(点击
上方公众号
,可快速关注)
来源:伯乐在线专栏作者 - selfboot
如有好文章投稿,请点击 → 这里了解详情
如需转载,发送「转载」二字查看说明
在人机交互之字符编码 一文中对字符编码进行了详细的讨论,并通过一些简单的小程序验证了我们对于字符编码的认识。但仅了解这篇文章的内容,并不能帮我们在日常编程中躲过一些字符编码相关的坑,Stackoverflow 上就有大量编码相关的问题,比如 1,2,3。
本文首先尝试对编码、解码进行一个宏观、直观的解读,然后详细来解释 python2 中的str和unicode,并对常见的UnicodeEncodeError 和 UnicodeDecodeError 异常进行剖析。
如何理解编、解码?
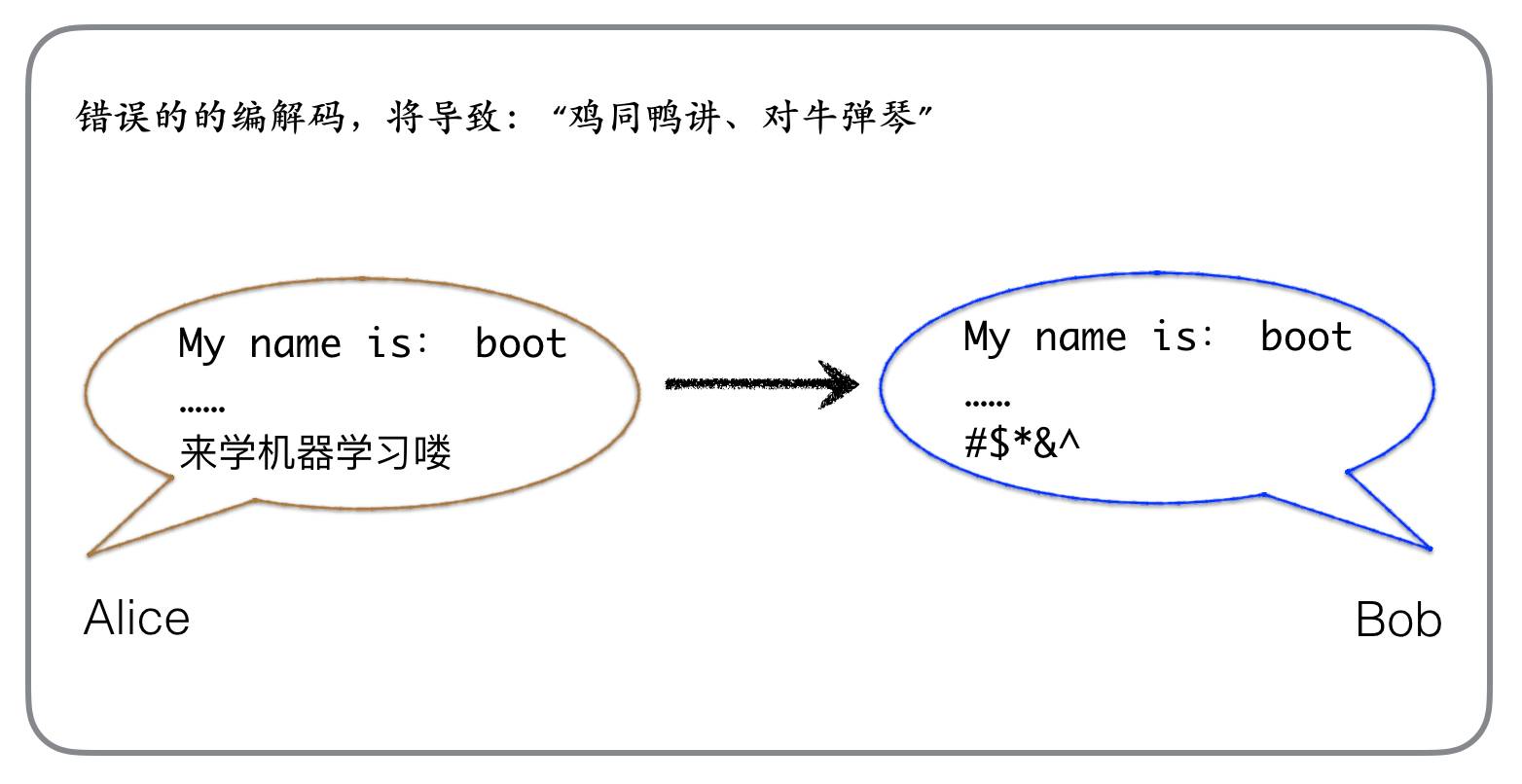
如何去理解编码、解码?举个例子,Alice同学刚加入了机器学习这门课,想给同班的Bob同学打个招呼。但是作为人,Alice不能通过意念和Bob交流,必须通过某种方式,比如手语、声音、文字等来表达自己的想法。如果Alice选择用文字,那么他可能会写下这么一段文字:My name is: boot …… 来学机器学习喽,写文字这个过程其实就是
编码
,经过编码后的文字才能给Bob看。Bob收到Alice的文字后,就会用自己对文字的认知来解读Alice传达的含义,这个过程其实就是
解码
。当然,如果Bob不懂中文,那么就无法理解Alice的最后一句了,如果Bob不识字,就完全不知道Alice想表达什么了。
上面的例子只是为了方便我们理解编码、解码这个抽象的概念,现在来看看对于计算机程序来说,如何去理解字符的编码、解码过程。我们知道绝大多数程序都是读取数据,做一些操作,然后输出数据。比如当我们打开一个文本文件时,就会从硬盘读取文件中的数据,接着我们输入了新的数据,点击保存后,文本程序会将更新后的内容输出到硬盘。程序读取数据就相当于Bob读文字,必须进行一个解码的过程,解码后的数据才能让我们进行各种操作。同理,保存到硬盘时,也需要对数据进行编码。
下图方框 A 代表一个输出数据的程序,方框 B 代表一个读取数据的程序。当然这里的程序只是一个概念,表示一个处理数据的逻辑单元,可以是一个进程、一个函数甚至一个语句等。A 和 B 也可以是同一个程序,先解码外部获取的数据,内部操作后,再进行某种编码。
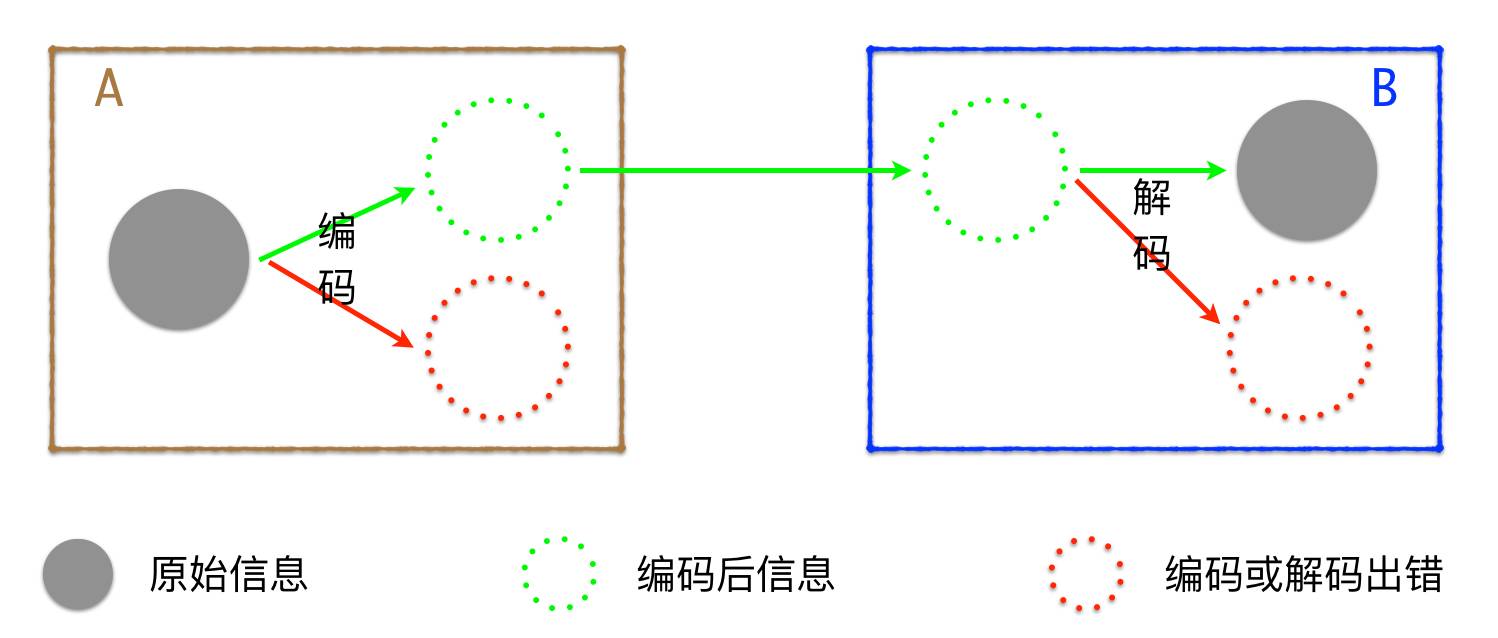
值得注意的是,有的编码方案不一定能表示某些信息,这时编码就会失败,比如 ASCII 就不能用来表示中文。当然,如果以错误的方式去解读某段内容,解码也会失败,比如用 ASCII 来解读包含 UTF-8的信息。至于什么是 ASCII,UTF-8等,在人机交互之字符编码 中有详细的说明,这里不再赘述。下面结合具体的例子,来看看编码、解码的细节问题。
python2.x 中的字符串
在程序设计中,字符串一般是指一连串的字符,比如hello world!、你好或者もしもし(日语)等等。各种语言对于字符串的支持各不相同,Python 2 中字符串的设计颇不合理,导致新手经常会出现各种问题,类似下面的提示信息相信很多人都遇到过(UnicodeEncodeError 或者 UnicodeDecodeError):
Traceback
(
most recent call
last
)
:
File
"
"
,
line
1
,
in
module
>
UnicodeEncodeError
:
'ascii'
codec
can
'
t
encode characters
in
position
0
-
1
:
ordinal
not
in
range
(
128
)
下面我们一起来解决这个疑难杂症。首先需要搞清楚python中的两个类型:
和
,文档中关于这两个类型的说明其实挺含糊的:
There are seven sequence types: strings, Unicode strings, lists, …
String literals are written in single or double quotes: ‘xyzzy’, “frobozz”. Unicode strings are much like strings, but are specified in the syntax using a preceding ‘u’ character: u’abc’, u”def”.
上面并没有给出什么有用的信息,不过好在
这篇文章
(https://www.azavea.com/blog/2014/03/24/solving-unicode-problems-in-python-2-7/)讲的特别好,简单来说:
-
str:是字节串(container for bytes),由 Unicode 经过编码(encode)后的字节组成的。
-
unicode:真正意义上的字符串,其中的每个字符用 Unicode 中对应的 Code Point 表示。翻译成人话就是,unicode 有点类似于前面 Alice 打招呼传递的想法,而 str 则是写下来的文字(或者是说出来的声音,甚至可以是手语)。我们可以用 GBK,UTF-8 等编码方案将 Unicode 类型转换为 str 类型,类似于用语言、文字或者手语来表达想法。
repr 与终端交互
为了彻底理解字符编码、解码,下面要用 python 交互界面进行一些小实验来加深我们的理解(下面所有的交互代码均在 Linux 平台下)。在这之前,我们先来看下面交互代码:
>>>
demo
=
'Test 试试'
>>>
demo
'Test \xe8\xaf\x95\xe8\xaf\x95'
当我们只输入标识符 demo 时,终端返回了 demo 的内容。这里返回的内容是怎么得到呢?答案是通过 repr() 函数 获得。文档中对于 repr 函数解释如下:
> Return a string containing a printable representation of an object.
