作者:沈晟 心动网络CTO 已获授权

今年有两个之于我关系比较大的项目,一个是「
RO仙境传说
」,一个是「
去月球
」。「RO仙境传说」是我经历的第一个出口流量达到万兆级的项目,运维比较重。「去月球」要对得起原作的口碑和盛名,责任比较大。这样一来二去,不知不觉中专栏已经断更近半年。好在近日去月球已经上线,终于可以松口气,更新一下自己的专栏了。
心动网络(833897)作为一间游戏发行公司,需要常年管理大量服务器来支撑各种网游服务玩家,涉及诸多服务器部署决策。随着云计算的兴起,心动网络开始越来越多的使用各种云服务商的产品,也积累了不少经验。
历史
最早,心动网络的服务器以自行采购服务器硬件托管至IDC数据中心模式为主(后文简称 IDC托管)。部分海外业务除了少量海外的IDC托管外,会使用一些Linode服务和零星的AWS服务,由此我们开始接触云服务商。
2015年心动做了很多尝试,包括在合作方的支持下建立了一个小规模的OpenStack集群(对内对外业务中都有使用)。同时随着云服务商的爆发,我们也开始使用一些阿里云、腾讯云和UCloud的服务。在AWS进入中国时,我们也第一时间启用了AWS的北京服务区。可以说所有提供过云计算的服务商,我们要么上业务要么评估,基本都接触了个遍,而且都有一定深度。
问题分析
先说说我们碰到的问题。
问题一:云计算价格贵,甚至现在仍然非常贵
曝光一下心动使用IDC托管的服务器成本和算力:心动采购的服务器中规中矩,例如我们最近采购的配置:两颗各12 Cores的CPU,开HT可48核,512G内存,12块硬盘做RAID10,组成24T可用存储。这样的服务器一般可以使用3~5年,平摊到每个月成本不过2千元上下。在IDC数据中心,我们不将服务器堆叠过密的情形下,托管费用均摊到每台也就每月1千元上下。之于说人员成本,在我们提倡DevOps和充分合理利用供应商支持的背景下,控制的非常好。管理这些设备的核心运维部门也只有3位同学,相对于我们庞大的服务器数量基本可以忽略不计。(而且我们发现,即使使用云服务,我们这些运维同学要做的事情也一点都不少。)所以在我们的IDC托管策略下,一台48核CPU 512G内存 24T硬盘的服务器月使用成本,在3千元左右或更低。
用这个数字来对比各家云服务商公开的价格,可以发现,接近这个计算能力的云服务售价,一般都比我们IDC托管贵3-7倍,像AWS这种高端云服务商的价格还会贵10倍以上。
而且,我们自行搭建OpenStack的过程也让我们确信,这个成本问题并不是云服务商给自己留的利润。而是因为要想建立可靠、弹性和灵活的云服务,就必须在网络、存储和各种基础设施上,投入更高的配置和额外的设备,即使不考虑研发和维护支出,成本也会直线上升。所以价格高,是传统虚拟云服务架构的硬伤。(未来的世界应该是属于容器编排和Serverless Compute的,不过那是后话。)
问题二:同配置下,云服务的服务能力更弱
只是贵而已?不那么简单。云计算的虚拟化技术,还会在计算能力上打折扣。
首先,在很多云服务商那里都提供不了48核、512G内存、24T存储这样的配置。而在同样的核心数时,我们也发现云上的CPU计算能力和内存性能不如单纯的物理机(Bare Metal)。以我们搭建OpenStack时的理解,这还是因为宿主机必须保证一定的资源来管理调度租户所需的资源,包括保障SDN和分布式存储的IO性能等,都是宿主机的职责。这是虚拟化的必然开销和损失。如果买的不是独享的配置,还会面临主机资源会被其他租户争抢的问题。
更有甚之,存储I/O、网络吞吐能力PPS(Packets per Second)和带宽这些指标,不只是有性能折扣,为了避免多租户争抢,还会有配额限制,而且这些限制都远低于物理机(bare-metal)。
问题三:所谓弹性,都是有限度的
云计算大为鼓吹伸缩性的优势,听上去很美好。但事实上,所有的弹性都是有限度的。云服务商的计算能力也是靠一个个数据中心、一台台服务器堆上去的。当你有100-200台高配置服务器资源需求时,最大的云服务商也不能保证第一时间满足。即使在谷歌云和AWS上,可购买的资源也是有配额的。如果超过一定量级,就要开工单申请,还不一定能被批准。国内服务沟通上好一点的,会先来和我们打招呼,让我们有大量需求时,尽量提前1~2个月提出来,让服务商做些准备,免得真上业务时创建不了实例。
即使如此,我们还是碰到几次,虽然提前打了招呼,到点还是拿不到计算资源,一台台买好的服务器就是启动不起来的情况。
问题四:云的高可用容灾,不能神话
有的人会说,「即使云服务成本高些性能弱些,但是技术先进、多地冗余,高可用和容灾能力都是IDC托管比不了的」… 我以前也这么以为的,但是用了两年各家云服务,现在的我只想说:「
不要神话云服务
」
我还清楚记得收到第一封来自AWS,通知实例「退休」邮件时的心情:
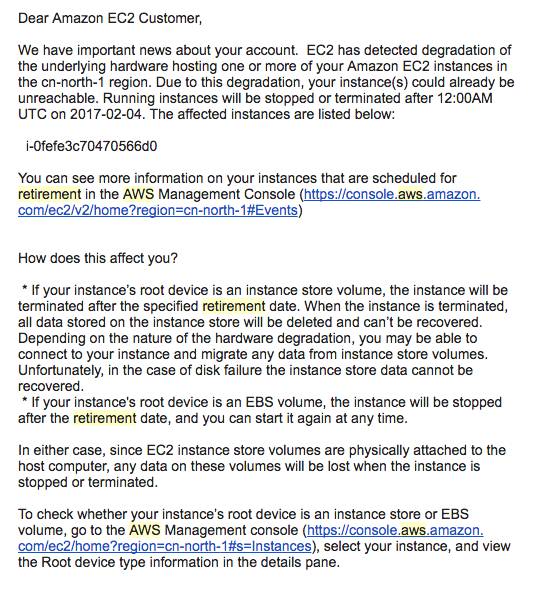
这里AWS所谓的「退休(Retirement)」也就是中止实例了,甚至默认分配的公网IP都不一定能保留下来…… 而这样被「退休」的事,每年都还有4~5次左右。
阿里云和UCloud碰到同样情形时略好些,会尽量保留实例,只是做下物理宿主机迁移,短暂甚至不太影响业务。但是在一些大型的规划变更时,也是有关机时间长达数小时,IP地址也必须更换的经历。
再举个例子,各家云服务商的存储都是花大代价「两地三中心」「异地冗余」保证多个9的。但是今年2月底,亚马逊 AWS S3 服务也故障了。
所以真的不能神话云服务。
部署策略
当然,尽管发现了这么多问题。云服务还是在很多业务类型上有优势:










