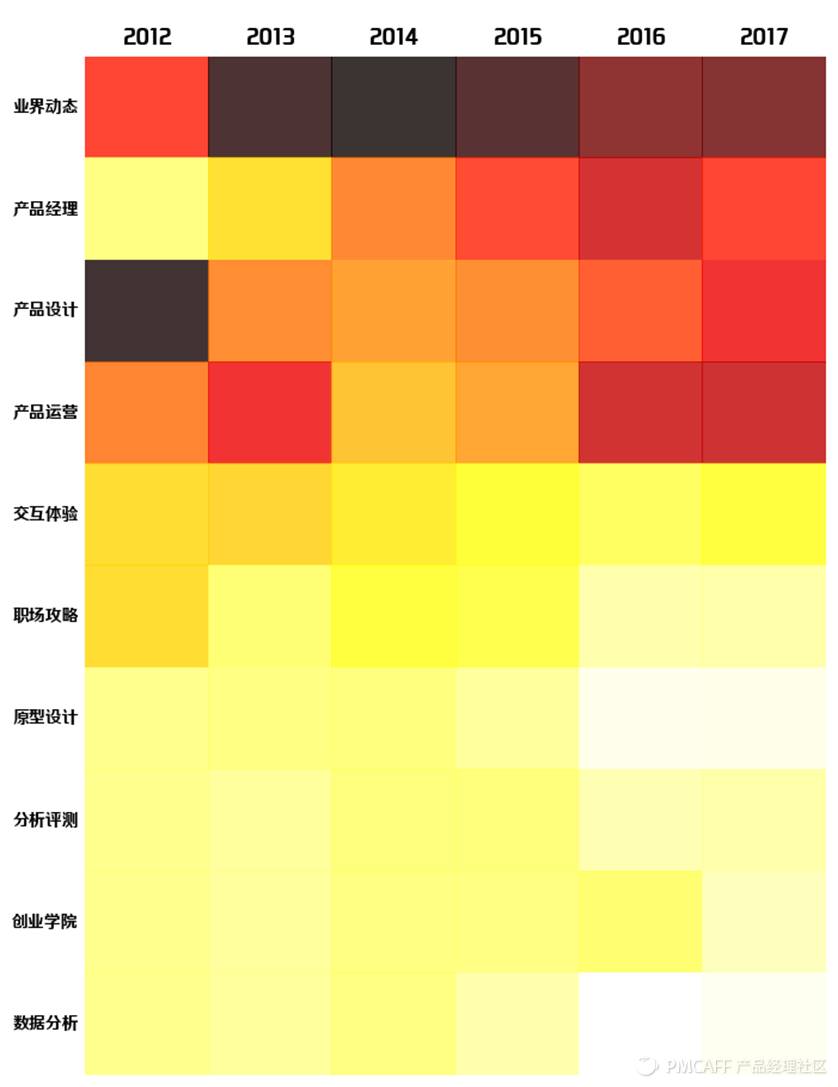
上面的热力图中,色块越深,对应的数值就越大,越浅则数值愈小。其中,互联网的“业界动态”一直是文章发布数量最多的栏目。
而“产品经理”的发文数量一路飙升(当然2017年还没过完),间接的可知该职位的热度(关注和写作偏好)蹭蹭的往上窜,成为“改变世界”、拿着高薪的产品经理,是无数互联网从业人员梦寐以求的工作。与此类似的是“产品运营”栏目,发文数量也在稳步上升。
另外,“产品设计”方面的文章主要集中在2012年,可以看出以“用户体验”、“UI设计”、“信息架构”和“需求规划”为主要活动的产品设计在2012年蓬勃发展,产生了大量基于实践经验的干货文章。
6.1.2 阅读数据分析
现在,笔者从“阅读量”、“点赞量”、“收藏量”、“正文字数”和“标题字数”这些能反映读者阅读偏好的数据着手,进行由浅入深的挖掘,从中发现阅读数据中的洞察。
在统计分析之前,先去掉若干有缺失值的数据,此时文本数据总量为33,394。
(1)文章数据的描述性分析
先对所有文章的各个维度进行描述性统计分析,获得这些数据的“初の印象”。
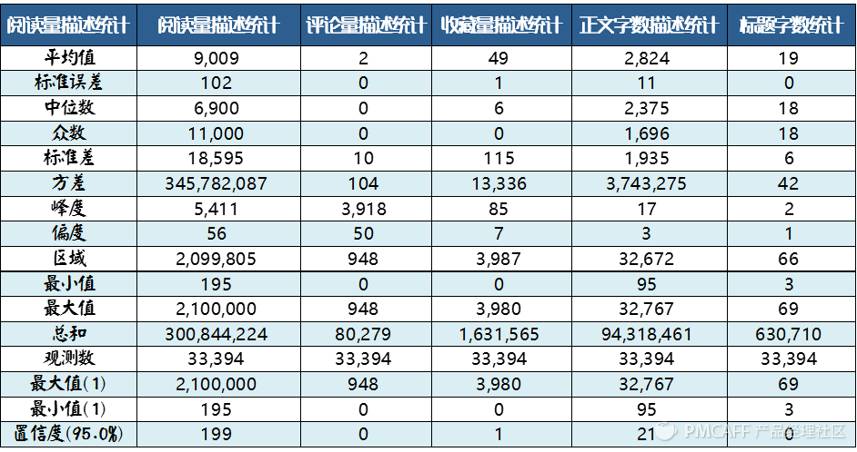
上面的数据过多,为节省篇幅,笔者仅摘取部分数据进行解读:
-
从上表中,笔者发现,单篇文章阅读量的最大值是2,100,000!阅读数高得惊人!在后面的截图中,小伙伴们可以知晓具体是哪一篇文章如此之高的阅读热度。
-
读者的评论热情不高,绝大部分的文章没有评论,这可以从“平均值”、“中位数”和“标准差”这3项指标中看出。
