出自雷锋网 http://www.leiphone.com/news/201608/Rlq2Vq5v8peap07S.html
本文详细介绍了
1)人工智能发展的七个重要阶段;
2)深度学习在人工智能的发展;
3)最后也提出作者对于深度学习挑战和未来发展的看法。
这两年人工智能热闹非凡,不仅科技巨头发力AI取得技术与产品的突破,还有众多初创企业获得风险资本的青睐,几乎每周都可以看到相关领域初创公司获得投资的报道,而最近的一次春雷毫无疑问是Google旗下Deepmind开发的人工智能AlphaGo与南韩李世石的围棋之战,AiphaGo大比分的获胜让人们对AI刮目相看的同时也引发了对AI将如何改变我们生活的思考。其实,人工智能从上世纪40年代诞生至今,经历了一次又一次的繁荣与低谷,首先我们来回顾下过去半个世纪里人工智能的各个发展历程。
|人工智能发展的七大篇章
人工智能的起源:人工智能真正诞生于20世纪的40 - 50年代,这段时间里数学类、工程类、计算机等领域的科学家探讨着人工大脑的可能性,试图去定义什么是机器的智能。在这个背景下,1950年Alan Turing发表了题为“机器能思考吗”的论文,成为划时代之作,提出了著名的图灵测试去定义何为机器具有智能,他说只要有30%的人类测试者在5分钟内无法分辨出被测试对象,就可以认为机器通过了图灵测试。
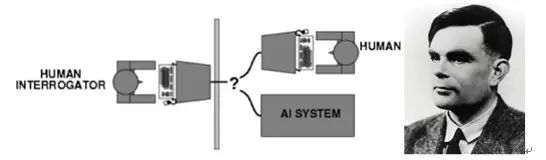 图1:图灵测试;Alan Turing本人
图1:图灵测试;Alan Turing本人
人工智能的第一次黄金时期:现在公认的人工智能起源是1956年的达特矛斯会议,在会议上计算机科学家John McCarthy说服了参会者接受“人工智能(Artificial Intelligence)”。达特矛斯会议之后的十几年是人工智能的第一次黄金时代,大批研究者扑向这一新领域,计算机被应用于代数应用题、几何定理证明,一些顶尖高校建立的人工智能项目获得了ARPA等机构的大笔经费,甚至有研究者认为机器很快就能替代人类做到一切工作。
人工智能的第一次低谷:到了70年代,由于计算机性能的瓶颈、计算复杂性的增长以及数据量的不足,很多项目的承诺无法兑现,比如现在常见的计算机视觉根本找不到足够的数据库去支撑算法去训练,智能也就无从谈起。后来学界将人工智能分为两种:难以实现的强人工智能和可以尝试的弱人工智能。强人工智能是可以认为就是人,可执行“通用任务”;弱人工智能则处理单一问题,我们迄今仍处于弱人工智能时代,而很多项目的停滞也影响了资助资金的走向,AI参与了长达数年之久的低谷。
专家系统的出现:1970年代之后,学术界逐渐接受新的思路:人工智能不光要研究解法,还得引入知识。于是,专家系统诞生了,它利用数字化的知识去推理,模仿某一领域的专家去解决问题,“知识处理”随之成为了主流人工智能的研究重点。在1977年世界人工智能大会提出的“知识工程”的启发下,日本的第五代计算机计划、英国的阿尔维计划、欧洲的尤里卡计划和美国的星计划相机出台,带来专家系统的高速发展,涌现了卡内基梅隆的XCON系统和Symbolics、IntelliCorp等新公司。
人工智能的第二次经费危机:20世纪90年代之前的大部分人工智能项目都是靠政府机构的资助资金在研究室里支撑,经费的走向直接影响着人工智能的发展。80年代中期,苹果和IBM的台式机性能已经超过了运用专家系统的通用型计算机,专家系统的风光随之褪去,人工智能研究再次遭遇经费危机。
