
原文来源
:
hackernoon
作者:Harshvardhan Gupta
「机器人圈」编译:嗯~阿童木呀
这是两篇文章的第二篇,为了更系统地了解与掌握该教程,在阅读本文之前,建议最好通读机器人圈的
前一篇文章
。
在前一篇文章中,我们讨论了小样本数据旨在解决的主要问题类别,以及孪生网络之所以能够成为解决这个问题优良选择的原因。首先,我们来重温一个特殊的损失函数,它能够在数据对中计算两个的图像相似度。我们现在将在PyTorch中实施我们之前所讨论的全部内容。
你可以在本文末尾查看完整的代码链接
架构
我们将使用的是标准卷积神经网络(CNN)架构,在每个卷积层之后使用批量归一化,然后dropout。
代码片段:孪生网络架构:
class SiameseNetwork(nn.Module):
def __init__(self):
super(SiameseNetwork, self).__init__()
self.cnn1 = nn.Sequential(
nn.ReflectionPad2d(1),
nn.Conv2d(1, 4, kernel_size=3),
nn.ReLU(inplace=True),
nn.BatchNorm2d(4),
nn.Dropout2d(p=.2),
nn.ReflectionPad2d(1),
nn.Conv2d(4, 8, kernel_size=3),
nn.ReLU(inplace=True),
nn.BatchNorm2d(8),
nn.Dropout2d(p=.2),
nn.ReflectionPad2d(1),
nn.Conv2d(8, 8, kernel_size=3),
nn.ReLU(inplace=True),
nn.BatchNorm2d(8),
nn.Dropout2d(p=.2),
)
self.fc1 = nn.Sequential(
nn.Linear(8*100*100, 500),
nn.ReLU(inplace=True),
nn.Linear(500, 500),
nn.ReLU(inplace=True),
nn.Linear(500, 5)
)
def forward_once(self, x):
output = self.cnn1(x)
output = output.view(output.size()[0], -1)
output = self.fc1(output)
return output
def forward(self, input1, input2):
output1 = self.forward_once(input1)
output2 = self.forward_once(input2)
return output1, output2
其实这个网络并没有什么特别之处,它可以接收一个100px * 100px的输入,并且在卷积层之后具有3个完全连接的层。
在上篇文章中,我展示了一对网络是如何处理数据对中的每个图像的。但在这篇文章中,只有一个网络。因为两个网络的权重是相同的,所以我们使用一个模型并连续地给它提供两个图像。之后,我们使用两个图像来计算损失值,然后再返回传播。这样可以节省大量的内存,绝对不会影响其他指标(如精确度)。
对比损失
我们将对比损失定义为
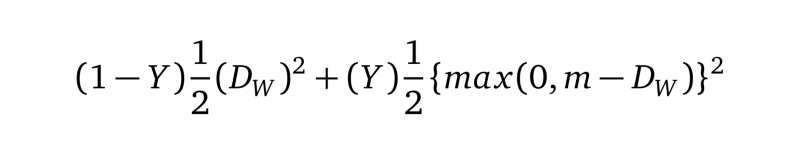 等式1.0
等式1.0
我们将Dw(也就是欧氏距离)定义为:
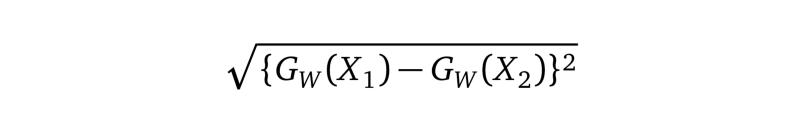
等式1.1
Gw是我们网络的一个图像的输出。
PyTorch中的对比损失看起来是这样的:
代码片段:默认边际价值为2的对比损失:
class ContrastiveLoss(torch.nn.Module):
"""
Contrastive loss function.