所以,我们可以在源文件中用下面的代码,来获取和上面终端一样的输出。
#! /usr/bin/env python
# -*- coding: UTF-8 -*-
demo
=
'Test 试试'
print repr
(
demo
)
# 'Test \xe8\xaf\x95\xe8\xaf\x95'
对于字符串来说,repr() 的返回值很好地说明了其在python内部的表示方式。通过 repr 的返回值,我们可以真切体会到前面提到的两点:
unicode 类型
unicode 是真正意义上的字符串
,为了理解这句话,先看下面的一段代码:
>>>
unicode_str
=
u
'Welcome to 广州'
# ''前面的 u 表示这是一个 unicode 字符串
>>>
unicode_str
,
type
(
unicode_str
)
# repr(unicode_str)
(
u
'Welcome to \u5e7f\u5dde'
,
type
'unicode'
>
)
repr 返回的 Welcome to \u5e7f\u5dde 说明了unicode_str存储的内容,其中两个\u后面的数字分别对应了广、州在unicode中的code point:
>>>
'{:04x}'
.
format
(
ord
(
u
'广'
))
'5e7f'
>>>
'{:04x}'
.
format
(
ord
(
u
'W'
))
'0057'
总结一下,我们可以将
看作是一系列字符组成的数组,数组的每一项是一个code point,用来表示相应位置的字符。所以对于 unicode 来说,其长度等于它包含的字符(a 和 广 都是一个字符)的数目。
>>>
len
(
unicode_str
)
13
>>>
unicode_str
[
0
],
unicode_str
[
12
],
unicode_str
[
-
1
]
(
u
'W'
,
u
'\u5dde'
,
u
'\u5dde'
)
str 类型
str 是字节串(container for bytes)
,为了理解这句话,先来看下面的一段代码:
>>>
str_str
=
'Welcome to 广州'
# 这是一个 str
>>>
str_str
,
type
(
str_str
)
(
'Welcome to \xe5\xb9\xbf\xe5\xb7\x9e'
,
type
'str'
>
)
python中 \xhh(h为16进制数字)表示一个字节,输出中的\xe5\xb9\xbf\xe5\xb7\x9e 就是所谓的字节串,它对应了广州。实际上 str_str 中的英文字母也是保存为字节串的,不过 repr 并没有以 \x 的形式返回。为了验证上面输出内容确实是字节串,我们用python提供的 bytearray 函数将相同内容的 unicode字符串用 UTF-8 编码为字节数组,如下所示:
>>>
unicode_str
=
u
'Welcome to 广州'
>>>
bytearray
(
unicode_str
,
'UTF-8'
)
bytearray
(
b
'Welcome to \xe5\xb9\xbf\xe5\xb7\x9e'
)
>>>
list
(
bytearray
(
unicode_str
,
'UTF-8'
))
# 字节数组,每一项为一个字节;
[
87
,
101
,
108
,
99
,
111
,
109
,
101
,
32
,
116
,
111
,
32
,
229
,
185
,
191
,
229
,
183
,
158
]
>>>
print
r
"\x"
+
r
"\x"
.
join
([
"%02x"
%
c
for
c
in
list
(
bytearray
(
unicode_str
,
'UTF-8'
))])
# 转换为 \xhh 的形式
\
x57
\
x65
\
x6c
\
x63
\
x6f
\
x6d
\
x65
\
x20
\
x74
\
x6f
\
x20
\
xe5
\
xb9
\
xbf
\
xe5
\
xb7
\
x9e
可见,上面的 strstr 是 unicode_str 经过 UTF-8 编码 后的字节串。这里透漏了一个十分重要的信息,
str类型隐含有某种编码方式
,正是这种隐式编码(_implicit encoding)的存在导致了许多问题的出现(后面详细说明)。值得注意的是,str类型字节串的隐式编码不一定都是’UTF-8’,前面示例程序都是在 OS X 平台下的终端,所以隐式编码是 UTF-8。对于 Windows 而言,如果语言设置为简体中文,那么交互界面输出如下:
# Win 平台下,系统语言为简体中文
>>>
str_str
=
'Welcome to 广州'
>>>
str_str
,
type
(
str_str
)
(
'Welcome to \xb9\xe3\xd6\xdd'
,
type
'str'
>
)
这里str_str的隐式编码是cp936,可以用 bytearray(unicode_str, 'cp936') 来验证这点。终端下,str类型的隐式编码由系统 locale 决定,可以采用下面方式查看:
# Unix or Linux
>>>
import
locale
>>>
locale
.
getdefaultlocale
()
(
'zh_CN'
,
'UTF-8'
)
...
# 简体中文 Windows
>>>
locale
.
getdefaultlocale
()
(
'zh_CN'
,
'cp936'
)
总结一下,我们可以将
看作是unicode字符串经过某种编码后的字节组成的数组。数组的每一项是一个字节,用 \xhh 来表示。所以对于 str 字符串来说,其长度等于编码后字节的长度。
>>>
len
(
str_str
)
17
>>>
str_str
[
0
],
str_str
[
-
1
]
(
'W'
,
'\x9e'
)
# 实际上是('\x57', '\x9e')
类型转换
Python 2.x 中为上面两种类型的字符串都提供了 encode 和 decode 方法,原型如下:
> str.decode([encoding[, errors]]) > str.encode([encoding[, errors]])
利用上面的两个函数,可以实现 str 和 unicode 类型之间的相互转换,如下图所示:
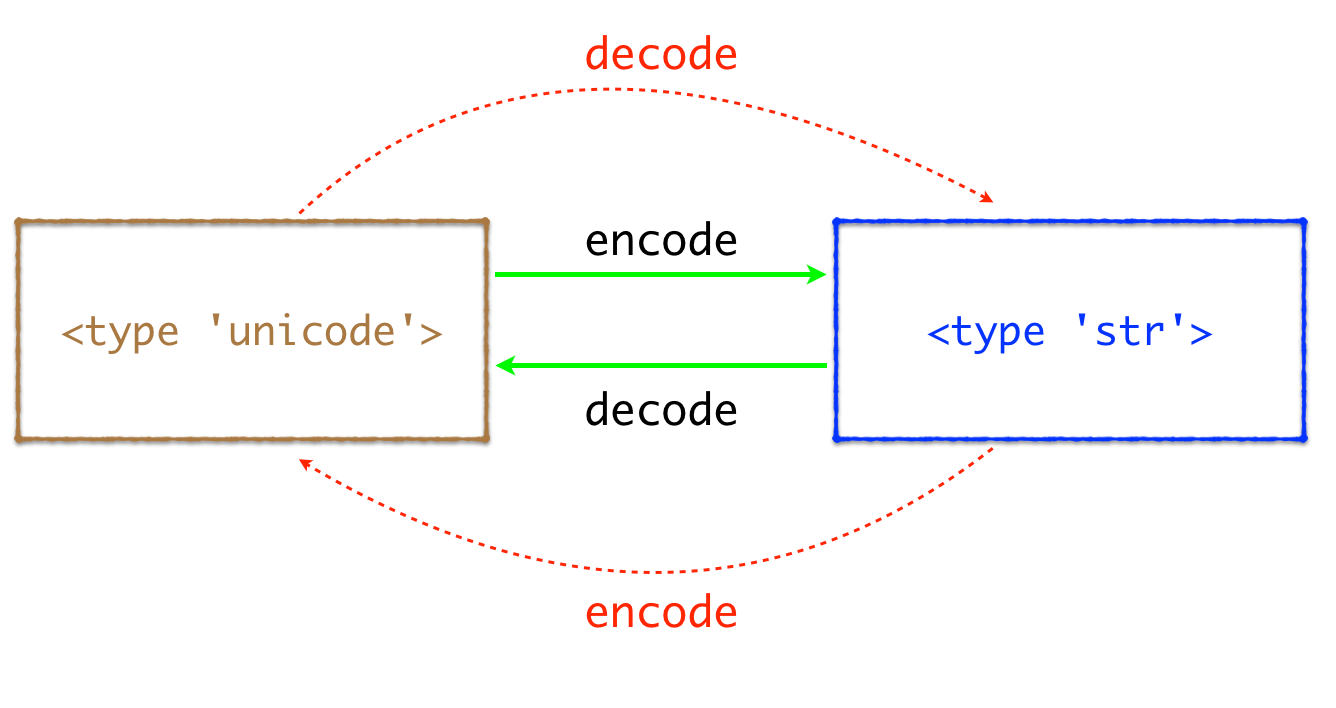
上图中绿色线段标示的即为我们常用的转换方法,红色标示的转换在 python 2.x 中是合法的,不过没有什么意义,通常会抛出错误(可以参见 What is the difference between encode/decode?)。下面是两种类型之间的转换示例:
# decode:
到
的转换
>>>
enc
=
str_str
.
decode
(
'utf-8'
)
>>>
enc
,
type
(
enc
)
(
u
'Welcome to \u5e7f\u5dde'
,
type
'unicode'
>
)
# encode:
到
的转换
>>>
dec
=
unicode_str
.
encode
(
'utf-8'
)
>>>
dec
,
type
(
dec
)
(
'Welcome to \xe5\xb9\xbf\xe5\xb7\x9e'
,
type
'str'
>
)
上面代码中通过encode将unicode类型
编码
为str类型,通过 decode 将str类型
解码
为unicode类型。当然,编码、解码的过程并不总是一帆风顺的,通常会出现各种错误。
编、解码错误
Python 中经常会遇到 UnicodeEncodeError 和 UnicodeDecodeError,怎么产生的呢? 如下代码所示:
>>>
u
'Hello 广州'
.
encode
(
'ascii'
)
Traceback
(
most recent call
last
)
:
File
"
"
,
line
1
,
in
module
>
UnicodeEncodeError
:
'ascii'
codec
can
't encode characters in position 6-7: ordinal not in range(128)
>>> '
Hello
广州
'.decode('
ascii
')
Traceback (most recent call last):
File "
", line 1, in
UnicodeDecodeError: '
ascii
' codec can'
t
decode
byte
0xe5
in
position
6
:
ordinal
not
in
range
(
128
)
当我们用 ascii 去编码带有中文的unicode字符串时,发生了UnicodeEncodeError,当我们用 ascii 去解码有中文的str字节串时,发生了UnicodeDecodeError。我们知道,ascii 只包含 127 个字符,根本无法表示中文。所以,让 ascii 来编码、解码中文,就超出了其能力范围。这就像你对一个不懂中文的老外说中文,他根本没法听懂。简单来说,
所有的编码、解码错误都是由于所选的编码、解码方式无法表示某些字符造成的
。
有时候我们就是想用 ascii 去编码一段夹杂中文的str字节串,并不希望抛出异常。那么可以通过 errors 参数来指定当无法编码某个字符时的处理方式,常用的处理方式有 “strict”,”ignore”和”replace”。改动后的程序如下:
>>>
u
'Hello 广州'
.
encode
(
'ascii'
,
'replace'
)
'Hello ??'
>>>
u
'Hello 广州'
.
encode
(
'ascii'
,
'ignore'
)
'Hello '
隐藏的解码
str和unicode类型都可以用来表示字符串,为了方便它们之间进行操作,python并不要求在操作之前统一类型,所以下面的代码是合法的,并且能得到正确的输出:
>>>
new_str
=
u
'Welcome to '
+
'GuangZhou'
>>>
new_str
,
type
(
new_str
)
(
u
'Welcome to GuangZhou'
,
type
'unicode'
>
)
因为str类型是隐含有某种编码方式的字节码,所以python内部将其
解码
为unicode后,再和unicode类型进行 + 操作,最后返回的结果也是unicode类型。
第2步的解码过程是在幕后悄悄发生的,
默认采用ascii来进行解码
,可以通过 sys.getdefaultencoding() 来获取默认编码方式。Python 之所以采用 ascii,是因为 ascii 是最早的编码方式,是许多编码方式的子集。
不过正是这个不可见的解码过程,有时候会导致出乎意料的解码错误,考虑下面的代码:
>>>
u
'Welcome to'