IBM的深蓝和Watson:专家系统之后,机器学习成为了人工智能的焦点,其目的是让机器具备自动学习的能力,通过算法使得机器从大量历史数据中学习规律并对新的样本作出判断识别或预测。在这一阶段,IBM无疑是AI领域的领袖,1996年深蓝(基于穷举搜索树)战胜了国际象棋世界冠军卡斯帕罗夫,2011年Watson(基于规则)在电视问答节目中战胜人类选手,特别是后者涉及到放到现在仍然是难题的自然语言理解,成为机器理解人类语言的里程碑的一步。
深度学习的强势崛起:深度学习是机器学习的第二次浪潮,2013年4月,《麻省理工学院技术评论》杂志将深度学习列为2013年十大突破性技术之首。其实,深度学习并不是新生物,它是传统神经网络(Neural Network)的发展,两者之间有相同的地方,采用了相似的分层结构,而不一样的地方在于深度学习采用了不同的训练机制,具备强大的表达能力。传统神经网络曾经是机器学习领域很火的方向,后来由于参数难于调整和训练速度慢等问题淡出了人们的视野。
但是有一位叫Geoffrey Hinton的多伦多大学老教授非常执着的坚持神经网络的研究,并和Yoshua Bengio、Yann LeCun(发明了现在被运用最广泛的深度学习模型-卷积神经网CNN)一起提出了可行的deep learning方案。标志性的事情是,2012年Hinton的学生在图片分类竞赛ImageNet上大大降低了错误率(ImageNet Classification with Deep Convolutional Neural Networks),打败了工业界的巨头Google,顿时让学术界和工业界哗然,这不仅学术意义重大,更是吸引了工业界大规模的对深度学习的投入:2012年Google Brain用16000个CPU核的计算平台训练10亿神经元的深度网络,无外界干涉下自动识别了“Cat”;Hinton的DNN初创公司被Google收购,Hinton个人也加入了Google;而另一位大牛LeCun加盟Facebook,出任AI实验室主任;百度成立深度学习研究所,由曾经领衔Google Brain的吴恩达全面负责。不仅科技巨头们加大对AI的投入,一大批初创公司乘着深度学习的风潮涌现,使得人工智能领域热闹非凡。
|人工智能之主要引擎:深度学习
机器学习发展分为两个阶段,起源于上世纪20年代的浅层学习(Shallow Learning)和最近几年才火起来的深度学习(Deep Learning)。浅层学习的算法中,最先被发明的是神经网络的反向传播算法(back propagation),为什么称之为浅层呢,主要是因为当时的训练模型是只含有一层隐含层(中间层)的浅层模型,浅层模型有个很大的弱点就是有限参数和计算单元,特征表达能力弱。
上世纪90年代,学术界提出一系列的浅层机器学习模型,包括风行一时的支撑向量机Support Vector Machine,Boosting等,这些模型相比神经网络在效率和准确率上都有一定的提升,直到2010年前很多高校研究室里都是用时髦的SVM等算法,包括笔者本人(当时作为一名机器学习专业的小硕,研究的是Twitter文本的自动分类,用的就是SVM),主要是因为这类浅层模型算法理论分析简单,训练方法也相对容易掌握,这个时期神经网络反而相对较为沉寂,顶级学术会议里很难看到基于神经网络算法实现的研究。
但其实后来人们发现,即使训练再多的数据和调整参数,识别的精度似乎到了瓶颈就是上不去,而且很多时候还需要人工的标识训练数据,耗费大量人力,机器学习中的5大步骤有特征感知,图像预处理,特征提取,特征筛选,预测与识别,其中前4项是不得不亲自设计的(笔者经过机器学习的地狱般的折磨终于决定转行)。在此期间,我们执着的Hinton老教授一直研究着多隐层神经网络的算法,多隐层其实就是浅层神经网络的深度版本,试图去用更多的神经元来表达特征,但为什么实现起来这么苦难的呢,原因有三点:
1. BP算法中误差的反向传播随着隐层的增加而衰减;优化问题,很多时候只能达到局部最优解;
2. 模型参数增加的时候,对训练数据的量有很高要求,特别是不能提供庞大的标识数据,只会导致过度复杂;
3. 多隐层结构的参数多,训练数据的规模大,需要消耗很多计算资源。
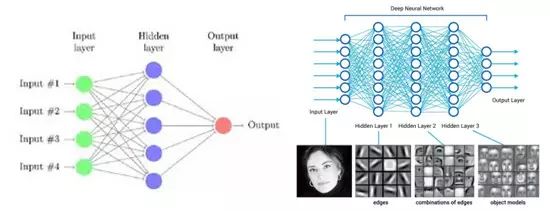
图2:传统神经网络与多隐层神经网络
2006年,Hinton和他的学生R.R. Salakhutdinov在《Science》上发表了一篇文章(Reducing the dimensionality of data with neural networks),成功训练出多层神经网络,改变了整个机器学习的格局,虽然只有3页纸但现在看来字字千金。这篇文章有两个主要观点:1)多隐层神经网络有更厉害的学习能力,可以表达更多特征来描述对象;2)训练深度神经网络时,可通过降维(pre-training)来实现,老教授设计出来的Autoencoder网络能够快速找到好的全局最优点,采用无监督的方法先分开对每层网络进行训练,然后再来微调。
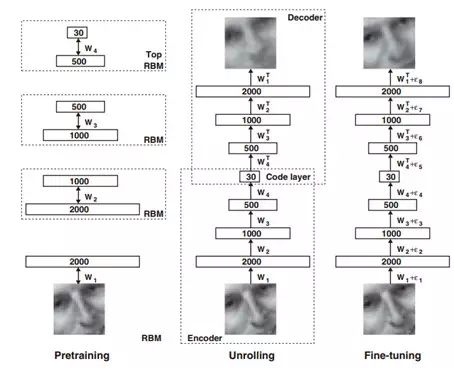
图3:图像的与训练,编码→解码→微调
从图3我们可以看到,深度网络是逐层逐层进行预训练,得到每一层的输出;同时引入编码器和解码器,通过原始输入与编码→再解码之后的误差来训练,这两步都是无监督训练过程;最后引入有标识样本,通过有监督训练来进行微调。逐层训练的好处是让模型处于一个接近全局最优的位置去获得更好的训练效果。
以上就是Hinton在2006年提出的著名的深度学习框架,而我们实际运用深度学习网络的时候,不可避免的会碰到卷积神经网络(Convolutional Neural Networks, CNN)。CNN的原理是模仿人类神经元的兴奋构造:大脑中的一些个体神经细胞只有在特定方向的边缘存在时才能做出反应,现在流行的特征提取方法就是CNN。打个比方,当我们把脸非常靠近一张人脸图片观察的时候(假设可以非常非常的近),这时候只有一部分的神经元是被激活的,我们也只能看到人脸上的像素级别点,当我们把距离一点点拉开,其他的部分的神经元将会被激活,我们也就可以观察到人脸的线条→图案→局部→人脸,整个就是一步步获得高层特征的过程。
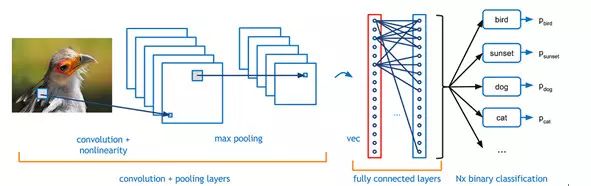
图4:基本完整的深度学习流程
深度学习的“深”(有很多隐层),好处是显而易见的 – 特征表达能力强,有能力表示大量的数据;pretraining是无监督训练,节省大量人力标识工作;相比传统的神经网络,通过逐层逐层训练的方法降低了训练的难度,比如信号衰减的问题。深度学习在很多学术领域,比浅层学习算法往往有20-30%成绩的提高,驱使研究者发现新大陆一般涌向深度学习这一领域,弄得现在不说用了深度学习都不好意思发论文了。
|深度学习的重要发展领域
深度学习首先在图像、声音和语义识别取得了长足的进步,特别是在图像和声音领域相比传统的算法大大提升了识别率,其实也很容易理解,深度学习是仿人来大脑神经感知外部世界的算法,而最直接的外部自然信号莫过于图像、声音和文字(非语义)。
图像识别:图像是深度学习最早尝试的领域,大牛Yann LeCun早在1989年就开始了卷积神经网络的研究,取得了在一些小规模(手写字)的图像识别的成果,但在像素丰富的图片上迟迟没有突破,直到2012年Hinton和他学生在ImageNet上的突破,使识别精度提高了一大步。2014年,香港中文大学教授汤晓鸥领导的计算机视觉研究组开发了名为DeepID的深度学习模型, 在LFW (Labeled Faces in the Wild,人脸识别使用非常广泛的测试基准)数据库上获得了99.15%的识别率,人用肉眼在LFW上的识别率为97.52%,深度学习在学术研究层面上已经超过了人用肉眼的识别。
当然在处理真实场景的人脸识别时还是差强人意,例如人脸不清晰,光照条件,局部遮挡等因素都会影响识别率,所以在实际操作中机器学习与人工确认相结合,更加妥当。国内做人脸识别的公司众多,其中Face++、中科奥森、Sensetime、Linkface、飞搜科技都是走在前面的,在真实环境运用或者在垂直细分领域中有着深厚的数据积累。在基于面部特征识别技术的情绪识别领域,阅面科技与Facethink(Facethink为天使湾早期投资项目)是国内少数进入该领域的初创公司。
语音识别:语音识别长期以来都是使用混合高斯模型来建模,在很长时间内都是占据垄断地位的建模方式,但尽管其降低了语音识别的错误率,但面向商业级别的应用仍然困难,也就是在实际由噪音的环境下达不到可用的级别。直到深度学习的出现,使得识别错误率在以往最好的基础上相对下降30%以上,达到商业可用的水平。微软的俞栋博士和邓力博士是这一突破的最早的实践者,他们与Hinton一起最早将深度学习引入语音识别并取得成功。由于语音识别的算法成熟,科大讯飞、云知声、思必驰在通用识别上识别率都相差不大,在推广上科大讯飞是先行者,从军用到民用,包括移动互联网、车联网、智能家居都有广泛涉及。
自然语言处理(NLP):即使现在深度学习在NLP领域并没有取得像图像识别或者语音识别领域的成绩,基于统计的模型仍然是NLP的主流,先通过语义分析提取关键词、关键词匹配、算法判定句子功能(计算距离这个句子最近的标识好的句子),最后再从提前准备的数据库里提供用户输出结果。显然,这明显谈不上智能,只能算一种搜索功能的实现,而缺乏真正的语言能力。苹果的Siri、微软的小冰、图灵机器人、百度度秘等巨头都在发力智能聊天机器人领域,而应用场景在国内主要还是客服(即使客户很讨厌机器客户,都希望能第一时间直接联系到人工服务),我认为市场上暂时还没出现成熟度非常高的产品。小冰众多竞争对手中还是蛮有意思的,她的设想就是“你随便和我聊天吧”,而其他竞争对手则专注于某些细分领域却面临着在细分领域仍是需要通用的聊天系统,个人认为小冰经过几年的数据积累和算法改善是具备一定优势脱颖而出。
为什么深度学习在NLP领域进展缓慢:对语音和图像来说,其构成元素(轮廓、线条、语音帧)不用经过预处理都能清晰的反映出实体或者音素,可以简单的运用到神经网络里进行识别工作。而语义识别大不相同:首先一段文本一句话是经过大脑预处理的,并非自然信号;其次,词语之间的相似并不代表其意思相近,而且简单的词组组合起来之后意思也会有歧义(特别是中文,比如说“万万没想到”,指的是一个叫万万的人没想到呢,还是表示出乎意料的没想到呢,还是一部电影的名字呢);对话需要上下文的语境的理解,需要机器有推理能力;人类的语言表达方式灵活,而很多交流是需要知识为依托的。很有趣,仿人类大脑识别机制建立的深度学习,对经过我们人类大脑处理的文字信号,反而效果差强人意。根本上来说,现在的算法还是弱人工智能,可以去帮人类快速的自动执行(识别),但还是不能理解这件事情本身。
|深度学习的挑战和发展方向的探讨
受益于计算能力的提升和大数据的出现,深度学习在计算机视觉和语音识别领域取得了显著的成果,不过我们也看到了一些深度学习的局限性,亟待解决:
1. 深度学习在学术领域取得了不错的成果,但在商业上对企业活动的帮助还是有限的,因为深度学习是一个映射的过程,从输入A映射到输出B,而在企业活动中我如果已经拥有了这样的A→B的配对,为什么还需要机器学习来预测呢?让机器自己在数据中寻找这种配对关系或者进行预测,目前还是有很大难度。