Based on: http://yann.lecun.com/exdb/publis/pdf/hadsell-chopra-lecun-06.pdf
"""
def __init__(self, margin=2.0):
super(ContrastiveLoss, self).__init__()
self.margin = margin
def forward(self, output1, output2, label):
euclidean_distance = F.pairwise_distance(output1, output2)
loss_contrastive = torch.mean((1-label) * torch.pow(euclidean_distance, 2) +
(label) * torch.pow(torch.clamp(self.margin - euclidean_distance, min=0.0), 2))
return loss_contrastive
数据集
在上一篇文章中,我想使用MNIST,但有些读者建议我使用我在同篇文章中所讨论的面部相似性样本。因此,我决定从MNIST / OmniGlot切换到AT&T面部数据集。
数据集包含40名测试对象的不同角度的图像。我从训练中挑选出3名测试对象的图像,以测试我们的模型。
不同类的样本图像

一名测试对象的所有样本图像
数据加载
我们的架构需要一个输入对,以及标签(类似/不相似)。因此,我创建了自己的自定义数据加载器来完成这项工作。它使用图像文件夹从文件夹中读取图像。这意味着你可以将其用于任何你所希望的数据集中。
代码段:该数据集生成一对图像和相似性标签。如果图像来自同一个类,标签将为0,否则为1:
class SiameseNetworkDataset(Dataset):
def __init__(self,imageFolderDataset,transform=None,should_invert=True):
self.imageFolderDataset = imageFolderDataset
self.transform = transform
self.should_invert = should_invert
def __getitem__(self,index):
img0_tuple = random.choice(self.imageFolderDataset.imgs)
#we need to make sure approx 50% of images are in the same class
should_get_same_class = random.randint(0,1)
if should_get_same_class:
while True:
#keep looping till the same class image is found
img1_tuple = random.choice(self.imageFolderDataset.imgs)
if img0_tuple[1]==img1_tuple[1]:
break
else:
img1_tuple = random.choice(self.imageFolderDataset.imgs)
img0 = Image.open(img0_tuple[0])
img1 = Image.open(img1_tuple[0])
img0 = img0.convert("L")
img1 = img1.convert("L")
if self.should_invert:
img0 = PIL.ImageOps.invert(img0)
img1 = PIL.ImageOps.invert(img1)
if self.transform is not None:
img0 = self.transform(img0)
img1 = self.transform(img1)
return img0, img1 , torch.from_numpy(np.array([int(img1_tuple[1]!=img0_tuple[1])],dtype=np.float32))
def __len__(self):
return len(self.imageFolderDataset.imgs)
孪生网络数据集生成一对图像,以及它们的相似性标签(如果为真,则为0,否则为1)。 为了防止不平衡,我将保证几乎一半的图像是同一个类的,而另一半则不是。
训练孪生网络
孪生网络的训练过程如下:
1.
通过网络传递图像对的第一张图像。
2.
通过网络传递图像对的第二张图像。
3.
使用1和2中的输出来计算损失。
4.
返回传播损失计算梯度
5.
使用优化器更新权重。我们将用Adam来进行演示:
代码片段:训练孪生网络:
net = SiameseNetwork().cuda()
criterion = ContrastiveLoss()
optimizer = optim.Adam(net.parameters(),lr = 0.0005 )
counter = []
loss_history = []
iteration_number= 0
for epoch in range(0,Config.train_number_epochs):
for i, data in enumerate(train_dataloader,0):
img0, img1 , label = data
img0, img1 , label = Variable(img0).cuda(), Variable(img1).cuda() , Variable(label).cuda()
output1,output2 = net(img0,img1)
optimizer.zero_grad()
loss_contrastive = criterion(output1,output2,label)
loss_contrastive.backward()
optimizer.step()
if i %10 == 0 :
print("Epoch number {}\n Current loss {}\n".format(epoch,loss_contrastive.data[0]))
iteration_number +=10
counter.append(iteration_number)
loss_history.append(loss_contrastive.data[0])
show_plot(counter,loss_history)
网络使用Adam,以0.0005的学习率进行了100次的迭代训练。随着时间的变化,损失曲线如下所示:
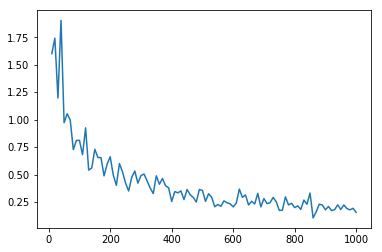
随时间变化的损失值曲线,x轴代表迭代次数