-
绝大部分的文章字数不超过3000,篇幅短小精悍,当然大多数文章都有配图,写得太长,读者懒得看。
-
绝大部分的标题字数不超过20字,太短说不清楚,太长看着招人烦。
(2)文章聚类分析
在该部分,笔者选取 “阅读量”、“收藏量”、“评论量”、“标题字数”这4个维度作为此次聚类分析的特征(Feature),它们共同构造了一个四维空间,每一篇文章因其在这4个维度上的数值不同,在四维空间中形成一个个的点。
以下是由DBSCAN自动聚类形成的图像,因4维空间难以在现实中呈现,故以2维的形式进行展示。
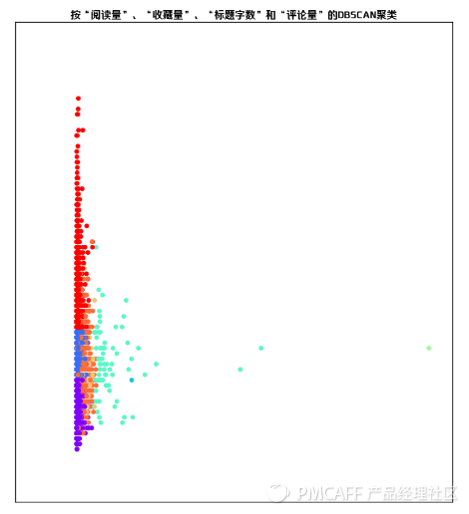
从上图可以看出,此次聚类中,有少数的异常点,由上面的描述型分析可知,阅读量极大的那几篇文章的“嫌疑”最大,现在在源数据中“揪出”它们,游街示众,然后再“除掉”。
去除掉上述异常点之后的聚类图谱:
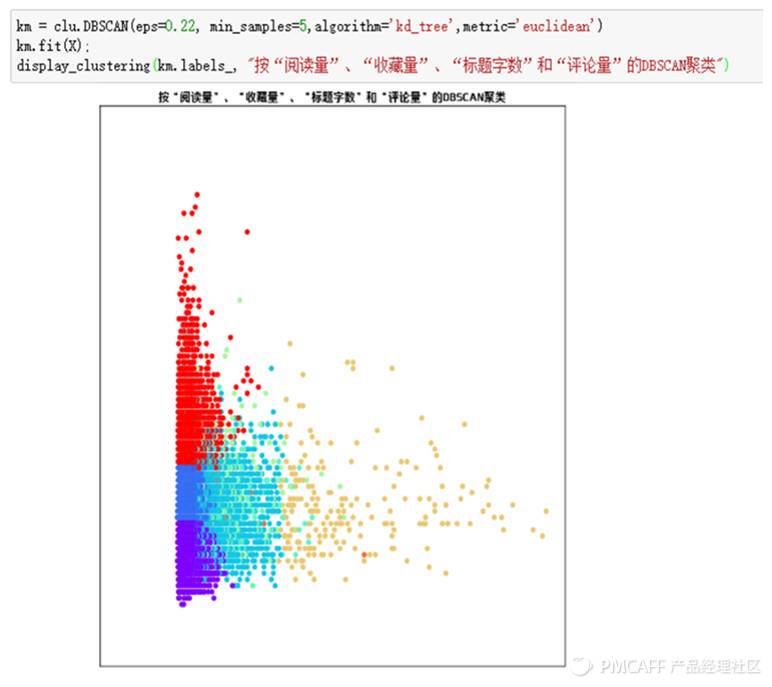
从上图中可以看出,虽然因为维度过高,不同类别簇群存在重合现象,但不同的颜色明显的将文章类别进行了区分,按照“阅读量”、“收藏量”、“评论量”、“标题字数”这4个维度进行的DBSCAN聚类可以分为5个类别。
(3)阅读量与正文字数、标题字数之间的关联分析
接着,笔者分别对“阅读量”与“标题字数”、“正文字数”做了散点图分析,以期判断它们之间是否存在相关关系。
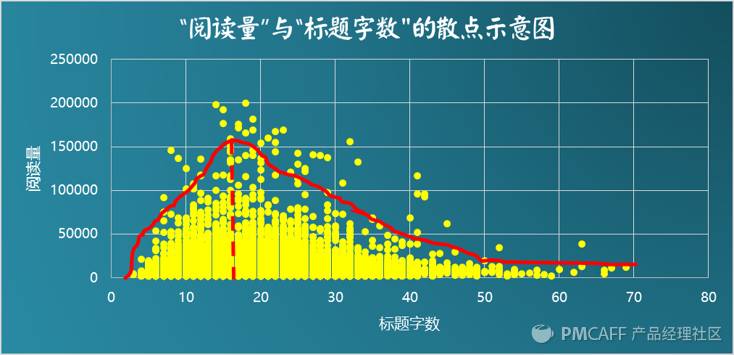