2. 缺乏理论基础,这是困扰着研究者的问题。比如说,AlphaGo这盘棋赢了,你是很难弄懂它怎么赢的,它的策略是怎样的。在这层意思上深度学习是一个黑箱子,在实际训练网络的过程中它也是个黑箱子:神经网络需要多少个隐层来训练,到底需要多少有效的参数等,都没有很好的理论解释。我相信很多研究者在建立多层神经网络的时候,还是花了很多时间在枯燥的参数调试上。
3. 深度学习需要大量的训练样本。由于深度学习的多层网络结构,其具备很强的特征表达能力,模型的参数也会增加,如果训练样本过小是很难实现的,需要海量的标记的数据,避免产生过拟合现象(overfitting)不能很好的表示整个数据。
4. 在上述关于深度学习在NLP应用的篇章也提到,目前的模型还是缺乏理解及推理能力。
因此,深度学习接下来的发展方向也将会涉及到以上问题的解决,Hinton、LeCun和Bengio三位AI领袖曾在合著的一篇论文(Deep Learning)的最后提到:
(https://www.cs.toronto.edu/~hinton/absps/NatureDeepReview.pdf)
1. 无监督学习。虽然监督学习在深度学习中表现不俗,压倒了无监督学习在预训练的效果,但人类和动物的学习都是无监督学习的,我们感知世界都是通过我们自己的观察,因此若要更加接近人类大脑的学习模式,无监督学习需要得到更好的发展。
2. 强化学习。增强学习指的是从外部环境到行为映射的学习,通过基于回报函数的试错来发现最优行为。由于在实际运用中数据量是递增的,在新数据中能否学习到有效的数据并做修正显得非常重要,深度+强化学习可以提供奖励的反馈机制让机器自主的学习(典型的案例是AlphaGo)。
3. 理解自然语言。老教授们说:赶紧让机器读懂语言吧!
4. 迁移学习。把大数据训练好的模型迁移运用到有效数据量小的任务上,也就是把学到的知识有效的解决不同但相关领域的问题,这事情显得很性感,但问题就在迁移过程已训练好的模型是存在自我偏差的,所以需要高效的算法去消除掉这些偏差。根本上来说,就是让机器像人类一样具备快速学习新知识能力。
自深度学习被Hinton在《Science》发表以来,短短的不到10年时间里,带来了在视觉、语音等领域革命性的进步,引爆了这次人工智能的热潮。虽然目前仍然存在很多差强人意的地方,距离强人工智能还是有很大距离,它是目前最接近人类大脑运作原理的算法,我相信在将来,随着算法的完善以及数据的积累,甚至硬件层面仿人类大脑神经元材料的出现,深度学习将会更进一步的让机器智能化。
最后,我们以Hinton老先生的一段话来结束这篇文章:“It has been obvious since the 1980s that backpropagation through deep autoencoders would be very effective for nonlinear dimensionality reduction, provided that computers were fast enough, data sets were big enough, and the initial weights were close enough to a good solution. All three conditions are now satisfied.”(自从上世纪80年代我们就知道,如果有计算机足够快、数据足够大、初始权重值足够完美,基于深度自动编码器的反向传播算法是非常有效的。现在,这三者都具备了。)









