如果你手上有一批数据,你可能应用统计学、挖掘算法、可视化方法等技术玩转你的数据,但你没有数据的时候,我该怎么玩呢?接下来就带着大家玩玩没有数据情况下的数据分析。
所有涉及到价格变动的问题,都要先确定一点——经济学上决定商品价格的第一因素是什么?供求。就算认定国家故意操纵房价的人,也是认同控制土地供给等于控制房价的概念的。
那么根据以上定律,房价要怎么样才能跌?没人要买房子的时候房价就会跌了。以此为基础进行推演,既然现在想住房子但是由于经济原因无法实现的人都在盼跌,那么我问你,如果房价是因为没人要买房所以下跌的话,那个时候房子已经没人要买了,你为什么还要买?所以现在那些吸引不了外地前来的劳动力安家扎根同时本地居民也没有改善自己现有住房的期望的地方,房价进入了下行的通道。
那么有没有一种在大家都想买的前提下,房价又确实在下跌的情况?在2013年3月1日,国务院出台国五条细则,其中最引人关注的便是个人出售房产要严格按照转让所得的20%计征个人所得税,力度之大令市场始料不及。此政策一出台,被解读为政府决心出手压制过热的房地产市场,此后许多房东为了赶在所得税开征之前完成交易躲避税费,降价抛售的也绝不在少数。这正是一个在买卖双方供需量没有明显变化情况下为了迅速完成交易导致商品价格下行的例子。过去荷兰是欧洲的花卉出口中心,由于花卉的保质期非常短,交易必须迅速进行,于是荷兰出现了一种拍卖方式:拍卖人以一个较高价格起拍,之后逐步降低价格,直到有人愿意以此价格成交。这种拍卖方式的优点就是迅速,它也适用于海鱼、乳制品等易变质物品的拍卖,这种拍卖方式也被称为荷兰式拍卖。现假设有一套房子,房东以300万的价格开售,短时间内没有买家问津,房东只好开始降价,你对这个房子的心理价位是250万,但是很遗憾,房东降价到275万的时候就被心理价位在275万的买家成交了。因此在这种情况下的问题就是,你要么购买力比别人都高,要么就要等到所有购买力比你高的人都完成了交易,这时你只能祈祷当地的库存量能多到把购买力比你高的买家都喂饱了,不然对你来说,买不起的房子还是买不起。另外补充一点,国家将房产交易过程中定价明显低于应有市场价的行为界定为逃税,是要依法打击的,所以就算是父母想以低价将自己名下的房屋过户给子女是不行的,还是需要以一个合理价格进行交易并支付税费,其实这从一定程度上支持了国家操纵房价的论点。当然,最后这个政策对房价的调控也是然并卵,这20%的所得税就算是支持政府开支了。
那么再考虑一个情况,政府出台了一种摇号或排号政策,每个月放出一定的低价房源,摇到或者排到号的人可以低价购买,其实就类似于现在的廉租房或保障性住房。大家不妨回忆不久前的北京医院女子大骂黄牛的事件,再想想每年春运期间抢火车票的盛况,一件商品被人为地压制了价格,要不就滋生黄牛,要不就需要消费者用上吃奶的力气抢购。
综上,现在想要置身世外幻想在自己的购买力没有变化的情况下,房价崩盘暴跌,是非常不现实的。而房价的变化应该是和民众的购买力相关的。为什么北上广深这几年的房价涨幅如此凶猛,多少人即使倾尽家财加上贷款也要拼命去供一个并不算舒适的房子?这些购房者其实内心都有一个信念——现在虽然还款压力大,但是我的收入是会增长的,等过几年,我的收入增加了,压力就不大了,如果那时房价再上涨,卖掉手上的房子,我就能再置换舒适点的房子了。为什么国内几个一线城市每年都能吸引那么多年轻人心甘情愿地离乡背井在此打拼?归根结底,这些一线城市给予了年轻人向上的通道,每天都有数不清的机遇在等待发掘。新兴的金融业、IT业每天都在制造着新的百万富翁,所以什么时候。有人提出了一个结论:“我无法预言房价是涨是跌,但我能知道我什么时候该买房。那就是当你收入增速放缓并且未来可能不会有较高年增长率时,你就应该在自己能力范围内买房了。”我在这个答案下评论:10年前在1线城市贷款买的房子,哪怕这10年工资收入没有任何长进,光房价的增值就能直接让你财富翻番;而10年前如果没有看好房市而选择了储蓄,那么这10年哪怕你收入翻倍也赶不上脚下土地的涨幅了。如果再完善一下这个结论,我会说最佳的购房时机是——当你购买力的增长速度比不过当地的房地产价格的增长速度的时候,你就应该在自己能力范围内买房了。”为什么现在房地产的行情是三四线城市松动,二线城市滞涨,一线城市继续高歌猛进?因为三四线城市已经失去了经济发展的动力,购房者预期到自己的购买力可能不会有太大的增长了,自然就开始保守起来,日本在广场条约后经济泡沫破裂,很多人的月收入下挫到连支付月供都有困难,大量房东开始抛售房产,可惜此时的市场已经低落到买家也无法支付房款了,这就是国民购买力预期大幅下跌最终引致了房地产崩盘。
在此思考一下,一个房子应该值什么价?这个价值怎样衡量?最简单的,使用人民币衡量。为什么我国房地产在过去的十几年里如日中天?因为这十几年来国民的购买力增长着实可观。而我们也知道,人民币是一般等价物,是一种特殊的商品,如果我们把人民币换成其他的商品呢?猪肉、白菜、衣服甚至股票、基金、外汇、黄金、期货等等等等,这些东西都可以用人民币兑换,那么我们用房价来兑换这些商品,又会获得怎样的结果?2015年年初到年中的股票牛市,使用人民币在股市中投资的收益是可以远大于投资房地产的,那么这个时候,房价对于你来说其实就是下跌了。同样,如果你在2015年6月至现在选择了投资股票的话,房价对你来说真的就是“涨到天上去了”。我经常能听到这样的感慨:“早知道房价这么涨,10年前说什么也要贷款买房子。”俗话说,种一棵树最好的时间是10年前,其次是现在。我想问问,今天有多少人敢把自己的全部家当做投资,赌10年后的收益?我们要认识到,在我们之中其实没有多少人有这样的眼光和胆识,同样10年前能想到用买房投资的人,要么真的相信房价能涨,要么输得起真的不在乎那么点钱,那么这种人和现在在买房投资的人又有什么区别?以前投资房地产现在暴富的人,他们的今天都是用眼光和胆识换来的,如果你相信这只是运气好的话,何不带上你的梦想和存款去澳门走一遭?我相信把房地产作为投资品的人还是少数,在过去现在和未来,买房的人最普遍的心态还是——想买,而且也买得起。
我认为分析房价的涨跌是徒劳的,长期来看房价变化都应该略高于社会的普遍购买力,我们只看到日本房价大崩盘,但在房价崩盘之前,日本的国民经济已经崩盘了。房价的走势难以预测,但你总能预测下自己将来的购买力相对于社会平均水平到底是怎么个变化吧?要是连自己几斤几两都不知道,还要去预测国民经济的走向,是不是太想当然了点?例如你提升了自己的工作能力,升职加薪了,你的购买力提升了,房价相对来说就下跌了,所以这里投资收益大于房价的,正是你自己的工作技能。所谓水涨船高,其实我们只看到房价这个船在涨,有时候我们都忘了我们自己也泡在水里,水再涨,我们想上船(买房)的难度其实是没有变化的。这里的水,正是当地的经济发展水平,因为在用人民币衡量房价的基础下,经济振奋,国民购买力上升,房价涨;经济萎靡,国民购买力下降,房价跌。要么你在经济上行的时候跑的比别人快,要么在经济下行的时候摔得比别人轻,如果你的购买力变化仅仅取决于社会整体财富水平的涨跌的话,现在买不起的房子,以后任何时候你一样买不起。说到这里不得不说说财富分配的问题了,最近在知乎上被热议的4万亿计划很大的一个问题就是这4万亿的水没有分流,被大量的集中在了少数的几个领域,并没有广泛地提高全社会的财富水平,反而拉大了贫富差距。对于光见房价涨不见工资涨的状况,症结在于这经济发展的“水”,没有流到你所在的行业,你和这个船不在一个池子里。前几年盛行“跑赢CPI”的说法,如果说收入能跑赢CPI算是对能力的肯定,那么收入跑赢房价,那这个房子确实是你应得的回报。
所以总结一下吧,对于想买房改善生活的各位,分各种情况来给出点建议:
1.现在的房价对你来说没有压力,那么早买早享受,直接一步到位买买得起的范围内最好的。
2.你现在有足够支付首付的资金,也有偿还月供的能力,同时你没有明确的投资途径能让这笔资金的增值速度快于房市,但是工作稳定将来有一定的上升空间,那么买。
3. 你现在有支付首付的资金,但是你有投资的打算并且认为投资的回报能大于房价的增长,那么投资。但是要注意一点,我举个例子,按照现在首套房30%的首付比例来说,你有90万本金,目标是购买300万的房子,如果1年后房价上涨10%,那么90万的资金在这个时间内的收益必须同样达到10%以上,否则就失去了购房的资格了,同时在此期间你的月收入也要达到10%的增长才能实现购买力增长大于房价增长。房价年增长10%在上海太过常见,对于现在国内的投资环境来说,年化收益在10%应该是中高风险了。在这样的资产配置下,千万不要再盼房价跌了,此时房价一跌,经济环境不知道要恶劣到什么程度,这本金恐怕贬值速度也要快于房价了。当然,如果投资的本金翻倍,但购房的目标没变的话,年化收益就只要达到5%即可,这算是一个可控的风险程度了。不过这应该比较接近情况1这种压力不大的情况,买或不买,取决于自己的需求有多迫切。
4.最后说个比较悲剧的情况,如果你目前没有支付首付的能力,同时你没能让自己年收入净增长在房价的净增长之上,可能你真的是这个城市希望筛除的对象……
本文从如下几个角度详细讲解数据分析的流程:
1、数据源的获取;
2、数据探索与清洗;
3、模型构建(聚类算法和线性回归);
4、模型预测;
5、模型评估;
一、数据源的获取
正如本文的题目一样,我要分析的是上海二手房数据,我想看看哪些因素会影响房价?哪些房源可以归为一类?我该如何预测二手房的价格?可我手上没有这样的数据样本,我该如何回答上面的问题呢?
互联网时代,网络信息那么发达,信息量那么庞大,随便找点数据就够喝一壶了。前几期我们已经讲过了如何从互联网中抓取信息,采用Python这个灵活而便捷的工具完成爬虫,
当然,上海二手房的数据仍然是通过爬虫获取的,爬取的平台来自于链家,页面是这样的:

我所需要抓取下来的数据就是红框中的内容,即上海各个区域下每套二手房的小区名称、户型、面积、所属区域、楼层、朝向、售价及单价。先截几张Python爬虫的代码,源代码和数据分析代码写在文后的链接中,如需下载可以
回复公众号“二手房”获取下载链接。

上面图中的代码是构造所有需要爬虫的链接。

上面图中的代码是爬取指定字段的内容。
爬下来的数据是长这样的(总共28000多套二手房):

二、数据探索与清洗(一下均以R语言实现)
当数据抓下来后,按照惯例,需要对数据做一个探索性分析,即了解我的数据都长成什么样子。
1、户型分布
# 户型分布
library(ggplot2)
type_freq
# 绘图
type_p
type_p

我们发现只有少数几种的户型数量比较多,其余的都非常少,明显属于长尾分布类型(严重偏态),所以,考虑将1000套一下的户型统统归为一类。
# 把低于一千套的房型设置为其他
type
house$type.new
type_freq
# 绘图
type_p
type_p

2、二手房的面积和房价的分布
# 面积的正态性检验
norm.test(house$面积)

# 房价的正态性检验
norm.test(house$价格.W.)
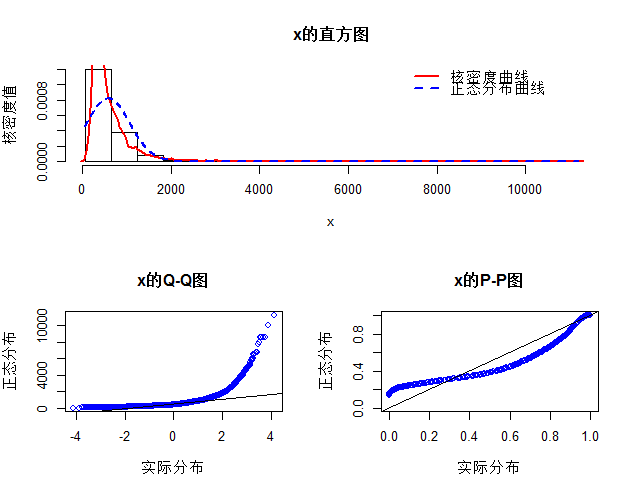
上面的norm.test函数是我自定义的函数,函数代码也在下文的链接中,可自行下载。从上图可知,二手房的面积和价格均不满足正态分布,那么就不能直接对这样的数据进行方差分析或构建线性回归模型,因为这两种统计方法,都要求正态性分布的前提假设,后面我们会将讲解如何处理这样的问题。
3、二手房的楼层分布
原始数据中关于楼层这一变量,总共有151种水平,如地上5层、低区/6层、中区/11层、高区/40层等,我们觉得有必要将这151种水平设置为低区、中区和高区三种水平,这样做有助于后面建模的需要。
# 把楼层分为低区、中区和高区三种
house$floow
# 各楼层类型百分比分布
percent
df
df
df

可见,三种楼层的分布大体相当,最多的为高区,占了36.1%。
4、上海各地区二手房的均价
# 上海各区房价均价
avg_price
#绘图
p
p

很明显,上海二手房价格最高的三个地区为:静安、黄埔和徐汇,均价都在7.5W以上,价格最低的三个地区为:崇明、金山和奉贤。
5、房屋建筑时间缺失严重

建筑时间这个变量有6216个缺失,占了总样本的22%。虽然缺失严重,但我也不能简单粗暴的把该变量扔掉,所以考虑到按各个区域分组,实现众数替补法。这里构建了两个自定义函数:
library(Hmisc)
# 自定义众数函数
stat.mode
if (rm.na == TRUE){
y = x[!is.na(x)]
}
res = names(table(y))[which.max(table(y))]
return(res)
}
# 自定义函数,实现分组替补
my.impute
miss.col = NULL, method = stat.mode){
impute.data = NULL
for(i in as.character(unique(data[,category.col]))){
sub.data = subset(data, data[,category.col] == i)
sub.data[,miss.col] = impute(sub.data[,miss.col], method)
impute.data = c(impute.data, sub.data[,miss.col])
}
data[,miss.col] = impute.data
return(data)
}
# 将建筑时间中空白字符串转换为缺失值
house$建筑时间[house$建筑时间 == '']
#分组替补缺失值,并对数据集进行变量筛选
final_house
#构建新字段,即建筑时间与当前2016年的时长
final_house
#删除原始的建筑时间这一字段
final_house
最终完成的干净数据集如下:

接下来就可以针对这样的干净数据集,作进一步的分析,如聚类、线性回归等。
三、模型构建
这么多的房子,我该如何把它们分分类呢?即应该把哪些房源归为一类?这就要用到聚类算法了,我们就使用简单而快捷的k-means算法实现聚类的工作。但聚类前,我需要掂量一下我该聚为几类?根据聚类原则:组内差距要小,组间差距要大。我们绘制不同类簇下的组内离差平方和图,聚类过程中,我们选择面积、房价和单价三个数值型变量:
tot.wssplot
#假设分为一组时的总的离差平方和
tot.wss
for (i in 2:nc){
#必须指定随机种子数
set.seed(seed)
tot.wss[i]
}
plot(1:nc, tot.wss, type="b", xlab="Number of Clusters",
ylab="Within groups sum of squares",col = 'blue',
lwd = 2, main = 'Choose best Clusters')
}
# 绘制不同聚类数目下的组内离差平方和
standrad
myplot

当把所有样本当作一类时,离差平方和达到最大,随着聚类数量的增加,组内离差平方和会逐渐降低,直到极端情况,每一个样本作为一类,此时组内离差平方和为0。从上图看,聚类数量在5次以上,组内离差平方降低非常缓慢,可以把拐点当作5,即聚为5类。
# 将样本数据聚为5类
set.seed(1234)
clust
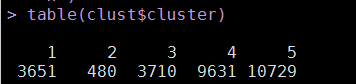
table(clust$cluster)
# 按照聚类的结果,查看各类中的区域分布
table(final_house$区域,clust$cluster)

# 各户型的平均面积
aggregate(final_house$面积, list(final_house$type.new), mean)

# 按聚类结果,比较各类中房子的平均面积、平均价格和平均单价
aggregate(final_house[,3:5], list(clust$cluster), mean)

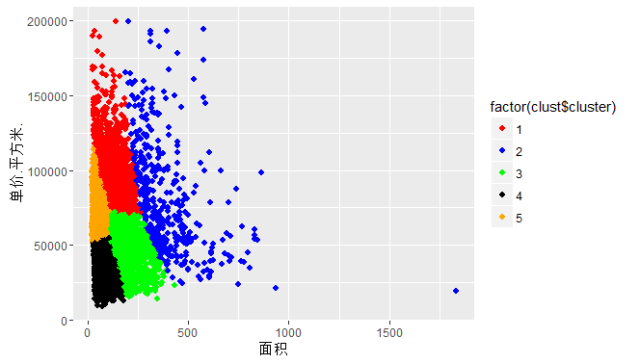
从平均水平来看,我大体可以将28000多套房源合成为如下几种说法:
a、大户型(3室2厅、4室2厅),属于第2类。平均面积都在130平以上,这种大户型的房源主要分布在青浦、黄埔、松江等地(具体可从各类中的区域分布图可知)。
b、地段型(房价高),属于第1类。典型的区域有黄埔、徐汇、长宁、浦东等地(具体可从各类中的区域分布图可知)。
c、大众蜗居型(面积小、价格适中、房源多),属于第4和5类。典型的区域有宝山、虹口、闵行、浦东、普陀、杨浦等地
d、徘徊型(大户型与地段型之间的房源),属于第3类。典型的区域有奉贤、嘉定、青浦、松江等地。这些地区也是将来迅速崛起的地方。
# 绘制面积与单价的散点图,并按聚类进行划分
p
p
p + scale_colour_manual(values = c("red","blue", "green", "black", "orange"))
接下来我想借助于已有的数据(房价、面积、单价、楼层、户型、建筑时长、聚类水平)构建线性回归方程,用于房价因素的判断及预测。由于数据中有离散变量,如户型、楼层等,这些变量入模的话需要对其进行哑变量处理。
# 构造楼层和聚类结果的哑变量
# 将几个离散变量转换为因子,目的便于下面一次性处理哑变量
final_house$cluster
final_house$floow
final_house$type.new
# 筛选出所有因子型变量
factors
# 将因子型变量转换成公式formula的右半边形式
formula
dummy
pred
head(pred)

# 将哑变量规整到final_house数据集中
final_house2
# 筛选出需要建模的数据
model.data
# 直接对数据进行线性回归建模
fit1
summary(fit1)

从体看上去还行,只有建筑时长和2室0厅的房型参数不显著,其他均在0.01置信水平下显著。不要赞赞自喜,我们说,使用线性回归是有假设前提的,即因变量满足正态或近似于正态分布,前面说过,房价明显在样本中是偏态的,并不服从正态分布,所以这里使用COX-BOX变换处理。根据COX-BOX变换的lambda结果,我们针对y变量进行转换,即:

# Cox-Box转换
library(car)
powerTransform(fit1)

根据结果显示,0.23非常接近上表中的0值,故考虑将二手房的价格进行对数变换。
fit2
summary(fit2)
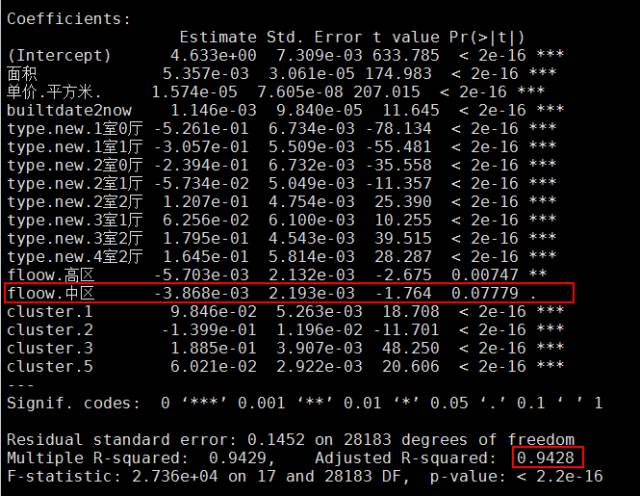
这次的结果就明显比fit1好很多,仅有楼层的中区在0.1置信水平下显著,其余变量均在0.01置信水平下显著,而且调整的R方值也提高到了94.3%,即这些自变量对房价的解释度达到了94.3%。
最后我们再看一下,关于最终模型的诊断结果:
# 使用plot方法完成模型定性的诊断
opar
par(mfrow = c(2,2))
plot(fit2)
par(opar)

从上图看,基本上满足了线性回归模型的几个假设,即:残差项服从均值为0(左上),标准差为常数(左下)的正态分布分布(右上)。基于这样的模型,我们就可以有针对性的预测房价啦~
点击文末阅读原文即可获得源代码
转自:https://mp.weixin.qq.com/s/DS4fFs0-rLD0UPkdTwQ5k
推荐文章
微信ID:SDx-SoftwareDefinedx
❶软件定义世界, 数据驱动未来;
❷ 大数据思想的策源地、产业变革的指南针、创业者和VC的桥梁、政府和企业家的智库、从业者的加油站;
❸个人微信号:sdxtime,
邮箱:[email protected];
=>> 长按右侧二维码关注。

 底部新增导航菜单,下载200多个精彩PPT,持续更新中!
底部新增导航菜单,下载200多个精彩PPT,持续更新中!