从上图来看,阅读量和标题字数之间并没有明显的线性相关性,标题字数及其对应数量的散点分布,近似形成了一条左偏态的正态曲线,从图像上印证了上面的描述性分析,而且更新了我们的认知:在10~30这个“标题字数”区间的文章数量最多,而标题字数过多未必是好事。
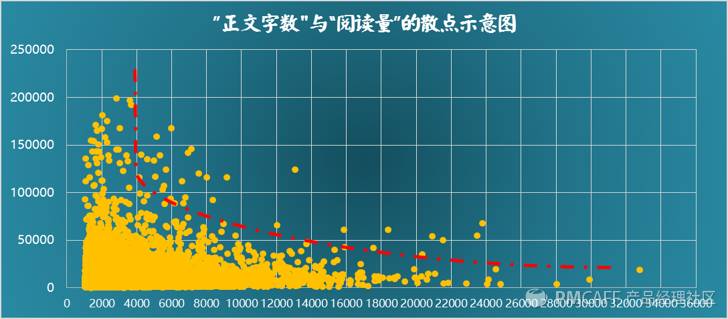
从上图可以看出,从1000字开始,阅读量和正文字数在大体上呈负相关关系,即文章字数越多,阅读量越小。由此看来,大家都比较喜欢短平快的“快餐式”阅读,篇幅太长的文章看起来太磨人。
6.1.3 热门文章特征分析
一篇文章的“收藏量”能在一定程度上反映读者对该文章的价值度的认可,较高的收藏量能代表该文章的质量属于上乘。而从一定数量的高收藏量文章中,我们又能间接的从中发掘出读者的阅读偏好,进而界定读者群体的某些特征。
在这部分,笔者筛选出收藏量大于1,000的文章,各栏目合计下来,不多不少,刚好60篇。以下是它们在各栏目下的数量分布情况:
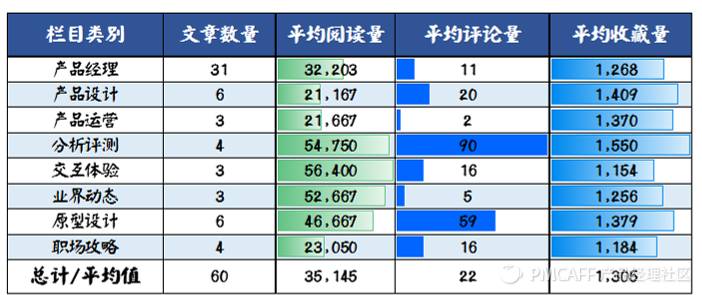
从上表中,笔者发现如下信息:
-
“产品经理”栏目下收藏量过1,000的文章数量最多,占到半数;
-
“分析评测”下的文章数量不多,但读者互动最多(平均评论量为90);
-
“分析评测”、“交互体验”、“业界动态”、“原型设计”入围的文章数量不多,但它们的平均阅读量较高
以上3点仅是从数值型数据上获得的认知,但是这些热门文章到底有哪些特征,我们不得而知,由此,笔者统计了这些热门文章的标题中的高频词,并将其制成关键词云:




